Uw eerste werkstroom maken met een Azure Databricks-taak
In dit artikel wordt een Azure Databricks-taak gedemonstreert waarmee taken worden ingedeeld om een voorbeeldgegevensset te lezen en te verwerken. In deze snelstart, gaat u het volgende doen:
- Maak een nieuw notebook en voeg code toe om een voorbeeldgegevensset met populaire babynamen per jaar op te halen.
- Sla de voorbeeldgegevensset op in Unity Catalog.
- Maak een nieuw notebook en voeg code toe om de gegevensset te lezen uit Unity Catalog, deze te filteren op jaar en de resultaten weer te geven.
- Maak een nieuwe taak en configureer twee taken met behulp van de notebooks.
- Voer de taak uit en bekijk de resultaten.
Vereisten
Als uw werkruimte Unity Catalog-enabled is en Serverless Jobs is ingeschakeld, wordt de taak standaard uitgevoerd op Serverless compute. U hebt geen machtiging voor het maken van clusters nodig om uw taak uit te voeren met serverloze compute.
Anders moet u de machtiging voor het maken van clusters hebben om taakresources of machtigingen voor rekenresources voor alle doeleinden te maken.
U moet een volume in Unity Cataloghebben. In dit artikel wordt een volume met de naam my-volume gebruikt in een schema met de naam default in een catalogus met de naam main. U moet ook beschikken over de volgende machtigingen in Unity Catalog:
-
READ VOLUMEenWRITE VOLUME, ofALL PRIVILEGES, voor hetmy-volumevolume. -
USE SCHEMAofALL PRIVILEGESvoor hetdefaultschema. -
USE CATALOGofALL PRIVILEGESvoor demain-catalogus.
Als u deze toestemmingen wilt instellen, kunt u contact opnemen met uw Databricks-beheerder of Unity Catalog-rechten en beveiligbare objecten.
De notebooks maken
Gegevens ophalen en opslaan
Een notebook maken om de voorbeeldgegevensset op te halen en op te slaan in Unity Catalog:
Ga naar de landingspagina van Azure Databricks en klik op
 Nieuwe in de zijbalk en selecteer Notebook. Databricks maakt en opent een nieuw, leeg notitieblok in uw standaardmap. De standaardtaal is de taal die u het laatst hebt gebruikt en het notebook wordt automatisch gekoppeld aan de rekenresource die u het laatst hebt gebruikt.
Nieuwe in de zijbalk en selecteer Notebook. Databricks maakt en opent een nieuw, leeg notitieblok in uw standaardmap. De standaardtaal is de taal die u het laatst hebt gebruikt en het notebook wordt automatisch gekoppeld aan de rekenresource die u het laatst hebt gebruikt.Wijzig indien nodig de standaardtaal in Python.
Kopieer de volgende Python-code en plak deze in de eerste cel van het notebook.
import requests response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv') csvfile = response.content.decode('utf-8') dbutils.fs.put("/Volumes/main/default/my-volume/babynames.csv", csvfile, True)
Gefilterde gegevens lezen en weergeven
Een notebook maken om de gegevens te lezen en te presenteren voor filteren:
Ga naar de landingspagina van Azure Databricks en klik op
Nieuwe in de zijbalk en selecteer Notebook. Databricks maakt en opent een nieuw, leeg notitieblok in uw standaardmap. De standaardtaal is de taal die u het laatst hebt gebruikt en het notebook wordt automatisch gekoppeld aan de rekenresource die u het laatst hebt gebruikt.Wijzig indien nodig de standaardtaal in Python.
Kopieer de volgende Python-code en plak deze in de eerste cel van het notebook.
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/my-volume/babynames.csv") babynames.createOrReplaceTempView("babynames_table") years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist() years.sort() dbutils.widgets.dropdown("year", "2014", [str(x) for x in years]) display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
Een taak maken
Klik op
 Werkstromen in de zijbalk.
Werkstromen in de zijbalk.Klik op
 .
.Het tabblad Taken wordt weergegeven met het dialoogvenster Taak maken.
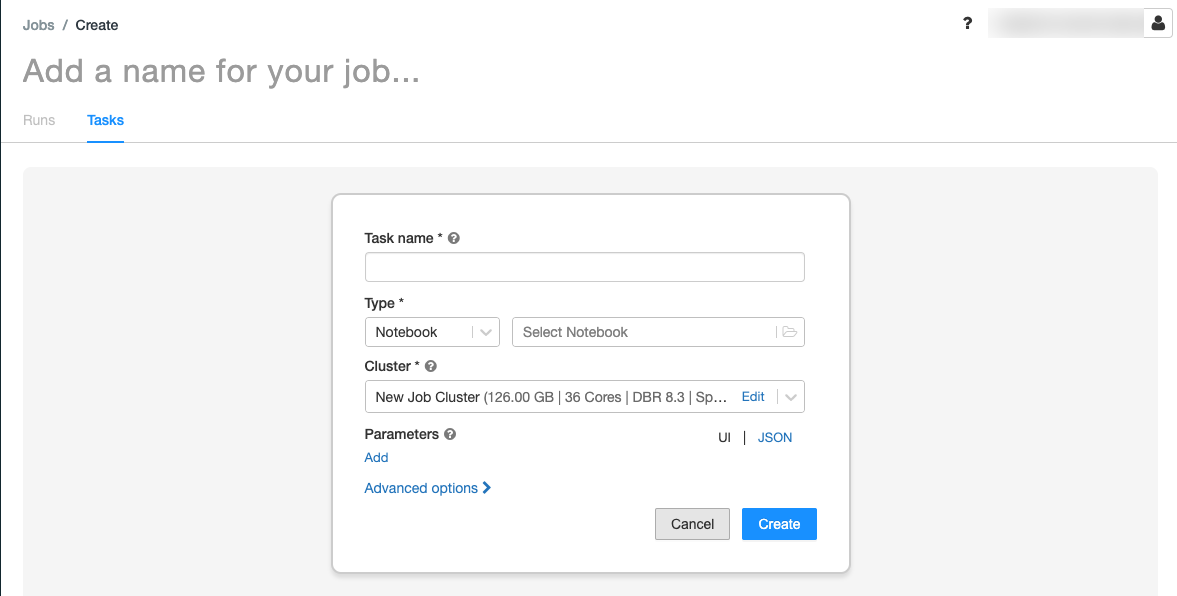
Vervang Een naam voor uw taak toevoegen... door uw taaknaam.
Voer in het veld Taaknaam een naam in voor de taak, bijvoorbeeld retrieve-baby-names.
In de vervolgkeuzelijst Type selecteer Notebook.
Gebruik de bestandsbrowser om het eerste notitieblok te zoeken dat u hebt gemaakt, klik op de naam van het notitieblok en klik op Bevestigen.
Klik op Taak maken.
Klik
 onder de taak die u zojuist hebt gemaakt om een andere taak toe te voegen.
onder de taak die u zojuist hebt gemaakt om een andere taak toe te voegen.Voer in het veld Taaknaam een naam in voor de taak, bijvoorbeeld filter-baby-namen.
In de vervolgkeuzelijst Type selecteer Notebook.
Gebruik de bestandsbrowser om het tweede notitieblok te vinden dat u hebt gemaakt, klik op de naam van het notitieblok en klik op Bevestigen.
Klik op Toevoegen onder Parameters. Voer in het veld Sleutel de waarde in
year. Voer in het veld Waarde2014in.Klik op Taak maken.
De taak uitvoeren
Als u de taak direct wilt uitvoeren, klikt u  in de rechterbovenhoek. U kunt de taak ook uitvoeren door te klikken op het tabblad Uitvoeringen en te klikken op Nu uitvoeren in de tabel Actieve uitvoeringen.
in de rechterbovenhoek. U kunt de taak ook uitvoeren door te klikken op het tabblad Uitvoeringen en te klikken op Nu uitvoeren in de tabel Actieve uitvoeringen.
Uitvoeringsdetails weergeven
Klik op het tabblad Uitvoeringen en klik op de koppeling voor de uitvoering in de tabel Actieve uitvoeringen of in de tabel Voltooide uitvoeringen (afgelopen 60 dagen).
Klik op een van beide taken om de uitvoer en details weer te geven. Klik bijvoorbeeld op de taak filter-baby-names om de uitvoer weer te geven en details voor de filtertaak uit te voeren:
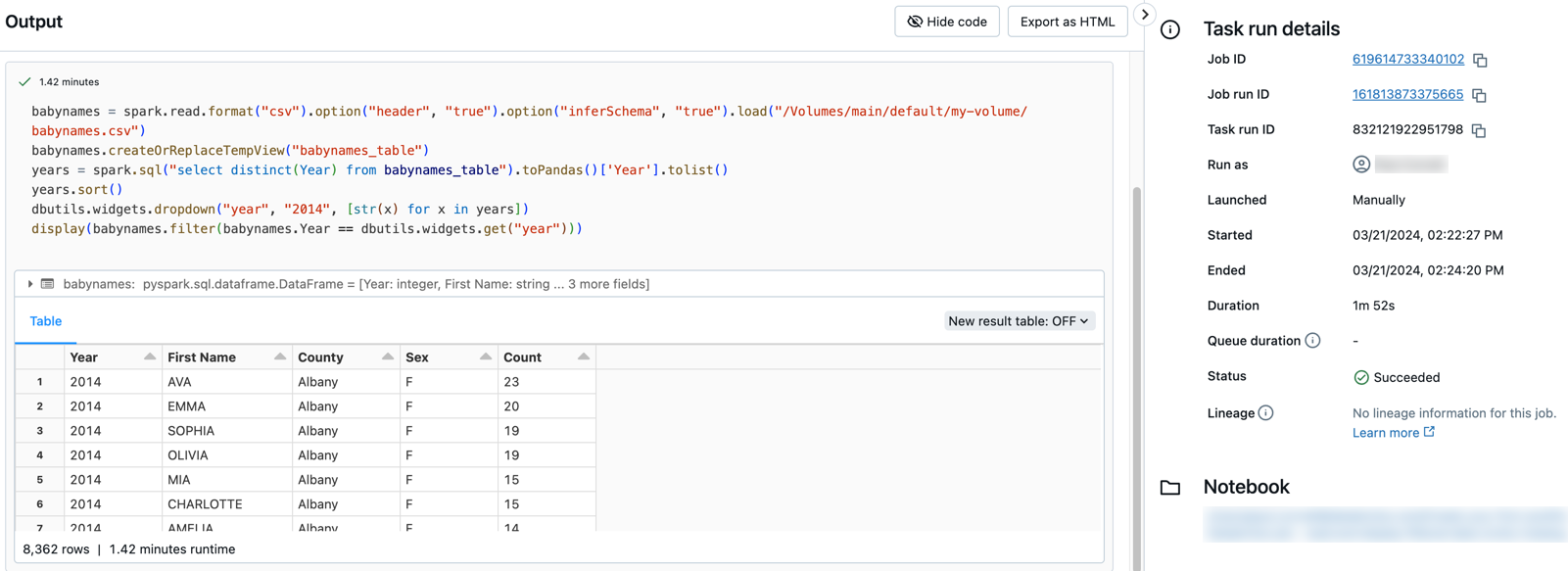
Uitvoeren met verschillende parameters
Voer de taak opnieuw uit en filter babynamen voor een ander jaar:
- Klik op
 naast Nu uitvoeren en selecteer Nu uitvoeren met verschillende parameters of klik op Nu uitvoeren met verschillende parameters in de tabel Actieve uitvoeringen.
naast Nu uitvoeren en selecteer Nu uitvoeren met verschillende parameters of klik op Nu uitvoeren met verschillende parameters in de tabel Actieve uitvoeringen. - Voer in het veld Waarde
2015in. - Klik op Uitvoeren .