Wat is DLT?
Notitie
DLT vereist het Premium-abonnement. Neem contact op met uw Databricks-accountteam voor meer informatie.
DLT is een declaratief framework dat is ontworpen om het maken van betrouwbare en onderhoudbare ETL-pijplijnen (extract, transform and load) te vereenvoudigen. U geeft op welke gegevens moeten worden opgenomen en hoe deze moeten worden getransformeerd, en DLT automatiseert belangrijke aspecten van het beheren van uw gegevenspijplijn, waaronder indeling, rekenbeheer, bewaking, afdwinging van gegevenskwaliteit en foutafhandeling.
DLT is gebaseerd op Apache Spark, maar in plaats van uw gegevenspijplijnen te definiëren met behulp van een reeks afzonderlijke Apache Spark-taken, definieert u streamingtabellen en gerealiseerde weergaven die het systeem moet maken en de query's die nodig zijn om deze streamingtabellen en gerealiseerde weergaven te vullen en bij te werken.
Zie de DLT-productpaginavoor meer informatie over de voordelen van het bouwen en uitvoeren van uw ETL-pijplijnen met DLT.
voordelen van DLT vergeleken met Apache Spark
Apache Spark is een veelzijdige opensource unified analytics-engine, waaronder ETL. DLT bouwt voort op Spark om specifieke en algemene ETL-verwerkingstaken aan te pakken. DLT kan uw pad naar productie aanzienlijk versnellen wanneer uw vereisten deze verwerkingstaken omvatten, waaronder:
- Gegevens opnemen uit typische bronnen.
- Gegevens incrementeel transformeren.
- Het uitvoeren van het vastleggen van wijzigingsgegevens (CDC).
DLT is echter niet geschikt voor het implementeren van bepaalde typen procedurele logica. Verwerkingsvereisten zoals schrijven naar een externe tabel of het opnemen van een voorwaarde die werkt op externe bestandsopslag of databasetabellen, kunnen bijvoorbeeld niet worden uitgevoerd in de code die een DLT-gegevensset definieert. Als u verwerking wilt implementeren die niet wordt ondersteund door DLT, raadt Databricks u aan Apache Spark te gebruiken of de pijplijn op te geven in een Databricks-taak die de verwerking in een afzonderlijke taaktaak uitvoert. Zie DLT-pijplijntaak voor opdrachten.
De volgende tabel vergelijkt DLT met Apache Spark:
| Vermogen | DLT | Apache Spark |
|---|---|---|
| Gegevenstransformaties | U kunt gegevens transformeren met BEHULP van SQL of Python. | U kunt gegevens transformeren met behulp van SQL, Python, Scala of R. |
| Incrementele gegevensverwerking | Veel gegevenstransformaties worden automatisch incrementeel verwerkt. | U moet bepalen welke gegevens nieuw zijn, zodat u deze incrementeel kunt verwerken. |
| Orkestratie | Transformaties worden automatisch in de juiste volgorde ingedeeld. | U moet ervoor zorgen dat verschillende transformaties in de juiste volgorde worden uitgevoerd. |
| Parallellisme | Alle transformaties worden uitgevoerd met het juiste parallelle uitvoeringsniveau. | U moet threads of een externe orchestrator gebruiken om niet-gerelateerde transformaties parallel uit te voeren. |
| Foutafhandeling | Fouten worden automatisch opnieuw geprobeerd. | U moet beslissen hoe u fouten en nieuwe pogingen kunt afhandelen. |
| Toezicht | Metrische gegevens en gebeurtenissen worden automatisch geregistreerd. | U moet code schrijven om metrische gegevens te verzamelen over uitvoering of gegevenskwaliteit. |
belangrijkste concepten van DLT
In de volgende afbeelding ziet u de belangrijke onderdelen van een DLT-pijplijn, gevolgd door een uitleg van elke pijplijn.
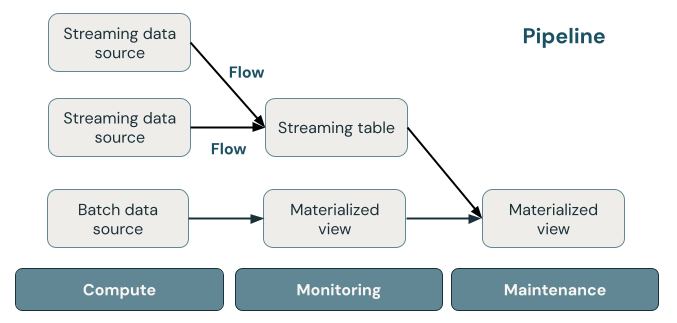
streamingtabel
Een streamingtabel is een Delta-tabel met een of meer streams die ernaar schrijven. Streamingtabellen worden vaak gebruikt voor opname omdat ze invoergegevens precies één keer verwerken en grote hoeveelheden toevoeggegevens kunnen verwerken. Streamingtabellen zijn ook handig voor transformatie met lage latentie van gegevensstromen met een hoog volume.
Gerealiseerde weergave
Een gerealiseerde weergave is een weergave die vooraf samengestelde records bevat op basis van de query waarmee de gerealiseerde weergave wordt gedefinieerd. De records in de gerealiseerde weergave worden automatisch bijgewerkt door DLT op basis van het updateschema of de triggers van de pijplijn. Telkens wanneer een gerealiseerde weergave wordt bijgewerkt, heeft deze gegarandeerd dezelfde resultaten als het uitvoeren van de definitiequery op de meest recente gegevens die beschikbaar zijn. Dit wordt echter vaak gedaan zonder het volledige resultaat vanaf nul te berekenen met behulp van incrementele verversing. Gematerialiseerde weergaven worden vaak gebruikt voor transformaties.
Weergaven
Alle weergaven in Azure Databricks ontstaan uit de rekenresultaten van brongegevenssets wanneer ze worden opgevraagd, waarbij gebruik wordt gemaakt van optimalisaties voor caching indien beschikbaar. DLT publiceert geen views in de catalogus, dus kan alleen naar views worden verwezen in de pijplijn waarin ze zijn gedefinieerd. Weergaven zijn handig als tussenliggende query's die niet zichtbaar moeten zijn voor eindgebruikers of systemen. Databricks raadt aan om weergaven te gebruiken om beperkingen van gegevenskwaliteit af te dwingen of gegevenssets te transformeren en verrijken die meerdere downstreamquery's stimuleren.
Pijpleiding
Een pijplijn is een verzameling streaming-tabellen en gematerialiseerde weergaven die samen worden bijgewerkt. Deze streamingtabellen en gerealiseerde weergaven worden gedeclareerd in Python- of SQL-bronbestanden. Een pijplijn bevat ook een configuratie waarmee de berekening wordt gedefinieerd die wordt gebruikt om de streamingtabellen en gerealiseerde weergaven bij te werken wanneer de pijplijn wordt uitgevoerd. Net als bij de manier waarop een Terraform-sjabloon de infrastructuur in uw cloudaccount definieert, definieert een DLT-pijplijn de gegevenssets en transformaties voor uw gegevensverwerking.
Hoe verwerken DLT-gegevenssets gegevens?
In de volgende tabel wordt uiteengezet hoe gematerialiseerde weergaven, streamingtabellen en weergaven gegevens verwerken:
| Gegevenssettype | Hoe worden records verwerkt via gedefinieerde query's? |
|---|---|
| Streamingtabel | Elke record wordt precies één keer verwerkt. Hierbij wordt ervan uitgegaan dat er een alleen-toevoegen bron is. |
| Gerealiseerde weergave | Records worden naar behoefte verwerkt om nauwkeurige resultaten te retourneren voor de huidige gegevensstatus. Gematerialiseerde weergaven moeten worden gebruikt voor gegevensverwerkingstaken, zoals transformaties, aggregaties, of het vooraf berekenen van trage queries en veelgebruikte berekeningen. |
| Bekijken | Records worden elke keer verwerkt wanneer de weergave wordt opgevraagd. Gebruik weergaven voor tussenliggende transformaties en controles van gegevenskwaliteit die niet mogen worden gepubliceerd naar openbare gegevenssets. |
Uw eerste gegevenssets declareren in DLT
DLT introduceert nieuwe syntaxis voor Python en SQL. Zie Pijplijncode ontwikkelen met Python en Pijplijncode ontwikkelen met SQLvoor meer informatie over de basisbeginselen van de pijplijnsyntaxis.
Notitie
DLT scheidt gegevenssetdefinities van updateverwerking en DLT-notebooks zijn niet bedoeld voor interactieve uitvoering.
Hoe configureert u DLT-pijplijnen?
De instellingen voor DLT-pijplijnen zijn onderverdeeld in twee algemene categorieën:
- Configuraties waarmee een verzameling notebooks of bestanden (ook wel broncodegenoemd) wordt gedefinieerd die gebruikmaken van DLT-syntaxis om gegevenssets te declareren.
- Configuraties voor het beheren van de pijplijninfrastructuur, afhankelijkheidsbeheer, hoe updates worden verwerkt en hoe tabellen worden opgeslagen in de werkruimte.
De meeste configuraties zijn optioneel, maar sommige vereisen zorgvuldige aandacht, met name bij het configureren van productiepijplijnen. Deze omvatten het volgende:
- Als u gegevens buiten de pijplijn beschikbaar wilt maken, moet u een doelschema declareren om te publiceren naar de Hive-metastore of een doelcatalogus en doelschema om te publiceren naar Unity Catalog.
- Machtigingen voor gegevenstoegang worden geconfigureerd via het cluster dat wordt gebruikt voor uitvoering. Zorg ervoor dat uw cluster de juiste machtigingen heeft geconfigureerd voor gegevensbronnen en de doelopslaglocatie , indien opgegeven.
Zie voor meer informatie over het gebruik van Python en SQL voor het schrijven van broncode voor pijplijnen DLT SQL-taalreferenties en DLT Python-taalreferentie.
Zie Een DLT-pijplijn configurerenvoor meer informatie over pijplijninstellingen en -configuraties.
Uw eerste pijplijn uitrollen en updates activeren.
Voordat u gegevens met DLT verwerkt, moet u een pijplijn configureren. Nadat een pijplijn is geconfigureerd, kunt u een update activeren om de resultaten voor elke gegevensset in uw pijplijn te berekenen. Om aan de slag te gaan met DLT-pijplijnen, zie Zelfstudie: Voer je eerste DLT-pijplijn uit.
Wat is een pijplijnupdate?
Pijplijnen implementeren infrastructuur en hercomputeren de gegevensstatus wanneer u een updatestart. Een update doet het volgende:
- Hiermee start u een cluster met de juiste configuratie.
- Detecteert alle tabellen en weergaven die zijn gedefinieerd en controleert op analysefouten, zoals ongeldige kolomnamen, ontbrekende afhankelijkheden en syntaxisfouten.
- Hiermee worden tabellen en weergaven gemaakt of bijgewerkt met de meest recente gegevens die beschikbaar zijn.
Pijplijnen kunnen continu of volgens een schema worden uitgevoerd, afhankelijk van de kosten- en latentievereisten van uw use-case. Zie Een update uitvoeren op een DLT-pijplijn.
gegevens opnemen met DLT
DLT ondersteunt alle gegevensbronnen die beschikbaar zijn in Azure Databricks.
Databricks raadt aan gebruik te maken van streamingtabellen voor de meeste gebruikssituaties van gegevensopname. Voor bestanden die binnenkomen in de opslag van cloudobjecten, raadt Databricks Auto Loader aan. U kunt rechtstreeks gegevens opnemen met DLT vanuit de meeste berichtenbussen.
Zie cloudopslagconfiguratievoor meer informatie over het configureren van toegang tot cloudopslag.
Voor indelingen die niet worden ondersteund door Auto Loader, kunt u Python of SQL gebruiken om een query uit te voeren op elke indeling die wordt ondersteund door Apache Spark. Zie Gegevens laden met DLT-.
Gegevenskwaliteit bewaken en afdwingen
U kunt verwachtingen gebruiken om kwaliteitscontroles voor gegevens op te geven voor de inhoud van een dataset. In tegenstelling tot een CHECK-restrictie in een traditionele database, die voorkomt dat je records toevoegt die niet aan de restrictie voldoen, bieden verwachtingen flexibiliteit bij het verwerken van gegevens die niet aan de vereisten voor gegevenskwaliteit voldoen. Dankzij deze flexibiliteit kunt u gegevens verwerken en opslaan die u verwacht rommelig te zijn en gegevens die moeten voldoen aan strenge kwaliteitsnormen. Zie Gegevenskwaliteit beheren met de verwachtingen van pijplijnen.
Hoe zijn DLT en Delta Lake gerelateerd?
DLT breidt de functionaliteit van Delta Lake uit. Omdat tabellen die zijn gemaakt en beheerd door DLT Delta-tabellen zijn, hebben ze dezelfde garanties en functies van Delta Lake. Zie Wat is Delta Lake?.
DLT voegt verschillende tabeleigenschappen toe naast de vele tabeleigenschappen die kunnen worden ingesteld in Delta Lake. Zie referentie van DLT-eigenschappen en referentie van Delta-tabeleigenschappen.
Hoe tabellen worden gemaakt en beheerd door DLT
Azure Databricks beheert automatisch tabellen die zijn gemaakt met DLT, en bepaalt hoe updates moeten worden verwerkt om de huidige status van een tabel correct te berekenen en een aantal onderhouds- en optimalisatietaken uit te voeren.
Voor de meeste bewerkingen moet u DLT toestaan om alle updates, invoegingen en verwijderingen te verwerken in een doeltabel. Zie voor meer informatie en beperkingen de secties Handmatige verwijderingen behouden of updates.
Onderhoudstaken uitgevoerd door DLT
DLT voert onderhoudstaken uit binnen 24 uur nadat een tabel wordt bijgewerkt. Onderhoud kan de prestaties van query's verbeteren en kosten verlagen door oude versies van tabellen te verwijderen. Standaard voert het systeem een volledige OPTIMIZE bewerking uit, gevolgd door VACUUM. U kunt OPTIMIZE voor een tabel uitschakelen door pipelines.autoOptimize.managed = false in de eigenschappen van de tabel in te stellen voor de tabel. Onderhoudstaken worden alleen uitgevoerd als een pijplijnupdate in de 24 uur voordat de onderhoudstaken worden gepland, is uitgevoerd.
Delta Live Tables is nu DLT
Het product dat voorheen Delta Live Tables werd genoemd, is nu DLT.
Beperkingen
Zie DLT-beperkingenvoor een lijst met beperkingen.
Zie voor een lijst met vereisten en beperkingen die specifiek zijn voor het gebruik van DLT met Unity Catalog Unity Catalog gebruiken met uw DLT-pijplijnen
Aanvullende informatiebronnen
- DLT biedt volledige ondersteuning in de Databricks REST API. Zie DLT-API-.
- Zie de DLT-eigenschappenreferentie voor instellingen voor pijplijnen en tabellen.
- DLT-SQL-taalreferentie.
- DLT Python-taalreferentie.