Azure Data Factory gebruiken om gegevens te migreren van een on-premises Hadoop-cluster naar Azure Storage
VAN TOEPASSING OP:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Azure Data Factory biedt een krachtig, robuust en rendabel mechanisme voor het migreren van gegevens op schaal van on-premises HDFS naar Azure Blob Storage of Azure Data Lake Storage Gen2.
Data Factory biedt twee basismethoden voor het migreren van gegevens van on-premises HDFS naar Azure. U kunt de benadering selecteren op basis van uw scenario.
- Data Factory DistCp-modus (aanbevolen): In Data Factory kunt u DistCp (gedistribueerde kopie) gebruiken om bestanden ongewijzigd te kopiëren naar Azure Blob Storage (inclusief gefaseerde kopie) of Azure Data Lake Store Gen2. Gebruik Data Factory geïntegreerd met DistCp om te profiteren van een bestaand krachtig cluster om de beste kopieerdoorvoer te bereiken. U krijgt ook het voordeel van flexibele planning en een uniforme bewakingservaring van Data Factory. Afhankelijk van uw Data Factory-configuratie maakt de kopieeractiviteit automatisch een DistCp-opdracht, verzendt u de gegevens naar uw Hadoop-cluster en bewaakt u vervolgens de kopieerstatus. We raden de Data Factory DistCp-modus aan voor het migreren van gegevens van een on-premises Hadoop-cluster naar Azure.
- Systeemeigen integratieruntimemodus van Data Factory: DistCp is geen optie in alle scenario's. In een azure Virtual Networks-omgeving biedt het hulpprogramma DistCp bijvoorbeeld geen ondersteuning voor privépeering van Azure ExpressRoute met een eindpunt voor een virtueel Azure Storage-netwerk. Bovendien wilt u in sommige gevallen uw bestaande Hadoop-cluster niet gebruiken als engine voor het migreren van gegevens, zodat u geen zware belasting op uw cluster plaatst, wat de prestaties van bestaande ETL-taken kan beïnvloeden. In plaats daarvan kunt u de systeemeigen mogelijkheid van de Data Factory-integratieruntime gebruiken als de engine waarmee gegevens van on-premises HDFS naar Azure worden gekopieerd.
Dit artikel bevat de volgende informatie over beide benaderingen:
- Voorstelling
- Tolerantie voor kopiëren
- Netwerkbeveiliging
- Oplossingsarchitectuur op hoog niveau
- Best practices voor implementatie
Prestaties
In de Data Factory DistCp-modus is de doorvoer hetzelfde als als als u het hulpprogramma DistCp onafhankelijk gebruikt. De Data Factory DistCp-modus maximaliseert de capaciteit van uw bestaande Hadoop-cluster. U kunt DistCp gebruiken voor het kopiëren van grote interclusters of intraclusters.
DistCp maakt gebruik van MapReduce om de distributie, foutafhandeling en herstel en rapportage door te voeren. Hiermee wordt een lijst met bestanden en mappen uitgebreid tot invoer voor taaktoewijzing. Elke taak kopieert een bestandspartitie die is opgegeven in de bronlijst. U kunt Data Factory geïntegreerd met DistCp gebruiken om pijplijnen te bouwen om uw netwerkbandbreedte, opslag-IOPS en bandbreedte volledig te gebruiken om de doorvoer van gegevensverplaatsing voor uw omgeving te maximaliseren.
De systeemeigen integratieruntimemodus van Data Factory biedt ook parallelle uitvoering op verschillende niveaus. U kunt parallellisme gebruiken om uw netwerkbandbreedte, opslag-IOPS en bandbreedte volledig te gebruiken om de doorvoer van gegevensverplaatsing te maximaliseren:
- Eén kopieeractiviteit kan profiteren van schaalbare rekenresources. Met een zelf-hostende Integration Runtime kunt u de machine handmatig omhoog schalen of uitschalen naar meerdere computers (maximaal vier knooppunten). Eén kopieeractiviteit partitioneert het bestand dat is ingesteld op alle knooppunten.
- Eén kopieeractiviteit leest van en schrijft naar het gegevensarchief met behulp van meerdere threads.
- De controlestroom van Data Factory kan meerdere kopieeractiviteiten parallel starten. U kunt bijvoorbeeld een For Each-lus gebruiken.
Zie de prestatiehandleiding voor kopieeractiviteiten voor meer informatie.
Flexibiliteit
In de Data Factory DistCp-modus kunt u verschillende DistCp-opdrachtregelparameters gebruiken (bijvoorbeeld -ifouten negeren of -updateschrijven wanneer het bronbestand en het doelbestand in grootte verschillen) voor verschillende tolerantieniveaus.
In de systeemeigen integratieruntimemodus van Data Factory, in één uitvoering van een kopieeractiviteit, beschikt Data Factory over een ingebouwd mechanisme voor opnieuw proberen. Het kan een bepaald niveau van tijdelijke fouten in de gegevensarchieven of in het onderliggende netwerk afhandelen.
Wanneer u binaire kopieën uitvoert van on-premises HDFS naar Blob Storage en van on-premises HDFS naar Data Lake Store Gen2, voert Data Factory automatisch controlepunten uit in grote mate. Als een uitvoering van een kopieeractiviteit mislukt of een time-out optreedt, wordt bij een volgende nieuwe poging (zorg ervoor dat het aantal nieuwe pogingen 1 is > ), de kopieerbewerking hervat vanaf het laatste foutpunt in plaats van bij het begin te beginnen.
Netwerkbeveiliging
Data Factory draagt standaard gegevens van on-premises HDFS over naar Blob Storage of Azure Data Lake Storage Gen2 met behulp van een versleutelde verbinding via het HTTPS-protocol. HTTPS biedt gegevensversleuteling tijdens overdracht en voorkomt afluisteren en man-in-the-middle-aanvallen.
Als u niet wilt dat gegevens worden overgedragen via het openbare internet, kunt u voor een hogere beveiliging gegevens overdragen via een privépeeringskoppeling via ExpressRoute.
Architectuur voor de oplossing
In deze afbeelding ziet u hoe u gegevens migreert via het openbare internet:
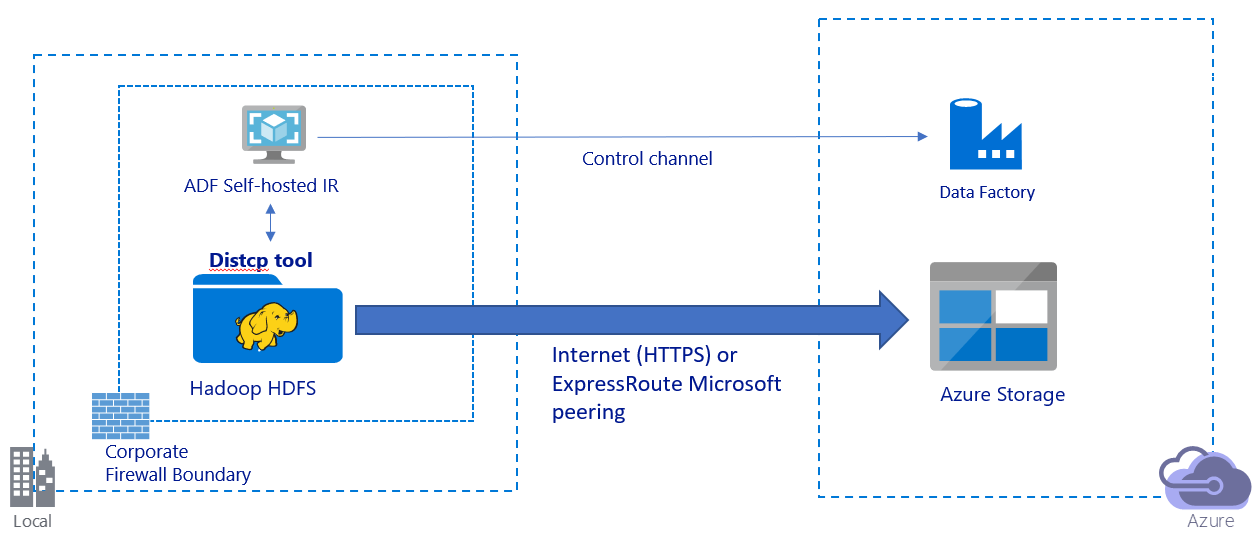
- In deze architectuur worden gegevens veilig overgedragen via HTTPS via het openbare internet.
- We raden u aan de Data Factory DistCp-modus te gebruiken in een openbare netwerkomgeving. U kunt profiteren van een krachtig bestaand cluster om de beste kopieerdoorvoer te bereiken. U krijgt ook het voordeel van flexibele planning en geïntegreerde bewakingservaring van Data Factory.
- Voor deze architectuur moet u de zelf-hostende Integration Runtime van Data Factory installeren op een Windows-computer achter een bedrijfsfirewall om de DistCp-opdracht naar uw Hadoop-cluster te verzenden en de kopieerstatus te bewaken. Omdat de machine niet de engine is die gegevens verplaatst (alleen voor controledoeleinden), heeft de capaciteit van de machine geen invloed op de doorvoer van gegevensverplaatsing.
- Bestaande parameters van de opdracht DistCp worden ondersteund.
In deze afbeelding ziet u hoe u gegevens migreert via een privékoppeling:
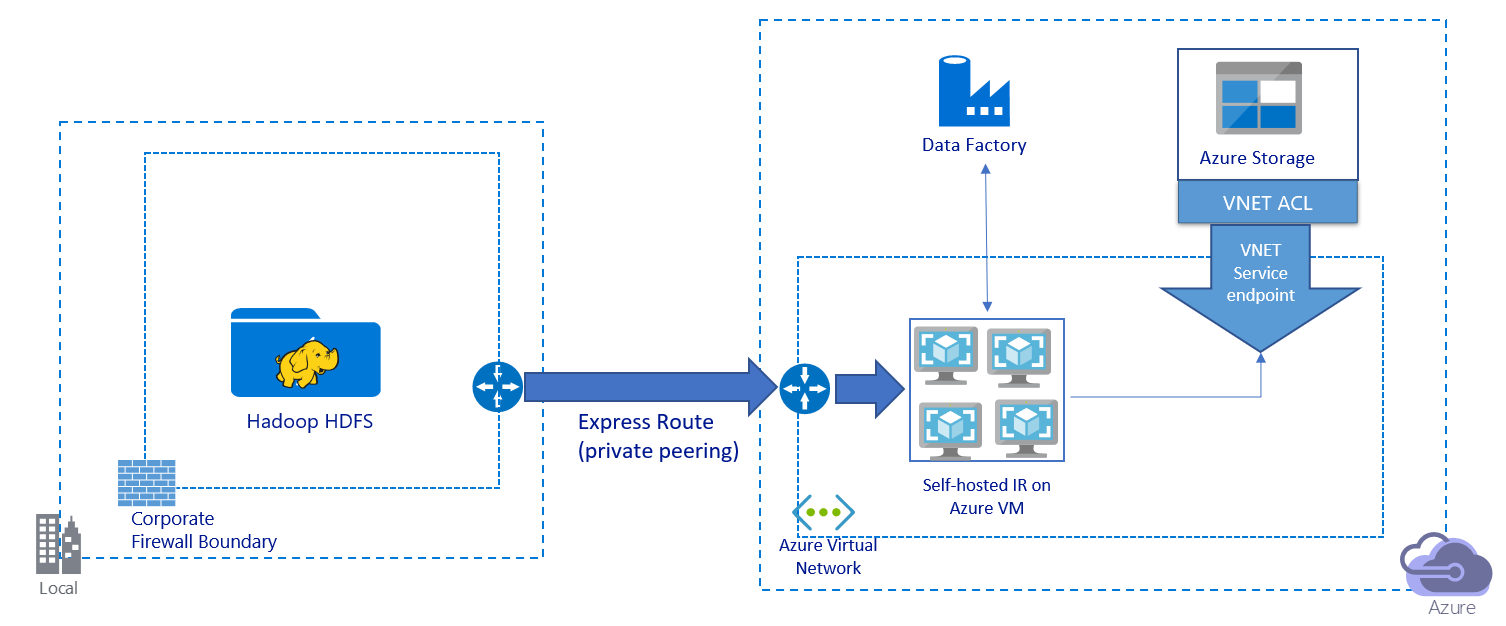
- In deze architectuur worden gegevens gemigreerd via een privé-peeringkoppeling via Azure ExpressRoute. Gegevens gaan nooit via het openbare internet.
- Het hulpprogramma DistCp biedt geen ondersteuning voor persoonlijke ExpressRoute-peering met een virtueel Azure Storage-netwerkeindpunt. U wordt aangeraden de systeemeigen mogelijkheid van Data Factory te gebruiken via de integratieruntime om de gegevens te migreren.
- Voor deze architectuur moet u de zelf-hostende Integration Runtime van Data Factory installeren op een Windows-VM in uw virtuele Azure-netwerk. U kunt uw VIRTUELE machine handmatig omhoog schalen of uitschalen naar meerdere VM's om volledig gebruik te maken van uw netwerk- en opslag-IOPS of bandbreedte.
- De aanbevolen configuratie waarmee u kunt beginnen voor elke Azure-VM (waarbij de zelf-hostende Integration Runtime van Data Factory is geïnstalleerd) is Standard_D32s_v3 met een 32 vCPU en 128 GB geheugen. U kunt het CPU- en geheugengebruik van de VIRTUELE machine bewaken tijdens de gegevensmigratie om te zien of u de VIRTUELE machine omhoog moet schalen voor betere prestaties of om de VM omlaag te schalen om de kosten te verlagen.
- U kunt ook uitschalen door maximaal vier VM-knooppunten te koppelen aan één zelf-hostende Integration Runtime. Met één kopieertaak die wordt uitgevoerd voor een zelf-hostende Integration Runtime, wordt de bestandsset automatisch gepartitioneerd en worden alle VM-knooppunten gebruikt om de bestanden parallel te kopiëren. Voor hoge beschikbaarheid raden we u aan om te beginnen met twee VM-knooppunten om een scenario met één storingspunt te voorkomen tijdens de gegevensmigratie.
- Wanneer u deze architectuur gebruikt, zijn de eerste momentopnamegegevensmigratie en deltagegevensmigratie beschikbaar voor u.
Best practices voor implementatie
We raden u aan deze aanbevolen procedures te volgen wanneer u uw gegevensmigratie implementeert.
Verificatie- en referentiebeheer
- Als u zich wilt verifiëren bij HDFS, kunt u Windows (Kerberos) of Anoniem gebruiken.
- Er worden meerdere verificatietypen ondersteund voor het maken van verbinding met Azure Blob Storage. We raden u ten zeerste aan beheerde identiteiten te gebruiken voor Azure-resources. Op basis van een automatisch beheerde Data Factory-identiteit in Microsoft Entra ID kunt u met beheerde identiteiten pijplijnen configureren zonder referenties in de definitie van de gekoppelde service op te geven. U kunt ook verifiëren bij Blob Storage met behulp van een service-principal, een handtekening voor gedeelde toegang of een sleutel voor een opslagaccount.
- Er worden ook meerdere verificatietypen ondersteund voor het maken van verbinding met Data Lake Storage Gen2. We raden u ten zeerste aan beheerde identiteiten te gebruiken voor Azure-resources, maar u kunt ook een service-principal of een sleutel voor een opslagaccount gebruiken.
- Wanneer u geen beheerde identiteiten voor Azure-resources gebruikt, raden we u ten zeerste aan de referenties op te slaan in Azure Key Vault om het eenvoudiger te maken om sleutels centraal te beheren en te roteren zonder gekoppelde Data Factory-services te wijzigen. Dit is ook een best practice voor CI/CD.
Eerste momentopnamegegevensmigratie
In de Data Factory DistCp-modus kunt u één kopieeractiviteit maken om de DistCp-opdracht te verzenden en verschillende parameters te gebruiken om het gedrag van de initiële gegevensmigratie te beheren.
In de systeemeigen integratieruntimemodus van Data Factory wordt de gegevenspartitie aanbevolen, met name wanneer u meer dan 10 TB aan gegevens migreert. Als u de gegevens wilt partitioneren, gebruikt u de mapnamen in HDFS. Vervolgens kan elke Data Factory-kopieertaak één mappartitie tegelijk kopiëren. U kunt meerdere Data Factory-kopieertaken tegelijk uitvoeren voor betere doorvoer.
Als een van de kopieertaken mislukt vanwege tijdelijke problemen met het netwerk of gegevensarchief, kunt u de mislukte kopieertaak opnieuw uitvoeren om die specifieke partitie opnieuw te laden vanuit HDFS. Andere kopieertaken die andere partities laden, worden niet beïnvloed.
Delta-gegevensmigratie
In de DistCp-modus van Data Factory kunt u de opdrachtregelparameter -updateDistCp gebruiken, gegevens schrijven wanneer het bronbestand en het doelbestand verschillen in grootte, voor deltagegevensmigratie.
In de systeemeigen integratiemodus van Data Factory is de meest presterende manier om nieuwe of gewijzigde bestanden van HDFS te identificeren met behulp van een naamconventie met tijdpartitionering. Wanneer uw gegevens in HDFS zijn gepartitioneerd met tijdssegmentinformatie in de naam van het bestand of de map (bijvoorbeeld /jjjj/mm/dd/file.csv), kan uw pijplijn eenvoudig identificeren welke bestanden en mappen incrementeel moeten worden gekopieerd.
Als uw gegevens in HDFS niet op tijd zijn gepartitioneerd, kan Data Factory nieuwe of gewijzigde bestanden identificeren met behulp van de waarde LastModifiedDate . Data Factory scant alle bestanden uit HDFS en kopieert alleen nieuwe en bijgewerkte bestanden met een laatst gewijzigde tijdstempel die groter is dan een ingestelde waarde.
Als u een groot aantal bestanden in HDFS hebt, kan het scannen van het eerste bestand lang duren, ongeacht het aantal bestanden dat overeenkomt met de filtervoorwaarde. In dit scenario raden we u aan eerst de gegevens te partitioneren met behulp van dezelfde partitie die u hebt gebruikt voor de eerste momentopnamemigratie. Vervolgens kan het scannen van bestanden parallel plaatsvinden.
Prijsraming
Overweeg de volgende pijplijn voor het migreren van gegevens van HDFS naar Azure Blob Storage:
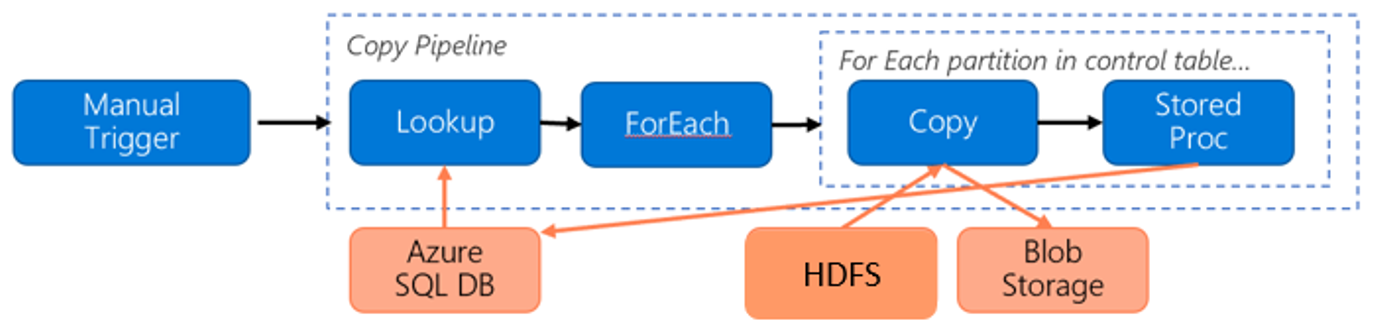
We gaan ervan uit dat de volgende informatie:
- Het totale gegevensvolume is 1 PB.
- U migreert gegevens met behulp van de systeemeigen integratieruntimemodus van Data Factory.
- 1 PB is onderverdeeld in 1000 partities en elke kopie verplaatst één partitie.
- Elke kopieeractiviteit wordt geconfigureerd met één zelf-hostende Integration Runtime die is gekoppeld aan vier computers en die 500 MBps-doorvoer bereikt.
- Gelijktijdigheid van ForEach is ingesteld op 4 en geaggregeerde doorvoer is 2 GBps.
- In totaal duurt het 146 uur om de migratie te voltooien.
Dit is de geschatte prijs op basis van onze veronderstellingen:
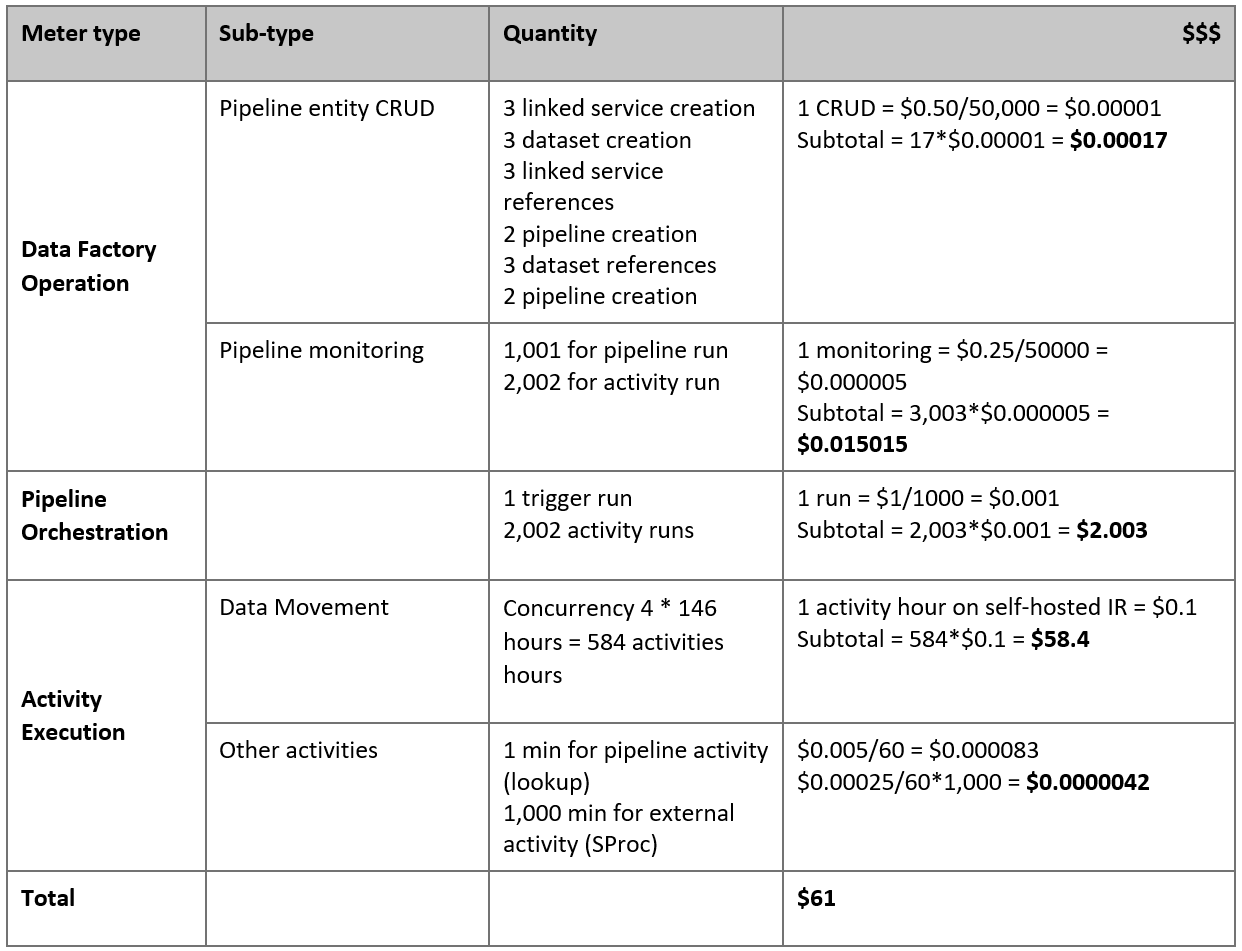
Notitie
Dit is een hypothetisch prijsvoorbeeld. De werkelijke prijzen zijn afhankelijk van de werkelijke doorvoer in uw omgeving. De prijs voor een Azure Windows-VM (waarop zelf-hostende Integration Runtime is geïnstalleerd) is niet inbegrepen.
Aanvullende naslaginformatie
- HDFS-connector
- Azure Blob Storage-connector
- Azure Data Lake Storage Gen2-connector
- handleiding voor het afstemmen van Copy-activiteit prestaties
- Zelf-hostende Integration Runtime maken en configureren
- Zelf-hostende integratie runtime hoge beschikbaarheid en schaalbaarheid
- Beveiligingsoverwegingen voor gegevensverplaatsing
- Referenties opslaan in Azure Key Vault
- Een bestand incrementeel kopiëren op basis van een tijdpartitioneerde bestandsnaam
- Nieuwe en gewijzigde bestanden kopiëren op basis van LastModifiedDate
- Pagina met prijzen voor Data Factory