Gegevens transformeren met pijplijnen
In dit artikel wordt beschreven hoe u DLT kunt gebruiken om transformaties op gegevenssets te declareren en op te geven hoe records worden verwerkt via querylogica. Het bevat ook voorbeelden van algemene transformatiepatronen voor het bouwen van DLT-pijplijnen.
U kunt een gegevensset definiëren op basis van elke query die een DataFrame retourneert. U kunt ingebouwde Apache Spark-bewerkingen, UDF's, aangepaste logica en MLflow-modellen gebruiken als transformaties in uw DLT-pijplijn. Nadat gegevens zijn opgenomen in uw DLT-pijplijn, kunt u nieuwe datasets definiëren op basis van upstream-bronnen om nieuwe streamingtabellen, gematerialiseerde weergaven en weergaven te maken.
Om te leren hoe je effectief stateful verwerking met DLT kunt uitvoeren, zie Stateful verwerking optimaliseren in DLT met watermerken.
Wanneer weergaven, gematerialiseerde weergaven en streamingtabellen te gebruiken
Bij het implementeren van uw pijplijnquery's kiest u het beste gegevenssettype om ervoor te zorgen dat ze efficiënt en onderhouden zijn.
U kunt een weergave gebruiken om het volgende te doen:
- Verdeel een grote of complexe query die u wilt in gemakkelijker te beheren queries.
- Valideer tussenliggende resultaten met behulp van verwachtingen.
- Verlaag de opslag- en rekenkosten voor resultaten die u niet hoeft te behouden. Omdat tabellen worden gematerialiseerd, zijn extra reken- en opslagbronnen vereist.
Overweeg om een gerealiseerde weergave te gebruiken wanneer:
- Meerdere downstreamquery's gebruiken de tabel. Omdat weergaven op aanvraag worden berekend, wordt de weergave telkens opnieuw berekend wanneer de weergave wordt opgevraagd.
- Andere pijplijnen, taken of queries gebruiken de tabel. Omdat weergaven niet worden gematerialiseerd, kunt u ze alleen in dezelfde pijplijn gebruiken.
- U wilt de resultaten van een query bekijken tijdens de ontwikkeling. Omdat tabellen worden gerealiseerd en kunnen worden bekeken en opgevraagd buiten de pijplijn, kan het gebruik van tabellen tijdens de ontwikkeling helpen bij het valideren van de juistheid van berekeningen. Na het valideren converteert u query's waarvoor geen materialisatie is vereist in weergaven.
Overweeg het gebruik van een streamingtabel wanneer:
- Een query wordt gedefinieerd op basis van een gegevensbron die continu of incrementeel groeit.
- Queryresultaten moeten incrementeel worden berekend.
- De pijplijn heeft een hoge doorvoer en lage latentie nodig.
Notitie
Streamingtabellen worden altijd gedefinieerd op basis van streamingbronnen. U kunt ook streamingbronnen met APPLY CHANGES INTO gebruiken om updates van CDC-feeds toe te passen. Zie De APPLY CHANGES-API's: Het vastleggen van wijzigingen vereenvoudigen met DLT-.
Tabellen uitsluiten van het doelschema
Als u tussenliggende tabellen moet berekenen die niet zijn bedoeld voor extern verbruik, kunt u voorkomen dat ze naar een schema worden gepubliceerd met behulp van het trefwoord TEMPORARY. Tijdelijke tabellen slaan nog steeds gegevens op volgens dlt-semantiek, maar mogen niet worden geopend buiten de huidige pijplijn. Een tijdelijke tabel blijft behouden voor de levensduur van de pijplijn waarmee deze wordt gemaakt. Gebruik de volgende syntaxis om tijdelijke tabellen te declareren:
SQL
CREATE TEMPORARY STREAMING TABLE temp_table
AS SELECT ... ;
Python
@dlt.table(
temporary=True)
def temp_table():
return ("...")
Streamingtabellen en gerealiseerde weergaven combineren in één pijplijn
Streamingtabellen nemen de verwerkingsgaranties van Apache Spark Structured Streaming over en worden geconfigureerd voor het verwerken van query's uit alleen toevoeggegevensbronnen, waarbij nieuwe rijen altijd worden ingevoegd in de brontabel in plaats van gewijzigd.
Notitie
Hoewel voor streamingtabellen standaard alleen toevoeggegevensbronnen zijn vereist, kunt u dit gedrag overschrijven met de vlag skipChangeCommits wanneer een streamingbron een andere streamingtabel is waarvoor updates of verwijderingen zijn vereist.
Een veelvoorkomend streamingpatroon houdt in dat brongegevens worden opgenomen om de initiële datasets in een pijplijn te creëren. Deze eerste gegevenssets worden vaak bronstabellen genoemd en voeren vaak eenvoudige transformaties uit.
De uiteindelijke tabellen in een datapijplijn, ook wel gouden tabellen genoemd, vereisen daarentegen vaak ingewikkelde aggregaties of het lezen van doelbestanden van een APPLY CHANGES INTO bewerking. Omdat deze bewerkingen inherent updates maken in plaats van toevoegbewerkingen, worden ze niet ondersteund als invoer voor streamingtabellen. Deze transformaties zijn beter geschikt voor gerealiseerde weergaven.
Door streamingtabellen en gerealiseerde weergaven te combineren in één pijplijn, kunt u uw pijplijn vereenvoudigen, kostbare heropname of herverwerking van onbewerkte gegevens voorkomen en de volledige kracht van SQL hebben om complexe aggregaties te berekenen via een efficiënt gecodeerde en gefilterde gegevensset. In het volgende voorbeeld ziet u dit type gemengde verwerking:
Notitie
In deze voorbeelden wordt automatisch laden van bestanden uit cloudopslag gebruikt. Als u bestanden wilt laden met Auto Loader in een pijplijn met Unity Catalog ingeschakeld, moet u externe locatiesgebruiken. Zie Unity Catalog gebruiken met uw DLT-pijplijnenvoor meer informatie over het gebruik van Unity Catalog met DLT.
Python
@dlt.table
def streaming_bronze():
return (
# Since this is a streaming source, this table is incremental.
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("abfss://path/to/raw/data")
)
@dlt.table
def streaming_silver():
# Since we read the bronze table as a stream, this silver table is also
# updated incrementally.
return spark.readStream.table("streaming_bronze").where(...)
@dlt.table
def live_gold():
# This table will be recomputed completely by reading the whole silver table
# when it is updated.
return spark.readStream.table("streaming_silver").groupBy("user_id").count()
SQL
CREATE OR REFRESH STREAMING TABLE streaming_bronze
AS SELECT * FROM STREAM read_files(
"abfss://path/to/raw/data",
format => "json"
)
CREATE OR REFRESH STREAMING TABLE streaming_silver
AS SELECT * FROM STREAM(streaming_bronze) WHERE...
CREATE OR REFRESH MATERIALIZED VIEW live_gold
AS SELECT count(*) FROM streaming_silver GROUP BY user_id
Meer informatie over het gebruik van Auto Loader voor het stapsgewijs inladen van JSON-bestanden uit Azure Storage.
Stream-statische koppelingen
Statische stream-joins zijn een goede keuze bij het denormaliseren van een continue stroom van uitsluitend toevoeggegevens met een overwegend statische dimensietabel.
Bij elke pijplijnupdate worden nieuwe records uit de stream samengevoegd met de meest recente momentopname van de statische tabel. Als records worden toegevoegd aan of bijgewerkt in de statische tabel nadat de bijbehorende gegevens uit de streamingtabel zijn verwerkt, worden de resulterende records niet opnieuw berekend, tenzij een volledige vernieuwing wordt uitgevoerd.
In pijplijnen die zijn geconfigureerd voor geactiveerde uitvoering, retourneert de statische tabel resultaten vanaf het moment dat de update is gestart. In pijplijnen die zijn geconfigureerd voor continue uitvoering, wordt de meest recente versie van de statische tabel telkens opgevraagd wanneer de tabel een update verwerkt.
Hier volgt een voorbeeld van een stream-statische join.
Python
@dlt.table
def customer_sales():
return spark.readStream.table("sales").join(spark.readStream.table("customers"), ["customer_id"], "left")
SQL
CREATE OR REFRESH STREAMING TABLE customer_sales
AS SELECT * FROM STREAM(sales)
INNER JOIN LEFT customers USING (customer_id)
Aggregaties efficiënt berekenen
U kunt streamingtabellen gebruiken om eenvoudige distributieaggregaties, zoals count, min, max of sum, en algebraïsche aggregaties, zoals gemiddelde of standaarddeviatie, incrementeel te berekenen. Databricks raadt incrementele aggregatie aan voor query's met een beperkt aantal groepen, zoals een query met een GROUP BY country-component. Alleen nieuwe invoergegevens worden gelezen bij elke update.
Zie Vensteraggregaties uitvoeren met watermerkenvoor meer informatie over het schrijven van DLT-query's die incrementele aggregaties uitvoeren.
MLflow-modellen gebruiken in een DLT-pijplijn
Notitie
Als u MLflow-modellen wilt gebruiken in een Unity Catalog-pijplijn, moet uw pijplijn zijn geconfigureerd voor het gebruik van het preview-kanaal. Als u het current-kanaal wilt gebruiken, moet u uw pijplijn configureren om te publiceren naar de Hive-metastore.
U kunt MLflow-getrainde modellen gebruiken in DLT-pijplijnen. MLflow-modellen worden behandeld als transformaties in Azure Databricks, wat betekent dat ze reageren op een Spark DataFrame-invoer en resultaten retourneren als een Spark DataFrame. Omdat DLT gegevenssets definieert voor DataFrames, kunt u Apache Spark-workloads die MLflow gebruiken, converteren naar DLT met slechts een paar regels code. Zie voor meer informatie over MLflow MLflow voor generatieve AI-agenten en ML-modellenlevenscyclus.
Als u al een Python-notebook hebt dat een MLflow-model aanroept, kunt u deze code aanpassen aan DLT met behulp van de @dlt.table decorator en ervoor zorgen dat functies worden gedefinieerd om transformatieresultaten te retourneren. DLT installeert MLflow niet standaard, dus controleer of u de MLFlow-bibliotheken hebt geïnstalleerd met %pip install mlflow en dat u mlflow en dlt boven aan uw notebook hebt geïmporteerd. Zie Pijplijncode ontwikkelen met Pythonvoor een inleiding tot DLT-syntaxis.
Voer de volgende stappen uit om MLflow-modellen in DLT te gebruiken:
- Haal de run-id en modelnaam van het MLflow-model op. De run-id en modelnaam worden gebruikt om de URI van het MLflow-model te maken.
- Gebruik de URI om een Spark UDF te definiëren om het MLflow-model te laden.
- Roep de UDF aan in de tabeldefinities om het MLflow-model te gebruiken.
In het volgende voorbeeld ziet u de basissyntaxis voor dit patroon:
%pip install mlflow
import dlt
import mlflow
run_id= "<mlflow-run-id>"
model_name = "<the-model-name-in-run>"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
@dlt.table
def model_predictions():
return spark.read.table(<input-data>)
.withColumn("prediction", loaded_model_udf(<model-features>))
Als volledig voorbeeld definieert de volgende code een Spark UDF met de naam loaded_model_udf waarmee een MLflow-model wordt geladen dat is getraind op gegevens over het leenrisico. De gegevenskolommen die worden gebruikt om de voorspelling te maken, worden als argument doorgegeven aan de UDF. De tabel loan_risk_predictions berekent voorspellingen voor elke rij in loan_risk_input_data.
%pip install mlflow
import dlt
import mlflow
from pyspark.sql.functions import struct
run_id = "mlflow_run_id"
model_name = "the_model_name_in_run"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
categoricals = ["term", "home_ownership", "purpose",
"addr_state","verification_status","application_type"]
numerics = ["loan_amnt", "emp_length", "annual_inc", "dti", "delinq_2yrs",
"revol_util", "total_acc", "credit_length_in_years"]
features = categoricals + numerics
@dlt.table(
comment="GBT ML predictions of loan risk",
table_properties={
"quality": "gold"
}
)
def loan_risk_predictions():
return spark.read.table("loan_risk_input_data")
.withColumn('predictions', loaded_model_udf(struct(features)))
handmatige verwijderingen of updates behouden
Met DLT kunt u records handmatig uit een tabel verwijderen of bijwerken en een vernieuwingsbewerking uitvoeren om downstreamtabellen opnieuw te compileren.
Met DLT worden standaard tabelresultaten opnieuw gecomputeerd op basis van invoergegevens telkens wanneer een pijplijn wordt bijgewerkt. U moet er dus voor zorgen dat de verwijderde record niet opnieuw wordt geladen uit de brongegevens. Als u de eigenschap pipelines.reset.allowed tabel instelt op false voorkomt u dat er vernieuwingen naar een tabel worden uitgevoerd, maar wordt niet voorkomen dat incrementele schrijfbewerkingen naar de tabellen of nieuwe gegevens naar de tabel stromen.
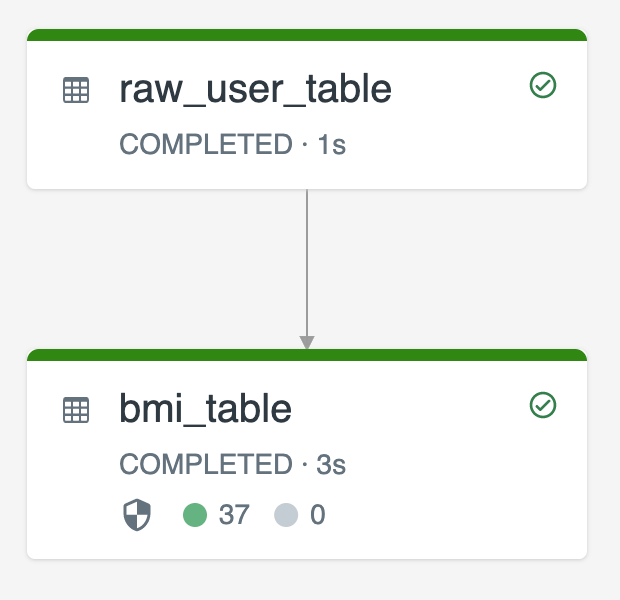
In het volgende diagram ziet u een voorbeeld met behulp van twee streamingtabellen:
-
raw_user_tableverwerkt onbewerkte gebruikersgegevens uit een bron. -
bmi_tableberekent stapsgewijs BMI-scores door het gewicht en de lengte vanraw_user_table.
U wilt gebruikersrecords handmatig verwijderen of bijwerken uit de raw_user_table en de bmi_tableopnieuw compileren.
De volgende code laat zien hoe u de eigenschap pipelines.reset.allowed tabel instelt op false om volledige vernieuwing voor raw_user_table uit te schakelen, zodat de beoogde wijzigingen na verloop van tijd worden bewaard, maar downstreamtabellen opnieuw worden gecomputeerd wanneer een pijplijnupdate wordt uitgevoerd:
CREATE OR REFRESH STREAMING TABLE raw_user_table
TBLPROPERTIES(pipelines.reset.allowed = false)
AS SELECT * FROM STREAM read_files("/databricks-datasets/iot-stream/data-user", format => "csv");
CREATE OR REFRESH STREAMING TABLE bmi_table
AS SELECT userid, (weight/2.2) / pow(height*0.0254,2) AS bmi FROM STREAM(raw_user_table);