Continue integratie en levering op Azure Databricks met behulp van Azure DevOps
Notitie
Dit artikel bevat informatie over Azure DevOps, die is ontwikkeld door een derde partij. Als u contact wilt opnemen met de provider, raadpleegt u de ondersteuning van Azure DevOps Services.
In dit artikel wordt u begeleid bij het configureren van Azure DevOps-automatisering voor uw code en artefacten die werken met Azure Databricks. Met name configureert u een CI/CD-werkstroom (continue integratie en levering) om verbinding te maken met een Git-opslagplaats, taken uit te voeren met behulp van Azure Pipelines om een Python-wiel (*.whl) te bouwen en te testen en deze te implementeren voor gebruik in Databricks-notebooks.
Werkstroom voor CI/CD-ontwikkeling
Databricks stelt de volgende werkstroom voor CI/CD-ontwikkeling met Azure DevOps voor:
- Maak een opslagplaats of gebruik een bestaande opslagplaats met uw Externe Git-provider.
- Verbind uw lokale ontwikkelcomputer met dezelfde opslagplaats van derden. Zie de documentatie van uw externe Git-provider voor instructies.
- Haal bestaande bijgewerkte artefacten (zoals notebooks, codebestanden en buildscripts) op naar uw lokale ontwikkelcomputer vanuit de opslagplaats van derden.
- Maak, updateen test indien nodig artefacten op uw lokale ontwikkelcomputer. Push vervolgens nieuwe en gewijzigde artefacten van uw lokale ontwikkelcomputer naar de opslagplaats van derden. Zie de documentatie van uw externe Git-provider voor instructies.
- Herhaal stap 3 en 4 indien nodig.
- Gebruik Azure DevOps periodiek als een geïntegreerde benadering om automatisch artefacten op te halen uit uw opslagplaats van derden, code te bouwen, te testen en uit te voeren in uw Azure Databricks-werkruimte, en test- en uitvoeringsresultaten te rapporteren. Hoewel u Azure DevOps handmatig kunt uitvoeren, moet u in echte implementaties de Git-provider van uw derde partij instrueren Om Azure DevOps uit te voeren telkens wanneer een specifieke gebeurtenis plaatsvindt, zoals een pull-aanvraag voor een opslagplaats.
Er zijn talloze CI/CD-hulpprogramma's die u kunt gebruiken om uw pijplijn te beheren en uit te voeren. In dit artikel wordt uitgelegd hoe u Azure DevOps gebruikt. CI/CD is een ontwerppatroon, dus de stappen en fasen die in het voorbeeld van dit artikel worden beschreven, moeten worden overgedragen met enkele wijzigingen in de taal van de pijplijndefinitie in elk hulpprogramma. Bovendien is veel van de code in deze voorbeeldpijplijn standaard Python-code die kan worden aangeroepen in andere hulpprogramma's.
Tip
Zie CI/CD met Jenkins in Azure Databricks voor informatie over het gebruik van Jenkins met Azure Databricks in plaats van Azure DevOps.
In de rest van dit artikel wordt een paar voorbeeldpijplijnen in Azure DevOps beschreven die u kunt aanpassen aan uw eigen behoeften voor Azure Databricks.
Over het voorbeeld
In dit artikel worden twee pijplijnen gebruikt voor het verzamelen, implementeren en uitvoeren van python-code en Python-notebooks die zijn opgeslagen in een externe Git-opslagplaats.
De eerste pijplijn, ook wel de build-pijplijn genoemd, bereidt buildartefacten voor op de tweede pijplijn, ook wel de release-pijplijn genoemd. Door de build-pijplijn van de release-pijplijn te scheiden, kunt u een build-artefact maken zonder deze te implementeren of artefacten uit meerdere builds tegelijk te implementeren. De build- en release-pijplijnen maken:
- Maak een virtuele Azure-machine voor de build-pijplijn.
- Kopieer de bestanden uit uw Git-opslagplaats naar de virtuele machine.
- Maak een tar-bestand met gzip dat de Python-code, Python-notebooks en gerelateerde build-, implementatie- en uitvoeringsinstellingenbestanden bevat.
- Kopieer het tar-bestand van gzip als een zip-bestand naar een locatie waar de release-pijplijn toegang heeft.
- Maak een andere virtuele Azure-machine voor de release-pijplijn.
- Get het zip-bestand vanaf de locatie van de build-pijplijn en vervolgens het zip-bestand uitpakken om de Python-code, Python-notebooks en gerelateerde build-, implementatie- en uitvoerinstellingenbestanden te get.
- Implementeer de Python-code, Python-notebooks en gerelateerde build-, implementatie- en uitvoeringsinstellingenbestanden naar uw externe Azure Databricks-werkruimte.
- Bouw de componentcodebestanden van de Python-wielbibliotheek in een Python-wielbestand.
- Voer eenheidstests uit op de onderdeelcode om de logica in het Python-wielbestand te controleren.
- Voer de Python-notebooks uit, die de functionaliteit van het Python-wielbestand aanroept.
Over de Databricks CLI
In dit artikel ziet u hoe u de Databricks CLI gebruikt in een niet-interactieve modus binnen een pijplijn. De voorbeeldpijplijn van dit artikel implementeert code, bouwt een bibliotheek en voert notebooks uit in uw Azure Databricks-werkruimte.
Als u de Databricks CLI in uw pijplijn gebruikt zonder de voorbeeldcode, bibliotheek en notebooks uit dit artikel te implementeren, voert u de volgende stappen uit:
Bereid uw Azure Databricks-werkruimte voor om OAuth-M2M-verificatie (machine-to-machine) te gebruiken voor verificatie van een service-principal. Controleer voordat u begint of u een Microsoft Entra ID-service-principal hebt met een Azure Databricks OAuth-geheim. Zie Toegang tot Azure Databricks verifiëren met een service-principal met behulp van OAuth (OAuth M2M).
Installeer de Databricks CLI in uw pijplijn. U doet dit door een Bash-scripttaak toe te voegen aan uw pijplijn waarop het volgende script wordt uitgevoerd:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | shZie stap 3.6 om een Bash-scripttaak toe te voegen aan uw pijplijn. Installeer de hulpprogramma's voor databricks CLI en Python-wielbuild.
Configureer uw pijplijn om de geïnstalleerde Databricks CLI in te schakelen voor het verifiëren van uw service-principal met uw werkruimte. Zie stap 3.1: Omgevingsvariabelen voor de release-pijplijn definiëren om dit te doen.
Voeg zo nodig meer Bash-scripttaken toe aan uw pijplijn om uw Databricks CLI-opdrachten uit te voeren. Zie Databricks CLI-opdrachten.
Voordat u begint
Als u het voorbeeld van dit artikel wilt gebruiken, moet u het volgende hebben:
- Een bestaand Azure DevOps-project . Als u nog geen project hebt, maakt u een project in Azure DevOps.
- Een bestaande opslagplaats met een Git-provider die door Azure DevOps wordt ondersteund. U voegt de Python-voorbeeldcode, het Python-voorbeeldnotebook en gerelateerde release-instellingenbestanden toe aan deze opslagplaats. Als u nog geen opslagplaats hebt, maakt u er een door de instructies van uw Git-provider te volgen. Verbind vervolgens uw Azure DevOps-project met deze opslagplaats als u dit nog niet hebt gedaan. Volg de koppelingen in ondersteunde bronopslagplaatsen voor instructies.
- In het voorbeeld van dit artikel wordt OAuth M2M-verificatie (machine-to-machine) gebruikt om een Microsoft Entra ID-service-principal te verifiëren bij een Azure Databricks-werkruimte. U moet een Microsoft Entra ID-service-principal hebben met een Azure Databricks OAuth-geheim voor die service-principal. Zie Toegang tot Azure Databricks verifiëren met een service-principal met behulp van OAuth (OAuth M2M).
Stap 1: De bestanden van het voorbeeld toevoegen aan uw opslagplaats
In deze stap voegt u in de opslagplaats met uw externe Git-provider alle voorbeeldbestanden van dit artikel toe die uw Azure DevOps-pijplijnen bouwen, implementeren en uitvoeren op uw externe Azure Databricks-werkruimte.
Stap 1.1: De Python wheel-onderdeelbestanden toevoegen
In het voorbeeld van dit artikel testen uw Azure DevOps-pijplijnen een Python-wielbestand en -eenheid. Een Azure Databricks-notebook roept vervolgens de functionaliteit van het ingebouwde Python-wielbestand aan.
Als u de logische en eenheidstests wilt definiëren voor het Python-wielbestand waarop de notebooks worden uitgevoerd, maakt u in de hoofdmap van uw opslagplaats twee bestanden met de naam addcol.py en test_addcol.pyvoegt u deze toe aan een mapstructuur met de naam python/dabdemo/dabdemo in een Libraries map, die als volgt wordt gevisualiseerd:
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
Het addcol.py bestand bevat een bibliotheekfunctie die later is ingebouwd in een Python-wielbestand en vervolgens is geïnstalleerd op Azure Databricks-clusters. Het is een eenvoudige functie waarmee een nieuwe column, gevuld door een letterlijke, aan een Apache Spark DataFrame wordt toegevoegd:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Het test_addcol.py bestand bevat tests om een gesimuleerd DataFrame-object door te geven aan de with_status functie, gedefinieerd in addcol.py. Het resultaat wordt vervolgens vergeleken met een DataFrame-object met de verwachte values. Als values overeenkomt, is de test geslaagd.
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Als u wilt dat de Databricks CLI deze bibliotheekcode correct inpakt in een Python-wielbestand, maakt u twee bestanden met de naam __init__.py en __main__.py in dezelfde map als de voorgaande twee bestanden. Maak ook een bestand met de naam setup.py in de python/dabdemo map, gevisualiseerd als volgt:
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
Het __init__.py bestand bevat het versienummer en de auteur van de bibliotheek. Vervang <my-author-name> door uw naam:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Het __main__.py bestand bevat het toegangspunt van de bibliotheek:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Het setup.py bestand bevat aanvullende instellingen voor het bouwen van de bibliotheek in een Python-wielbestand. Vervang <my-url>, <my-author-name>@<my-organization>en <my-package-description> door geldige values:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Stap 1.2: Een notebook voor het testen van eenheden toevoegen voor het Python-wielbestand
Later voert de Databricks CLI een notebooktaak uit. Met deze taak wordt een Python-notebook uitgevoerd met de bestandsnaam van run_unit_tests.py. Dit notebook wordt uitgevoerd pytest op basis van de logica van de Python-wielbibliotheek.
Als u de eenheidstests voor het voorbeeld van dit artikel wilt uitvoeren, voegt u een notebookbestand met de naam run_unit_tests.py toe aan de hoofdmap van uw opslagplaats met de volgende inhoud:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Stap 1.3: Een notebook toevoegen dat het Python-wielbestand aanroept
Later voert de Databricks CLI een andere notebooktaak uit. Dit notebook maakt een DataFrame-object, geeft dit door aan de functie van with_status de Python-wielbibliotheek, drukt het resultaat af en rapporteert de uitvoeringsresultaten van de taak. Maak de hoofdmap van uw opslagplaats een notebookbestand met de naam dabdemo_notebook.py met de volgende inhoud:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
Stap 1.4: De bundelconfiguratie maken
In dit artikel wordt gebruikgemaakt van Databricks Asset Bundles om de instellingen en het gedrag te definiëren voor het bouwen, implementeren en uitvoeren van het Python-wielbestand, de twee notebooks en het Python-codebestand. Databricks Asset Bundles, ook wel bundels genoemd, maken het mogelijk om volledige gegevens, analyses en ML-projecten uit te drukken als een verzameling bronbestanden. Bekijk wat zijn Databricks Asset Bundles?.
Als u de bundel wilt configureren voor het voorbeeld van dit artikel, maakt u een bestand met de naam databricks.ymlin de hoofdmap van uw opslagplaats. Vervang in dit voorbeeldbestand databricks.yml de volgende tijdelijke aanduidingen:
- Vervang door
<bundle-name>een unieke programmatische naam voor de bundel. Bijvoorbeeld:azure-devops-demo. - Vervang
<job-prefix-name>door een tekenreeks om de taken die in uw Azure Databricks-werkruimte zijn gemaakt, uniek te identificeren voor dit voorbeeld. Bijvoorbeeld:azure-devops-demo. - Vervang
<spark-version-id>bijvoorbeeld door de versie-id van Databricks Runtime voor uw taakclusters13.3.x-scala2.12. - Vervang bijvoorbeeld door
<cluster-node-type-id>de type-id van het clusterknooppunt voor uw taakclustersStandard_DS3_v2. - U ziet dat
devin detargetstoewijzing de host en het gerelateerde implementatiegedrag worden opgegeven. In echte implementaties kunt u dit doel een andere naam geven in uw eigen bundels.
Dit zijn de inhoud van het bestand van dit voorbeeld databricks.yml :
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
targets:
dev:
mode: development
Zie de configuratiedatabricks.ymlvan het bestand.
Stap 2: De build-pijplijn definiëren
Azure DevOps biedt een in de cloud gehoste gebruikersinterface voor het definiëren van de fasen van uw CI/CD-pijplijn met behulp van YAML. Zie de Documentatie voor Azure DevOps voor meer informatie over Azure DevOps en pijplijnen.
In deze stap gebruikt u YAML-markeringen om de build-pijplijn te definiëren, waarmee een implementatieartefact wordt gebouwd. Als u de code wilt implementeren in een Azure Databricks-werkruimte, geeft u het buildartefact van deze pijplijn op als invoer in een release-pijplijn. U definieert deze release-pijplijn later.
Voor het uitvoeren van build-pijplijnen biedt Azure DevOps in de cloud gehoste, on-demand uitvoeringsagents die implementaties ondersteunen voor Kubernetes, VM's, Azure Functions, Azure Web Apps en nog veel meer doelen. In dit voorbeeld gebruikt u een agent op aanvraag om het bouwen van het implementatieartefact te automatiseren.
Definieer de voorbeeld-build-pijplijn van dit artikel als volgt:
Meld u aan bij Azure DevOps en klik vervolgens op de koppeling Aanmelden om uw Azure DevOps-project te openen.
Notitie
Als Azure Portal wordt weergegeven in plaats van uw Azure DevOps-project, klikt u op Meer services > van Azure DevOps-organisaties Mijn Azure DevOps-organisaties > en opent u vervolgens uw Azure DevOps-project.
Klik op Pijplijnen in de zijbalk en klik vervolgens op Pijplijnen in het menu Pijplijnen.
Klik op de knop Nieuwe pijplijn en volg de instructies op het scherm. (Als u al pijplijnen hebt, klikt u op Maak in plaats daarvan pijplijn .) Aan het einde van deze instructies wordt de pijplijneditor geopend. Hier definieert u het build-pijplijnscript in het
azure-pipelines.ymlbestand dat wordt weergegeven. Als de pijplijneditor niet zichtbaar is aan het einde van de instructies, select de naam van de build-pijplijn en klikt u vervolgens op Bewerken.U kunt de Git-vertakkingkiezer
 gebruiken om het buildproces voor elke vertakking in uw Git-opslagplaats aan te passen. Het is een best practice voor CI/CD om geen productiewerkzaamheden rechtstreeks in de vertakking van
gebruiken om het buildproces voor elke vertakking in uw Git-opslagplaats aan te passen. Het is een best practice voor CI/CD om geen productiewerkzaamheden rechtstreeks in de vertakking van mainuw opslagplaats uit te voeren. In dit voorbeeld wordt ervan uitgegaan dat er een vertakking met de naamreleasebestaat in de opslagplaats die moet worden gebruikt in plaats vanmain.
Het
azure-pipelines.ymlscript voor de build-pijplijn wordt standaard opgeslagen in de hoofdmap van de externe Git-opslagplaats die u aan de pijplijn koppelt.Overschrijf de startersinhoud van het bestand van
azure-pipelines.ymluw pijplijn met de volgende definitie en klik vervolgens op Opslaan.# Specify the trigger event to start the build pipeline. # In this case, new code merged into the release branch initiates a new build. trigger: - release # Specify the operating system for the agent that runs on the Azure virtual # machine for the build pipeline (known as the build agent). The virtual # machine image in this example uses the Ubuntu 22.04 virtual machine # image in the Azure Pipeline agent pool. See # https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software pool: vmImage: ubuntu-22.04 # Download the files from the designated branch in the remote Git repository # onto the build agent. steps: - checkout: self persistCredentials: true clean: true # Generate the deployment artifact. To do this, the build agent gathers # all the new or updated code to be given to the release pipeline, # including the sample Python code, the Python notebooks, # the Python wheel library component files, and the related Databricks asset # bundle settings. # Use git diff to flag files that were added in the most recent Git merge. # Then add the files to be used by the release pipeline. # The implementation in your pipeline will likely be different. # The objective here is to add all files intended for the current release. - script: | git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory) mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory) displayName: 'Get Changes' # Create the deployment artifact and then publish it to the # artifact repository. - task: ArchiveFiles@2 inputs: rootFolderOrFile: '$(Build.BinariesDirectory)' includeRootFolder: false archiveType: 'zip' archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip' replaceExistingArchive: true - task: PublishBuildArtifacts@1 inputs: ArtifactName: 'DatabricksBuild'
Stap 3: De release-pijplijn definiëren
De release-pijplijn implementeert de buildartefacten van de build-pijplijn naar een Azure Databricks-omgeving. Als u de release-pijplijn in deze stap scheidt van de build-pijplijn in de voorgaande stappen, kunt u een build maken zonder deze te implementeren of artefacten uit meerdere builds tegelijk te implementeren.
Klik in uw Azure DevOps-project in het menu Pijplijnen in de zijbalk op Releases.
Klik op Nieuwe > nieuwe release-pijplijn. (Als u al pijplijnen hebt, klikt u op Nieuwe pijplijn in plaats daarvan .)
Aan de zijkant van het scherm bevindt zich een list van aanbevolen sjablonen voor algemene implementatiepatronen. Klik voor dit voorbeeld van een release-pijplijn op
 .
.
Klik in het vak ArtefactenAdd aan de zijkant van het scherm op . Voeg in het deelvenster Een artefact toevoegen voor bron (build-pijplijn)select de build-pijplijn die u eerder hebt gemaakt. Klik vervolgens op Toevoegen.
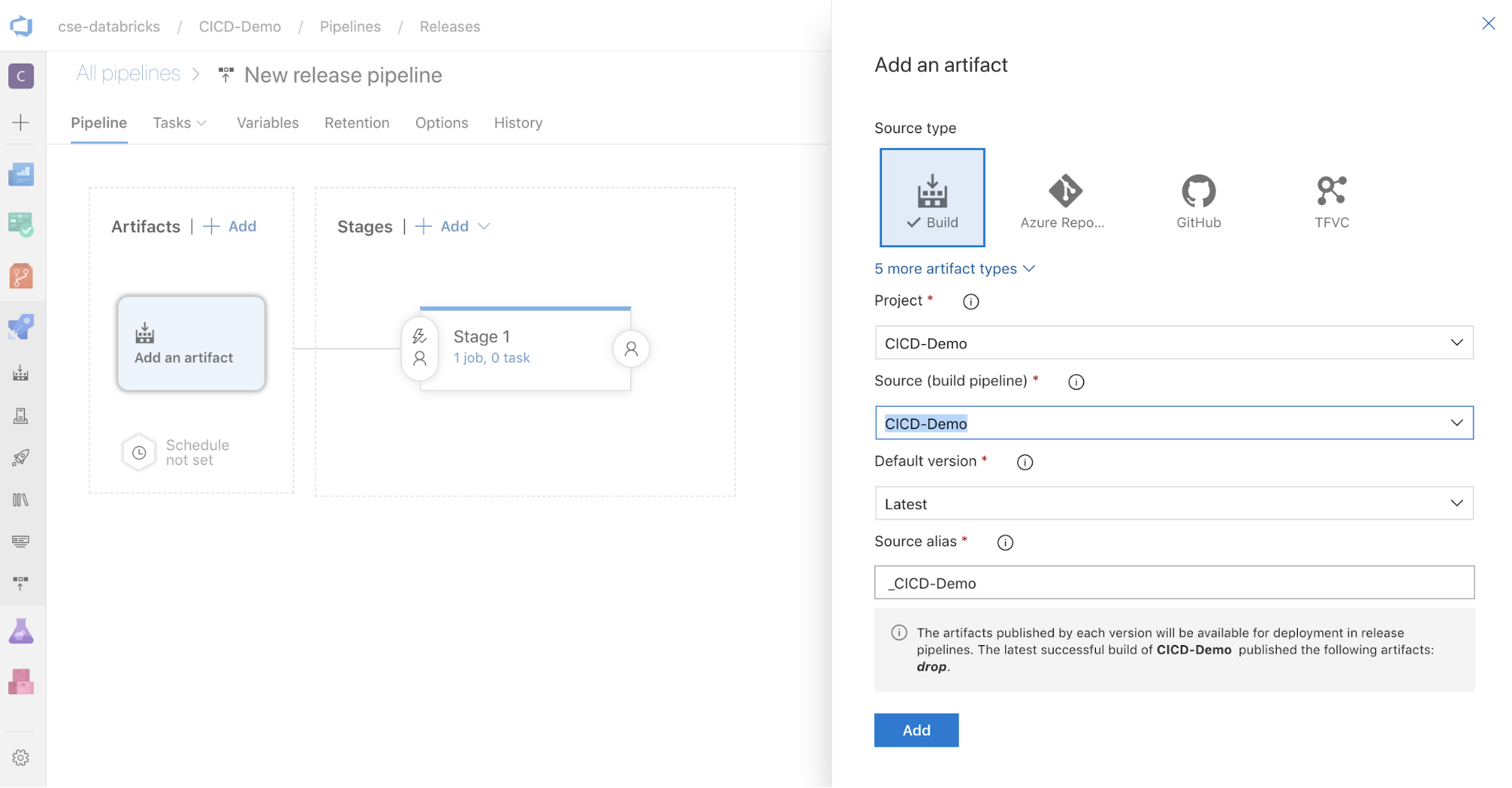
U kunt configureren hoe de pijplijn wordt geactiveerd door te klikken
 om triggeropties aan de zijkant van het scherm weer te geven. Als u wilt dat een release automatisch wordt gestart op basis van de beschikbaarheid van buildartefacten of na een werkstroom voor pull-aanvragen, schakelt u de juiste trigger in. In dit voorbeeld in dit voorbeeld activeert u in de laatste stap van dit artikel handmatig de build-pijplijn en vervolgens de release-pijplijn.
om triggeropties aan de zijkant van het scherm weer te geven. Als u wilt dat een release automatisch wordt gestart op basis van de beschikbaarheid van buildartefacten of na een werkstroom voor pull-aanvragen, schakelt u de juiste trigger in. In dit voorbeeld in dit voorbeeld activeert u in de laatste stap van dit artikel handmatig de build-pijplijn en vervolgens de release-pijplijn.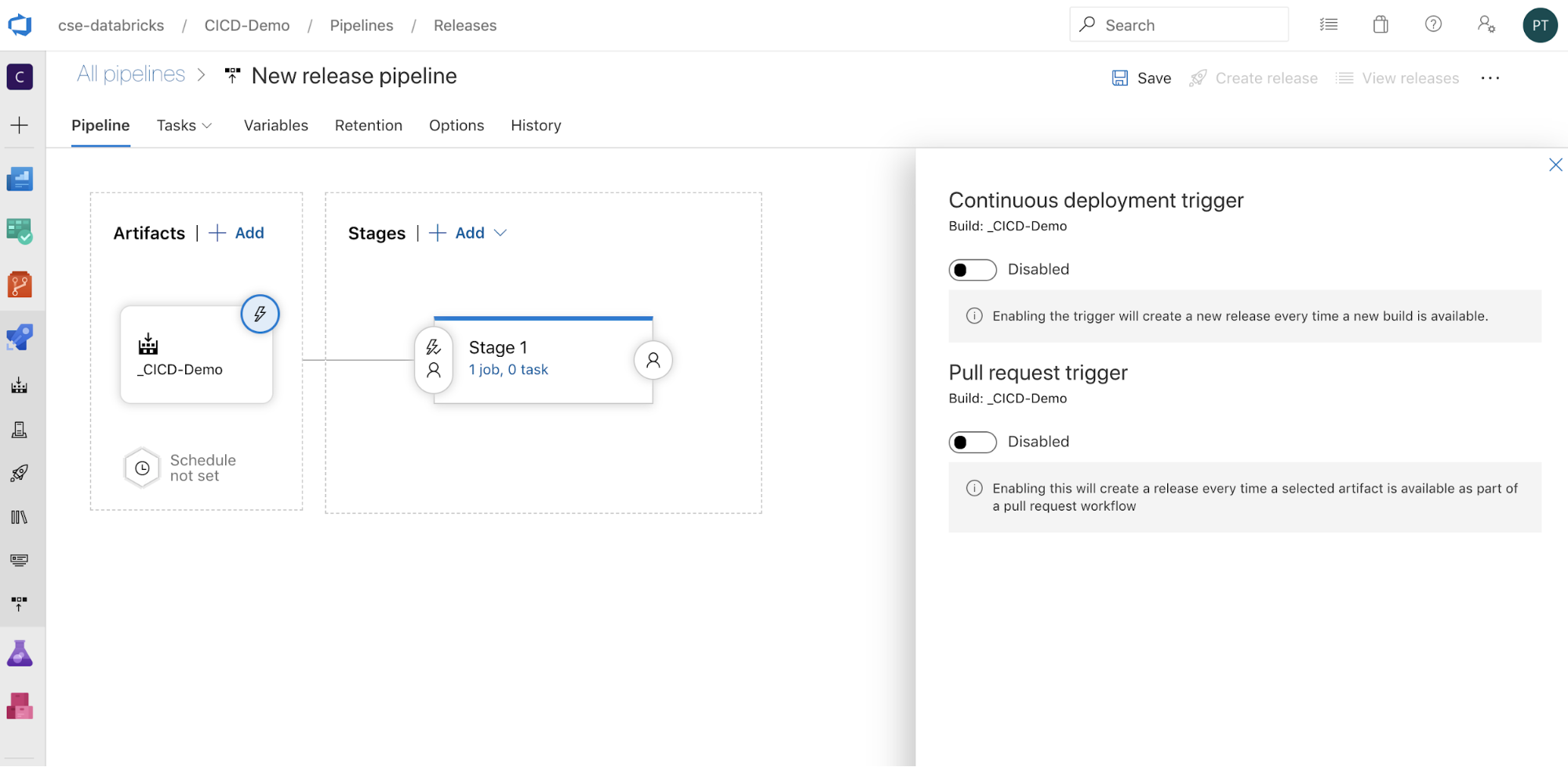
Klik op > opslaan.
Stap 3.1: Omgevingsvariabelen definiëren voor de release-pijplijn
De release-pijplijn van dit voorbeeld is afhankelijk van de volgende omgevingsvariabelen, die u kunt toevoegen door te klikken op Toevoegen in de sectie Pijplijnvariabelen op het tabblad Variabelen, met een bereik van fase 1:
-
BUNDLE_TARGET, die moet overeenkomen met detargetnaam in uwdatabricks.ymlbestand. In het voorbeeld van dit artikel isdevdit . -
DATABRICKS_HOST, dat de . Neem de afsluitende navolging/niet op.net. -
DATABRICKS_CLIENT_ID, dat de toepassings-id vertegenwoordigt voor de Service-principal van Microsoft Entra ID. -
DATABRICKS_CLIENT_SECRET, dat het Azure Databricks OAuth-geheim vertegenwoordigt voor de Service-principal van Microsoft Entra ID.
Stap 3.2: De releaseagent voor de release-pijplijn configureren
Klik op de taak 1 taakkoppeling, 0 taak in het object Fase 1 .
Klik op het tabblad Taken op Agent-taak.
In de sectie Agentselectie voor Agent-poolselectAzure Pipelines.
Voor agentspecificatieselect dezelfde agent als die u eerder hebt opgegeven voor de buildagent, in dit voorbeeld ubuntu-22.04.
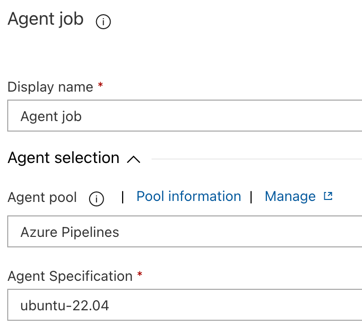
Klik op > opslaan.
Stap 3.3: Set de Python-versie voor de releaseagent
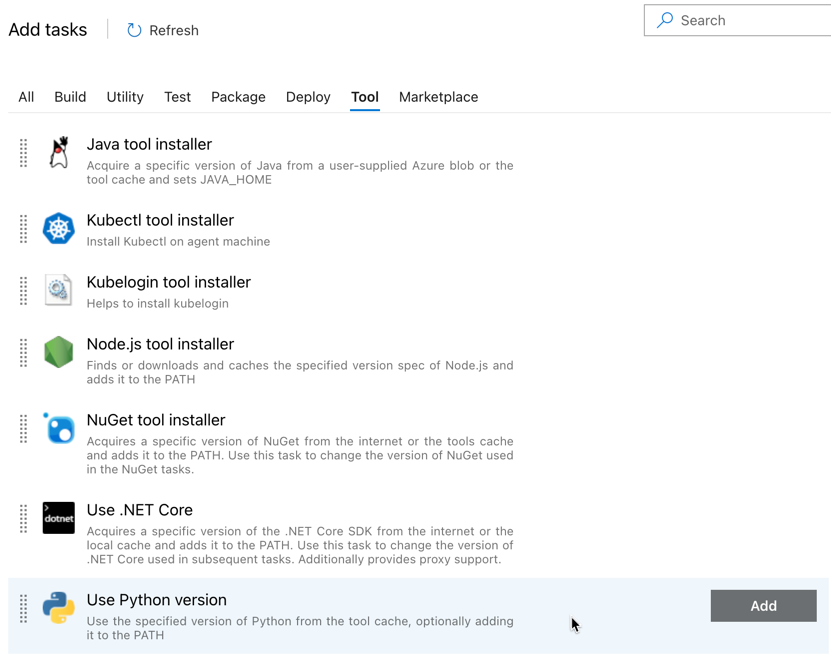
Klik op het plusteken in de sectie Agenttaak , aangegeven met de rode pijl in de volgende afbeelding. Er wordt een doorzoekbare list met beschikbare taken weergegeven. Er is ook een Marketplace-tabblad voor invoegtoepassingen van derden die kunnen worden gebruikt om de standaard Azure DevOps-taken aan te vullen. Tijdens de volgende stappen voegt u verschillende taken toe aan de releaseagent.
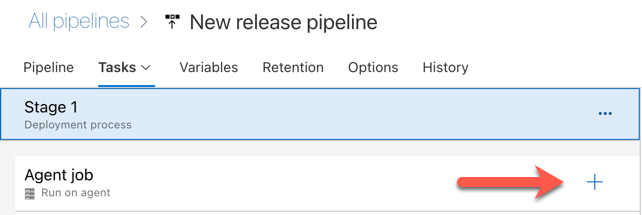
De eerste taak die u toevoegt, is Python-versie gebruiken op het tabblad Hulpprogramma. Als u deze taak niet kunt vinden, gebruikt u het zoekvak om deze te zoeken. Wanneer u deze vindt, select u deze en klikt u vervolgens op de knop Toevoegen naast de Python-versie taak gebruiken.
Net als bij de build-pijplijn wilt u ervoor zorgen dat de Python-versie compatibel is met de scripts die in de volgende taken worden aangeroepen. Klik in dit geval op de Python 3.x taak naast Agent-taakgebruiken en setversiespecificatie om
3.10te3.10. Ook setweergavenaam naarUse Python 3.10. In deze pijplijn wordt ervan uitgegaan dat u Databricks Runtime 13.3 LTS gebruikt op de clusters waarop Python 3.10.12 is geïnstalleerd.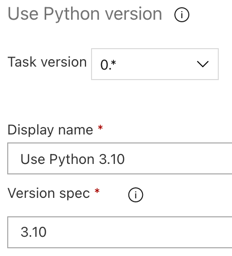
Klik op > opslaan.
Stap 3.4: Het buildartefact uitpakken vanuit de build-pijplijn
Laat vervolgens de releaseagent het Python-wielbestand, gerelateerde release-instellingenbestanden, de notebooks en het Python-codebestand uit het zip-bestand extraheren met behulp van de bestanden extraheren taak: klik op het plusteken in de sectie Agent-taak, select de bestanden extraheren taak op het tabblad Hulpprogramma, en klik vervolgens op Toevoegen.
Klik op de Bestanden extraheren taak naast Agent-taak, setBestandspatronen archiveren om te
**/*.zipen set de map Doel naar de systeemvariabele$(Release.PrimaryArtifactSourceAlias)/Databricks. Ook setweergavenaam naarExtract build pipeline artifact.Notitie
$(Release.PrimaryArtifactSourceAlias)vertegenwoordigt een door Azure DevOps gegenereerde alias voor het identificeren van de primaire artefactbronlocatie op de releaseagent, bijvoorbeeld_<your-github-alias>.<your-github-repo-name>. Met de release-pijplijn wordt deze waarde ingesteld als de omgevingsvariabeleRELEASE_PRIMARYARTIFACTSOURCEALIASin de fase Initialize-taak voor de releaseagent. Zie klassieke variabelen voor release en artefacten.Set weergavenaam van tot
Extract build pipeline artifact.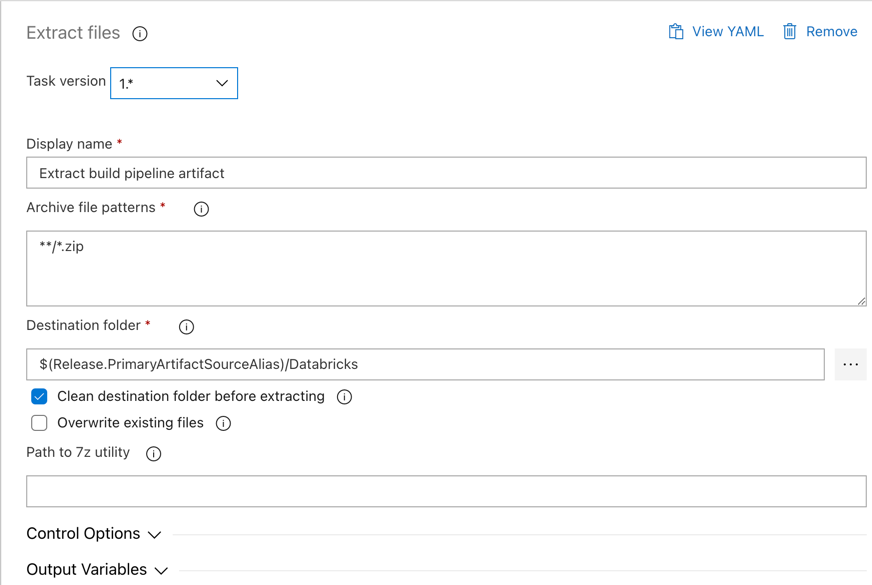
Klik op > opslaan.
Stap 3.5: Set de omgevingsvariabele BUNDLE_ROOT
Als u wilt dat het voorbeeld van dit artikel werkt zoals verwacht, moet u set een omgevingsvariabele met de naam BUNDLE_ROOT in de release-pijplijn. Databricks Asset Bundles gebruikt deze omgevingsvariabele om te bepalen waar zich where het databricks.yml bestand bevindt. Voor de omgevingsvariabele set, ga als volgt te werk:
Gebruik de omgevingsvariabelen taak: klik nogmaals op het plusteken in de sectie agenttaak, select de omgevingsvariabelen taak op het tabblad Hulpprogramma en klik vervolgens op toevoegen.
Notitie
Als de omgevingsvariabelen taak niet zichtbaar is op het tabblad Hulpprogramma, voert u
Environment Variablesin het vak Zoeken in en volgt u de instructies op het scherm om de taak toe te voegen aan het tabblad Hulpprogramma. Hiervoor moet u Azure DevOps mogelijk verlaten en vervolgens terugkeren naar deze locatie where u was gebleven.Voer voor omgevingsvariabelen (door komma's gescheiden) de volgende definitie in:
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/Databricks.Notitie
$(Agent.ReleaseDirectory)vertegenwoordigt een door Azure DevOps gegenereerde alias om de locatie van de releasemap op de releaseagent te identificeren, bijvoorbeeld/home/vsts/work/r1/a. Met de release-pijplijn wordt deze waarde ingesteld als de omgevingsvariabeleAGENT_RELEASEDIRECTORYin de fase Initialize-taak voor de releaseagent. Zie klassieke variabelen voor release en artefacten. Zie de opmerking in de vorige stap voor meer informatie$(Release.PrimaryArtifactSourceAlias).Set weergavenaam van tot
Set BUNDLE_ROOT environment variable.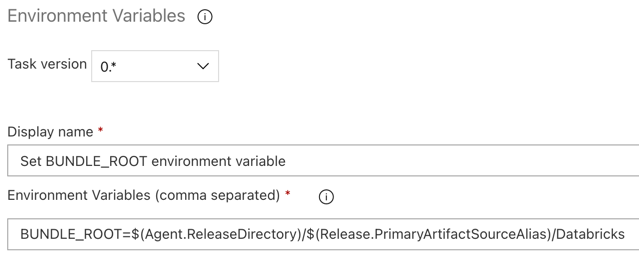
Klik op > opslaan.
Stap 3.6. De hulpprogramma's voor het bouwen van databricks CLI en Python-wiel installeren
Installeer vervolgens de databricks CLI en python wheel build-hulpprogramma's op de releaseagent. De releaseagent roept de Databricks CLI en Python wheel build-hulpprogramma's aan in de volgende paar taken. Als u dit wilt doen, gebruikt u de
Bash-taak : klik nogmaals op het plusteken in de sectieagenttaak, de Bash- taak op het tabbladUtility en klik vervolgens opToevoegen .Klik op de Bash-scripttaak naast agenttaak.
Voor Typ, selectInline-.
Vervang de inhoud van Script door de volgende opdracht, waarmee de Hulpprogramma's voor databricks CLI en Python wheel build worden geïnstalleerd:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh pip install wheelSet weergavenaam van tot
Install Databricks CLI and Python wheel build tools.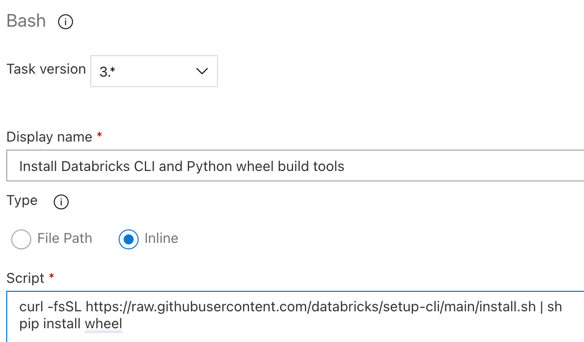
Klik op > opslaan.
Stap 3.7: De Databricks-assetbundel valideren
In deze stap zorgt u ervoor dat het databricks.yml bestand syntactisch juist is.
Gebruik de
Bash taak: klik nogmaals op het plusteken in de sectie agenttaakagent, de taak Bash op het tabbladUtility en klik vervolgens op Toevoegen .Klik op de Bash-scripttaak naast agenttaak.
Voor Typ, selectInline-.
Vervang de inhoud van Script door de volgende opdracht, die de Databricks CLI gebruikt om te controleren of het
databricks.ymlbestand syntactisch juist is:databricks bundle validate -t $(BUNDLE_TARGET)Set weergavenaam van tot
Validate bundle.Klik op > opslaan.
Stap 3.8: De bundel implementeren
In deze stap bouwt u het Python-wielbestand en implementeert u het ingebouwde Python-wielbestand, de twee Python-notebooks en het Python-bestand van de release-pijplijn naar uw Azure Databricks-werkruimte.
Gebruik de
Bash taak: klik nogmaals op het plusteken in de sectie agenttaakagent, de taak Bash op het tabbladUtility en klik vervolgens op Toevoegen .Klik op de Bash-scripttaak naast agenttaak.
Voor Typ, selectInline-.
Vervang de inhoud van Script door de volgende opdracht, die de Databricks CLI gebruikt om het Python-wielbestand te bouwen en de voorbeeldbestanden van dit artikel uit de release-pijplijn te implementeren in uw Azure Databricks-werkruimte:
databricks bundle deploy -t $(BUNDLE_TARGET)Set weergavenaam van tot
Deploy bundle.Klik op > opslaan.
Stap 3.9: Voer het eenheidstestnotebook uit voor het Python-wiel
In deze stap voert u een taak uit waarmee het eenheidstestnotebook in uw Azure Databricks-werkruimte wordt uitgevoerd. Met dit notebook worden eenheidstests uitgevoerd op basis van de logica van de Python-wielbibliotheek.
Gebruik de
Bash taak: klik nogmaals op het plusteken in de sectie agenttaakagent, de taak Bash op het tabbladUtility en klik vervolgens op Toevoegen .Klik op de Bash-scripttaak naast agenttaak.
Voor Typ, selectInline-.
Vervang de inhoud van Script door de volgende opdracht, die de Databricks CLI gebruikt om de taak uit te voeren in uw Azure Databricks-werkruimte:
databricks bundle run -t $(BUNDLE_TARGET) run-unit-testsSet weergavenaam van tot
Run unit tests.Klik op > opslaan.
Stap 3.10: Voer het notebook uit dat het Python-wiel aanroept
In deze stap voert u een taak uit die een ander notebook uitvoert in uw Azure Databricks-werkruimte. Dit notebook roept de Python-wielbibliotheek aan.
Gebruik de
Bash taak: klik nogmaals op het plusteken in de sectie agenttaakagent, de taak Bash op het tabbladUtility en klik vervolgens op Toevoegen .Klik op de Bash-scripttaak naast agenttaak.
Voor Typ, selectInline-.
Vervang de inhoud van Script door de volgende opdracht, die de Databricks CLI gebruikt om de taak uit te voeren in uw Azure Databricks-werkruimte:
databricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebookSet weergavenaam van tot
Run notebook.Klik op > opslaan.
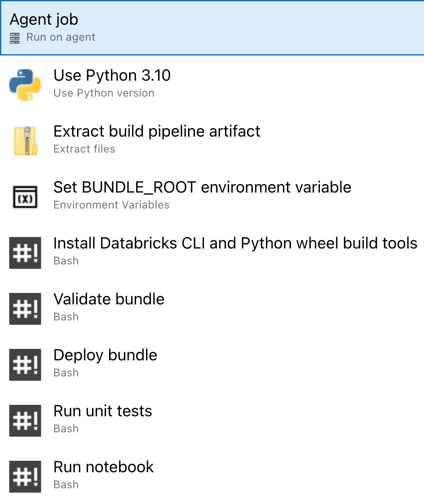
U bent nu klaar met het configureren van uw release-pijplijn. Dit moet er als volgt uitzien:
Stap 4: De build- en release-pijplijnen uitvoeren
In deze stap voert u de pijplijnen handmatig uit. Zie Gebeurtenissen opgeven waarmee pijplijnen en releasetriggers worden geactiveerd voor meer informatie over het automatisch uitvoeren van de pijplijnen.
De build-pijplijn handmatig uitvoeren:
- Klik in het menu Pijplijnen in de zijbalk op Pijplijnen.
- Klik op de naam van de build-pijplijn en klik vervolgens op Pijplijn uitvoeren.
- De naam van de branch/tag in uw Git-opslagplaats, select, bevat alle broncode die u hebt toegevoegd. In dit voorbeeld wordt ervan uitgegaan dat dit zich in de
releasevertakking bevindt. - Klik op Uitvoeren . De uitvoeringspagina van de build-pijplijn wordt weergegeven.
- Als u de voortgang van de build-pijplijn wilt zien en de gerelateerde logboeken wilt bekijken, klikt u op het draaiende pictogram naast Taak.
- Nadat het taakpictogram is omgedraaid naar een groen vinkje, gaat u verder met het uitvoeren van de release-pijplijn.
De release-pijplijn handmatig uitvoeren:
- Nadat de build-pijplijn is uitgevoerd, klikt u in het menu Pijplijnen in de zijbalk op Releases.
- Klik op de naam van de release-pijplijn en klik vervolgens op Release maken.
- Klik op Create.
- Als u de voortgang van de release-pijplijn wilt zien, klikt u in het list van releases op de naam van de meest recente release.
- Klik in het vak Fasen op Fase 1 en klik op Logboeken.