Ondersteunde bestandsindelingen en compressiecodecs in Azure Data Factory en Synapse Analytics (verouderd)
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Dit artikel is van toepassing op de volgende connectors: Amazon S3, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP en SFTP.
Belangrijk
In de service is een nieuw op indeling gebaseerd gegevenssetmodel geïntroduceerd. Zie het bijbehorende indelingsartikel met details:
-
Avro-indeling
-
Binaire indeling
-
Tekstindeling met scheidingstekens
-
JSON-indeling
-
ORC-indeling
-
Parquet-indeling
De restconfiguraties die in dit artikel worden genoemd, worden nog steeds ondersteund voor compatibiliteit met eerdere versies. U wordt aangeraden het nieuwe model in de toekomst te gebruiken.
Tekstopmaak (verouderd)
Notitie
Meer informatie over het nieuwe model in het artikel met tekstindeling met scheidingstekens. De volgende configuraties voor gegevensopslaggegevensset op basis van bestanden worden nog steeds ondersteund voor achterwaartse compatibiliteit. U wordt aangeraden het nieuwe model in de toekomst te gebruiken.
Als u wilt lezen uit een tekstbestand of wilt schrijven naar een tekstbestand, stelt u de type eigenschap in de format sectie van de gegevensset in op TextFormat. U kunt ook de volgende optionele eigenschappen opgeven in het gedeelte format. Raadpleeg het gedeelte TextFormat-voorbeeld voor configuratie-instructies.
| Eigenschappen | Beschrijving | Toegestane waarden | Vereist |
|---|---|---|---|
| columnDelimiter | Het teken dat wordt gebruikt voor het scheiden van kolommen in een bestand. U kunt overwegen om een zeldzaam onafdrukbaar teken te gebruiken dat mogelijk niet in uw gegevens aanwezig is. Geef bijvoorbeeld '\u0001' op, dat het begin van de kop (SOH) vertegenwoordigt. | Er is slechts één teken toegestaan. De standaardwaarde is een komma (','). Als u een Unicode-teken wilt gebruiken, raadpleegt u Unicode-tekens om de bijbehorende code op te halen. |
Nee |
| rowDelimiter | Het teken dat wordt gebruikt voor het scheiden van rijen in een bestand. | Er is slechts één teken toegestaan. De standaardwaarde is een van de volgende leeswaarden ['\r\n', '\r', '\n'] en de schrijfwaarde '\r\n'. | Nee |
| escapeChar | Dit speciale teken wordt gebruikt om een scheidingsteken voor kolommen van de inhoud van het invoerbestand om te zetten. Het is niet mogelijk om zowel escapeChar als quoteChar voor een tabel op te geven. |
Er is slechts één teken toegestaan. Er is geen standaardwaarde. Voorbeeld: als u een komma (',') als kolomscheidingsteken hebt, maar u het kommateken in de tekst wilt hebben (bijvoorbeeld: 'Hallo, wereld'),), kunt u '$' definiëren als escapeteken en de tekenreeks 'Hallo$, wereld' in de bron gebruiken. |
Nee |
| quoteChar | Het teken dat wordt gebruikt om een tekenreekswaarde te citeren. De scheidingstekens voor kolommen en rijen binnen de aanhalingstekens worden beschouwd als onderdeel van de tekenreekswaarde. Deze eigenschap is van toepassing op gegevenssets voor invoer en uitvoer. Het is niet mogelijk om zowel escapeChar als quoteChar voor een tabel op te geven. |
Er is slechts één teken toegestaan. Er is geen standaardwaarde. Als u bijvoorbeeld een komma (',') als kolomscheidingsteken hebt, maar u een komma wilt hebben in de tekst (bijvoorbeeld: <Hallo, wereld>), kunt u ' (dubbele aanhalingsteken) definiëren als aanhalingsteken en de tekenreeks 'Hallo, wereld' in de bron gebruiken. |
Nee |
| nullValue | Een of meer tekens die worden gebruikt om een null-waarde te vertegenwoordigen. | Een of meer tekens. De standaardwaarden zijn '\N' en 'NULL' voor lezen en '\N' voor schrijven. | Nee |
| encodingName | Geef de coderingsnaam op. | Een geldige coderingsnaam. Zie De eigenschap Encoding.EncodingName. Voorbeeld: windows 1250 of shift_jis. De standaardwaarde is UTF-8. | Nee |
| firstRowAsHeader | Hiermee geeft u op of de eerste rij als een header moet worden gezien. Voor een invoergegevensset leest de service de eerste rij als koptekst. Voor een uitvoergegevensset schrijft de service de eerste rij als koptekst. Zie Gebruiksscenario's firstRowAsHeader en skipLineCount voor voorbeeldscenario's. |
Waar False (standaard) |
Nee |
| skipLineCount | Geeft het aantal niet-lege rijen aan dat moet worden overgeslagen bij het lezen van gegevens uit invoerbestanden. Als zowel skipLineCount als firstRowAsHeader is opgegeven, worden de regels eerst overgeslagen en wordt de headerinformatie gelezen uit het invoerbestand. Zie Gebruiksscenario's firstRowAsHeader en skipLineCount voor voorbeeldscenario's. |
Geheel getal | Nee |
| treatEmptyAsNull | Hiermee geeft u aan of null of lege tekenreeks moeten worden behandeld als een null-waarde bij het lezen van gegevens uit een invoerbestand. |
True (standaard) Onwaar |
Nee |
Voorbeeld van TextFormat
In de volgende JSON-definitie voor een gegevensset worden enkele van de optionele eigenschappen opgegeven.
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
Gebruik een escapeChar in plaats van quoteChar, vervang de regel door quoteChar met het volgende escapeChar:
"escapeChar": "$",
Scenario's voor het gebruik van firstRowAsHeader en skipLineCount
- U kopieert vanuit een bron die geen bestand is, naar een tekstbestand en wilt een headerregel toevoegen die de metagegevens van het schema bevat (bijvoorbeeld: SQL-schema). Geef voor
firstRowAsHeader'True' op in de uitvoergegevensset voor dit scenario. - U wilt kopiëren vanuit een tekstbestand met een headerregel naar een sink die geen bestand is en wilt die regel verwijderen. Geef voor
firstRowAsHeader'True' op in de invoergegevensset. - U wilt kopiëren uit een tekstbestand en wilt een paar regels aan het begin overslaan die geen gegevens of headerinformatie bevatten. Geef
skipLineCountop om aan te geven hoeveel regels er moeten worden overgeslagen. Als de rest van het bestand een headerregel bevat, kunt u ookfirstRowAsHeaderopgeven. Als zowelskipLineCountalsfirstRowAsHeaderis opgegeven, worden de regels eerst overgeslagen en wordt de headerinformatie gelezen uit het invoerbestand
JSON-indeling (verouderd)
Notitie
Meer informatie over het nieuwe model uit het JSON-indelingsartikel . De volgende configuraties voor gegevensopslaggegevensset op basis van bestanden worden nog steeds ondersteund voor achterwaartse compatibiliteit. U wordt aangeraden het nieuwe model in de toekomst te gebruiken.
Als u een JSON-bestand wilt importeren/exporteren naar/vanuit Azure Cosmos DB, raadpleegt u het gedeelte JSON-documenten importeren/exporteren in het artikel Gegevens verplaatsen naar/van Azure Cosmos DB.
Als u de JSON-bestanden wilt parseren of de gegevens in JSON-indeling wilt schrijven, stelt u de type eigenschap in de format sectie in op JsonFormat. U kunt ook de volgende optionele eigenschappen opgeven in het gedeelte format. Zie het gedeelte JsonFormat-voorbeeld voor configuratie-instructies.
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| filePattern | Hiermee geeft u het patroon aan van gegevens die zijn opgeslagen in elk JSON-bestand. Toegestane waarden zijn setOfObjects en arrayOfObjects. De standaardwaarde is setOfObjects. Zie het gedeelte JSON-bestandpatronen voor meer informatie over deze patronen. | Nee |
| jsonNodeReference | Als u wilt bladeren en gegevens wilt ophalen uit de objecten in een matrixveld met hetzelfde patroon, geeft u het JSON-pad van die matrix op. Deze eigenschap wordt alleen ondersteund bij het kopiëren van gegevens uit JSON-bestanden. | Nee |
| jsonPathDefinition | Hiermee geeft u de JSON-padexpressie aan voor elke kolomtoewijzing met een aangepaste kolomnaam (begin met een kleine letter). Deze eigenschap wordt alleen ondersteund bij het kopiëren van gegevens uit JSON-bestanden en u kunt gegevens extraheren uit een object of matrix. Voor velden onder het hoofdobject begint u met root $; voor velden binnen de matrix die is gekozen door de eigenschap jsonNodeReference, begint u vanaf het element van de matrix. Zie het gedeelte JsonFormat-voorbeeld voor configuratie-instructies. |
Nee |
| encodingName | Geef de coderingsnaam op. Zie voor de lijst met geldige namen voor versleuteling De eigenschap Encoding.EncodingName. Bijvoorbeeld: windows 1250 of shift_jis. De standaardwaarde is UTF-8. | Nee |
| nestingSeparator | Teken dat wordt gebruikt voor het scheiden van geneste niveaus. De standaardwaarde is '.' (punt). | Nr. |
Notitie
Voor het geval van kruislings toepassen van gegevens in matrix in meerdere rijen (case 1 -> voorbeeld 2 in JsonFormat-voorbeelden), kunt u er alleen voor kiezen om één matrix uit te vouwen met behulp van eigenschap jsonNodeReference.
JSON-bestandpatronen
Copy-activiteit kunt de volgende patronen van JSON-bestanden parseren:
Type I: setOfObjects
Elk bestand bevat één object of meerdere door regels gescheiden/samengevoegde objecten. Wanneer deze optie is geselecteerd in een uitvoergegevensset, produceert de kopieerbewerking een enkel JSON-bestand met één object per regel (door regels gescheiden).
voorbeeld van JSON-bestand met één object
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }voorbeeld van JSON-bestand dat door regels is gescheiden
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}voorbeeld van JSON-bestand met samengevoegde objecten
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Type II: arrayOfObjects
Elk bestand bevat een matrix met objecten.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Voorbeeld van JsonFormat
Voorbeeld 1: gegevens uit JSON-bestanden kopiëren
Voorbeeld 1: gegevens ophalen uit object en matrix
In dit voorbeeld kunt u verwachten dat één JSON-hoofdobject wordt toegewezen aan één record in het tabelresultaat. Als u een JSON-bestand hebt met de volgende inhoud:
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
en u wilt het kopiëren naar een Azure SQL-tabel in de volgende indeling door gegevens te extraheren uit de objecten en matrix:
| Id | deviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | PC | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 13/1/2017 11:24:37 uur |
De invoergegevensset met het type JsonFormat wordt als volgt gedefinieerd: (gedeeltelijke definitie met alleen belangrijke onderdelen). Specifieke opdrachten:
- Het gedeelte
structuredefinieert de aangepaste kolomnamen en het bijbehorende gegevenstype tijdens het converteren van gegevens in tabelvorm. Dit gedeelte is optioneel, tenzij u kolommen moet toewijzen. Zie Kolommen van brongegevenssets toewijzen aan doelgegevenssetkolommen voor meer informatie. - Met
jsonPathDefinitiongeeft u het JSON-pad op voor elke kolom die aangeeft waar de gegevens moeten worden opgehaald. Als u gegevens uit een matrix wilt kopiëren, kunt u dearray[x].propertywaarde van de opgegeven eigenschap uit hetxthobject extraheren of gebruikenarray[*].propertyom de waarde te vinden uit elk object dat een dergelijke eigenschap bevat.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
Voorbeeld 2: meerdere objecten met hetzelfde patroon uit een matrix toepassen
In dit voorbeeld probeert u een JSON-hoofdobject te transformeren naar meerdere records in een tabelresultaat. Als u een JSON-bestand hebt met de volgende inhoud:
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
en u wilt het kopiëren naar een Azure SQL-tabel in de volgende indeling, door de gegevens binnen de matrix af te vlakken en samen te voegen met de algemene root-gegevens:
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
De invoergegevensset met het type JsonFormat wordt als volgt gedefinieerd: (gedeeltelijke definitie met alleen belangrijke onderdelen). Specifieke opdrachten:
- Het gedeelte
structuredefinieert de aangepaste kolomnamen en het bijbehorende gegevenstype tijdens het converteren van gegevens in tabelvorm. Dit gedeelte is optioneel, tenzij u kolommen moet toewijzen. Zie Kolommen van brongegevenssets toewijzen aan doelgegevenssetkolommen voor meer informatie. -
jsonNodeReferencegeeft aan dat gegevens uit de objecten worden herhaald en geëxtraheerd met hetzelfde patroon onder matrixorderlines. - Met
jsonPathDefinitiongeeft u het JSON-pad op voor elke kolom die aangeeft waar de gegevens moeten worden opgehaald. In dit voorbeeld , en zich onder het hoofdobject bevinden met JSON-pad beginnend met$., terwijlorder_pdenorder_pricezijn gedefinieerd met pad afgeleid van het matrixelement zonder$..cityorderdateordernumber
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
Houd rekening met de volgende punten:
- Als de
structureenjsonPathDefinitionniet zijn gedefinieerd in de gegevensset, detecteert de kopieeractiviteit het schema van het eerste object en wordt het hele object platgemaakt. - Als de JSON-invoer een matrix heeft, zet de kopieerbewerking de volledige matrix-waarde standaard om in een tekenreeks. U kunt ervoor kiezen om er gegevens uit op te halen met behulp van
jsonNodeReferenceen/ofjsonPathDefinition, of deze stap over te slaan door deze niet op te geven injsonPathDefinition. - Als er dubbele namen op hetzelfde niveau voorkomen, gebruikt de kopieerbewerking de laatste.
- Eigenschapnamen zijn hoofdlettergevoelig. Twee eigenschappen met dezelfde naam maar met een verschil in hoofdletters en kleine letters worden behandeld als twee afzonderlijke eigenschappen.
Voorbeeld 2: gegevens schrijven naar een JSON-bestand
Als u de volgende tabel in SQL Database hebt:
| Id | order_date | order_price | order_by |
|---|---|---|---|
| 1 | 20170119 | 2000 | David |
| 2 | 20170120 | 3500 | Patrick |
| 3 | 20170121 | 4000 | Jason |
en voor elke record verwacht u in de volgende indeling naar een JSON-object te schrijven:
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
De uitvoergegevensset met het type JsonFormat wordt als volgt gedefinieerd: (gedeeltelijke definitie met alleen belangrijke onderdelen).
structure In sectie worden de aangepaste eigenschapsnamen in het doelbestand nestingSeparator gedefinieerd (standaard is '.') gebruikt om de nestlaag te identificeren op basis van de naam. Dit gedeelte is optioneel, tenzij u de naam van de eigenschap wilt wijzigen ten opzichte van de naam van de bronkolom of sommige eigenschappen wilt nesten.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Parquet-indeling (verouderd)
Notitie
Meer informatie over het nieuwe model in parquet-indelingsartikel . De volgende configuraties voor gegevensopslaggegevensset op basis van bestanden worden nog steeds ondersteund voor achterwaartse compatibiliteit. U wordt aangeraden het nieuwe model in de toekomst te gebruiken.
Als u de Parquet-bestanden wilt parseren of de gegevens in Parquet-indeling wilt schrijven, stelt u de formattype eigenschap in op ParquetFormat. U hoeft geen eigenschappen op te geven in het gedeelte Indeling binnen het gedeelte typeProperties. Voorbeeld:
"format":
{
"type": "ParquetFormat"
}
Let op de volgende punten:
- Complexe gegevenstypen worden niet ondersteund (MAP, LIST).
- Witruimte in kolomnaam wordt niet ondersteund.
- Parquet-bestanden hebben de volgende opties voor compressie: NONE, SNAPPY, GZIP en LZO. De service ondersteunt het lezen van gegevens uit parquet-bestanden in een van deze gecomprimeerde indelingen, met uitzondering van LZO. Hierbij wordt de compressiecodec in de metagegevens gebruikt om de gegevens te lezen. Wanneer u echter naar een Parquet-bestand schrijft, kiest de service SNAPPY. Dit is de standaardindeling voor Parquet. Er is momenteel geen optie om dit gedrag te overschrijven.
Belangrijk
Voor kopie die mogelijk is door zelf-hostende Integration Runtime, bijvoorbeeld tussen on-premises en cloudgegevensarchieven, moet u de 64-bits JRE 8 (Java Runtime Environment) of OpenJDK op uw IR-computer installeren als u parquet-bestanden niet naar behoren kopieert. Zie de volgende alinea met meer informatie.
Voor kopiëren die wordt uitgevoerd op zelf-hostende IR met Parquet-bestandsserialisatie/deserialisatie, zoekt de service de Java-runtime door eerst het register (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) voor JRE te controleren, indien niet gevonden, ten tweede de systeemvariabele JAVA_HOME voor OpenJDK te controleren.
- Jre gebruiken: voor de 64-bits IR is 64-bits JRE vereist. U vindt het hier.
- OpenJDK gebruiken: deze wordt ondersteund sinds IR versie 3.13. Verpakt de jvm.dll met alle andere vereiste assembly's van OpenJDK in een zelf-hostende IR-machine en stel de omgevingsvariabele van het systeem dienovereenkomstig in JAVA_HOME.
Tip
Als u gegevens kopieert naar/van Parquet-indeling met behulp van zelf-hostende Integration Runtime en de fout 'Er is een fout opgetreden bij het aanroepen van Java, bericht: java.lang.OutOfMemoryError:Java heap space', kunt u een omgevingsvariabele _JAVA_OPTIONS toevoegen op de computer waarop de zelf-hostende IR wordt gehost om de minimale/maximale heapgrootte voor JVM aan te passen om dergelijke kopie mogelijk te maken en de pijplijn opnieuw uit te voeren.
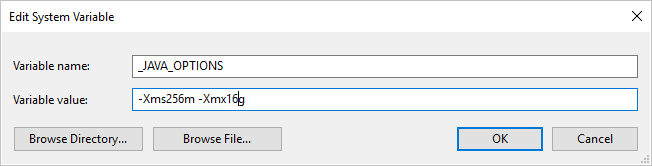
Voorbeeld: variabele _JAVA_OPTIONS instellen met waarde -Xms256m -Xmx16g. De vlag Xms geeft de eerste geheugentoewijzingsgroep voor een Java Virtual Machine (JVM) op, terwijl Xmx de maximale geheugentoewijzingsgroep wordt opgegeven. Dit betekent dat JVM wordt gestart met Xms een hoeveelheid geheugen en een maximale Xmx hoeveelheid geheugen kan gebruiken. De service gebruikt standaard min. 64 MB en maximaal 1G.
Toewijzing van gegevenstypen voor Parquet-bestanden
| Tussentijdse servicegegevenstype | Parquet Primitive-type | Oorspronkelijk Parquet-type (deserialiseren) | Oorspronkelijk Parquet-type (serialiseren) |
|---|---|---|---|
| Booleaanse waarde | Booleaanse waarde | N.v.t. | N.v.t. |
| SByte | Int32 | Int8 | Int8 |
| Byte | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Int64/Binary | UInt64 | Decimal |
| Eén | Float | N.v.t. | N.v.t. |
| Dubbel | Dubbel | N.v.t. | N.v.t. |
| Decimal | Binary | Decimal | Decimaal |
| String | Binary | Utf8 | Utf8 |
| Datum en tijd | Int96 | N.v.t. | N.v.t. |
| TimeSpan | Int96 | N.v.t. | N.v.t. |
| DateTimeOffset | Int96 | N.v.t. | N.v.t. |
| ByteArray | Binary | N.v.t. | N.v.t. |
| Guid | Binary | Utf8 | Utf8 |
| Char | Binary | Utf8 | Utf8 |
| CharArray | Niet ondersteund | N.v.t. | N.v.t. |
ORC-indeling (verouderd)
Notitie
Meer informatie over het nieuwe model in orc-indelingsartikel . De volgende configuraties voor gegevensopslaggegevensset op basis van bestanden worden nog steeds ondersteund voor achterwaartse compatibiliteit. U wordt aangeraden het nieuwe model in de toekomst te gebruiken.
Als u de ORC-bestanden wilt parseren of de gegevens in ORC-indeling wilt schrijven, stelt u de formattype eigenschap in op OrcFormat. U hoeft geen eigenschappen op te geven in het gedeelte Indeling binnen het gedeelte typeProperties. Voorbeeld:
"format":
{
"type": "OrcFormat"
}
Let op de volgende punten:
- Complexe gegevenstypen worden niet ondersteund (STRUCT, MAP, LIST, UNION).
- Witruimte in kolomnaam wordt niet ondersteund.
- Een ORC-bestand heeft drie opties voor compressie: NONE, ZLIB, SNAPPY. De service ondersteunt het lezen van gegevens uit ORC-bestanden in een van deze gecomprimeerde indelingen. Hierbij wordt de compressiecodec in de metagegevens gebruikt om de gegevens te lezen. Wanneer u echter naar een ORC-bestand schrijft, kiest de service ZLIB. Dit is de standaardinstelling voor ORC. Er is momenteel geen optie om dit gedrag te overschrijven.
Belangrijk
Voor kopie die mogelijk is door zelf-hostende Integration Runtime, bijvoorbeeld tussen on-premises en cloudgegevensarchieven, moet u de 64-bits JRE 8 (Java Runtime Environment) of OpenJDK installeren op uw IR-computer als u geen ORC-bestanden kopieert. Zie de volgende alinea met meer informatie.
Voor kopiëren die wordt uitgevoerd op zelf-hostende IR met ORC-bestandsserialisatie/deserialisatie, zoekt de service de Java-runtime door eerst het register (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) voor JRE te controleren, indien niet gevonden, ten tweede de systeemvariabele JAVA_HOME voor OpenJDK te controleren.
- Jre gebruiken: voor de 64-bits IR is 64-bits JRE vereist. U vindt het hier.
- OpenJDK gebruiken: deze wordt ondersteund sinds IR versie 3.13. Verpakt de jvm.dll met alle andere vereiste assembly's van OpenJDK in een zelf-hostende IR-machine en stel de omgevingsvariabele van het systeem dienovereenkomstig in JAVA_HOME.
Toewijzing van gegevenstypen voor ORC-bestanden
| Tussentijdse servicegegevenstype | ORC-typen |
|---|---|
| Booleaanse waarde | Booleaanse waarde |
| SByte | Byte |
| Byte | Kort |
| Int16 | Kort |
| UInt16 | Int |
| Int32 | Int |
| UInt32 | Lang |
| Int64 | Lang |
| UInt64 | String |
| Eén | Float |
| Dubbel | Dubbel |
| Decimal | Decimaal |
| String | String |
| Datum en tijd | Tijdstempel |
| DateTimeOffset | Tijdstempel |
| TimeSpan | Tijdstempel |
| ByteArray | Binary |
| Guid | String |
| Char | Teken(1) |
AVRO-indeling (verouderd)
Notitie
Meer informatie over het nieuwe model in avro-indelingsartikel . De volgende configuraties voor gegevensopslaggegevensset op basis van bestanden worden nog steeds ondersteund voor achterwaartse compatibiliteit. U wordt aangeraden het nieuwe model in de toekomst te gebruiken.
Als u de Avro-bestanden wilt parseren of de gegevens in Avro-indeling wilt schrijven, stelt u de formattype eigenschap in op AvroFormat. U hoeft geen eigenschappen op te geven in het gedeelte Indeling binnen het gedeelte typeProperties. Voorbeeld:
"format":
{
"type": "AvroFormat",
}
Als u de Avro-indeling in een Hive-tabel wilt gebruiken, raadpleegt u de zelfstudie van Apache Hive.
Let op de volgende punten:
- Complexe gegevenstypen worden niet ondersteund (records, opsommingen, matrices, kaarten, samenvoegingen en vast).
Ondersteuning voor compressie (verouderd)
De service ondersteunt het comprimeren/decomprimeren van gegevens tijdens het kopiëren. Wanneer u een eigenschap opgeeft in een invoergegevensset, leest de kopieeractiviteit de gecomprimeerde gegevens uit de bron en decomprimeert deze. Wanneer u de eigenschap opgeeft compression in een uitvoergegevensset, wordt de kopieeractiviteit gecomprimeerd en vervolgens gegevens naar de sink geschreven. Hier volgen enkele voorbeeldscenario's:
- Lees gecomprimeerde GZIP-gegevens uit een Azure-blob, decomprimeren en resultaatgegevens schrijven naar Azure SQL Database. U definieert de Azure Blob-invoergegevensset met de
compressiontypeeigenschap als GZIP. - Lees gegevens uit een bestand met tekst zonder opmaak uit het on-premises bestandssysteem, comprimeer het met behulp van de GZip-indeling en schrijf de gecomprimeerde gegevens naar een Azure-blob. U definieert een Azure Blob-uitvoergegevensset met de
compressiontypeeigenschap GZip. - Lees .zip bestand van de FTP-server, decomprim het om de bestanden binnen te halen en deze bestanden in Azure Data Lake Store te landen. U definieert een FTP-invoergegevensset met de
compressiontypeeigenschap ZipDeflate. - Lees een met GZIP gecomprimeerde gegevens uit een Azure-blob, decomprimeert deze, comprimeert deze met BZIP2 en schrijft resultaatgegevens naar een Azure-blob. U definieert de Azure Blob-invoergegevensset die
compressiontypeis ingesteld op GZIP en de uitvoergegevensset diecompressiontypeis ingesteld op BZIP2.
Als u compressie voor een gegevensset wilt opgeven, gebruikt u de compressie-eigenschap in de JSON van de gegevensset, zoals in het volgende voorbeeld:
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
De compressiesectie heeft twee eigenschappen:
Type: de compressiecodec, die GZIP, Deflate, BZIP2 of ZipDeflate kan zijn. Opmerking wanneer u kopieeractiviteit gebruikt om ZipDeflate-bestanden te decomprimeren en schrijven naar het op bestanden gebaseerde sinkgegevensarchief, worden bestanden uitgepakt naar de map:
<path specified in dataset>/<folder named as source zip file>/.Niveau: de compressieverhouding, die optimaal of snelst kan zijn.
Snelste: De compressiebewerking moet zo snel mogelijk worden voltooid, zelfs als het resulterende bestand niet optimaal is gecomprimeerd.
Optimaal: De compressiebewerking moet optimaal worden gecomprimeerd, zelfs als het langer duurt om de bewerking te voltooien.
Zie het onderwerp Compressieniveau voor meer informatie.
Notitie
Compressie-instellingen worden niet ondersteund voor gegevens in avroFormat, OrcFormat of ParquetFormat. Bij het lezen van bestanden in deze indelingen detecteert en gebruikt de service de compressiecodec in de metagegevens. Bij het schrijven naar bestanden in deze indelingen kiest de service de standaardcompressiecodec voor die indeling. Bijvoorbeeld ZLIB voor OrcFormat en SNAPPY voor ParquetFormat.
Niet-ondersteunde bestandstypen en compressieindelingen
U kunt de uitbreidbaarheidsfuncties gebruiken om bestanden te transformeren die niet worden ondersteund. Twee opties zijn Onder andere Azure Functions en aangepaste taken met behulp van Azure Batch.
U kunt een voorbeeld zien waarin een Azure-functie wordt gebruikt om de inhoud van een tar-bestand te extraheren. Zie Azure Functions-activiteit voor meer informatie.
U kunt deze functionaliteit ook bouwen met behulp van een aangepaste dotnet-activiteit. Meer informatie is hier beschikbaar
Gerelateerde inhoud
Meer informatie over de meest recente ondersteunde bestandsindelingen en compressies van ondersteunde bestandsindelingen en compressies.