Een vectorzoekindex maken en er query's op uitvoeren
In dit artikel wordt beschreven hoe u een vectorzoekindex maakt en opvraagt met behulp van Mozaïek AI Vector Search.
U kunt vectorzoekonderdelen, zoals een vectorzoekeindpunt en vectorzoekindexen, maken en beheren met behulp van de gebruikersinterface, de Python SDK-of de REST API-.
Eisen
- Werkruimte met Unity Catalog ingeschakeld.
- Serverloze rekenkracht ingeschakeld. Zie voor instructies Verbinden met serverloze computing.
- Voor de brontabel moet Wijzigingengegevensfeed zijn ingeschakeld. Zie Delta Lake-wijzigingenfeed gebruiken in Azure Databricksvoor instructies.
- Als u een vectorzoekindex wilt maken, moet u CREATE TABLE bevoegdheden hebben voor het catalogusschema waarin de index wordt gemaakt.
- Als u een query wilt uitvoeren op een index die eigendom is van een andere gebruiker, moet u extra bevoegdheden hebben. Zie Een vectorzoekeindpunt opvragen.
De machtiging voor het maken en beheren van vectorzoekeindpunten wordt geconfigureerd met behulp van toegangsbeheerlijsten. Zie Eindpunt-ACL's voor vectorzoekopdrachten.
Installatie
Als u de Vector Search SDK wilt gebruiken, moet u deze installeren in uw notebook. Gebruik de volgende code om het pakket te installeren:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
Gebruik vervolgens de volgende opdracht om VectorSearchClientte importeren:
from databricks.vector_search.client import VectorSearchClient
Authenticatie
Zie gegevensbescherming en -verificatie.
Een vectorzoekeindpunt maken
U kunt een vectorzoekeindpunt maken met behulp van de Databricks-gebruikersinterface, Python SDK of de API.
Een vectorzoekeindpunt maken met behulp van de gebruikersinterface
Volg deze stappen om een vectorzoekeindpunt te maken met behulp van de gebruikersinterface.
Klik in de linkerzijbalk op Compute.
Klik op het tabblad Vector Search en klik op Maken.

Het formulier voor het maken van een eindpunt wordt geopend. Voer een naam in voor dit eindpunt.
Klik op bevestigen.
Een vectorzoekeindpunt maken met behulp van de Python SDK
In het volgende voorbeeld wordt de create_endpoint() SDK-functie gebruikt om een vectorzoekeindpunt te maken.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
Een vectorzoekeindpunt maken met behulp van de REST API
Zie de REST-API-referentiedocumentatie: POST /api/2.0/vector-search/endpoints.
(Optioneel) Een eindpunt maken en configureren voor het insluitmodel
Als u ervoor kiest om databricks de insluitingen te laten berekenen, kunt u een vooraf geconfigureerd Foundation Model-API-eindpunt gebruiken of een model voor eindpunt maken om het insluitmodel van uw keuze te leveren. Zie Api's voor betalen per token Foundation-model of Basismodel maken voor eindpunten voor instructies. Zie bijvoorbeeld notebooks Notebook-voorbeelden voor het aanroepen van een model voor insluitingen.
Wanneer u een insluiteindpunt configureert, raadt Databricks u aan de standaardselectie van Schalen te verwijderen naar nul. Het kan enkele minuten duren voordat de eindpunten gereed zijn. De eerste query op een index met een afgeschaald eindpunt kan een time-out opleveren.
Notitie
Er kan een time-out optreden voor de initialisatie van de vectorzoekindex als het embedding-eindpunt niet juist is geconfigureerd voor de dataset. Gebruik alleen CPU-eindpunten voor kleine gegevenssets en tests. Gebruik voor grotere gegevenssets een GPU-eindpunt voor optimale prestaties.
Een vectorzoekindex maken
U kunt een vectorzoekindex maken met behulp van de gebruikersinterface, de Python SDK of de REST API. De gebruikersinterface is de eenvoudigste benadering.
Er zijn twee typen indexen:
- Delta Sync Index automatisch wordt gesynchroniseerd met een Delta-brontabel, waarbij de index automatisch en incrementeel wordt bijgewerkt wanneer de onderliggende gegevens in de Delta-tabel worden gewijzigd.
- Direct Vector Access Index ondersteunt direct lezen en schrijven van vectoren en metagegevens. De gebruiker is verantwoordelijk voor het bijwerken van deze tabel met behulp van de REST API of de Python SDK. Dit type index kan niet worden gemaakt met behulp van de gebruikersinterface. U moet de REST API of de SDK gebruiken.
index maken met behulp van de gebruikersinterface
Klik in de linkerzijbalk op Catalogus om de gebruikersinterface van Catalog Explorer te openen.
Navigeer naar de Delta-tabel die u wilt gebruiken.
Klik op de Creeër-knop in de rechterbovenhoek en selecteer vectorzoekindex uit de vervolgkeuzelijst.
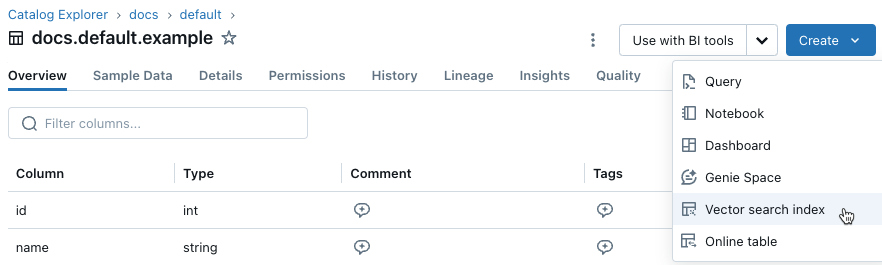
Gebruik de selectors in het dialoogvenster om de index te configureren.
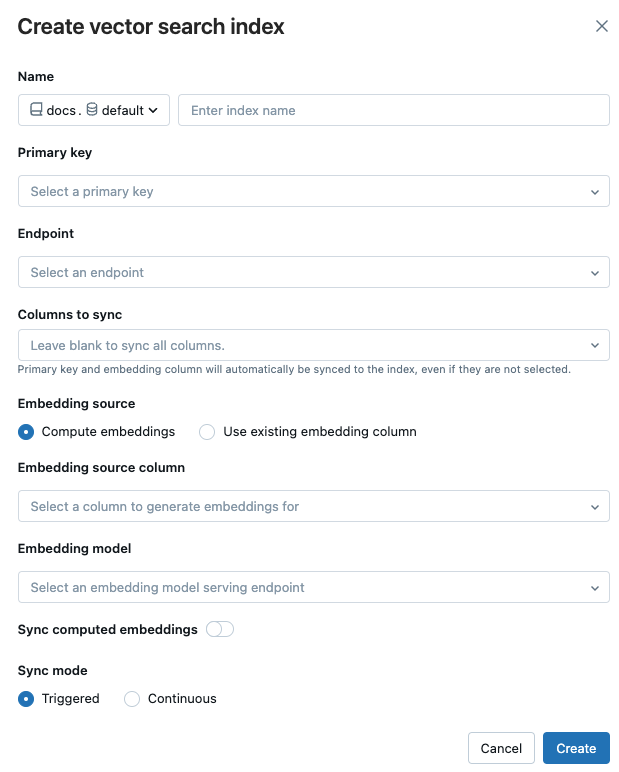
Naam: Naam te gebruiken voor de online tabel in Unity Catalog. De naam vereist een naamruimte met drie niveaus,
<catalog>.<schema>.<name>. Alleen alfanumerieke tekens en onderstrepingstekens zijn toegestaan.primaire sleutel: kolom die moet worden gebruikt als primaire sleutel.
Eindpunt: selecteer het eindpunt voor vectorzoekopdrachten dat u wilt gebruiken.
kolommen omte synchroniseren: selecteer de kolommen die u wilt synchroniseren met de vectorindex. Als u dit veld leeg laat, worden alle kolommen uit de brontabel gesynchroniseerd met de index. De primaire sleutelkolom en de insluitingsbronkolom of de insluitvectorkolom worden altijd gesynchroniseerd.
Bron insluiten: Geef aan of Databricks insluitingen voor een tekstkolom in de Delta-tabel (Compute-insluitingen) moet berekenen of als uw Delta-tabel vooraf berekende insluitingen bevat (Bestaande insluitingskolom gebruiken).
- Als u Compute-embeddingshebt geselecteerd, kiest u de kolom waarvoor u embeddings wilt berekenen en het eindpunt dat het embeddingmodel bedient. Alleen tekstkolommen worden ondersteund.
- Als u Bestaande insluitingskolom gebruikenhebt geselecteerd, selecteert u de kolom die de vooraf berekende insluitingen en de insluitingsdimensie bevat. De indeling van de vooraf samengestelde insluitingskolom moet
array[float]zijn.
Berekende insluitingen synchroniseren: schakel deze instelling in om de gegenereerde insluitingen op te slaan in een Unity Catalog-tabel. Zie Gegenereerde insluitingstabel opslaanvoor meer informatie.
Synchronisatiemodus: Continue houdt de index gesynchroniseerd met seconden latentie. Er zijn echter hogere kosten aan gekoppeld omdat een rekencluster is ingericht om de pijplijn voor continue synchronisatiestreaming uit te voeren. Voor zowel continue als geactiveerdeis de update incrementeel, alleen gegevens die zijn gewijzigd sinds de laatste synchronisatie wordt verwerkt.
Met geactiveerde synchronisatiemodus gebruikt u de Python SDK of de REST API om de synchronisatie te starten. Zie Een Delta Sync Index bijwerken.
Wanneer u klaar bent met het configureren van de index, klikt u op maken.
Index maken met behulp van de Python SDK
In het volgende voorbeeld wordt een Delta Sync-index gemaakt met insluitingen die worden berekend door Databricks.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
In het volgende voorbeeld wordt een Delta Sync-index gemaakt met zelfbeheerde insluitingen. In dit voorbeeld ziet u ook het gebruik van de optionele parameter columns_to_sync om alleen een subset kolommen te selecteren die in de index moeten worden gebruikt.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Standaard worden alle kolommen uit de brontabel gesynchroniseerd met de index. Als u alleen een subset kolommen wilt synchroniseren, gebruikt u columns_to_sync. De primaire sleutel en het insluiten van kolommen worden altijd opgenomen in de index.
Als u alleen de primaire sleutel en de embedding-kolom wilt synchroniseren, moet u deze in columns_to_sync opgeven zoals getoond:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Als u extra kolommen wilt synchroniseren, geeft u deze op zoals wordt weergegeven. U hoeft de primaire sleutel en de insluitingskolom niet op te nemen, omdat ze altijd worden gesynchroniseerd.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
In het volgende voorbeeld wordt een Direct Vector Access-index gemaakt.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Index maken met behulp van de REST API
Raadpleeg de REST API-referentiedocumentatie: POST /api/2.0/vector-search/indexen.
Gegenereerde insluitingstabel opslaan
Als Databricks de insluitingen genereert, kunt u de gegenereerde insluitingen opslaan in een tabel in Unity Catalog. Deze tabel wordt gemaakt in hetzelfde schema als de vectorindex en is gekoppeld vanaf de vectorindexpagina.
De naam van de tabel is de naam van de vectorzoekindex, toegevoegd door _writeback_table. De naam kan niet worden bewerkt.
U kunt de tabel als elke andere tabel in Unity Catalog openen en er query's op uitvoeren. U moet de tabel echter niet verwijderen of wijzigen, omdat deze niet handmatig moet worden bijgewerkt. De tabel wordt automatisch verwijderd als de index wordt verwijderd.
Een vectorzoekindex bijwerken
een Delta Sync-index bijwerken
Indexen die zijn gemaakt met continue synchronisatiemodus, worden automatisch bijgewerkt wanneer de delta-brontabel wordt gewijzigd. Als u geactiveerde synchronisatiemodus gebruikt, gebruikt u de Python SDK of de REST API om de synchronisatie te starten.
Python SDK
index.sync()
REST API
Zie de documentatie voor de REST API-referentie: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Een Direct Vector Access-index bijwerken
U kunt de Python SDK of de REST API gebruiken om gegevens in te voegen, bij te werken of te verwijderen uit een Direct Vector Access Index.
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
REST API
Raadpleeg de REST API-referentiedocumentatie: POST /api/2.0/vector-search/indexen.
In het volgende codevoorbeeld ziet u hoe u een index bijwerkt met behulp van een persoonlijk toegangstoken (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
In het volgende codevoorbeeld ziet u hoe u een index bijwerkt met behulp van een service-principal.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
een vectorzoekeindpunt opvragen
U kunt alleen een query uitvoeren op het eindpunt voor vectorzoekopdrachten met behulp van de Python SDK, de REST API of de SQL vector_search() AI-functie.
Notitie
Als de gebruiker die het eindpunt opvraagt niet de eigenaar is van de vectorzoekindex, moet de gebruiker de volgende UC-bevoegdheden hebben:
- USE CATALOG in de catalogus die de vectorzoekindex bevat.
- USE SCHEMA in het schema dat de vectorzoekindex bevat.
- SELECT op de vectorzoekindex.
Als u een zoekopdracht voor hybride trefwoorden wilt uitvoeren, stelt u de parameter query_type in op hybrid. De standaardwaarde is ann (dichtstbijzijnde buur).
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
REST API
Zie de REST API-referentiedocumentatie: POST /api/2.0/vector-search/indexes/{index_name}/query.
In het volgende codevoorbeeld ziet u hoe u een query kunt uitvoeren op een index met behulp van een persoonlijk toegangstoken (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query Vector Search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
In het volgende codevoorbeeld ziet u hoe u een query uitvoert op een index met behulp van een service-principal.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint (TODO: link), then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
Belangrijk
De vector_search() AI-functie bevindt zich in openbare preview-.
Als u deze AI-functiewilt gebruiken, raadpleegt u vector_search functie.
Filters gebruiken voor query's
Een query kan filters definiëren op basis van elke kolom in de Delta-tabel.
similarity_search retourneert alleen rijen die overeenkomen met de opgegeven filters. De volgende filters worden ondersteund:
| Filteroperator | Gedrag | Voorbeelden |
|---|---|---|
NOT |
Hiermee wordt het filter ontkend. De sleutel moet eindigen op 'NIET'. 'color NOT' met de waarde 'rood' komt bijvoorbeeld overeen met documenten waarbij de kleur niet rood is. |
{"id NOT": 2}
{“color NOT”: “red”}
|
< |
Controleert of de veldwaarde kleiner is dan de filterwaarde. De sleutel moet eindigen op ' <'. Bijvoorbeeld 'price <' met waarde 200 komt overeen met documenten waarbij de prijs kleiner is dan 200. | {"id <": 200} |
<= |
Hiermee wordt gecontroleerd of de veldwaarde kleiner is dan of gelijk is aan de filterwaarde. De sleutel moet eindigen op "<=". Bijvoorbeeld : "price <=" met waarde 200 komt overeen met documenten waarbij de prijs kleiner is dan of gelijk is aan 200. | {"id <=": 200} |
> |
Controleert of de veldwaarde groter is dan de filterwaarde. De sleutel moet eindigen op ' >'. Bijvoorbeeld 'price >' met waarde 200 komt overeen met documenten waarbij de prijs groter is dan 200. | {"id >": 200} |
>= |
Hiermee wordt gecontroleerd of de veldwaarde groter is dan of gelijk is aan de filterwaarde. De sleutel moet eindigen op ">=". Bijvoorbeeld: 'price >=' met waarde 200 komt overeen met documenten waarbij de prijs groter is dan of gelijk is aan 200. | {"id >=": 200} |
OR |
Controleert of de veldwaarde overeenkomt met een van de filterwaarden. De sleutel moet OR bevatten om meerdere subsleutels te scheiden.
color1 OR color2 met waarde ["red", "blue"] bijvoorbeeld overeenkomt met documenten waarbij color1red is of color2blueis. |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
Komt overeen met gedeeltelijke tekenreeksen. | {"column LIKE": "hello"} |
| Er is geen filteroperator opgegeven | Filter controleert op een exacte overeenkomst. Als er meerdere waarden zijn opgegeven, komt deze overeen met een van de waarden. |
{"id": 200}
{"id": [200, 300]}
|
Zie de volgende codevoorbeelden:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
REST API
Zie POST /api/2.0/vector-search/indexes/{index_name}/query.
voorbeeldnotitieblokken
De voorbeelden in deze sectie laten het gebruik van de Python SDK voor vectorzoekopdrachten zien.
Voorbeelden van LangChain
Zie hoe je LangChain kunt gebruiken met Mosaic AI Vector Search voor het integreren van Mosaic AI Vector Search met LangChain-pakketten.
In het volgende notebook ziet u hoe u zoekresultaten voor overeenkomsten converteert naar LangChain-documenten.
Vector zoeken met het Python SDK-notebook
Notebook-voorbeelden voor het aanroepen van een embeddingsmodel
In de volgende notebooks wordt gedemonstreerd hoe u een Mosaic AI Model Serving-eindpunt configureert voor het genereren van embedingen.