Een trigger maken waarmee een pijplijn wordt uitgevoerd als reactie op een opslag gebeurtenis
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel worden de opslag gebeurtenistriggers beschreven die u kunt maken in uw Azure Data Factory- of Azure Synapse Analytics-pijplijnen.
Gebeurtenisgestuurde architectuur is een gemeenschappelijk gegevensintegratiepatroon dat productie, detectie, verbruik en reactie op gebeurtenissen omvat. Scenario's voor gegevensintegratie vereisen vaak dat klanten pijplijnen activeren die worden geactiveerd vanuit gebeurtenissen in een Azure Storage-account, zoals de aankomst of verwijdering van een bestand in een Azure Blob Storage-account. Data Factory- en Azure Synapse Analytics-pijplijnen integreren systeemeigen met Azure Event Grid, waarmee u pijplijnen op dergelijke gebeurtenissen kunt activeren.
Overwegingen voor triggers voor opslagevenementen
Houd rekening met de volgende punten wanneer u triggers voor opslagevenementen gebruikt:
- De integratie die in dit artikel wordt beschreven, is afhankelijk van Azure Event Grid. Zorg ervoor dat uw abonnement is geregistreerd bij de Event Grid-resourceprovider. Zie Resourceproviders en -typen voor meer informatie. U moet de
Microsoft.EventGrid/eventSubscriptions/actie kunnen uitvoeren. Deze actie maakt deel uit van deEventGrid EventSubscription Contributoringebouwde rol. - Als u deze functie gebruikt in Azure Synapse Analytics, moet u ervoor zorgen dat u ook uw abonnement registreert bij de Data Factory-resourceprovider. Anders krijgt u een bericht met de mededeling dat het maken van een gebeurtenisabonnement is mislukt.
- Als het Blob Storage-account zich achter een privé-eindpunt bevindt en de toegang tot openbare netwerken blokkeert, moet u netwerkregels configureren om communicatie van Blob Storage naar Event Grid toe te staan. U kunt opslagtoegang verlenen tot vertrouwde Azure-services, zoals Event Grid, de volgende opslagdocumentatie of privé-eindpunten configureren voor Event Grid die zijn toegewezen aan een adresruimte voor een virtueel netwerk, volgens de Event Grid-documentatie.
- De opslaggebeurtenistrigger ondersteunt momenteel alleen Azure Data Lake Storage Gen2- en algemeen gebruik 2-opslagaccounts. Als u werkt met SFTP-opslagevenementen (Secure File Transfer Protocol), moet u ook de SFTP-gegevens-API opgeven onder de filtersectie. Vanwege een Beperking van Event Grid biedt Data Factory alleen ondersteuning voor maximaal 500 triggers voor opslagevenementen per opslagaccount.
- Als u een nieuwe trigger voor opslaggebeurtenissen wilt maken of een bestaande wilt wijzigen, moet het Azure-account dat u gebruikt om u aan te melden bij de service en de trigger voor opslaggebeurtenissen te publiceren over de juiste machtiging voor op rollen gebaseerd toegangsbeheer (Azure RBAC) voor het opslagaccount beschikken. Er zijn geen andere machtigingen vereist. Service-principal voor Azure Data Factory en Azure Synapse Analytics heeft geen speciale machtiging nodig voor het opslagaccount of Event Grid. Zie de sectie Op rollen gebaseerd toegangsbeheer voor meer informatie over toegangsbeheer .
- Als u een Azure Resource Manager-vergrendeling hebt toegepast op uw opslagaccount, kan dit van invloed zijn op de mogelijkheid van de blobtrigger om blobs te maken of te verwijderen. Een
ReadOnlyvergrendeling voorkomt zowel het maken als verwijderen, terwijl eenDoNotDeletevergrendeling verwijdering voorkomt. Zorg ervoor dat u rekening houdt met deze beperkingen om eventuele problemen met uw triggers te voorkomen. - Het wordt afgeraden om triggers voor bestands aankomst te activeren als een triggermechanisme van sinks voor gegevensstromen. Gegevensstromen voeren een aantal bestandsnamen en het partitioneren van bestandsverdeeltaken uit in de doelmap die per ongeluk een gebeurtenis voor bestandsaankomst kunnen activeren voordat de volledige verwerking van uw gegevens wordt voltooid.
Een trigger maken met de gebruikersinterface
In deze sectie wordt beschreven hoe u een opslag gebeurtenistrigger maakt in de gebruikersinterface van de Pijplijn van Azure Synapse Analytics en Azure Synapse Analytics.
Ga naar het tabblad Bewerken in Data Factory of het tabblad Integreren in Azure Synapse Analytics.
Selecteer Trigger in het menu en selecteer Vervolgens Nieuw/Bewerken.
Selecteer op de pagina Triggers toevoegen de optie Trigger kiezen en selecteer vervolgens + Nieuw.
Selecteer het triggertype Storage-gebeurtenissen.
Selecteer uw opslagaccount in de vervolgkeuzelijst van het Azure-abonnement of handmatig met behulp van de resource-id van het opslagaccount. Kies de container waarop u de gebeurtenissen wilt laten plaatsvinden. Containerselectie is vereist, maar het selecteren van alle containers kan leiden tot een groot aantal gebeurtenissen.
Met de
Blob path begins withenBlob path ends witheigenschappen kunt u de containers, mappen en blobnamen opgeven waarvoor u gebeurtenissen wilt ontvangen. Voor de trigger voor opslagevenementen moet ten minste één van deze eigenschappen worden gedefinieerd. U kunt verschillende patronen gebruiken voor zowel alsBlob path begins withBlob path ends witheigenschappen, zoals wordt weergegeven in de voorbeelden verderop in dit artikel.-
Blob path begins with: Het blobpad moet beginnen met een mappad. Geldige waarden zijn onder andere2018/en2018/april/shoes.csv. Dit veld kan niet worden geselecteerd als er geen container is geselecteerd. -
Blob path ends with: Het blobpad moet eindigen met een bestandsnaam of extensie. Geldige waarden zijn onder andereshoes.csven.csv. Namen van containers en mappen, indien opgegeven, moeten worden gescheiden door een/blobs/segment. Een container met de naamorderskan bijvoorbeeld een waarde hebben van/orders/blobs/2018/april/shoes.csv. Als u een map in een container wilt opgeven, laat u het voorloopteken/weg. Hiermee wordt bijvoorbeeldapril/shoes.csveen gebeurtenis geactiveerd voor elk bestand met de naamshoes.csvin een map die in een container wordt aangeroepenapril.
Houd er rekening mee dat en
Blob path ends withhet enige patroon is dat overeenkomt met het patroon datBlob path begins withis toegestaan in een opslag gebeurtenistrigger. Andere typen jokertekens worden niet ondersteund voor het triggertype.-
Selecteer of uw trigger reageert op een door een blob gemaakte gebeurtenis, een verwijderde blob-gebeurtenis of beide. In uw opgegeven opslaglocatie activeert elke gebeurtenis de Data Factory- en Azure Synapse Analytics-pijplijnen die aan de trigger zijn gekoppeld.
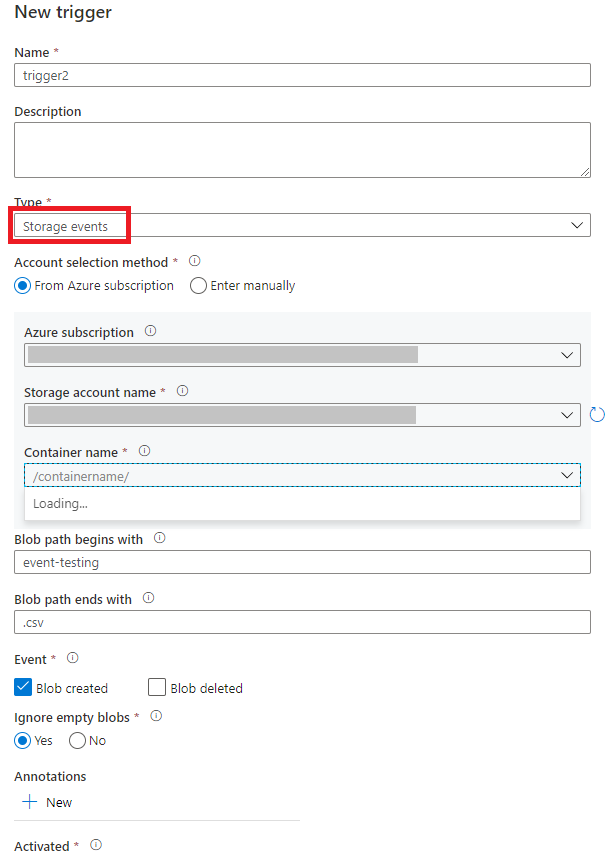
Selecteer of uw trigger blobs met nul bytes negeert.
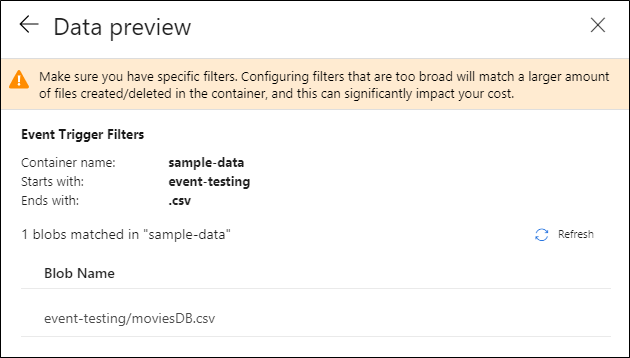
Nadat u de trigger hebt geconfigureerd, selecteert u Volgende: Gegevensvoorbeeld. In dit scherm ziet u de bestaande blobs die overeenkomen met de configuratie van uw opslaggebeurtenistrigger. Zorg ervoor dat u specifieke filters hebt. Het configureren van filters die te breed zijn, kan overeenkomen met een groot aantal bestanden die zijn gemaakt of verwijderd en die van invloed kunnen zijn op uw kosten. Nadat de filtervoorwaarden zijn geverifieerd, selecteert u Voltooien.
Als u een pijplijn aan deze trigger wilt koppelen, gaat u naar het pijplijncanvas en selecteert u Nieuw>/Bewerken activeren. Wanneer het zijvenster wordt weergegeven, selecteert u de vervolgkeuzelijst Trigger kiezen en selecteert u de trigger die u hebt gemaakt. Selecteer Volgende: Gegevensvoorbeeld om te bevestigen dat de configuratie juist is. Selecteer vervolgens Volgende om te controleren of de voorbeeldweergave van de gegevens juist is.
Als uw pijplijn parameters bevat, kunt u deze opgeven in het zijvenster Parameters voor triggeruitvoering. De trigger voor opslaggebeurtenissen legt het mappad en de bestandsnaam van de blob vast in de eigenschappen
@triggerBody().folderPathen@triggerBody().fileName. Als u de waarden van deze eigenschappen in een pijplijn wilt gebruiken, moet u de eigenschappen toewijzen aan pijplijnparameters. Nadat u de eigenschappen hebt toegewezen aan parameters, hebt u toegang tot de waarden die door de trigger zijn vastgelegd via de@pipeline().parameters.parameterNameexpressie in de pijplijn. Zie Referentietriggermetagegevens in pijplijnen voor een gedetailleerde uitleg.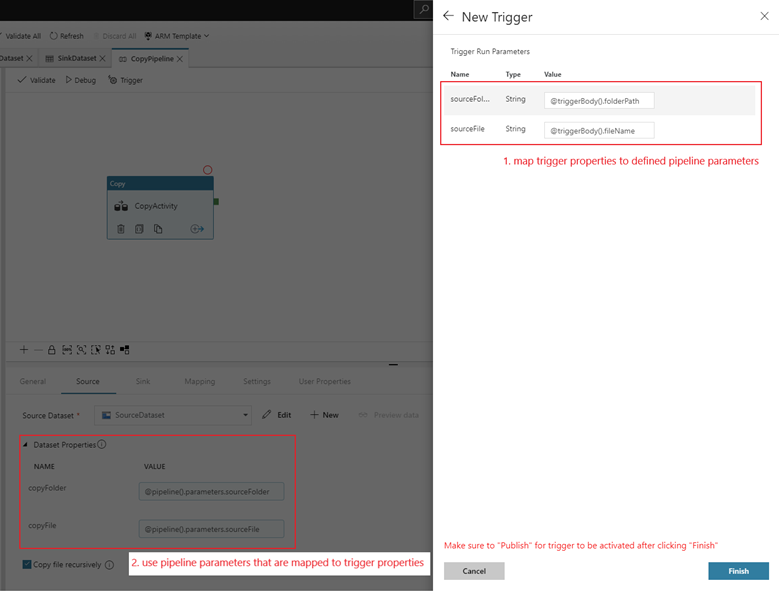
In het voorgaande voorbeeld is de trigger geconfigureerd om te worden geactiveerd wanneer een blobpad dat eindigt op .csv wordt gemaakt in de mapgebeurtenistests in de containervoorbeeldgegevens. De
folderPathenfileNameeigenschappen leggen de locatie van de nieuwe blob vast. Wanneer MoviesDB.csv bijvoorbeeld wordt toegevoegd aan het pad sample-data/event-testing,@triggerBody().folderPathheeft deze een waarde vansample-data/event-testingen@triggerBody().fileNameeen waarde vanmoviesDB.csv. Deze waarden worden in het voorbeeld toegewezen aan de pijplijnparameterssourceFolderensourceFile, die in de pijplijn kunnen worden gebruikt als@pipeline().parameters.sourceFolderrespectievelijk@pipeline().parameters.sourceFile.Nadat u klaar bent, selecteert u Voltooien.


JSON-schema
De volgende tabel bevat een overzicht van de schema-elementen die betrekking hebben op triggers voor opslagevenementen.
| JSON-element | Beschrijving | Type | Toegestane waarden | Vereist |
|---|---|---|---|---|
| bereik | De resource-id van Azure Resource Manager van het opslagaccount. | String | Azure Resource Manager-id | Ja. |
| gebeurtenissen | Het type gebeurtenissen dat ervoor zorgt dat deze trigger wordt geactiveerd. | Matrix |
Microsoft.Storage.BlobCreated, Microsoft.Storage.BlobDeleted |
Ja, elke combinatie van deze waarden. |
blobPathBeginsWith |
Het blobpad moet beginnen met het patroon dat is opgegeven om de trigger te activeren. Hiermee wordt bijvoorbeeld /records/blobs/december/ alleen de trigger voor blobs in de december map onder de records container geactiveerd. |
String | Geef een waarde op voor ten minste één van deze eigenschappen: blobPathBeginsWith of blobPathEndsWith. |
|
blobPathEndsWith |
Het blobpad moet eindigen met het patroon dat is opgegeven om de trigger te activeren. Hiermee wordt bijvoorbeeld december/boxes.csv alleen de trigger geactiveerd voor blobs met de naam boxes in een december map. |
String | Geef een waarde op voor ten minste één van deze eigenschappen: blobPathBeginsWith of blobPathEndsWith. |
|
ignoreEmptyBlobs |
Ongeacht of blobs met nul-byte een pijplijnuitvoering activeren. Dit is standaard ingesteld op true. |
Booleaanse waarde | waar of onwaar | Nee |
Voorbeelden van triggers voor opslagevenementen
In deze sectie vindt u voorbeelden van instellingen voor triggers voor opslagevenementen.
Belangrijk
U moet het /blobs/ segment van het pad opnemen, zoals wordt weergegeven in de volgende voorbeelden, wanneer u een container en map, container en bestand of container, map en bestand opgeeft. De blobPathBeginsWithgebruikersinterface wordt automatisch toegevoegd /blobs/ tussen de map en de containernaam in de trigger-JSON.
| Eigenschappen | Opmerking | Beschrijving |
|---|---|---|
Blob path begins with |
/containername/ |
Ontvangt gebeurtenissen voor elke blob in de container. |
Blob path begins with |
/containername/blobs/foldername/ |
Ontvangt gebeurtenissen voor blobs in de containername container en foldername map. |
Blob path begins with |
/containername/blobs/foldername/subfoldername/ |
U kunt ook verwijzen naar een submap. |
Blob path begins with |
/containername/blobs/foldername/file.txt |
Ontvangt gebeurtenissen voor een blob met de naam file.txt in de foldername map onder de containername container. |
Blob path ends with |
file.txt |
Ontvangt gebeurtenissen voor een blob met de naam file.txt in een willekeurig pad. |
Blob path ends with |
/containername/blobs/file.txt |
Ontvangt gebeurtenissen voor een blob met de naam file.txt onder de container containername. |
Blob path ends with |
foldername/file.txt |
Ontvangt gebeurtenissen voor een blob met de naam file.txt in de foldername map onder een container. |
Op rollen gebaseerd toegangsbeheer
Data Factory- en Azure Synapse Analytics-pijplijnen maken gebruik van op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) om ervoor te zorgen dat onbevoegde toegang tot luisteren, abonneren op updates van en triggerpijplijnen die zijn gekoppeld aan blobgebeurtenissen, strikt verboden zijn.
- Als u een nieuwe opslag gebeurtenistrigger wilt maken of een bestaande wilt bijwerken, moet het Azure-account dat is aangemeld bij de service, over de juiste toegang tot het relevante opslagaccount beschikken. Anders mislukt de bewerking met het bericht 'Toegang geweigerd'.
- Data Factory en Azure Synapse Analytics hebben geen speciale machtigingen nodig voor uw Event Grid-exemplaar en u hoeft geen speciale RBAC-machtiging toe te wijzen aan de Data Factory- of Azure Synapse Analytics-service-principal voor de bewerking.
Een van de volgende RBAC-instellingen werkt voor triggers voor opslag gebeurtenis:
- Rol van eigenaar voor het opslagaccount
- Rol Inzender voor het opslagaccount
-
Microsoft.EventGrid/EventSubscriptions/Writemachtiging voor het opslagaccount/subscriptions/####/resourceGroups/####/providers/Microsoft.Storage/storageAccounts/storageAccountName
Specifiek:
- Wanneer u bijvoorbeeld in de data factory ontwerpt (in de ontwikkelomgeving), moet het Azure-account dat is aangemeld, de voorgaande machtiging hebben.
- Wanneer u publiceert via continue integratie en continue levering, moet het account dat wordt gebruikt voor het publiceren van de Azure Resource Manager-sjabloon in de test- of productiefactory de voorgaande machtiging hebben.
Als u wilt weten hoe de service de twee beloften levert, gaan we een stap terug en kijken we achter de schermen. Hier volgen de werkstromen op hoog niveau voor integratie tussen Data Factory/Azure Synapse Analytics, Storage en Event Grid.
Een nieuwe trigger voor opslag gebeurtenis maken
In deze werkstroom op hoog niveau wordt beschreven hoe Data Factory communiceert met Event Grid om een trigger voor opslaggebeurtenissen te maken. De gegevensstroom is hetzelfde in Azure Synapse Analytics, waarbij Azure Synapse Analytics-pijplijnen de rol van de data factory in het volgende diagram nemen.
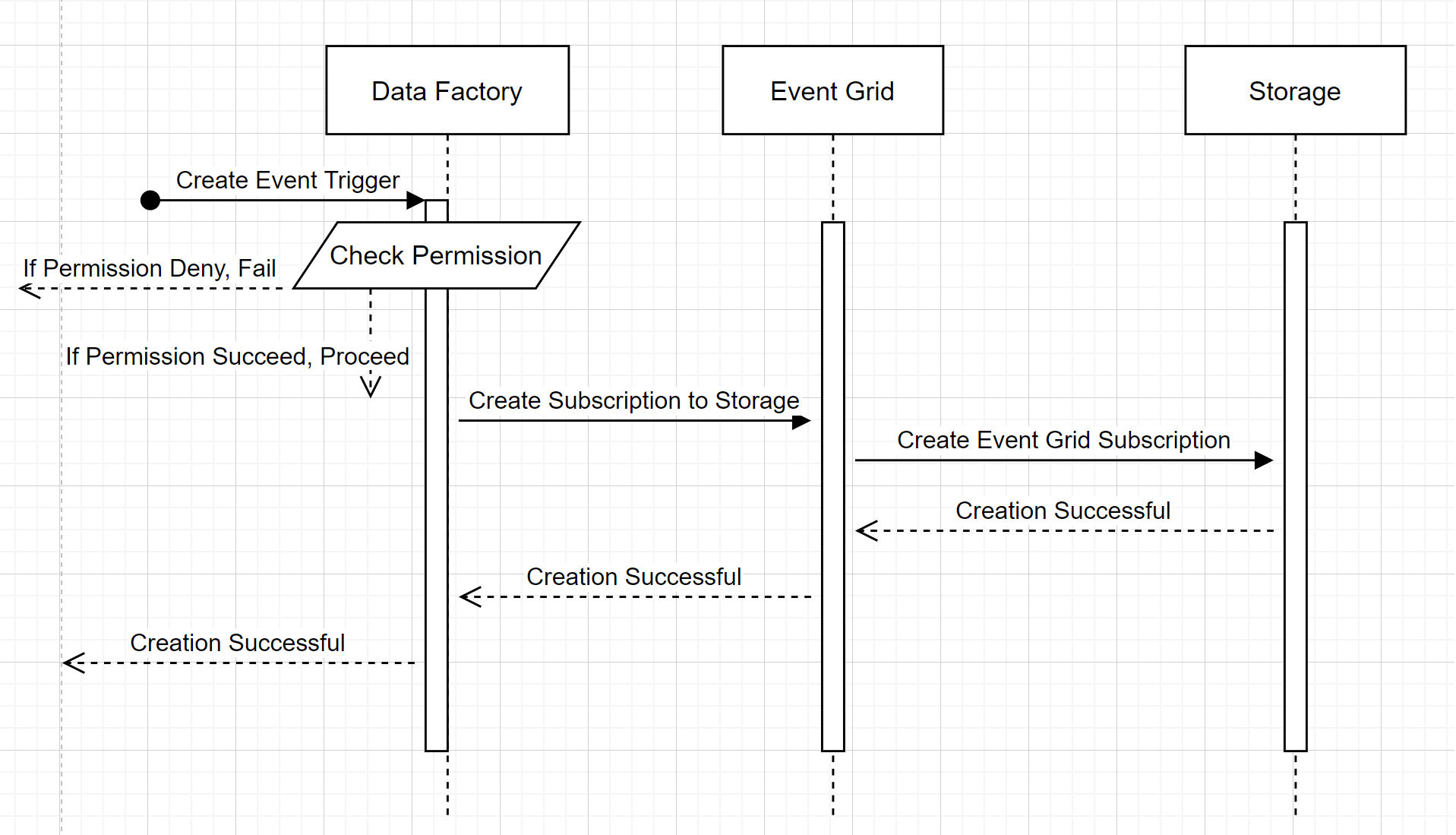
Twee merkbare bijschriften van de werkstromen:
- Data Factory en Azure Synapse Analytics maken geen rechtstreeks contact met het opslagaccount. De aanvraag voor het maken van een abonnement wordt in plaats daarvan doorGegeven en verwerkt door Event Grid. De service heeft geen toegang nodig tot het opslagaccount voor deze stap.
- Toegangsbeheer en machtigingscontrole vinden plaats in de service. Voordat de service een aanvraag verzendt om u te abonneren op een opslag gebeurtenis, controleert deze de machtiging voor de gebruiker. In het bijzonder wordt gecontroleerd of het Azure-account dat is aangemeld en probeert de trigger voor opslaggebeurtenissen te maken, de juiste toegang heeft tot het relevante opslagaccount. Als de machtigingscontrole mislukt, mislukt het maken van triggers ook.
Pijplijnuitvoering voor opslag gebeurtenistrigger
In deze werkstroom op hoog niveau wordt beschreven hoe pijplijnen voor opslaggebeurtenistriggers worden uitgevoerd via Event Grid. Voor Azure Synapse Analytics is de gegevensstroom hetzelfde, waarbij Azure Synapse Analytics-pijplijnen de rol van Data Factory hebben in het volgende diagram.
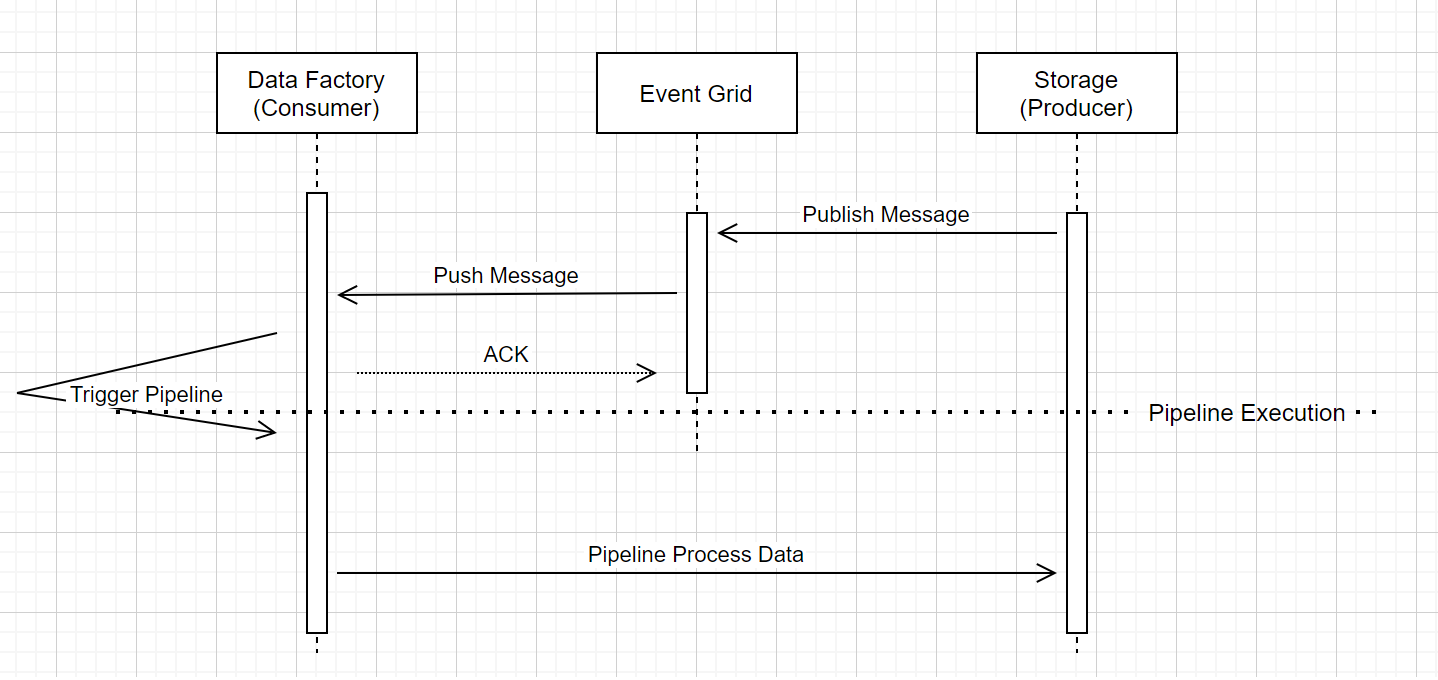
Drie merkbare bijschriften in de werkstroom zijn gerelateerd aan gebeurtenistriggers binnen de service:
Event Grid maakt gebruik van een Push-model dat het bericht zo snel mogelijk doorsturen wanneer de opslag het bericht in het systeem laat vallen. Deze benadering verschilt van een berichtensysteem, zoals Kafka, waarbij een Pull-systeem wordt gebruikt.
De gebeurtenistrigger fungeert als een actieve listener voor het binnenkomende bericht en activeert de bijbehorende pijplijn correct.
De trigger voor de opslag gebeurtenis zelf maakt geen direct contact met het opslagaccount.
- Als u een Copy-activiteit of een andere activiteit in de pijplijn hebt om de gegevens in het opslagaccount te verwerken, maakt de service rechtstreeks contact met het opslagaccount met behulp van de referenties die zijn opgeslagen in de gekoppelde service. Zorg ervoor dat de gekoppelde service juist is ingesteld.
- Als u geen verwijzing maakt naar het opslagaccount in de pijplijn, hoeft u de service geen toestemming te geven voor toegang tot het opslagaccount.
Gerelateerde inhoud
- Zie Pijplijnuitvoering en triggers voor meer informatie over triggers.
- Zie Referentietriggermetagegevens in pijplijnuitvoeringen om te verwijzen naar metagegevens van triggers in een pijplijn.