CI/CD met Jenkins in Azure Databricks
Notitie
In dit artikel wordt Jenkins behandeld, dat is ontwikkeld door een derde partij. Als u contact wilt opnemen met de provider, raadpleegt u De Help van Jenkins.
Er zijn talloze CI/CD-hulpprogramma's die u kunt gebruiken om uw CI/CD-pijplijnen te beheren en uit te voeren. In dit artikel wordt uitgelegd hoe u de Jenkins-automatiseringsserver gebruikt. CI/CD is een ontwerppatroon, dus de stappen en fasen die in dit artikel worden beschreven, moeten worden overgedragen met enkele wijzigingen in de definitietaal van de pijplijn in elk hulpprogramma. Bovendien voert veel van de code in deze voorbeeldpijplijn standaard Python-code uit, die u in andere hulpprogramma's kunt aanroepen. Zie Wat is CI/CD in Azure Databricks voor een overzicht van CI/CD in Azure Databricks.
Zie Continue integratie en levering in Azure Databricks met behulp van Azure DevOps voor meer informatie over het gebruik van Azure DevOps met Azure Databricks.
Werkstroom voor CI/CD-ontwikkeling
Databricks stelt de volgende werkstroom voor CI/CD-ontwikkeling met Jenkins voor:
- Maak een opslagplaats of gebruik een bestaande opslagplaats met uw Externe Git-provider.
- Verbind uw lokale ontwikkelcomputer met dezelfde opslagplaats van derden. Zie de documentatie van uw externe Git-provider voor instructies.
- Haal bestaande bijgewerkte artefacten (zoals notebooks, codebestanden en buildscripts) op uit de opslagplaats van derden op uw lokale ontwikkelcomputer.
- U kunt naar wens artefacten maken, bijwerken en testen op uw lokale ontwikkelcomputer. Push vervolgens nieuwe en gewijzigde artefacten van uw lokale ontwikkelcomputer naar de opslagplaats van derden. Zie de documentatie van uw externe Git-provider voor instructies.
- Herhaal stap 3 en 4 indien nodig.
- Gebruik Jenkins periodiek als een geïntegreerde benadering om automatisch artefacten op te halen uit uw opslagplaats van derden naar uw lokale ontwikkelcomputer of Azure Databricks-werkruimte; code bouwen, testen en uitvoeren op uw lokale ontwikkelcomputer of Azure Databricks-werkruimte; en het rapporteren van test- en uitvoeringsresultaten. Hoewel u Jenkins handmatig kunt uitvoeren, zou u in praktijkimplementaties uw Git-provider van derden opdracht geven om Jenkins uit te voeren telkens wanneer een specifieke gebeurtenis plaatsvindt, zoals een pull-aanvraag voor een opslagplaats.
In de rest van dit artikel wordt een voorbeeldproject gebruikt om een manier te beschrijven om Jenkins te gebruiken om de voorgaande CI/CD-ontwikkelwerkstroom te implementeren.
Zie Continue integratie en levering in Azure Databricks met behulp van Azure DevOps voor informatie over het gebruik van Azure DevOps in plaats van Jenkins.
Installatie van lokale ontwikkelcomputer
In dit artikel wordt Jenkins gebruikt om de Databricks CLI en Databricks Asset Bundles te instrueren om het volgende te doen:
- Bouw een Python-wielbestand op uw lokale ontwikkelcomputer.
- Implementeer het ingebouwde Python-wielbestand samen met extra Python-bestanden en Python-notebooks van uw lokale ontwikkelcomputer naar een Azure Databricks-werkruimte.
- Test en voer het geüploade Python-wielbestand en de geüploade notebooks in die werkruimte uit.
Als u uw lokale ontwikkelcomputer wilt instellen om uw Azure Databricks-werkruimte in testrueren om de build- en uploadfasen voor dit voorbeeld uit te voeren, gaat u als volgt te werk op uw lokale ontwikkelcomputer:
Stap 1: Vereiste hulpprogramma's installeren
In deze stap installeert u de Databricks CLI, Jenkins jqen python wheel build-hulpprogramma's op uw lokale ontwikkelcomputer. Deze hulpprogramma's zijn vereist om dit voorbeeld uit te voeren.
Installeer Databricks CLI versie 0.205 of hoger als u dit nog niet hebt gedaan. Jenkins gebruikt de Databricks CLI om de test van dit voorbeeld door te geven en instructies uit te voeren voor uw werkruimte. Zie De Databricks CLI installeren of bijwerken.
Installeer Jenkins en start deze als u dit nog niet hebt gedaan. Zie Jenkins installeren voor Linux, macOS of Windows.
Installeer jq. In dit voorbeeld wordt gebruikgemaakt
jqvan het parseren van uitvoer van een JSON-opdracht.Gebruik
pipdit om de Python wheel build-hulpprogramma's te installeren met de volgende opdracht (voor sommige systemen moet upip3mogelijk in plaats vanpip):pip install --upgrade wheel
Stap 2: Een Jenkins-pijplijn maken
In deze stap gebruikt u Jenkins om een Jenkins-pijplijn te maken voor het voorbeeld van dit artikel. Jenkins biedt een aantal verschillende projecttypen voor het maken van CI/CD-pijplijnen. Jenkins Pipelines bieden een interface voor het definiëren van fasen in een Jenkins-pijplijn met behulp van Groovy-code om Jenkins-invoegtoepassingen aan te roepen en te configureren.
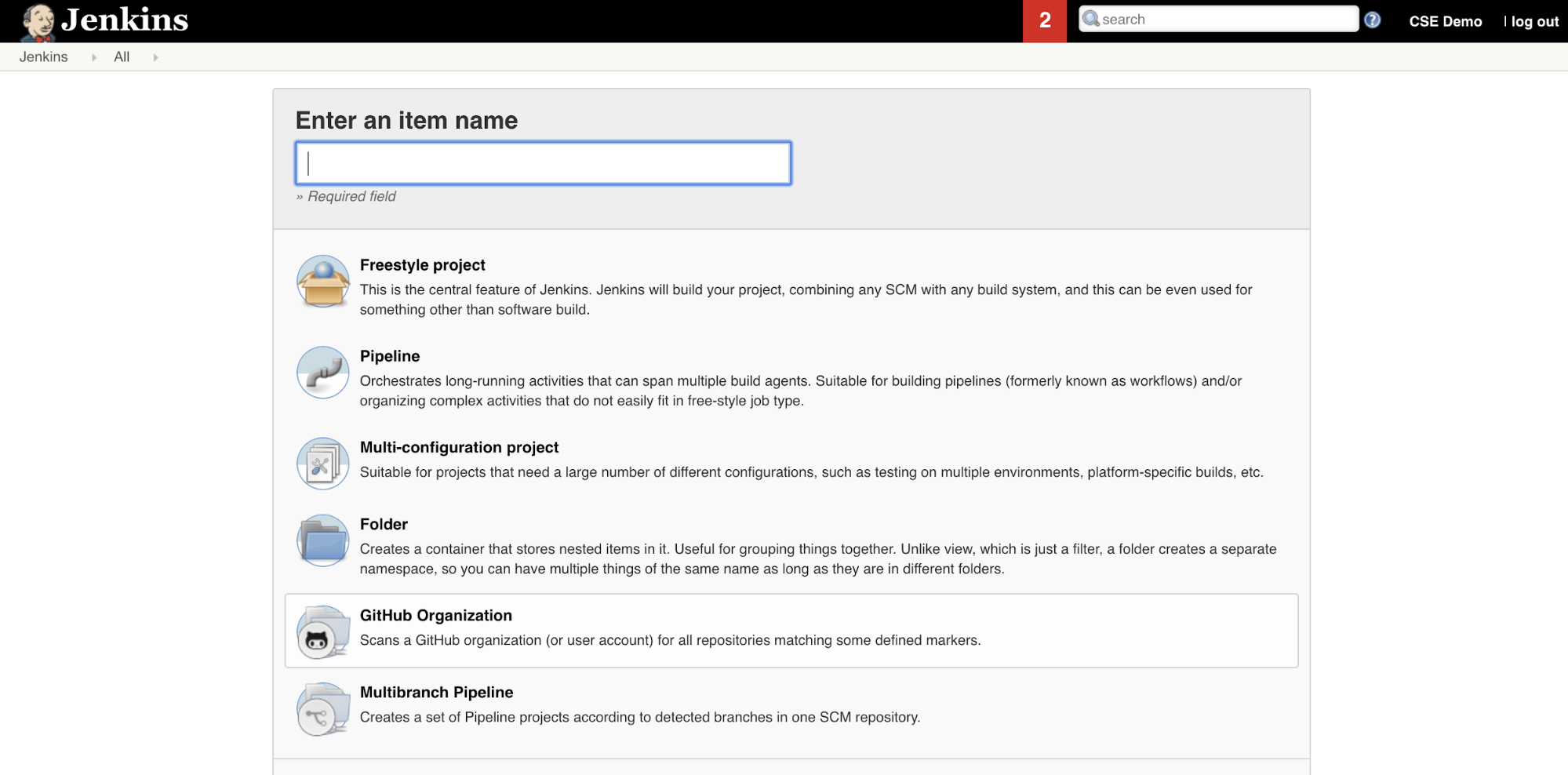
De Jenkins-pijplijn maken in Jenkins:
- Nadat u Jenkins hebt gestart, klikt u in het Jenkins-dashboard op Nieuw item.
- Voor Voer een itemnaam in, typt u bijvoorbeeld
jenkins-demoeen naam voor de Jenkins-pijplijn. - Klik op het pictogram Type pijplijnproject .
- Klik op OK. De pagina Configureren van Jenkins Pipeline wordt weergegeven.
- Selecteer in het gebied Pijplijn in de vervolgkeuzelijst Defintion het pijplijnscript uit SCM.
- Selecteer Git in de vervolgkeuzelijst SCM.
- Voor de URL van de opslagplaats typt u de URL naar de opslagplaats die wordt gehost door de Git-provider van het derde deel.
- Typ voor Branch Specifier,
*/<branch-name>waar<branch-name>is de naam van de vertakking in uw opslagplaats die u wilt gebruiken, bijvoorbeeld*/main. - Voor scriptpad typt
Jenkinsfileu , als dit nog niet is ingesteld. U maakt deJenkinsfileverderop in dit artikel. - Schakel het selectievakje met de titel Lightweight-betaling uit als dit al is ingeschakeld.
- Klik op Opslaan.
Stap 3: Globale omgevingsvariabelen toevoegen aan Jenkins
In deze stap voegt u drie globale omgevingsvariabelen toe aan Jenkins. Jenkins geeft deze omgevingsvariabelen door aan de Databricks CLI. De Databricks CLI heeft de waarden voor deze omgevingsvariabelen nodig om te verifiëren met uw Azure Databricks-werkruimte. In dit voorbeeld wordt OAuth M2M-verificatie (machine-to-machine) gebruikt voor een service-principal (hoewel er ook andere verificatietypen beschikbaar zijn). Als u OAuth M2M-verificatie wilt instellen voor uw Azure Databricks-werkruimte, raadpleegt u Autoriseren zonder toezicht toegang tot Azure Databricks-resources met een service-principal met behulp van OAuth.
De drie globale omgevingsvariabelen voor dit voorbeeld zijn:
-
DATABRICKS_HOST, ingesteld op de URL van uw Azure Databricks-werkruimte, te beginnen methttps://. Zie namen, URL's en id's van werkruimte-exemplaren. -
DATABRICKS_CLIENT_ID, ingesteld op de client-id van de service-principal, die ook wel de toepassings-id wordt genoemd. -
DATABRICKS_CLIENT_SECRET, ingesteld op het Azure Databricks OAuth-geheim van de service-principal.
Ga als volgende te werk om globale omgevingsvariabelen in Jenkins in te stellen vanuit uw Jenkins-dashboard:
- Klik in de zijbalk op Jenkins beheren.
- Klik in de sectie Systeemconfiguratie op Systeem.
- Schakel in het gedeelte Globale eigenschappen het selectievakje omgevingsvariabelen in.
- Klik op Toevoegen en voer de naam en waarde van de omgevingsvariabele in. Herhaal dit voor elke extra omgevingsvariabele.
- Wanneer u klaar bent met het toevoegen van omgevingsvariabelen, klikt u op Opslaan om terug te keren naar uw Jenkins-dashboard.
De Jenkins-pijplijn ontwerpen
Jenkins biedt een aantal verschillende projecttypen voor het maken van CI/CD-pijplijnen. In dit voorbeeld wordt een Jenkins-pijplijn geïmplementeerd. Jenkins Pipelines bieden een interface voor het definiëren van fasen in een Jenkins-pijplijn met behulp van Groovy-code om Jenkins-invoegtoepassingen aan te roepen en te configureren.
U schrijft een Jenkins Pipeline-definitie in een tekstbestand met de naam Jenkinsfile, dat op zijn beurt wordt ingecheckt in de opslagplaats voor broncodebeheer van een project. Zie Jenkins Pipeline voor meer informatie. Hier volgt de Jenkins-pijplijn voor het voorbeeld van dit artikel. Vervang in dit voorbeeld Jenkinsfilede volgende tijdelijke aanduidingen:
- Vervang en vervang
<user-name>de<repo-name>gebruikersnaam en de naam van de opslagplaats voor uw host door uw git-provider van het derde deel. In dit artikel wordt een GitHub-URL als voorbeeld gebruikt. - Vervang door
<release-branch-name>de naam van de releasebranch in uw opslagplaats. Dit kan bijvoorbeeld zijnmain. - Vervang
<databricks-cli-installation-path>door het pad op uw lokale ontwikkelcomputer waarop de Databricks CLI is geïnstalleerd. In macOS kan dit bijvoorbeeld zijn/usr/local/bin. - Vervang
<jq-installation-path>door het pad op uw lokale ontwikkelcomputer waarjqdeze is geïnstalleerd. In macOS kan dit bijvoorbeeld zijn/usr/local/bin. - Vervang
<job-prefix-name>door een tekenreeks om de Azure Databricks-taken die in uw werkruimte zijn gemaakt, uniek te identificeren voor dit voorbeeld. Dit kan bijvoorbeeld zijnjenkins-demo. - U ziet dat
BUNDLETARGETdit is ingesteld opdev, wat de naam is van het Databricks Asset Bundle-doel dat verderop in dit artikel is gedefinieerd. In echte implementaties zou u dit wijzigen in de naam van uw eigen bundeldoel. Verderop in dit artikel vindt u meer informatie over bundeldoelen.
Dit is de Jenkinsfile, die moet worden toegevoegd aan de hoofdmap van uw opslagplaats:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
In de rest van dit artikel wordt elke fase in deze Jenkins-pijplijn beschreven en wordt beschreven hoe u de artefacten en opdrachten voor Jenkins instelt die in die fase moeten worden uitgevoerd.
Haal de meest recente artefacten op uit de opslagplaats van derden
De eerste fase in deze Jenkins-pijplijn, de Checkout fase, wordt als volgt gedefinieerd:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
In deze fase zorgt u ervoor dat de werkmap die Jenkins gebruikt op uw lokale ontwikkelcomputer de meest recente artefacten uit uw Git-opslagplaats van derden bevat. Jenkins stelt deze werkmap doorgaans in op <your-user-home-directory>/.jenkins/workspace/<pipeline-name>. Hierdoor kunt u op dezelfde lokale ontwikkelcomputer uw eigen kopie van artefacten in ontwikkeling houden, gescheiden van de artefacten die Jenkins gebruikt vanuit uw Git-opslagplaats van derden.
De Databricks-assetbundel valideren
De tweede fase in deze Jenkins Pipeline, de Validate Bundle fase, wordt als volgt gedefinieerd:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
Deze fase zorgt ervoor dat de Databricks Asset Bundle, die de werkstromen voor het testen en uitvoeren van uw artefacten definieert, syntactisch juist is. Databricks Asset Bundles, ook wel bundels genoemd, maken het mogelijk om volledige gegevens, analyses en ML-projecten uit te drukken als een verzameling bronbestanden. Bekijk wat zijn Databricks Asset Bundles?.
Als u de bundel voor dit artikel wilt definiëren, maakt u een bestand met de naam databricks.yml in de hoofdmap van de gekloonde opslagplaats op uw lokale computer. Vervang in dit voorbeeldbestand databricks.yml de volgende tijdelijke aanduidingen:
- Vervang door
<bundle-name>een unieke programmatische naam voor de bundel. Dit kan bijvoorbeeld zijnjenkins-demo. - Vervang
<job-prefix-name>door een tekenreeks om de Azure Databricks-taken die in uw werkruimte zijn gemaakt, uniek te identificeren voor dit voorbeeld. Dit kan bijvoorbeeld zijnjenkins-demo. Deze moet overeenkomen met deJOBPREFIXwaarde in uw Jenkins-bestand. - Vervang
<spark-version-id>bijvoorbeeld door de versie-id van Databricks Runtime voor uw taakclusters13.3.x-scala2.12. - Vervang bijvoorbeeld door
<cluster-node-type-id>de id van het knooppunttype voor uw taakclustersStandard_DS3_v2. - U ziet dat
devin detargetstoewijzing hetzelfde is als inBUNDLETARGETuw Jenkinsfile. Een bundeldoel geeft de host en het gerelateerde implementatiegedrag aan.
Hier volgt het databricks.yml bestand, dat moet worden toegevoegd aan de hoofdmap van uw opslagplaats, zodat dit voorbeeld correct werkt:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: '/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl'
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
Zie de configuratie van Databricks Asset Bundle voor meer informatie over het databricks.yml bestand.
De bundel implementeren in uw werkruimte
De derde fase van de Jenkins Pipeline, getiteld Deploy Bundle, wordt als volgt gedefinieerd:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
In deze fase worden twee dingen uitgevoerd:
- Omdat de
artifacttoewijzing in hetdatabricks.ymlbestand is ingesteld opwhl, geeft dit de Databricks CLI de opdracht om het Python-wielbestand te bouwen met behulp van hetsetup.pybestand op de opgegeven locatie. - Nadat het Python-wielbestand is gebouwd op uw lokale ontwikkelcomputer, implementeert de Databricks CLI het ingebouwde Python-wielbestand samen met de opgegeven Python-bestanden en -notebooks in uw Azure Databricks-werkruimte. Databricks Asset Bundles implementeert standaard het Python-wielbestand en andere bestanden in
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>.
Als u wilt dat het Python-wielbestand kan worden gebouwd zoals opgegeven in het databricks.yml bestand, maakt u de volgende mappen en bestanden in de hoofdmap van uw gekloonde opslagplaats op uw lokale computer.
Als u de logica en de eenheidstests voor het Python-wheel-bestand wilt definiëren waarop het notebook wordt uitgevoerd, maakt u twee bestanden met de naam addcol.py en test_addcol.pyvoegt u deze toe aan een mapstructuur met de naam python/dabdemo/dabdemo in de map van Libraries uw opslagplaats, gevisualiseerd als volgt (weglatingstekens geven weggelaten mappen in de opslagplaats aan voor beknoptheid):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
Het addcol.py bestand bevat een bibliotheekfunctie die later is ingebouwd in een Python-wielbestand en vervolgens is geïnstalleerd op een Azure Databricks-cluster. Het is een eenvoudige functie waarmee een nieuwe kolom, gevuld met een letterlijke kolom, wordt toegevoegd aan een Apache Spark DataFrame:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Het test_addcol.py bestand bevat tests om een gesimuleerd DataFrame-object door te geven aan de with_status functie, gedefinieerd in addcol.py. Het resultaat wordt vervolgens vergeleken met een DataFrame-object met de verwachte waarden. Als de waarden overeenkomen, wat in dit geval het geval is, wordt de test doorgegeven:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Als u wilt dat de Databricks CLI deze bibliotheekcode correct inpakt in een Python-wielbestand, maakt u twee bestanden met de naam __init__.py en __main__.py in dezelfde map als de voorgaande twee bestanden. Maak ook een bestand met de naam setup.py in de python/dabdemo map, gevisualiseerd als volgt (weglatingstekens geven weggelaten mappen aan, ter beknoptheid):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
Het __init__.py bestand bevat het versienummer en de auteur van de bibliotheek. Vervang <my-author-name> door uw naam:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Het __main__.py bestand bevat het toegangspunt van de bibliotheek:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Het setup.py bestand bevat aanvullende instellingen voor het bouwen van de bibliotheek in een Python-wielbestand. Vervang <my-url>, <my-author-name>@<my-organization>en <my-package-description> door zinvolle waarden:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
De componentlogica van het Python-wiel testen
De Run Unit Tests fase, de vierde fase van deze Jenkins Pipeline, gebruikt pytest om de logica van een bibliotheek te testen om ervoor te zorgen dat deze werkt zoals gebouwd. Deze fase wordt als volgt gedefinieerd:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
In deze fase wordt de Databricks CLI gebruikt om een notebooktaak uit te voeren. Met deze taak wordt het Python-notebook uitgevoerd met de bestandsnaam van run-unit-test.py. Dit notebook wordt uitgevoerd pytest op basis van de logica van de bibliotheek.
Als u de eenheidstests voor dit voorbeeld wilt uitvoeren, voegt u een Python-notebookbestand met de naam run_unit_tests.py met de volgende inhoud toe aan de hoofdmap van uw gekloonde opslagplaats op uw lokale computer:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Het ingebouwde Python-wiel gebruiken
De vijfde fase van deze Jenkins-pijplijn, getiteld Run Notebook, voert als volgt een Python-notebook uit die de logica aanroept in het ingebouwde Python-wielbestand:
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
In deze fase wordt de Databricks CLI uitgevoerd, die uw werkruimte op zijn beurt instrueert een notebooktaak uit te voeren. Dit notebook maakt een DataFrame-object, geeft dit door aan de functie van with_status de bibliotheek, drukt het resultaat af en rapporteert de uitvoeringsresultaten van de taak. Maak het notebook door een Python-notebookbestand met de naam toe dabdaddemo_notebook.py te voegen met de volgende inhoud in de hoofdmap van uw gekloonde opslagplaats op uw lokale ontwikkelcomputer:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Resultaten van uitvoering van notebooktaak evalueren
De Evaluate Notebook Runs fase, de zesde fase van deze Jenkins-pijplijn, evalueert de resultaten van de voorgaande uitvoering van de notebooktaak. Deze fase wordt als volgt gedefinieerd:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
In deze fase wordt de Databricks CLI uitgevoerd, waarmee uw werkruimte vervolgens wordt geïnstrueerd om een Python-bestandstaak uit te voeren. Dit Python-bestand bepaalt de fout- en succescriteria voor de uitvoering van de notebooktaak en rapporteert dit mislukte of geslaagde resultaat. Maak een bestand met de naam evaluate_notebook_runs.py met de volgende inhoud in de hoofdmap van de gekloonde opslagplaats op uw lokale ontwikkelcomputer:
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Testresultaten importeren en rapporteren
De zevende fase in deze Jenkins-pijplijn, getiteld Import Test Results, gebruikt de Databricks CLI om de testresultaten van uw werkruimte naar uw lokale ontwikkelcomputer te verzenden. De achtste en laatste fase, getiteld Publish Test Results, publiceert de testresultaten naar Jenkins met behulp van de junit Jenkins-invoegtoepassing. Hiermee kunt u rapporten en dashboards visualiseren die betrekking hebben op de status van de testresultaten. Deze fasen worden als volgt gedefinieerd:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
Alle codewijzigingen naar uw opslagplaats van derden pushen
U moet nu de inhoud van uw gekloonde opslagplaats op uw lokale ontwikkelcomputer pushen naar uw opslagplaats van derden. Voordat u pusht, moet u eerst de volgende vermeldingen toevoegen aan het .gitignore bestand in uw gekloonde opslagplaats, omdat u waarschijnlijk geen interne Databricks Asset Bundle-werkbestanden, validatierapporten, Python-buildbestanden en Python-caches naar uw opslagplaats van derden moet pushen. Normaal gesproken wilt u nieuwe validatierapporten en de laatste Python-wiel-builds opnieuw genereren in uw Azure Databricks-werkruimte, in plaats van mogelijk verouderde validatierapporten en Python-wiel-builds te gebruiken:
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
Uw Jenkins-pijplijn uitvoeren
U bent nu klaar om uw Jenkins Pipeline handmatig uit te voeren. U doet dit via uw Jenkins-dashboard:
- Klik op de naam van uw Jenkins-pijplijn.
- Klik in de zijbalk op Nu bouwen.
- Als u de resultaten wilt zien, klikt u op de meest recente pijplijnuitvoering (bijvoorbeeld
#1) en klikt u vervolgens op Console-uitvoer.
Op dit moment heeft de CI/CD-pijplijn een integratie- en implementatiecyclus voltooid. Door dit proces te automatiseren, kunt u ervoor zorgen dat uw code is getest en geïmplementeerd door een efficiënt, consistent en herhaalbaar proces. Als u uw externe Git-provider wilt instrueren om Jenkins uit te voeren telkens wanneer een specifieke gebeurtenis plaatsvindt, zoals een pull-aanvraag voor een opslagplaats, raadpleegt u de documentatie van uw externe Git-provider.