Taken systeemtabel referentie
Notitie
Het lakeflow schema werd voorheen workflowgenoemd. De inhoud van beide schema's is identiek. Als u het lakeflow-schema zichtbaar wilt maken, moet u het afzonderlijk inschakelen.
Dit artikel is een handleiding voor hoe je de lakeflow-systeemtabellen gebruikt om taken in uw account te monitoren. Deze tabellen bevatten records uit alle werkruimten in uw account die zijn geïmplementeerd in dezelfde cloudregio. Als u records uit een andere regio wilt zien, moet u de tabellen bekijken uit een werkruimte die in die regio is geïmplementeerd.
Eisen
- Het
system.lakeflow-schema moet worden ingeschakeld door een accountbeheerder. Zie Systeemtabelschema's inschakelen. - Voor toegang tot deze systeemtabellen moeten gebruikers het volgende doen:
- Zowel een metastore-beheerder als een accountbeheerder zijn, of
- Beschikken over
USE- enSELECTmachtigingen voor de systeemschema's. Zie Toegang verlenen tot systeemtabellen.
Beschikbare taaktabellen
Alle systeemtabellen met betrekking tot taken bevinden zich in het system.lakeflow schema. Op dit moment host het schema vier tabellen:
| Tafel | Beschrijving | Ondersteunt streaming | Gratis bewaarperiode | Bevat globale of regionale gegevens |
|---|---|---|---|---|
| opdrachten (Preview) | Houdt alle taken bij die in het account zijn gemaakt | Ja | 365 dagen | Regionaal |
| job_tasks (openbare preview) | Houdt alle taaktaken bij die worden uitgevoerd in het account | Ja | 365 dagen | Regionaal |
| job_run_timeline (Openbare Preview) | Houdt de taakuitvoeringen en gerelateerde metagegevens bij | Ja | 365 dagen | Regionaal |
| job_task_run_timeline (openbare preview) | Taakuitvoeringen en gerelateerde metagegevens bijhoudt | Ja | 365 dagen | Regionaal |
Gedetailleerde schemareferentie
De volgende secties bevatten schemaverwijzingen voor elk van de systeemtabellen met betrekking tot taken.
Banen tabelschema
De jobs tabel is een langzaam veranderende dimensietabel (SCD2). Wanneer een rij wordt gewijzigd, wordt er een nieuwe rij verzonden, waarbij de vorige logisch wordt vervangen.
tabelpad: system.lakeflow.jobs
| Kolomnaam | Gegevenstype | Beschrijving | Notities |
|---|---|---|---|
account_id |
tekenreeks | De ID van het account waartoe deze taak behoort | |
workspace_id |
tekenreeks | De ID van de werkruimte waartoe deze opdracht behoort | |
job_id |
tekenreeks | De ID van de taak | Alleen uniek binnen één werkruimte |
name |
tekenreeks | De door de gebruiker opgegeven naam van de taak | |
description |
tekenreeks | De door de gebruiker opgegeven beschrijving van de taak | Dit veld is leeg als u door de klant beheerde sleutels hebt geconfigureerd. Niet ingevuld voor rijen die vóór eind augustus 2024 zijn verzonden |
creator_id |
tekenreeks | De identificatie van de Principal die de taak heeft gemaakt | |
tags |
tekenreeks | De door de gebruiker opgegeven aangepaste tags die aan deze taak zijn gekoppeld | |
change_time |
timestamp | Het tijdstip waarop de taak voor het laatst is gewijzigd | Tijdzone geregistreerd als +00:00 (UTC) |
delete_time |
timestamp | Het tijdstip waarop de taak is verwijderd door de gebruiker | Tijdzone geregistreerd als +00:00 (UTC) |
run_as |
tekenreeks | De id van de gebruiker of service-principal waarvan de machtigingen worden gebruikt voor de taakuitvoering |
Voorbeeldquery
-- Get the most recent version of a job
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
schema van de taaktabel
De taaktakentabel is een langzaam veranderende dimensietabel (SCD2). Wanneer een rij wordt gewijzigd, wordt er een nieuwe rij verzonden, waarbij de vorige logisch wordt vervangen.
tabelpad: system.lakeflow.job_tasks
| Kolomnaam | Gegevenstype | Beschrijving | Notities |
|---|---|---|---|
account_id |
tekenreeks | De ID van het account waartoe deze taak behoort | |
workspace_id |
tekenreeks | De ID van de werkruimte waartoe deze opdracht behoort | |
job_id |
tekenreeks | De ID van de taak | Alleen uniek binnen één werkruimte |
task_key |
tekenreeks | De referentiesleutel voor een taak in een werk | Alleen uniek binnen één taak |
depends_on_keys |
matrix | De taaksleutels van alle upstream-afhankelijkheden van deze taak | |
change_time |
timestamp | Het tijdstip waarop de taak voor het laatst is gewijzigd | Tijdzone geregistreerd als +00:00 (UTC) |
delete_time |
timestamp | Het tijdstip waarop een taak is verwijderd door de gebruiker | Tijdzone geregistreerd als +00:00 (UTC) |
Voorbeeldquery
-- Get the most recent version of a job task
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.job_tasks QUALIFY rn=1
tijdlijntabelschema voor taakuitvoering
De tijdlijntabel voor taakuitvoering is onveranderbaar en voltooid op het moment dat deze wordt geproduceerd.
tabelpad: system.lakeflow.job_run_timeline
| Kolomnaam | Gegevenstype | Beschrijving | Notities |
|---|---|---|---|
account_id |
tekenreeks | De ID van het account waartoe deze taak behoort | |
workspace_id |
tekenreeks | De ID van de werkruimte waartoe deze opdracht behoort | |
job_id |
tekenreeks | De ID van de taak | Deze sleutel is slechts uniek binnen één werkruimte |
run_id |
tekenreeks | De ID van de taakuitvoering | |
period_start_time |
timestamp | De begintijd voor de run of voor de tijdsperiode | Tijdzonegegevens worden vastgelegd aan het einde van de waarde met +00:00 die UTC vertegenwoordigen |
period_end_time |
timestamp | De eindtijd voor de uitvoering of voor de periode | Tijdzonegegevens worden vastgelegd aan het einde van de waarde met +00:00 die UTC vertegenwoordigen |
trigger_type |
tekenreeks | Het type trigger dat een taak kan activeren | Zie Trigger-typewaarden voor mogelijke waarden |
run_type |
tekenreeks | Het type taakuitvoering | Zie Run-typewaarden voor mogelijke waarden |
run_name |
tekenreeks | De door de gebruiker opgegeven uitvoeringsnaam die is gekoppeld aan deze taakuitvoering | |
compute_ids |
matrix | Matrix met de taak-reken-id's voor de bovenliggende taakuitvoering | Gebruik voor het identificeren van taakclusters die door WORKFLOW_RUN runtypes worden gebruikt. Raadpleeg de job_task_run_timeline tabel voor andere rekengegevens.Niet ingevuld voor rijen die vóór eind augustus 2024 zijn verzonden |
result_state |
tekenreeks | Het resultaat van de taakuitvoering | Zie resultaatstatuswaarden voor mogelijke waarden |
termination_code |
tekenreeks | De beëindigingscode van de taakuitvoering | Zie Waarden voor beëindigingscodevoor mogelijke waarden. Niet ingevuld voor rijen die vóór eind augustus 2024 zijn verzonden |
job_parameters |
map | De parameters op taakniveau die worden gebruikt in de taakuitvoering | De afgeschafte notebook_params instellingen zijn niet opgenomen in dit veld. Niet ingevuld voor rijen die vóór eind augustus 2024 zijn verzonden |
Voorbeeldquery
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name = :run_name
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
tijdlijntabelschema voor taak uitvoeren
De tijdlijntabel voor taakuitvoering is onveranderbaar en voltooid op het moment dat deze wordt geproduceerd.
tabelpad: system.lakeflow.job_task_run_timeline
| Kolomnaam | Gegevenstype | Beschrijving | Notities |
|---|---|---|---|
account_id |
tekenreeks | De ID van het account waartoe deze taak behoort | |
workspace_id |
tekenreeks | De ID van de werkruimte waartoe deze opdracht behoort | |
job_id |
tekenreeks | De ID van de taak | Alleen uniek binnen één werkruimte |
run_id |
tekenreeks | De ID van de taakuitvoering | |
job_run_id |
tekenreeks | De ID van de taakuitvoering | Niet ingevuld voor rijen die vóór eind augustus 2024 zijn verzonden |
parent_run_id |
tekenreeks | De ID van de bovenliggende run | Niet ingevuld voor rijen die vóór eind augustus 2024 zijn verzonden |
period_start_time |
timestamp | De begintijd voor de taak of voor de periode | Tijdzonegegevens worden vastgelegd aan het einde van de waarde met +00:00 die UTC vertegenwoordigen |
period_end_time |
timestamp | De eindtijd voor de taak of voor de periode | Tijdzonegegevens worden vastgelegd aan het einde van de waarde met +00:00 die UTC vertegenwoordigen |
task_key |
tekenreeks | De referentiesleutel voor een taak in een werk | Deze sleutel is slechts uniek binnen één taak |
compute_ids |
matrix | De compute_ids matrix bevat id's van taakclusters, interactieve clusters en SQL-warehouses die door de taaktaak worden gebruikt | |
result_state |
tekenreeks | Het resultaat van de taakuitvoering | Zie resultaatstatuswaarden voor mogelijke waarden |
termination_code |
tekenreeks | De beëindigingscode van de taakuitvoering | Zie Waarden voor beëindigingscodevoor mogelijke waarden. Niet ingevuld voor rijen die vóór eind augustus 2024 zijn verzonden |
Algemene koppelingspatronen
De volgende secties bevatten voorbeeldquery's die veelgebruikte joinpatronen voor systeemtabellen voor taken benadrukken.
De taken en draaitijdlijntabellen samenvoegen
taakuitvoering verrijken met een taaknaam
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
De tijdlijn van de taakuitvoering en de gebruikstabellen samenvoegen
Elk factureringslogboek verrijken met metagegevens voor taakuitvoering
SELECT
t1.*,
t2.*
FROM system.billing.usage t1
LEFT JOIN system.lakeflow.job_run_timeline t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
WHERE
billing_origin_product="JOBS"
Kosten per taakuitvoering berekenen
Deze query wordt samengevoegd met de billing.usage systeemtabel om een kosten per taakuitvoering te berekenen.
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
Gebruikslogboeken ophalen voor SUBMIT_RUN-opdrachten
SELECT
*
FROM system.billing.usage
WHERE
EXISTS (
SELECT 1
FROM system.lakeflow.job_run_timeline
WHERE
job_run_timeline.job_id = usage_metadata.job_id
AND run_name = :run_name
AND workspace_id = :workspace_id
)
Combineer de tijdlijntabellen en clustertabellen van de taakuitvoeringen
Taaktaken verrijken met metagegevens van clusters
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
exploded_task_runs.*,
clusters.*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
Vind taken die draaien op algemene computervoorzieningen
Deze query voegt samen met de compute.clusters-systeemtabel om recente taken te retourneren die worden uitgevoerd op algemene berekeningen in plaats van op takenberekeningen.
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
Dashboard voor het bewaken van taken
In het volgende dashboard worden systeemtabellen gebruikt om u te helpen uw taken en operationele status te bewaken. Het omvat veelvoorkomende gebruiksvoorbeelden, zoals het bijhouden van taakprestaties, het bewaken van fouten en het resourcegebruik.
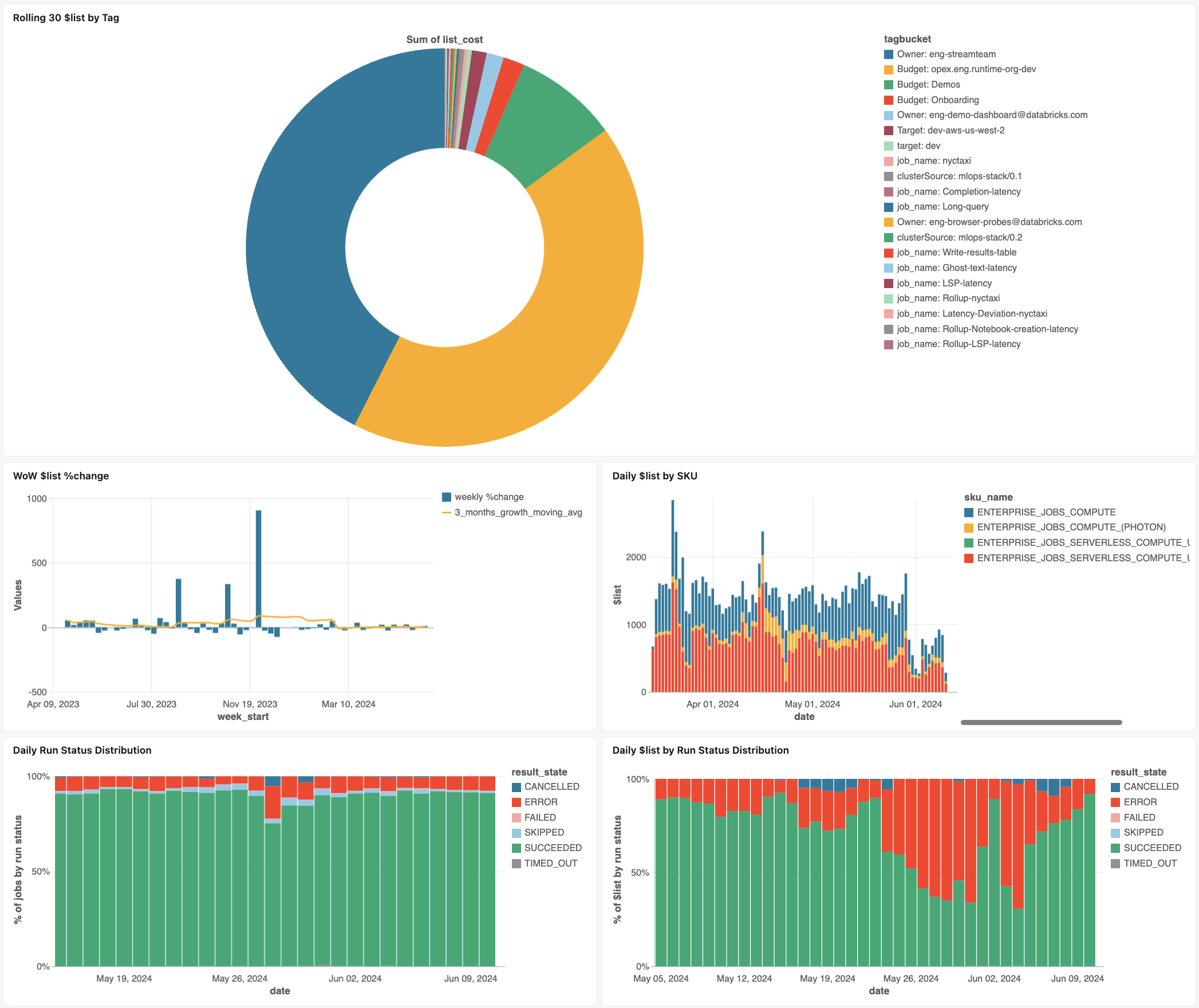
Zie Taakkosten bewaken & prestaties met systeemtabellen voor informatie over het downloaden van het dashboard
Probleemoplossing
Taak is niet vastgelegd in de lakeflow.jobs tabel
Als een taak niet zichtbaar is in de systeemtabellen:
- De taak is in de afgelopen 365 dagen niet gewijzigd
- Wijzig een van de taakvelden die aanwezig zijn in het schema om een nieuw record te emitteren.
- De functie werd gecreëerd in een andere regio
- Recente taak maken (tabelvertraging)
Kan geen baan vinden in tabel job_run_timeline
Niet alle job runs zijn overal zichtbaar. Hoewel JOB_RUN vermeldingen worden weergegeven in alle taakgerelateerde tabellen, worden WORKFLOW_RUN (werkstroomuitvoeringen van notebooks) alleen vastgelegd in job_run_timeline en worden SUBMIT_RUN (eenmalige ingediende uitvoeringen) alleen vastgelegd in beide tijdlijntabellen. Deze uitvoeringen worden niet gevuld met andere taaksysteemtabellen, zoals jobs of job_tasks.
Zie de Uitvoeringstypen tabel hieronder voor een gedetailleerde uitsplitsing van waar elk type uitvoering zichtbaar en toegankelijk is.
taak wordt niet weergegeven in billing.usage tabel
In system.billing.usagewordt de usage_metadata.job_id alleen ingevuld voor taken die worden uitgevoerd op taakberekening of serverloze verwerking.
Daarnaast hebben WORKFLOW_RUN taken geen eigen usage_metadata.job_id- of usage_metadata.job_run_id-toeschrijvingen in system.billing.usage.
In plaats daarvan wordt het rekengebruik toegeschreven aan het hoofdnotebook dat hen heeft geactiveerd.
Dit betekent dat wanneer een notebook een werkstroomuitvoering start, alle rekenkosten worden weergegeven onder het gebruik van het bovenliggende notitieblok, niet als een afzonderlijke werkstroomtaak.
Zie Gebruiksmetagegevensreferentie voor meer informatie.
de kosten berekenen van een taak die wordt uitgevoerd op een rekenproces voor alle doeleinden
Nauwkeurige kostenberekening voor taken die worden uitgevoerd op doelberekening is niet mogelijk met 100% nauwkeurigheid. Wanneer een taak wordt uitgevoerd op een interactieve (all-purpose) berekening, worden meerdere workloads zoals notebooks, SQL-query's of andere taken vaak tegelijkertijd uitgevoerd op dezelfde rekenresource. Omdat de clusterresources worden gedeeld, is er geen directe 1-op-1 relatie tussen de computerkosten en afzonderlijke taakuitvoeringen.
Voor nauwkeurige kosten bijhouden van taken raadt Databricks aan om taken uit te voeren op toegewezen taak berekenen of serverloze berekeningen, waarbij de usage_metadata.job_id en usage_metadata.job_run_id nauwkeurige kostentoewijzing mogelijk maken.
Als u berekeningen voor alle doeleinden moet gebruiken, kunt u het volgende doen:
- Bewaak het totale clustergebruik en de kosten in
system.billing.usageop basis vanusage_metadata.cluster_id. - Houd de metrische gegevens van de taakruntime afzonderlijk bij.
- Houd er rekening mee dat elke kostenraming bij benadering zal zijn vanwege gedeelde middelen.
Zie Naslaginformatie over gebruiksgegevens voor meer informatie over kostentoewijzing.
Referentiewaarden
De volgende sectie bevat verwijzingen voor geselecteerde kolommen in taken gerelateerde tabellen.
Triggertypewaarden
De mogelijke waarden voor de kolom trigger_type zijn:
CONTINUOUSCRONFILE_ARRIVALONETIMEONETIME_RETRY
waarden voor run-type
De mogelijke waarden voor de kolom run_type zijn:
| Type | Beschrijving | UI-locatie | API-eindpunt | Systeemtabellen |
|---|---|---|---|---|
JOB_RUN |
Standaardtaakuitvoering | Taken & gebruikersinterface voor taakuitvoeringen | /jobs en /jobs/voert eindpunten uit | banen, bantaken, baanuitvoeringslijn, bantakenuitvoeringslijn |
SUBMIT_RUN |
Eenmalige uitvoering via POST /jobs/runs/submit | Alleen gebruikersinterface voor taakuitvoeringen | Alleen eindpunten voor /jobs/runs | taakuitvoeringstijdlijn, taakuitvoertijddetail |
WORKFLOW_RUN |
Uitvoering gestart vanuit notebook-werkstroom | Niet zichtbaar | Niet toegankelijk | tijdsverloop van taakuitvoering |
waarden voor resultaatstatus
De mogelijke waarden voor de kolom result_state zijn:
| Staat | Beschrijving |
|---|---|
SUCCEEDED |
De uitvoering is succesvol voltooid |
FAILED |
De uitvoering is voltooid met een fout |
SKIPPED |
De taak is nooit uitgevoerd omdat niet aan een voorwaarde is voldaan. |
CANCELLED |
De uitvoering is geannuleerd op verzoek van de gebruiker |
TIMED_OUT |
De uitvoering is gestopt na het bereiken van de time-out |
ERROR |
De uitvoering is voltooid met een fout |
BLOCKED |
De uitvoering is geblokkeerd door een upstream-afhankelijkheid |
-code waarden voor beëindiging
De mogelijke waarden voor de kolom termination_code zijn:
| Beëindigingscode | Beschrijving |
|---|---|
SUCCESS |
De loop is succesvol voltooid |
CANCELLED |
De uitvoering is geannuleerd tijdens de uitvoering door het Databricks-platform; Als de maximale uitvoeringsduur bijvoorbeeld is overschreden |
SKIPPED |
De uitvoering heeft nooit plaatsgevonden, bijvoorbeeld als de upstream-taakuitvoering is mislukt, er niet aan de voorwaarde van het afhankelijkheidstype werd voldaan, of er geen taken waren om uit te voeren. |
DRIVER_ERROR |
Er is een fout opgetreden tijdens de communicatie met het Spark-stuurprogramma |
CLUSTER_ERROR |
De uitvoering is mislukt vanwege een clusterfout |
REPOSITORY_CHECKOUT_FAILED |
Kan het uitchecken niet voltooien vanwege een fout bij het communiceren met de service van derden |
INVALID_CLUSTER_REQUEST |
De uitvoering is mislukt omdat er een ongeldige aanvraag is verzonden om het cluster te starten |
WORKSPACE_RUN_LIMIT_EXCEEDED |
De werkruimte heeft het quotum bereikt voor de maximale hoeveelheid gelijktijdige actieve runs. Overweeg de uitvoeringen gedurende een groter tijdsbestek te plannen |
FEATURE_DISABLED |
De uitvoering is mislukt omdat er is geprobeerd toegang te krijgen tot een functie die niet beschikbaar is voor de werkruimte |
CLUSTER_REQUEST_LIMIT_EXCEEDED |
Het aantal aanvragen voor het maken, starten en upsize van clusters heeft de toegewezen frequentielimiet overschreden. Overweeg om de uitvoering over een groter tijdsbestek te spreiden |
STORAGE_ACCESS_ERROR |
De uitvoering is mislukt vanwege een fout bij het openen van de blobopslag van de klant |
RUN_EXECUTION_ERROR |
De uitvoering is voltooid met taakfouten |
UNAUTHORIZED_ERROR |
De uitvoering is mislukt vanwege een machtigingsprobleem tijdens het openen van een resource |
LIBRARY_INSTALLATION_ERROR |
De uitvoering is mislukt tijdens het installeren van de door de gebruiker aangevraagde bibliotheek. De oorzaken kunnen zijn, maar zijn niet beperkt tot: De opgegeven bibliotheek is ongeldig, er zijn onvoldoende machtigingen om de bibliotheek te installeren, enzovoort |
MAX_CONCURRENT_RUNS_EXCEEDED |
De geplande uitvoering overschrijdt de limiet van het maximum aantal gelijktijdige uitvoeringen dat is ingesteld voor de taak |
MAX_SPARK_CONTEXTS_EXCEEDED |
De run is gepland op een cluster dat al het maximale aantal contexten heeft bereikt dat is ingesteld om te creëren |
RESOURCE_NOT_FOUND |
Er bestaat geen resource die nodig is om de uitvoering uit te voeren |
INVALID_RUN_CONFIGURATION |
De uitvoering is mislukt vanwege een ongeldige configuratie |
CLOUD_FAILURE |
De uitvoering is mislukt vanwege een probleem met de cloudprovider |
MAX_JOB_QUEUE_SIZE_EXCEEDED |
De uitvoering werd overgeslagen omdat de wachtrijlimiet op taakniveau was bereikt. |