Copy-activiteit in Azure Data Factory en Azure Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In Azure Data Factory- en Synapse-pijplijnen kunt u de Copy-activiteit gebruiken om gegevens te kopiëren tussen gegevensarchieven die zich on-premises en in de cloud bevinden. Nadat u de gegevens hebt gekopieerd, kunt u andere activiteiten gebruiken om deze verder te transformeren en te analyseren. U kunt ook de Copy-activiteit gebruiken om transformatie- en analyseresultaten te publiceren voor business intelligence (BI) en toepassingsverbruik.
De Copy-activiteit wordt uitgevoerd op een integratieruntime. U kunt verschillende typen integratieruntimes gebruiken voor verschillende scenario's voor het kopiëren van gegevens:
- Wanneer u gegevens kopieert tussen twee gegevensarchieven die openbaar toegankelijk zijn via internet vanaf elk IP-adres, kunt u de Azure Integration Runtime gebruiken voor de kopieeractiviteit. Deze integratieruntime is veilig, betrouwbaar, schaalbaar en wereldwijd beschikbaar.
- Wanneer u gegevens kopieert van en naar gegevensarchieven die zich on-premises of in een netwerk bevinden met toegangsbeheer (bijvoorbeeld een virtueel Azure-netwerk), moet u een zelf-hostende Integration Runtime instellen.
Er moet een integratieruntime worden gekoppeld aan elk bron- en sinkgegevensarchief. Zie Bepalen welke IR moet worden gebruikt voor informatie over hoe de Copy-activiteit bepaalt welke Integration Runtime moet worden gebruikt.
Notitie
U kunt niet meer dan één zelf-hostende Integration Runtime binnen dezelfde Copy-activiteit gebruiken. De bron en sink voor de activiteit moeten zijn verbonden met dezelfde zelf-hostende Integration Runtime.
Als u gegevens van een bron naar een sink wilt kopiëren, voert de service die de Copy-activiteit uitvoert de volgende stappen uit:
- Leest gegevens uit een brongegevensarchief.
- Serialisatie/deserialisatie, compressie/decompressie, kolomtoewijzing, enzovoort. Deze bewerkingen worden uitgevoerd op basis van de configuratie van de invoergegevensset, uitvoergegevensset en Copy-activiteit.
- Hiermee schrijft u gegevens naar het sink-/doelgegevensarchief.

Notitie
Als een zelf-hostende Integration Runtime wordt gebruikt in een bron- of sinkgegevensarchief binnen een Copy-activiteit, moeten zowel de bron als de sink toegankelijk zijn vanaf de server waarop de integratieruntime wordt gehost, zodat de Copy-activiteit succesvol is.
Ondersteunde gegevensarchieven en -indelingen
Notitie
Als een connector is gemarkeerd met preview, kunt u deze proberen en ons feedback geven. Neem contact op met de ondersteuning van Azure als u een afhankelijkheid van preview-connectors wilt opnemen in uw oplossing.
Ondersteunde bestandsindelingen
Azure Data Factory ondersteunt de volgende bestandsindelingen. Raadpleeg elk artikel voor op indeling gebaseerde instellingen.
- Avro-indeling
- Binaire indeling
- Tekstindeling met scheidingstekens
- Excel-indeling
- Iceberg-indeling (alleen voor Azure Data Lake Storage Gen2)
- JSON-indeling
- ORC-indeling
- Parquet-indeling
- XML-indeling
U kunt de Copy-activiteit gebruiken om bestanden als zodanig te kopiëren tussen twee gegevensarchieven op basis van bestanden. In dat geval worden de gegevens efficiënt gekopieerd zonder serialisatie of deserialisatie. Daarnaast kunt u ook bestanden van een bepaalde indeling parseren of genereren, bijvoorbeeld:
- Kopieer gegevens uit een SQL Server-database en schrijf naar Azure Data Lake Storage Gen2 in Parquet-indeling.
- Kopieer bestanden in tekstindeling (CSV) vanuit een on-premises bestandssysteem en schrijf naar Azure Blob Storage in Avro-indeling.
- Kopieer gezipte bestanden van een on-premises bestandssysteem, ontcomprim ze on-the-fly en schrijf geëxtraheerde bestanden naar Azure Data Lake Storage Gen2.
- Kopieer gegevens in de CSV-indeling (compressed-text) van Azure Blob Storage en schrijf deze naar Azure SQL Database.
- Nog veel meer activiteiten waarvoor serialisatie/deserialisatie of compressie/decompressie is vereist.
Ondersteunde regio’s
De service waarmee de Copy-activiteit wereldwijd beschikbaar is in de regio's en geografische gebieden die worden vermeld in Azure Integration Runtime-locaties. De wereldwijd beschikbare topologie zorgt voor een efficiënte gegevensverplaatsing die meestal hops tussen regio's vermijdt. Zie Producten per regio om de beschikbaarheid van Data Factory, Synapse-werkruimten en gegevensverplaatsing in een specifieke regio te controleren.
Configuratie
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Het hulpprogramma voor het kopiëren van gegevens
- Azure Portal
- De .NET-SDK
- De Python-SDK
- Azure PowerShell
- De REST API
- Een Azure Resource Manager-sjabloon
Over het algemeen moet u het volgende doen om de Copy-activiteit te gebruiken in Azure Data Factory- of Synapse-pijplijnen:
- Maak gekoppelde services voor het brongegevensarchief en het sinkgegevensarchief. U vindt de lijst met ondersteunde connectors in de sectie Ondersteunde gegevensarchieven en indelingen van dit artikel. Raadpleeg de sectie 'Eigenschappen van gekoppelde service' van het connectorartikel voor configuratie-informatie en ondersteunde eigenschappen.
- Maak gegevenssets voor de bron en sink. Raadpleeg de secties Gegevensseteigenschappen van de artikelen over de bron- en sinkconnector voor configuratie-informatie en ondersteunde eigenschappen.
- Maak een pijplijn met de Copy-activiteit. De volgende sectie bevat een voorbeeld.
Syntaxis
De volgende sjabloon van een Copy-activiteit bevat een volledige lijst met ondersteunde eigenschappen. Geef de waarden op die passen bij uw scenario.
"activities":[
{
"name": "CopyActivityTemplate",
"type": "Copy",
"inputs": [
{
"referenceName": "<source dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<sink dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>",
<properties>
},
"sink": {
"type": "<sink type>"
<properties>
},
"translator":
{
"type": "TabularTranslator",
"columnMappings": "<column mapping>"
},
"dataIntegrationUnits": <number>,
"parallelCopies": <number>,
"enableStaging": true/false,
"stagingSettings": {
<properties>
},
"enableSkipIncompatibleRow": true/false,
"redirectIncompatibleRowSettings": {
<properties>
}
}
}
]
Syntaxisdetails
| Eigenschappen | Beschrijving | Vereist? |
|---|---|---|
| type | Voor een Copy-activiteit ingesteld opCopy |
Ja |
| Ingangen | Geef de gegevensset op die u hebt gemaakt die verwijst naar de brongegevens. De Copy-activiteit ondersteunt slechts één invoer. | Ja |
| uitvoer | Geef de gegevensset op die u hebt gemaakt die verwijst naar de sinkgegevens. De Copy-activiteit ondersteunt slechts één uitvoer. | Ja |
| typeProperties | Geef eigenschappen op om de Copy-activiteit te configureren. | Ja |
| source | Geef het type kopieerbron en de bijbehorende eigenschappen op voor het ophalen van gegevens. Zie de sectie 'Copy-activiteit eigenschappen' in het connectorartikel in ondersteunde gegevensarchieven en -indelingen voor meer informatie. |
Ja |
| zinken | Geef het type kopieersink en de bijbehorende eigenschappen op voor het schrijven van gegevens. Zie de sectie 'Copy-activiteit eigenschappen' in het connectorartikel in ondersteunde gegevensarchieven en -indelingen voor meer informatie. |
Ja |
| Translator | Geef expliciete kolomtoewijzingen op van bron naar sink. Deze eigenschap is van toepassing wanneer het standaard kopieergedrag niet aan uw behoeften voldoet. Zie Schematoewijzing in kopieeractiviteit voor meer informatie. |
Nee |
| dataIntegrationUnits | Geef een meting op die de hoeveelheid energie aangeeft die de Azure Integration Runtime gebruikt voor het kopiëren van gegevens. Deze eenheden werden voorheen DMU (Cloud Data Movement Units) genoemd. Zie Data-Integratie Eenheden voor meer informatie. |
Nee |
| parallelcopies | Geef de parallelle uitvoering op die de Copy-activiteit moet gebruiken bij het lezen van gegevens uit de bron en het schrijven van gegevens naar de sink. Zie Parallel kopiëren voor meer informatie. |
Nee |
| bewaren | Geef op of metagegevens/ACL's moeten worden bewaard tijdens het kopiëren van gegevens. Zie Metagegevens behouden voor meer informatie. |
Nee |
| enableStaging stagingSettings |
Geef op of de tussentijdse gegevens in Blob-opslag moeten worden gefaseerde in plaats van gegevens rechtstreeks van de bron naar de sink te kopiëren. Zie Gefaseerde kopie voor meer informatie over nuttige scenario's en configuratiedetails. |
Nee |
| enableSkipIncompatibleRow redirectIncompatibleRowSettings |
Kies hoe u incompatibele rijen kunt verwerken wanneer u gegevens kopieert van de bron naar de sink. Zie Fouttolerantie voor meer informatie. |
Nee |
Controleren
U kunt de Copy-activiteit uitvoeren in de Azure Data Factory- en Synapse-pijplijnen zowel visueel als programmatisch bewaken. Zie Kopieeractiviteit bewaken voor meer informatie.
Incrementele kopie
Met Data Factory- en Synapse-pijplijnen kunt u incrementeel deltagegevens uit een brongegevensarchief kopiëren naar een sinkgegevensarchief. Zie Zelfstudie: Incrementeel gegevens kopiëren voor meer informatie.
Prestaties en afstemmen
In de bewakingservaring voor kopieeractiviteiten ziet u de statistieken van de kopieerprestaties voor elke uitvoering van uw activiteit. In de handleiding Copy-activiteit prestaties en schaalbaarheid worden belangrijke factoren beschreven die van invloed zijn op de prestaties van gegevensverplaatsing via de Copy-activiteit. Ook worden de prestatiewaarden vermeld die tijdens het testen zijn waargenomen en wordt besproken hoe u de prestaties van de Copy-activiteit optimaliseert.
Hervatten vanaf laatste mislukte uitvoering
Copy-activiteit ondersteunt het hervatten van de laatste mislukte uitvoering wanneer u grote grootte van bestanden als zodanig kopieert met binaire indeling tussen op bestanden gebaseerde archieven en ervoor kiest om de map-/bestandshiërarchie van bron naar sink te behouden, bijvoorbeeld om gegevens van Amazon S3 naar Azure Data Lake Storage Gen2 te migreren. Dit is van toepassing op de volgende bestandsconnectors: Amazon S3, Amazon S3 Compatible Storage Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, Oracle Cloud Storage en SFTP.
U kunt het hervatten van de kopieeractiviteit op de volgende twee manieren gebruiken:
Opnieuw proberen op activiteitsniveau: u kunt het aantal nieuwe pogingen instellen op kopieeractiviteit. Als de uitvoering van deze kopieeractiviteit mislukt tijdens de uitvoering van de pijplijn, wordt de volgende automatische poging gestart vanaf het foutpunt van de laatste proefversie.
Opnieuw uitvoeren vanaf mislukte activiteit: nadat de uitvoering van de pijplijn is voltooid, kunt u ook een nieuwe uitvoering activeren vanuit de mislukte activiteit in de bewakingsweergave van de ADF-gebruikersinterface of programmatisch. Als de mislukte activiteit een kopieeractiviteit is, wordt de pijplijn niet alleen opnieuw uitgevoerd vanuit deze activiteit, maar wordt ook hervat vanaf het foutpunt van de vorige uitvoering.
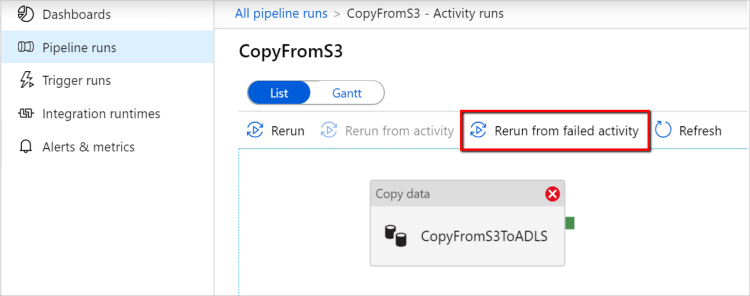
Enkele punten om te noteren:
- Hervatten vindt plaats op bestandsniveau. Als de kopieeractiviteit mislukt bij het kopiëren van een bestand, wordt dit specifieke bestand in de volgende uitvoering opnieuw gekopieerd.
- Wijzig de instellingen voor de kopieeractiviteit tussen de nieuwe uitvoeringen niet om het werk goed te laten werken.
- Wanneer u gegevens kopieert uit Amazon S3, Azure Blob, Azure Data Lake Storage Gen2 en Google Cloud Storage, kan de kopieeractiviteit worden hervat vanuit een willekeurig aantal gekopieerde bestanden. Hoewel voor de rest van op bestanden gebaseerde connectors als bron, momenteel kopieeractiviteit cv ondersteunt van een beperkt aantal bestanden, meestal in het bereik van tienduizenden en varieert afhankelijk van de lengte van de bestandspaden; bestanden buiten dit nummer worden opnieuw gekopieerd tijdens opnieuw uitvoeren.
Voor andere scenario's dan het kopiëren van binaire bestanden begint het opnieuw uitvoeren van de kopieeractiviteit vanaf het begin.
Notitie
Hervatten van laatste mislukte uitvoering via zelf-hostende Integration Runtime wordt nu alleen ondersteund in de zelf-hostende Integration Runtime versie 5.43.8935.2 of hoger.
Metagegevens samen met gegevens behouden
Tijdens het kopiëren van gegevens van bron naar sink, kunt u in scenario's zoals data lake-migratie ook ervoor kiezen om de metagegevens en ACL's samen met gegevens te behouden met behulp van kopieeractiviteit. Zie Metagegevens behouden voor meer informatie.
Metagegevenstags toevoegen aan een op bestanden gebaseerde sink
Wanneer de sink is gebaseerd op Azure Storage (Azure Data Lake Storage of Azure Blob Storage), kunnen we ervoor kiezen om enkele metagegevens aan de bestanden toe te voegen. Deze metagegevens worden weergegeven als onderdeel van de bestandseigenschappen als sleutel-waardeparen. Voor alle typen sinks op basis van bestanden kunt u metagegevens met dynamische inhoud toevoegen met behulp van de pijplijnparameters, systeemvariabelen, functies en variabelen. Daarnaast kunt u voor een binaire sink op basis van bestanden datum/tijd (van het bronbestand) toevoegen met behulp van het trefwoord $$LASTMODIFIED, evenals aangepaste waarden als metagegevens aan het sinkbestand.
Toewijzing van schema- en gegevenstypen
Zie Schema- en gegevenstypetoewijzing voor informatie over hoe de Copy-activiteit uw brongegevens toe te voegen aan uw sink.
Extra kolommen toevoegen tijdens het kopiëren
Naast het kopiëren van gegevens uit het brongegevensarchief naar sink, kunt u ook configureren dat u extra gegevenskolommen toevoegt om naar sink te kopiëren. Voorbeeld:
- Wanneer u kopieert van een bron op basis van een bestand, slaat u het relatieve bestandspad op als een extra kolom om te traceren van welk bestand de gegevens afkomstig zijn.
- Dupliceer de opgegeven bronkolom als een andere kolom.
- Voeg een kolom met ADF-expressie toe om ADF-systeemvariabelen, zoals pijplijnnaam/pijplijn-id, te koppelen of andere dynamische waarde op te slaan uit de uitvoer van de upstream-activiteit.
- Voeg een kolom met statische waarde toe om te voldoen aan uw downstreamverbruiksbehoefte.
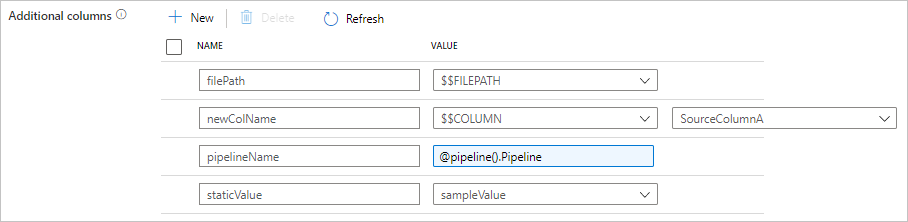
U vindt de volgende configuratie op het tabblad Bron van kopieeractiviteit. U kunt deze extra kolommen ook toewijzen in de toewijzing van het kopieeractiviteitsschema zoals gebruikelijk met behulp van de gedefinieerde kolomnamen.
Tip
Deze functie werkt met het nieuwste gegevenssetmodel. Als u deze optie niet ziet in de gebruikersinterface, probeert u een nieuwe gegevensset te maken.
Als u deze programmatisch wilt configureren, voegt u de eigenschap toe aan de bron van de additionalColumns kopieeractiviteit:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| additionalColumns | Voeg extra gegevenskolommen toe om naar sink te kopiëren. Elk object onder de additionalColumns matrix vertegenwoordigt een extra kolom. De name kolomnaam wordt gedefinieerd en de value gegevenswaarde van die kolom wordt aangegeven.Toegestane gegevenswaarden zijn: - $$FILEPATH - Een gereserveerde variabele geeft aan dat het relatieve pad van de bronbestanden moet worden opgeslagen naar het mappad dat is opgegeven in de gegevensset. Toepassen op bron op basis van bestanden.- $$COLUMN:<source_column_name> - Een gereserveerd variabelepatroon geeft aan dat de opgegeven bronkolom moet worden gedupliceerd als een andere kolom- Expression - Statische waarde |
Nee |
Voorbeeld:
"activities":[
{
"name": "CopyWithAdditionalColumns",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "<source type>",
"additionalColumns": [
{
"name": "filePath",
"value": "$$FILEPATH"
},
{
"name": "newColName",
"value": "$$COLUMN:SourceColumnA"
},
{
"name": "pipelineName",
"value": {
"value": "@pipeline().Pipeline",
"type": "Expression"
}
},
{
"name": "staticValue",
"value": "sampleValue"
}
],
...
},
"sink": {
"type": "<sink type>"
}
}
}
]
Tip
Nadat u extra kolommen hebt geconfigureerd, moet u deze toewijzen aan uw doelsink, op het tabblad Toewijzing.
Automatisch sinktabellen maken
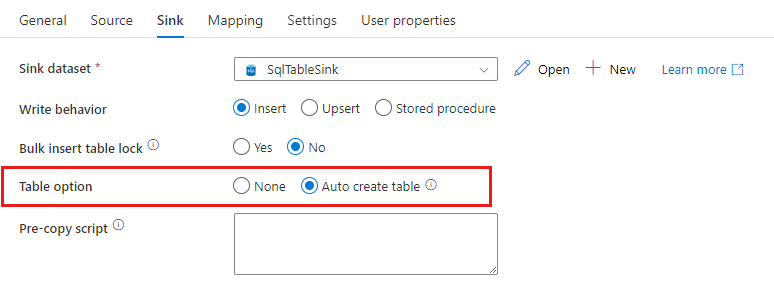
Wanneer u gegevens kopieert naar SQL Database/Azure Synapse Analytics, als de doeltabel niet bestaat, ondersteunt kopieeractiviteit het automatisch maken ervan op basis van de brongegevens. Het is bedoeld om snel aan de slag te gaan met het laden van de gegevens en het evalueren van SQL-database/Azure Synapse Analytics. Na de gegevensopname kunt u het sinktabelschema controleren en aanpassen aan uw behoeften.
Deze functie wordt ondersteund bij het kopiëren van gegevens uit een bron naar de volgende sinkgegevensarchieven. U vindt de optie in de gebruikersinterface van ADF-creatie ->Copy-activiteit sink ->Table-optie ->Automatisch tabel maken of via tableOption de eigenschap in de nettolading van de kopieeractiviteitssink.
Fouttolerantie
De Copy-activiteit stopt standaard met het kopiëren van gegevens en retourneert een fout wanneer brongegevensrijen niet compatibel zijn met sinkgegevensrijen. Als u het kopiëren wilt voltooien, kunt u de Copy-activiteit configureren om de niet-compatibele rijen over te slaan en te registreren en alleen de compatibele gegevens te kopiëren. Zie Copy-activiteit fouttolerantie voor meer informatie.
Verificatie van gegevensconsistentie
Wanneer u gegevens verplaatst van bron naar doelarchief, biedt kopieeractiviteit een optie om aanvullende verificatie van gegevensconsistentie uit te voeren om ervoor te zorgen dat de gegevens niet alleen van bron naar doelarchief zijn gekopieerd, maar ook gecontroleerd of ze consistent zijn tussen bron- en doelopslag. Zodra inconsistente bestanden zijn gevonden tijdens de gegevensverplaatsing, kunt u de kopieeractiviteit afbreken of doorgaan met het kopiëren van de rest door de instelling voor fouttolerantie in te schakelen om inconsistente bestanden over te slaan. U kunt de overgeslagen bestandsnamen ophalen door de instelling voor sessielogboeken in te schakelen in de kopieeractiviteit. Zie Verificatie van gegevensconsistentie in kopieeractiviteit voor meer informatie.
Sessielogboek
U kunt de gekopieerde bestandsnamen vastleggen, zodat u er zeker van kunt zijn dat de gegevens niet alleen zijn gekopieerd van de bron naar het doelarchief, maar ook consistent zijn tussen de bron- en doelopslag door de logboeken van de kopieeractiviteitssessie te bekijken. Zie Activiteit voor het kopiëren van sessies voor meer informatie.
Gerelateerde inhoud
Zie de volgende quickstarts, zelfstudies en voorbeelden: