Gegevens transformeren door een Synapse Spark-taakdefinitie uit te voeren
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
De taakdefinitieactiviteit van Azure Synapse Spark in een pijplijn voert een Synapse Spark-taakdefinitie uit in uw Azure Synapse Analytics-werkruimte. Dit artikel is gebaseerd op het artikel over activiteiten voor gegevenstransformatie , waarin een algemeen overzicht wordt weergegeven van de gegevenstransformatie en de ondersteunde transformatieactiviteiten.
Canvas voor Apache Spark-taakdefinitie instellen
Voer de volgende stappen uit om een Spark-taakdefinitieactiviteit voor Synapse in een pijplijn te gebruiken:
Algemene instellingen
Zoek naar Spark-taakdefinitie in het deelvenster Pijplijnactiviteiten en sleep een Spark-taakdefinitieactiviteit onder Synapse naar het pijplijncanvas.
Selecteer de nieuwe Spark-taakdefinitieactiviteit op het canvas als deze nog niet is geselecteerd.
Voer op het tabblad Algemeen voorbeeld in voor Naam.
(Optie) U kunt ook een beschrijving invoeren.
Time-out: De maximale hoeveelheid tijd die een activiteit kan uitvoeren. De standaardwaarde is zeven dagen, wat ook de maximale hoeveelheid tijd is die is toegestaan. De indeling is in D.HH:MM:SS.
Opnieuw proberen: maximum aantal nieuwe pogingen.
Interval voor opnieuw proberen: het aantal seconden tussen elke nieuwe poging.
Beveiligde uitvoer: wanneer deze optie is ingeschakeld, wordt de uitvoer van de activiteit niet vastgelegd in logboekregistratie.
Beveiligde invoer: wanneer deze optie is ingeschakeld, wordt invoer van de activiteit niet vastgelegd in logboekregistratie.
Instellingen voor Azure Synapse Analytics (artefacten)
Selecteer de nieuwe Spark-taakdefinitieactiviteit op het canvas als deze nog niet is geselecteerd.
Selecteer het tabblad Azure Synapse Analytics (Artefacten) om een nieuwe gekoppelde Azure Synapse Analytics-service te selecteren of te maken waarmee de activiteit van de Spark-taakdefinitie wordt uitgevoerd.
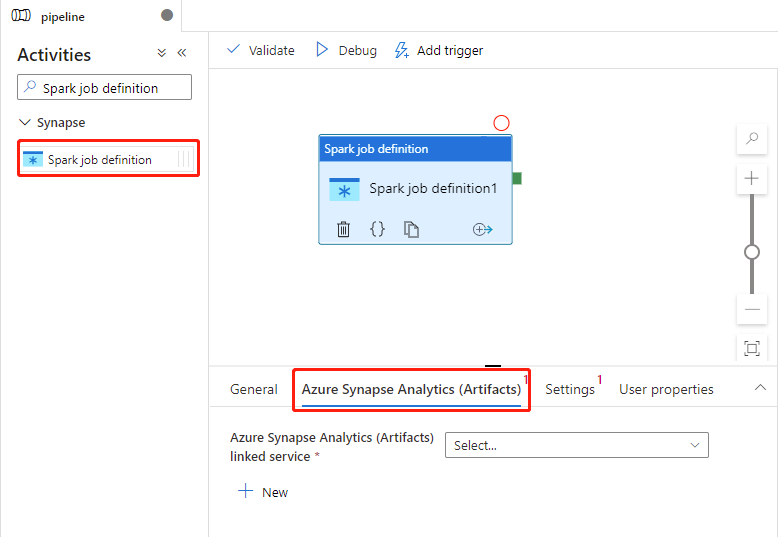
Tabblad Instellingen
Selecteer de nieuwe Spark-taakdefinitieactiviteit op het canvas als deze nog niet is geselecteerd.
Selecteer het tabblad Instellingen.
Vouw de lijst met Spark-taakdefinities uit. U kunt een bestaande Apache Spark-taakdefinitie selecteren in de gekoppelde Azure Synapse Analytics-werkruimte.
(Optioneel) U kunt informatie invullen voor de Apache Spark-taakdefinitie. Als de volgende instellingen leeg zijn, worden de instellingen van de Spark-taakdefinitie zelf gebruikt om uit te voeren; als de volgende instellingen niet leeg zijn, vervangen deze instellingen de instellingen van de Spark-taakdefinitie zelf.
Eigenschappen Beschrijving Primair definitiebestand Het primaire bestand dat wordt gebruikt voor de taak. Selecteer een PY/JAR/ZIP-bestand in uw opslag. U kunt Bestand uploaden selecteren om het bestand te uploaden naar een opslagaccount.
Voorbeeld:abfss://…/path/to/wordcount.jarVerwijzingen uit submappen Submappen scannen vanuit de hoofdmap van het hoofddefinitiebestand. Deze bestanden worden toegevoegd als referentiebestanden. De mappen met de naam 'jars', 'pyFiles', 'files' of 'archieven' worden gescand en de naam van de mappen is hoofdlettergevoelig. Hoofdklassenaam De volledig gekwalificeerde id of de hoofdklasse die zich in het hoofddefinitiebestand bevindt.
Voorbeeld:WordCountOpdrachtregelargumenten U kunt opdrachtregelargumenten toevoegen door op de knop Nieuw te klikken. Het toevoegen van opdrachtregelargumenten overschrijft de opdrachtregelargumenten die zijn gedefinieerd door de Spark-taakdefinitie.
Monster:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultApache Spark-pool U kunt Een Apache Spark-pool selecteren in de lijst. Naslaginformatie over Python-code Aanvullende Python-codebestanden die worden gebruikt voor verwijzing in het hoofddefinitiebestand.
Het ondersteunt het doorgeven van bestanden (.py, .py3, .zip) aan de eigenschap 'pyFiles'. Hiermee wordt de eigenschap 'pyFiles' overschreven die is gedefinieerd in de Spark-taakdefinitie.Verwijzingsbestanden Aanvullende bestanden die worden gebruikt voor verwijzingen in het hoofddefinitiebestand. Apache Spark-pool U kunt Een Apache Spark-pool selecteren in de lijst. Uitvoerders dynamisch toewijzen Deze instelling wordt toegewezen aan de eigenschap dynamische toewijzing in de Spark-configuratie voor toewijzing van spark-toepassingsexecutors. Min.uitvoerders Minimum aantal uitvoerders dat moet worden toegewezen in de opgegeven Spark-pool voor de taak. Maximum aantal uitvoerders Maximum aantal uitvoerders dat moet worden toegewezen in de opgegeven Spark-pool voor de taak. Grootte van stuurprogramma Aantal kernen en het geheugen die moet worden gebruikt voor het stuurprogramma dat in de gespecificeerde Apache Spark-pool voor de taak is opgegeven. Spark-configuratie Geef waarden op voor Spark-configuratie-eigenschappen die worden vermeld in het onderwerp: Spark-configuratie - toepassingseigenschappen. Gebruikers kunnen standaardconfiguratie en aangepaste configuratie gebruiken. 
U kunt dynamische inhoud toevoegen door te klikken op de knop Dynamische inhoud toevoegen of door op alt+ Shift+D te drukken. Op de pagina Dynamische inhoud toevoegen kunt u elke combinatie van expressies, functies en systeemvariabelen gebruiken om aan dynamische inhoud toe te voegen.
Tabblad Gebruikerseigenschappen
U kunt eigenschappen toevoegen voor activiteit in apache Spark-taakdefinities in dit deelvenster.
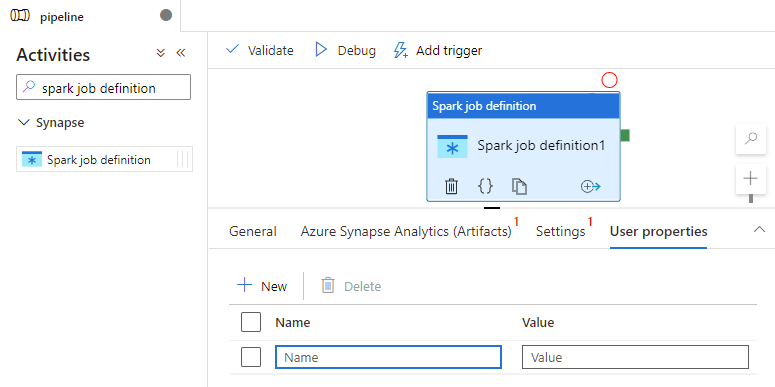
Activiteitsdefinitie van Azure Synapse Spark-taakdefinitie
Hier volgt de JSON-voorbeelddefinitie van een Azure Synapse Analytics Notebook-activiteit:
{
"activities": [
{
"name": "Spark job definition1",
"type": "SparkJob",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"typeProperties": {
"sparkJob": {
"referenceName": {
"value": "Spark job definition 1",
"type": "Expression"
},
"type": "SparkJobDefinitionReference"
}
},
"linkedServiceName": {
"referenceName": "AzureSynapseArtifacts1",
"type": "LinkedServiceReference"
}
}
],
}
Azure Synapse Spark-taakdefinitieeigenschappen
In de volgende tabel worden de JSON-eigenschappen beschreven die worden gebruikt in de JSON-definitie:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| naam | Naam van de activiteit in de pijplijn. | Ja |
| beschrijving | Tekst die beschrijft wat de activiteit doet. | Nee |
| type | Voor Azure Synapse Spark-taakdefinitieactiviteit is het activiteitstype SparkJob. | Ja |
Zie de uitvoeringsgeschiedenis van azure Synapse Spark-taakdefinitie
Ga naar Pijplijnuitvoeringen op het tabblad Monitor . U ziet de pijplijn die u hebt geactiveerd. Open de pijplijn met azure Synapse Spark-taakdefinitieactiviteit om de uitvoeringsgeschiedenis te bekijken.
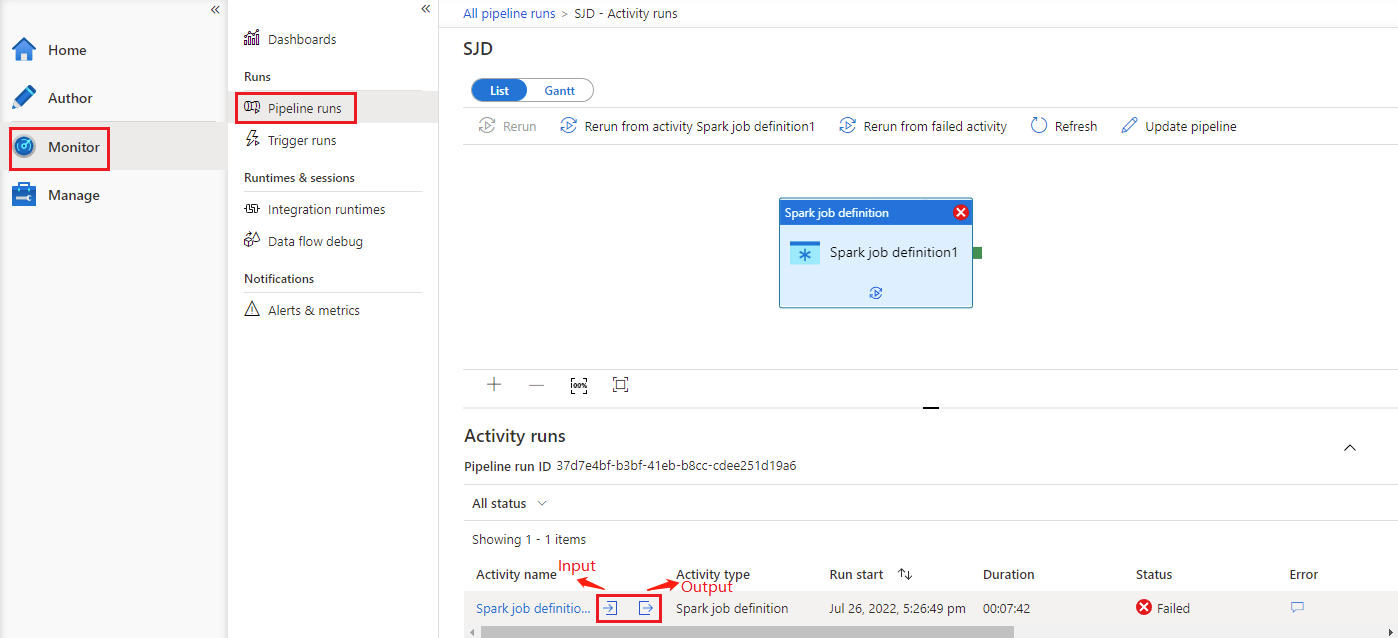
U kunt de invoer of uitvoer van de notebookactiviteit zien door de invoer- of uitvoerknop te selecteren. Als uw pijplijn is mislukt met een gebruikersfout, selecteert u de uitvoer om het resultaatveld te controleren om de gedetailleerde tracering van gebruikersfouten te bekijken.