RAG (Augmented Generation ophalen) in Azure Databricks
Belangrijk
Deze functie is beschikbaar als openbare preview.
Agent Framework bestaat uit een set hulpprogramma's in Databricks die zijn ontworpen om ontwikkelaars te helpen bij het bouwen, implementeren en evalueren van productiekwaliteit AI-agents zoals RAG-toepassingen (Retrieval Augmented Generation).
In dit artikel wordt beschreven wat RAG is en wat de voordelen zijn van het ontwikkelen van RAG-toepassingen in Azure Databricks.
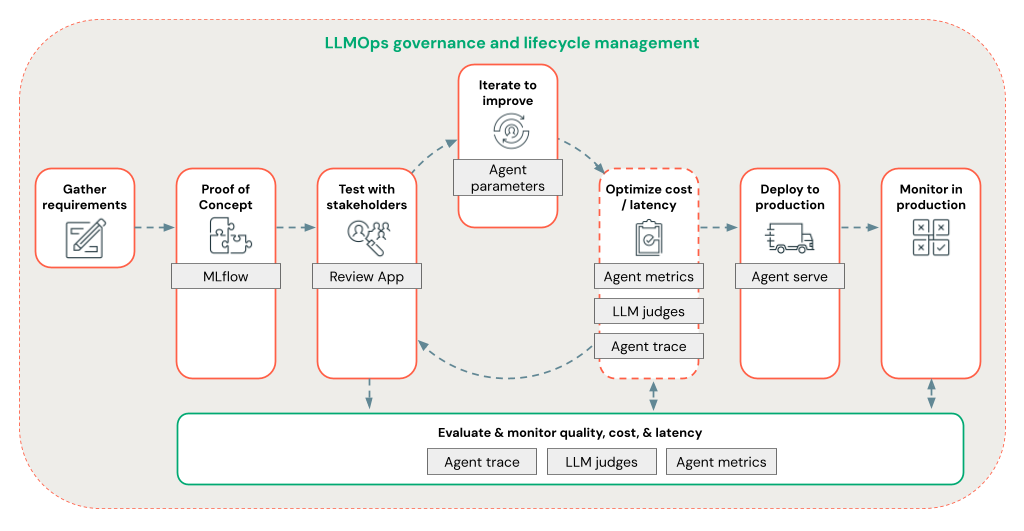
Met Agent Framework kunnen ontwikkelaars snel alle aspecten van RAG-ontwikkeling herhalen met behulp van een end-to-end LLMOps-werkstroom.
Vereisten
- Door Azure AI gemaakte AI-ondersteunende functies moeten zijn ingeschakeld voor uw werkruimte.
- Alle onderdelen van een agentische toepassing moeten zich in één werkruimte bevinden. In het geval van een RAG-toepassing moeten het servicemodel en het vectorzoekexemplaren zich bijvoorbeeld in dezelfde werkruimte bevinden.
Wat is RAG?
RAG is een generatieve AI-ontwerptechniek die grote taalmodellen (LLM) verbetert met externe kennis. Met deze techniek worden LLM's op de volgende manieren verbeterd:
- Eigen kennis: RAG kan eigendomsinformatie bevatten die niet in eerste instantie wordt gebruikt voor het trainen van de LLM, zoals memo's, e-mailberichten en documenten om domeinspecifieke vragen te beantwoorden.
- Actuele informatie: een RAG-toepassing kan de LLM voorzien van informatie uit bijgewerkte gegevensbronnen.
- Bronvermeldingen: MET RAG kunnen LLM's specifieke bronnen citeren, zodat gebruikers de feitelijke nauwkeurigheid van reacties kunnen controleren.
- ACL's (Data Security and Access Control Lists): De ophaalstap kan worden ontworpen om selectief persoonlijke of bedrijfseigen gegevens op te halen op basis van gebruikersreferenties.
Samengestelde AI-systemen
Een RAG-toepassing is een voorbeeld van een samengesteld AI-systeem: het breidt de taalmogelijkheden van de LLM uit door deze te combineren met andere hulpprogramma's en procedures.
In de eenvoudigste vorm doet een RAG-toepassing het volgende:
- Ophalen: de aanvraag van de gebruiker wordt gebruikt om een query uit te voeren op een externe gegevensopslag, zoals een vectorarchief, een zoekopdracht naar tekstwoorden of een SQL-database. Het doel is om gegevens te verkrijgen die het antwoord van de LLM ondersteunen.
- Uitbreiding: De opgehaalde gegevens worden gecombineerd met de aanvraag van de gebruiker, vaak met behulp van een sjabloon met extra opmaak en instructies, om een prompt te maken.
- Generatie: de prompt wordt doorgegeven aan de LLM, die vervolgens een antwoord op de query genereert.
Ongestructureerde versus gestructureerde RAG-gegevens
Rag-architectuur kan werken met niet-gestructureerde of gestructureerde ondersteunende gegevens. De gegevens die u met RAG gebruikt, zijn afhankelijk van uw use-case.
Ongestructureerde gegevens: gegevens zonder een specifieke structuur of organisatie. Documenten met tekst en afbeeldingen of multimedia-inhoud, zoals audio of video's.
- PDF-bestanden
- Google/Office-documenten
- Wiki's
- Installatiekopieën
- Video's
gestructureerde gegevens: tabelgegevens gerangschikt in rijen en kolommen met een specifiek schema, zoals tabellen in een database.
- Klantrecords in een BI- of Data Warehouse-systeem
- Transactiegegevens uit een SQL-database
- Gegevens uit toepassings-API's (bijvoorbeeld SAP, Salesforce, enzovoort)
In de volgende secties wordt een RAG-toepassing voor ongestructureerde gegevens beschreven.
RAG-gegevenspijplijn
De RAG-gegevenspijplijn verwerkt en indexeert documenten voor snel en nauwkeurig ophalen.
In het onderstaande diagram ziet u een voorbeeldgegevenspijplijn voor een ongestructureerde gegevensset met behulp van een semantisch zoekalgoritmen. Databricks-taken organiseren elke stap.
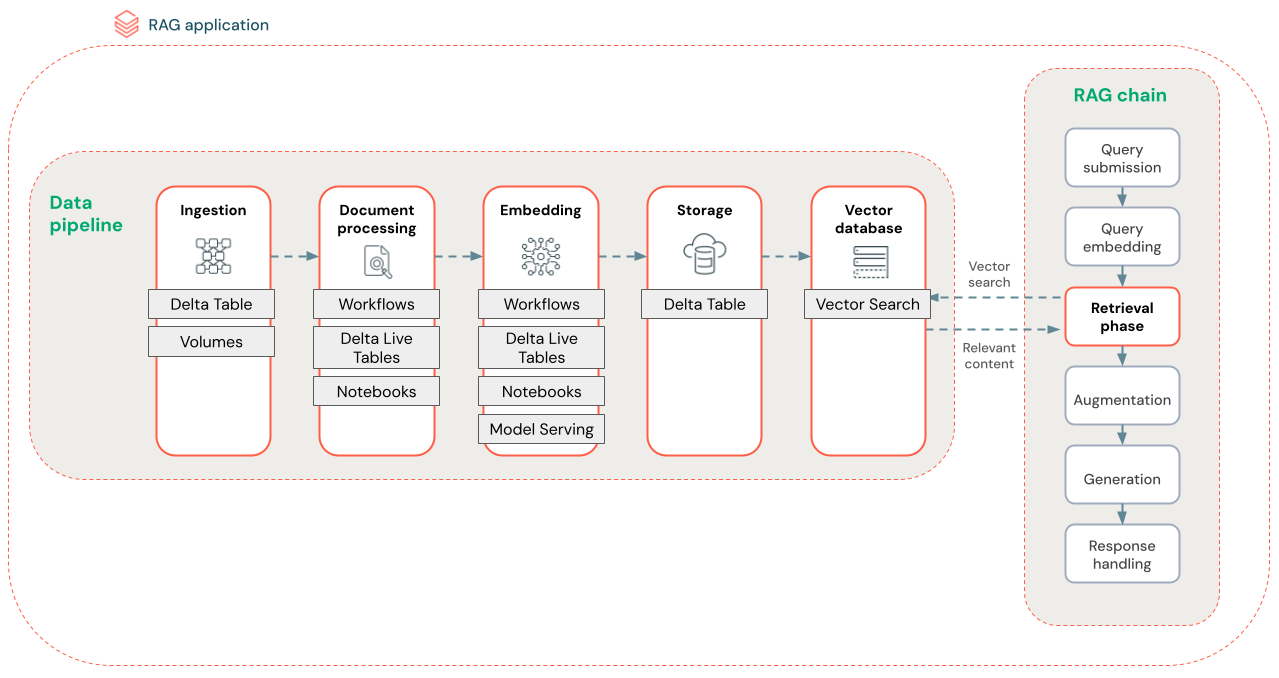
- Gegevensopname : gegevens opnemen uit uw eigen bron. Sla deze gegevens op in een Delta-tabel of Unity Catalog-volume.
-
documentverwerking: U kunt deze taken uitvoeren met Databricks Jobs, Databricks Notebooks en Delta Live Tables.
- Onbewerkte documenten parseren: transformeer de onbewerkte gegevens in een bruikbare indeling. Bijvoorbeeld het extraheren van de tekst, tabellen en afbeeldingen uit een verzameling PDF-bestanden of het gebruik van optische tekenherkenningstechnieken om tekst uit afbeeldingen te extraheren.
- Metagegevens extraheren: metagegevens van documenten extraheren, zoals documenttitels, paginanummers en URL's, zodat de stapquery nauwkeuriger kan worden opgehaald.
- Documenten in stukken hakken: de gegevens splitsen in segmenten die in het contextvenster van de LLM passen. Door deze gerichte segmenten op te halen, in plaats van volledige documenten, krijgt de LLM meer gerichte inhoud om antwoorden te genereren.
- Segmenten insluiten : een insluitmodel gebruikt de segmenten om numerieke representaties te maken van de informatie die vector-insluitingen worden genoemd. Vectoren vertegenwoordigen de semantische betekenis van de tekst, niet alleen trefwoorden op oppervlakniveau. In dit scenario berekent u de insluitingen en gebruikt u Model Serving voor het insluitmodel.
- Opslag insluiten : sla de vector-insluitingen en de tekst van het segment op in een Delta-tabel die is gesynchroniseerd met Vector Search.
- Vectordatabase - Als onderdeel van Vector Search worden insluitingen en metagegevens geïndexeerd en opgeslagen in een vectordatabase voor eenvoudige query's door de RAG-agent. Wanneer een gebruiker een query doet, wordt de aanvraag ingesloten in een vector. De database gebruikt vervolgens de vectorindex om de meest vergelijkbare segmenten te zoeken en te retourneren.
Elke stap omvat technische beslissingen die van invloed zijn op de kwaliteit van de RAG-toepassing. Als u bijvoorbeeld de juiste segmentgrootte in stap 3 kiest, zorgt u ervoor dat de LLM specifieke maar contextuele informatie ontvangt, terwijl het selecteren van een geschikt insluitingsmodel in stap 4 de nauwkeurigheid bepaalt van de segmenten die worden geretourneerd tijdens het ophalen.
Databricks Vector Search
Het berekenen van overeenkomsten is vaak computationeel intensief, maar vectorindexen zoals Databricks Vector Search optimaliseren dit door embeddings efficiënt te organiseren. Vectorzoekopdrachten rangschikken snel de meest relevante resultaten zonder elke insluiting afzonderlijk te vergelijken met de query van de gebruiker.
Vector Search synchroniseert automatisch nieuwe insluitingen die zijn toegevoegd aan uw Delta-tabel en werkt de Vector Search-index bij.
Wat is een RAG-agent?
Een RAG-agent (Retrieval Augmented Generation) is een belangrijk onderdeel van een RAG-toepassing waarmee de mogelijkheden van grote taalmodellen (LLM's) worden verbeterd door externe gegevens te integreren. De RAG-agent verwerkt gebruikersquery's, haalt relevante gegevens op uit een vectordatabase en geeft deze gegevens door aan een LLM om een antwoord te genereren.
Hulpprogramma's zoals LangChain of Pyfunc koppelen deze stappen door hun invoer en uitvoer te verbinden.
In het onderstaande diagram ziet u een RAG-agent voor een chatbot en de Databricks-functies die worden gebruikt om elke agent te bouwen.
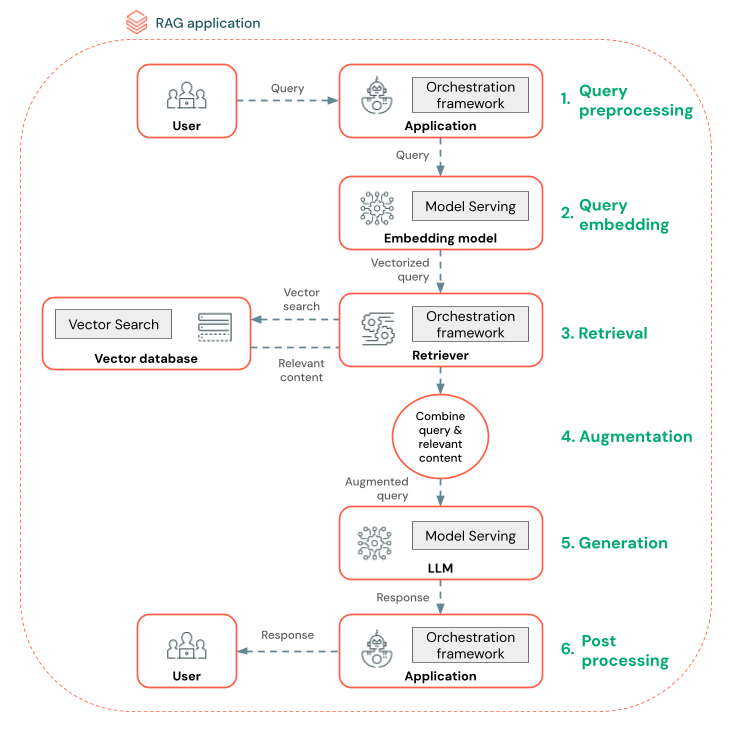
- Query vooraf verwerken : een gebruiker verzendt een query, die vervolgens vooraf wordt verwerkt om deze geschikt te maken voor het uitvoeren van query's op de vectordatabase. Dit kan betrekking hebben op het plaatsen van de aanvraag in een sjabloon of het extraheren van trefwoorden.
- Queryvectorisatie: gebruik Modelverdiening om de aanvraag in te sluiten met hetzelfde insluitingsmodel dat wordt gebruikt voor het insluiten van de segmenten in de gegevenspijplijn. Deze insluitingen maken het mogelijk om de semantische overeenkomsten tussen de aanvraag en de vooraf verwerkte segmenten te vergelijken.
- Ophaalfase : de retriever, een toepassing die verantwoordelijk is voor het ophalen van relevante informatie, neemt de gevectoriseerde query en voert een vector-overeenkomstenzoekopdracht uit met behulp van Vector Search. De meest relevante gegevenssegmenten worden gerangschikt en opgehaald op basis van hun gelijkenis met de query.
- Prompt-uitbreiding : de retriever combineert de opgehaalde gegevenssegmenten met de oorspronkelijke query om extra context te bieden aan de LLM. De prompt is zorgvuldig gestructureerd om ervoor te zorgen dat de LLM de context van de query begrijpt. Vaak heeft de LLM een sjabloon voor het opmaken van het antwoord. Dit proces voor het aanpassen van de prompt wordt prompt engineering genoemd.
- LLM Generation-fase : de LLM genereert een antwoord met behulp van de uitgebreide query die is verrijkt met de resultaten van het ophalen. De LLM kan een aangepast model of een basismodel zijn.
- Naverwerking : het antwoord van de LLM kan worden verwerkt om aanvullende bedrijfslogica toe te passen, bronvermeldingen toe te voegen of op een andere manier de gegenereerde tekst te verfijnen op basis van vooraf gedefinieerde regels of beperkingen
Tijdens dit proces kunnen verschillende kaders worden toegepast om te zorgen voor naleving van het ondernemingsbeleid. Dit kan betrekking hebben op het filteren van de juiste aanvragen, het controleren van gebruikersmachtigingen voordat u toegang verleent tot gegevensbronnen en het gebruik van technieken voor het beheren tentmodus van de gegenereerde antwoorden.
Ontwikkeling van RAG-agent op productieniveau
Voer snel een iteratie uit voor het ontwikkelen van agents met behulp van de volgende functies:
Agents maken en registreren met behulp van een bibliotheek en MLflow. Parameteriseer uw agents om snel te experimenteren en door te gaan met het ontwikkelen van agents.
Agenten inzetten in productie met systeemeigen ondersteuning voor tokenstreaming en aanvraag-/antwoordlogboek, plus een ingebouwde beoordelingsapplicatie om feedback van gebruikers over uw agent te krijgen.
Met agenttracering kunt u traceringen in uw agentcode vastleggen, analyseren en vergelijken om fouten op te sporen en te begrijpen hoe uw agent reageert op aanvragen.
Evaluatie en bewaking
Met evaluatie en bewaking kunt u bepalen of uw RAG-toepassing voldoet aan uw vereisten voor kwaliteit, kosten en latentie. Evaluatie vindt plaats tijdens de ontwikkeling, terwijl de bewaking plaatsvindt zodra de toepassing in productie is geïmplementeerd.
RAG over ongestructureerde gegevens heeft veel onderdelen die van invloed zijn op de kwaliteit. Wijzigingen in gegevensopmaak kunnen bijvoorbeeld van invloed zijn op de opgehaalde segmenten en de mogelijkheid van de LLM om relevante antwoorden te genereren. Het is dus belangrijk om afzonderlijke onderdelen naast de algehele toepassing te evalueren.
Zie Wat is De evaluatie van De AI-agent van Mozaïek? voor meer informatie.
Regionale beschikbaarheid
Zie Functies met beperkte regionale beschikbaarheid voor Agent Framework voor regionale beschikbaarheid