Google BigQuery
In dit artikel wordt beschreven hoe u kunt lezen van en schrijven naar Google BigQuery-tabellen in Azure Databricks.
Belangrijk
De configuraties die in dit artikel worden beschreven, zijn experimenteel. Experimentele functies worden geleverd als zodanig en worden niet ondersteund door Databricks via technische ondersteuning van klanten. Als u volledige ondersteuning voor queryfederatie wilt krijgen, moet u in plaats daarvan Lakehouse Federationgebruiken, zodat uw Azure Databricks-gebruikers kunnen profiteren van de syntaxis en hulpprogramma's voor gegevensbeheer van Unity Catalog.
U moet verbinding maken met BigQuery met behulp van verificatie op basis van sleutels.
Machtigingen
Uw projecten moeten specifieke Google-machtigingen hebben om te lezen en schrijven met BigQuery.
Notitie
In dit artikel worden gematerialiseerde weergaven van BigQuery besproken. Zie het Google-artikel Inleiding tot gerealiseerde weergavenvoor meer informatie. Zie de Google BigQuery-documentatie voor meer informatie over andere BigQuery-terminologie en het BigQuery-beveiligingsmodel.
Het lezen en schrijven van gegevens met BigQuery is afhankelijk van twee Google Cloud-projecten:
- Project (
project): de id voor het Google Cloud-project waaruit Azure Databricks de BigQuery-tabel leest of schrijft. - Bovenliggend project (
parentProject): de ID voor het bovenliggende project, de Google Cloud Project-ID waarvoor kosten worden gemaakt voor het lezen en schrijven. Stel dit in op het Google Cloud-project dat is gekoppeld aan het Google-serviceaccount waarvoor u sleutels gaat genereren.
U moet expliciet de project en parentProject waarden opgeven in de code die toegang heeft tot BigQuery. Gebruik code die vergelijkbaar is met de volgende:
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
De vereiste machtigingen voor de Google Cloud-projecten zijn afhankelijk van of project en parentProject hetzelfde zijn. In de volgende secties worden de vereiste machtigingen voor elk scenario vermeld.
Vereiste machtigingen indien project en parentProject overeenkomen
Als de id's voor uw project en parentProject hetzelfde zijn, gebruikt u de volgende tabel om de minimale machtigingen te bepalen:
| Azure Databricks-taak | Google-machtigingen vereist in het project |
|---|---|
| Een BigQuery-tabel lezen zonder gerealiseerde weergave | In het project project:
|
| Een BigQuery-tabel lezen met een gematerialiseerde weergave | In het project project:
In het materialisatieproject:
|
| Een BigQuery-tabel schrijven | In het project project:
|
Vereiste machtigingen als project en parentProject verschillen
Als de id's voor uw project en parentProject verschillen, gebruikt u de volgende tabel om minimale machtigingen te bepalen:
| Azure Databricks-taak | Google-machtigingen vereist |
|---|---|
| Een BigQuery-tabel lezen zonder gerealiseerde weergave | In het parentProject project:
In het project project:
|
| Een BigQuery-tabel lezen met een gematerialiseerde weergave | In het parentProject project:
In het project project:
In het materialisatieproject:
|
| Een BigQuery-tabel schrijven | In het parentProject project:
In het project project:
|
Stap 1: Google Cloud instellen
De BigQuery Storage-API inschakelen
De BigQuery Storage-API is standaard ingeschakeld in nieuwe Google Cloud-projecten waarin BigQuery is ingeschakeld. Als u echter een bestaand project hebt en de BigQuery Storage-API niet is ingeschakeld, volgt u de stappen in deze sectie om dit in te schakelen.
U kunt de BigQuery Storage-API inschakelen met behulp van de Google Cloud CLI of de Google Cloud Console.
De BigQuery Storage-API inschakelen met behulp van Google Cloud CLI
gcloud services enable bigquerystorage.googleapis.com
De BigQuery Storage-API inschakelen met behulp van Google Cloud Console
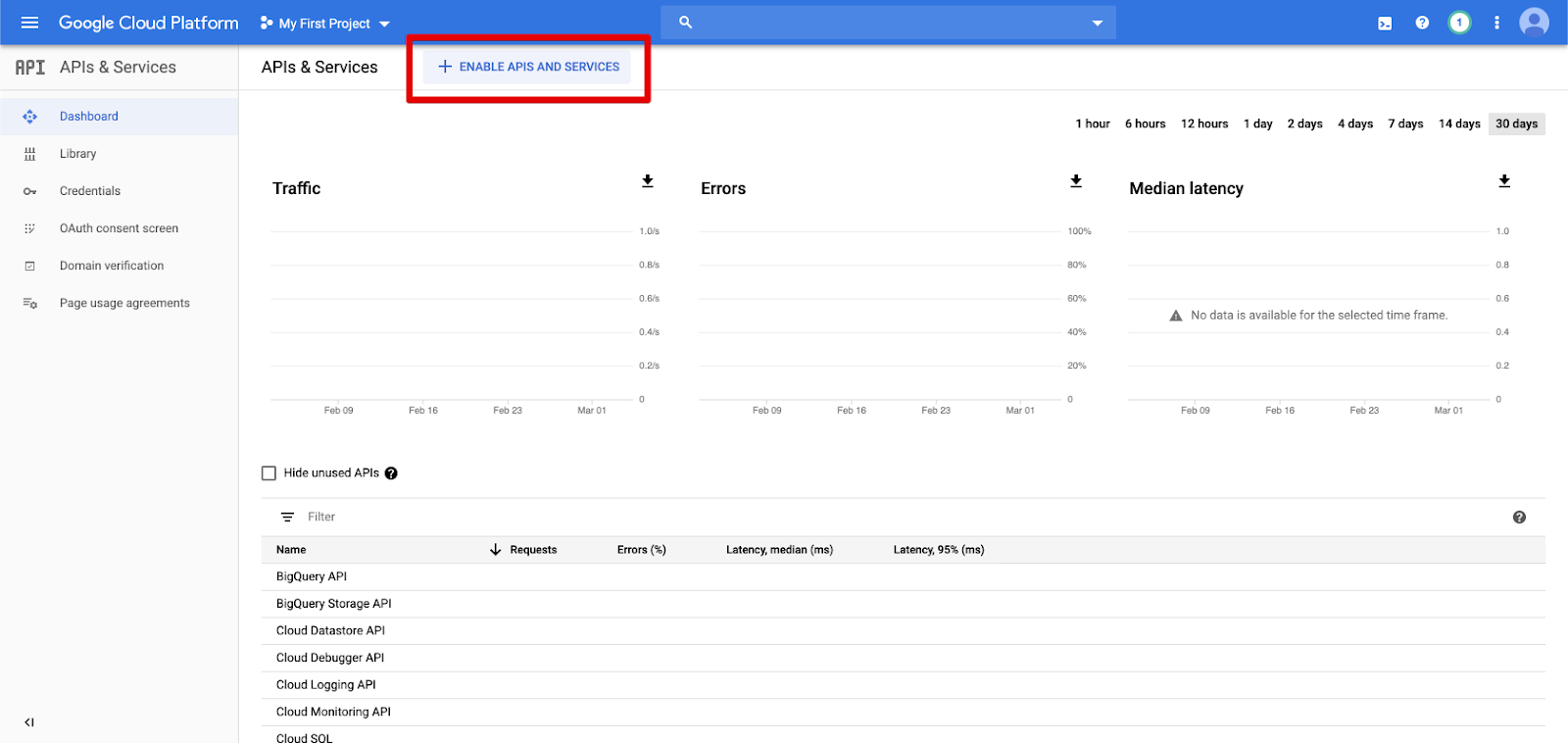
Klik op API's & Services in het linkernavigatiedeelvenster.
Klik op de knop API'S EN SERVICES INSCHAKELEN.
Typ
bigquery storage apiin de zoekbalk en selecteer het eerste resultaat.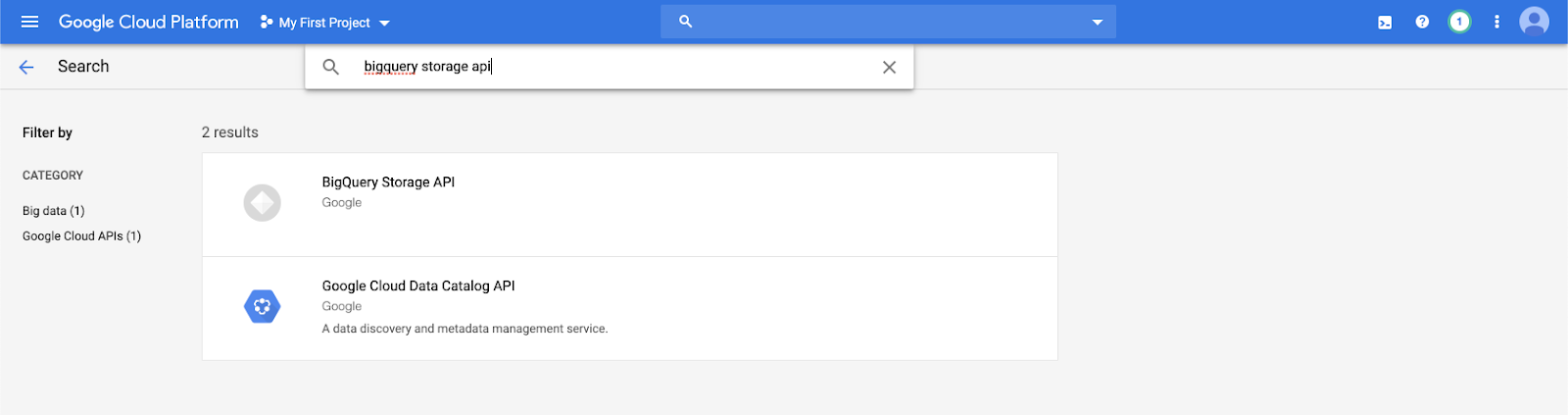
Zorg ervoor dat de BigQuery Storage-API is ingeschakeld.
Een Google-serviceaccount maken voor Azure Databricks
Maak een serviceaccount voor het Azure Databricks-cluster. Databricks raadt aan dit serviceaccount de minste bevoegdheden te geven die nodig zijn om de taken uit te voeren. Zie BigQuery-rollen en -machtigingen.
U kunt een serviceaccount maken met behulp van de Google Cloud CLI of de Google Cloud Console.
Een Google-serviceaccount maken met behulp van Google Cloud CLI
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
Maak de sleutels voor uw serviceaccount:
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Een Google-serviceaccount maken met behulp van Google Cloud Console
Ga als volgende te werk om het account te maken:
Klik op IAM en Beheerder in het linkernavigatiedeelvenster.
Klik op Serviceaccounts.
Klik op + SERVICEACCOUNT MAKEN.
Voer de naam en beschrijving van het serviceaccount in.
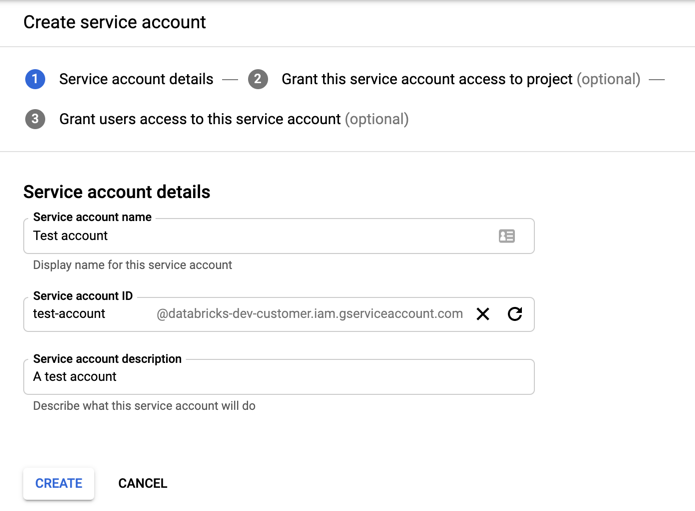
Klik op MAKEN.
Geef rollen op voor uw serviceaccount. In de vervolgkeuzelijst Selecteer een rol, typ
BigQueryen voeg de volgende rollen toe: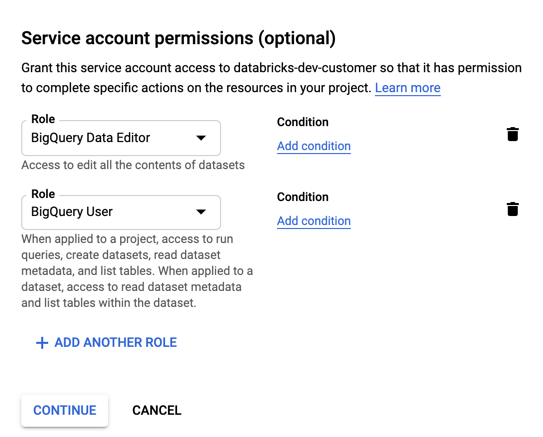
Klik op CONTINUE.
Klik op GEREED.
Sleutels voor uw serviceaccount maken:
Klik in de lijst met serviceaccounts op uw zojuist gemaakte account.
Selecteer in het gedeelte Sleutels de knop SLEUTEL TOEVOEGEN > Nieuwe sleutel maken.
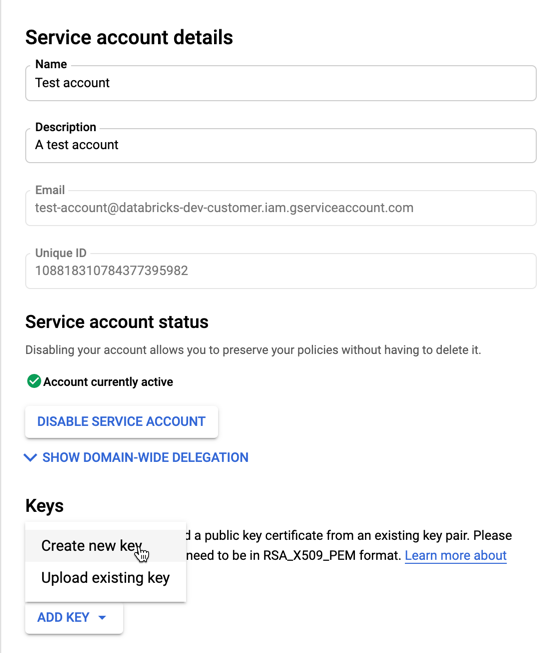
Accepteer het JSON-sleuteltype .
Klik op MAKEN. Het JSON-sleutelbestand wordt gedownload naar uw computer.
Belangrijk
Het JSON-sleutelbestand dat u voor het serviceaccount genereert, is een persoonlijke sleutel die alleen moet worden gedeeld met geautoriseerde gebruikers, omdat het de toegang tot gegevenssets en resources in uw Google Cloud-account beheert.
Een GCS-bucket (Google Cloud Storage) maken voor tijdelijke opslag
Als u gegevens naar BigQuery wilt schrijven, moet de gegevensbron toegang hebben tot een GCS-bucket.
Klik in het linkernavigatiedeelvenster op Opslag .
Klik op BUCKET MAKEN.
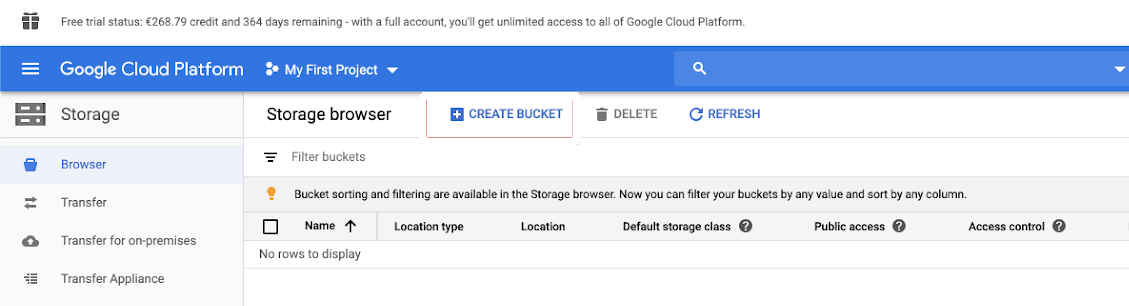
Configureer de inhoud van de emmer.
Klik op MAKEN.
Klik op het tabblad Machtigingen en Voeg leden toe.
Geef de volgende machtigingen op voor het serviceaccount in de bucket.
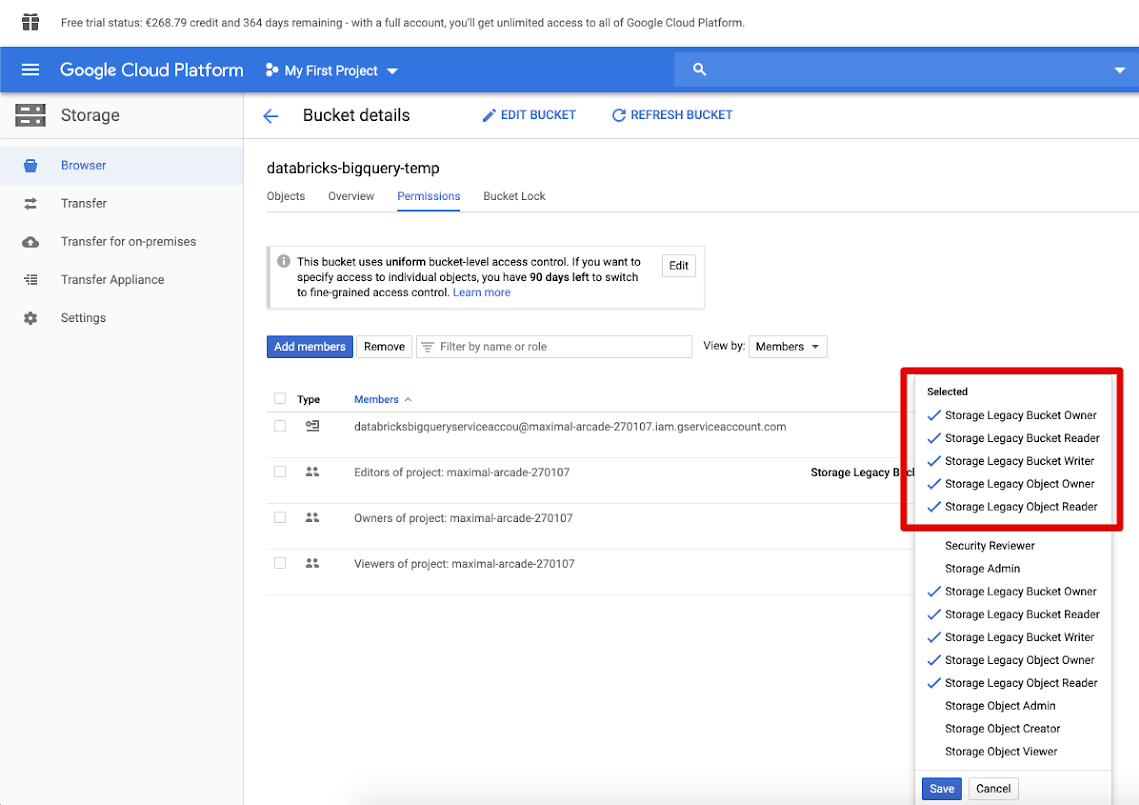
Klik op OPSLAAN.
Stap 2: Azure Databricks instellen
Als u een cluster wilt configureren voor toegang tot BigQuery-tabellen, moet u het JSON-sleutelbestand opgeven als een Spark-configuratie. Gebruik een lokaal hulpprogramma om uw JSON-sleutelbestand te coderen met Base64. Voor beveiligingsdoeleinden wordt geen web- of extern hulpprogramma gebruikt dat toegang heeft tot uw sleutels.
Wanneer u uw cluster configureert:
Voeg op het tabblad Spark-configuratie de volgende Spark-configuratie toe. Vervang <base64-keys> door de tekenreeks van het met Base64 gecodeerde JSON-sleutelbestand. Vervang de andere items tussen vierkante haken (zoals <client-email>) door de waarden van deze velden uit het JSON-sleutelbestand.
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
Lezen en schrijven naar een BigQuery-tabel
Om een BigQuery-tabel te lezen, specificeren we
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Om naar een BigQuery-tabel te schrijven, specificeer
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
waarbij <bucket-name> de naam is van de bucket die u hebt gemaakt in Een GCS-bucket (Google Cloud Storage) maken voor tijdelijke opslag. Zie machtigingen voor meer informatie over vereisten voor <project-id> en <parent-id> waarden.
Een externe tabel maken vanuit BigQuery
Belangrijk
Deze functie wordt niet ondersteund door Unity Catalog.
U kunt een niet-beheerde tabel in Databricks declareren waarmee gegevens rechtstreeks vanuit BigQuery worden gelezen:
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Voorbeeld van Python-notebook: een Google BigQuery-tabel laden in een DataFrame
In het volgende Python-notebook wordt een Google BigQuery-tabel geladen in een Azure Databricks DataFrame.
Google BigQuery Python-voorbeeldnotitieblok
Voorbeeld van Scala-notebook: Een Google BigQuery-tabel laden in een DataFrame
Met het volgende Scala-notebook wordt een Google BigQuery-tabel geladen in een Azure Databricks DataFrame.