Bulksgewijs kopiëren van een database naar Azure Data Explorer met behulp van de sjabloon Azure Data Factory
Azure Data Explorer is een snelle, volledig beheerde gegevensanalyseservice. Het biedt realtime-analyse van grote hoeveelheden gegevens die vanuit veel bronnen worden gestreamd, zoals toepassingen, websites en IoT-apparaten.
Als u gegevens uit een database in Oracle Server, Netezza, Teradata of SQL Server naar Azure Data Explorer wilt kopiëren, moet u grote hoeveelheden gegevens uit meerdere tabellen laden. Normaal gesproken moeten de gegevens in elke tabel worden gepartitioneerd, zodat u rijen met meerdere threads parallel vanuit één tabel kunt laden. In dit artikel wordt een sjabloon beschreven die in deze scenario's moet worden gebruikt.
Azure Data Factory sjablonen zijn vooraf gedefinieerde Data Factory-pijplijnen. Met deze sjablonen kunt u snel aan de slag met Data Factory en de ontwikkelingstijd voor gegevensintegratieprojecten verkorten.
U maakt de sjabloon Bulksgewijs kopiëren van database naar Azure Data Explorer met behulp van de activiteiten Lookup en ForEach. Voor het sneller kopiëren van gegevens kunt u de sjabloon gebruiken om veel pijplijnen per database of per tabel te maken.
Belangrijk
Zorg ervoor dat u het hulpprogramma gebruikt dat geschikt is voor de hoeveelheid gegevens die u wilt kopiëren.
- Gebruik de sjabloon Bulksgewijs kopiëren van database naar Azure Data Explorer om grote hoeveelheden gegevens te kopiëren uit databases zoals SQL Server en Google BigQuery naar Azure Data Explorer.
- Gebruik het data factory-hulpprogramma Voor het kopiëren van gegevens om enkele tabellen met kleine of gemiddelde hoeveelheden gegevens naar Azure Data Explorer te kopiëren.
Vereisten
- Een Azure-abonnement. Maak een gratis Azure-account.
- Een Azure Data Explorer-cluster en -database. Maak een cluster en database.
- Een data factory. Een data factory maken.
- Een gegevensbron.
ControlTableDataset maken
ControlTableDataset geeft aan welke gegevens worden gekopieerd van de bron naar de bestemming in de pijplijn. Het aantal rijen geeft het totale aantal pijplijnen aan dat nodig is om de gegevens te kopiëren. Definieer ControlTableDataset als onderdeel van de brondatabase.
Een voorbeeld van de indeling van de SQL Server brontabel wordt weergegeven in de volgende code:
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
De code-elementen worden beschreven in de volgende tabel:
| Eigenschap | Beschrijving | Voorbeeld |
|---|---|---|
| PartitionId | De kopieervolgorde | 1 |
| SourceQuery | De query die aangeeft welke gegevens worden gekopieerd tijdens de pijplijnruntime | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''> |
| ADXTableName | De naam van de doeltabel | MyAdxTable |
Als uw ControlTableDataset een andere indeling heeft, maakt u een vergelijkbare ControlTableDataset voor uw indeling.
De sjabloon Bulksgewijs kopiëren van database naar Azure Data Explorer gebruiken
Selecteer in het deelvenster Aan de slagde optie Pijplijn maken op basis van sjabloon om het deelvenster Sjabloongalerie te openen.
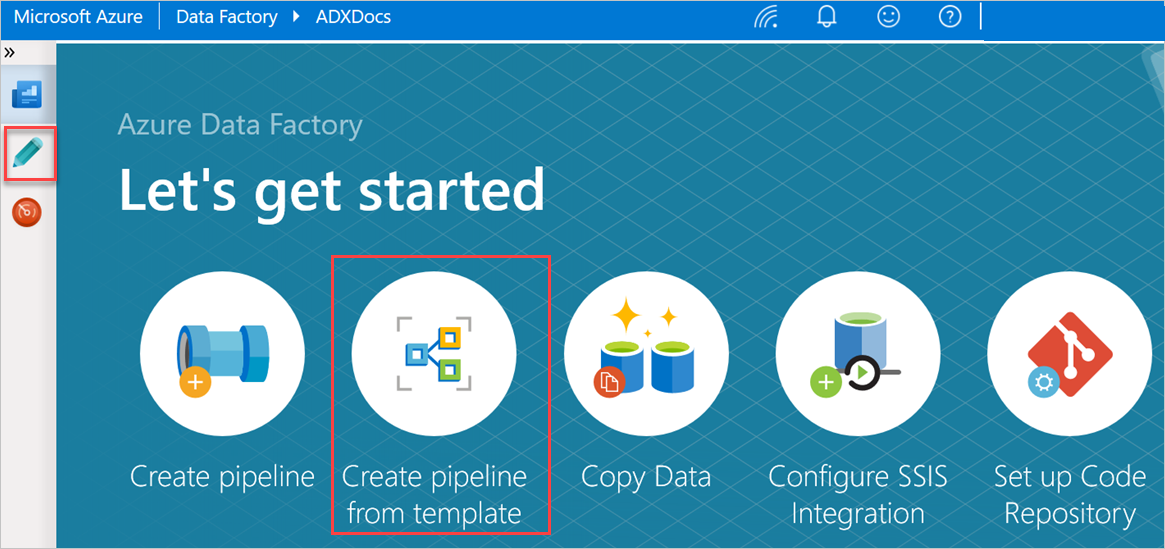
Selecteer de sjabloon Bulksgewijs kopiëren van database naar Azure Data Explorer.
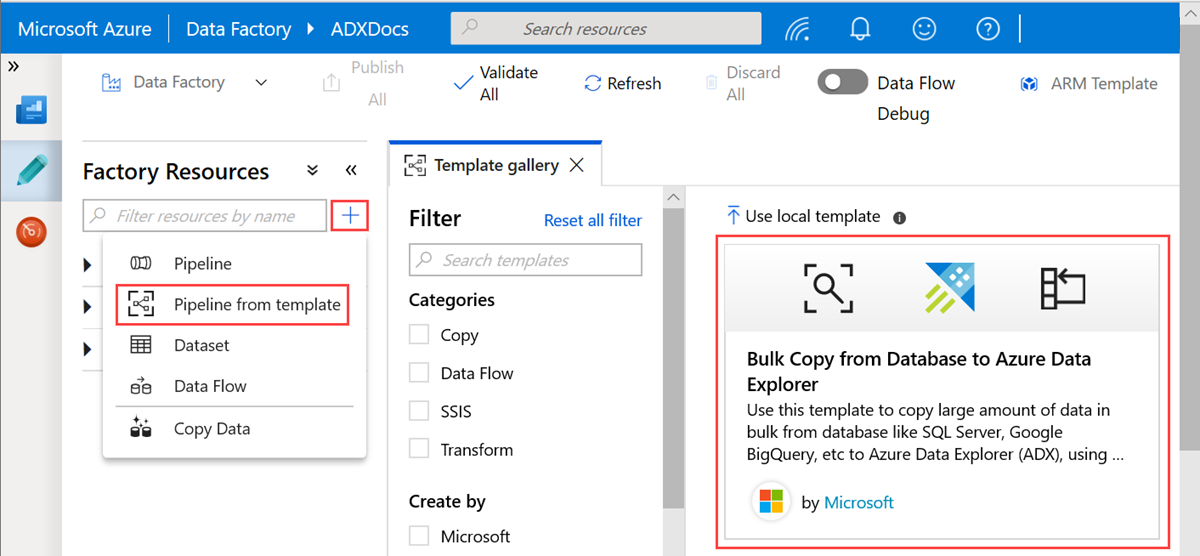
Geef in het deelvenster Bulksgewijs kopiëren van database naar Azure Data Explorer onder Gebruikersinvoer uw gegevenssets op door het volgende te doen:
a. Selecteer in de vervolgkeuzelijst ControlTableDataset de gekoppelde service aan de besturingstabel die aangeeft welke gegevens van de bron naar de bestemming worden gekopieerd en waar deze in de bestemming worden geplaatst.
b. Selecteer in de vervolgkeuzelijst SourceDataset de gekoppelde service voor de brondatabase.
c. Selecteer in de vervolgkeuzelijst AzureDataExplorerTable de tabel Azure Data Explorer. Als de gegevensset niet bestaat, maakt u de gekoppelde Azure Data Explorer-service om de gegevensset toe te voegen.
d. Selecteer Deze sjabloon gebruiken.
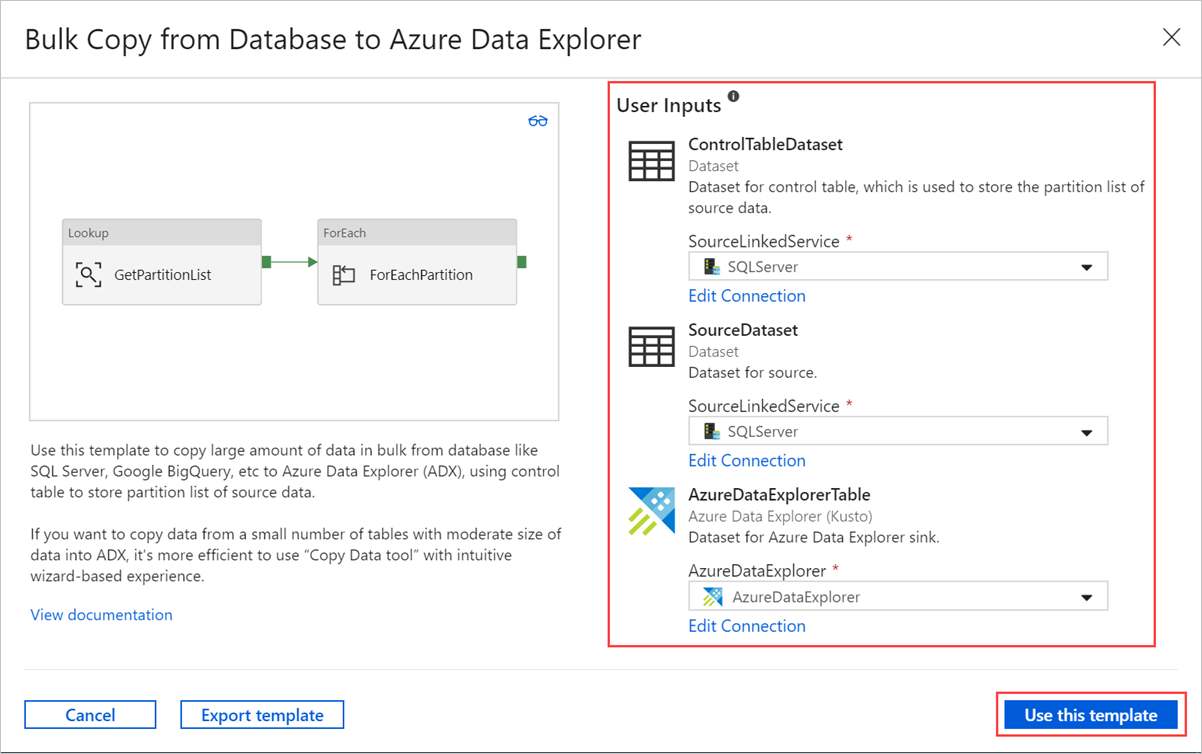
Selecteer een gebied op het canvas, buiten de activiteiten, om toegang te krijgen tot de sjabloonpijplijn. Selecteer het tabblad Parameters om de parameters voor de tabel in te voeren, waaronder Naam (naam van besturingselementtabel) en Standaardwaarde (kolomnamen).
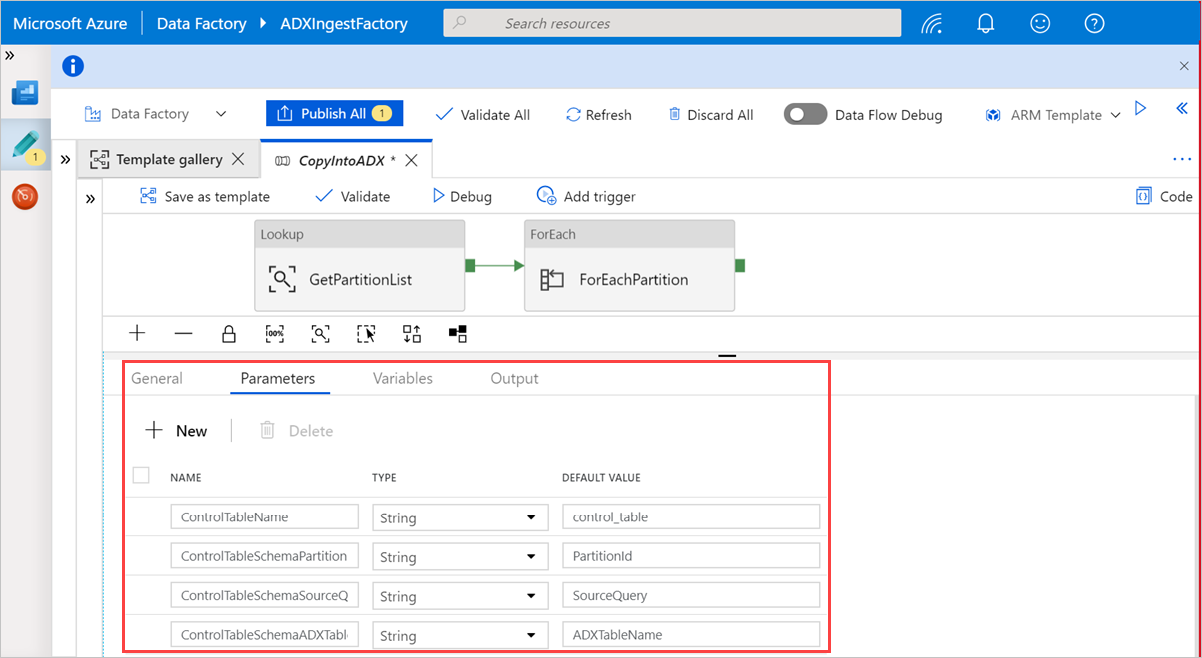
Selecteer onder Opzoeken de optie GetPartitionList om de standaardinstellingen weer te geven. De query wordt automatisch gemaakt.
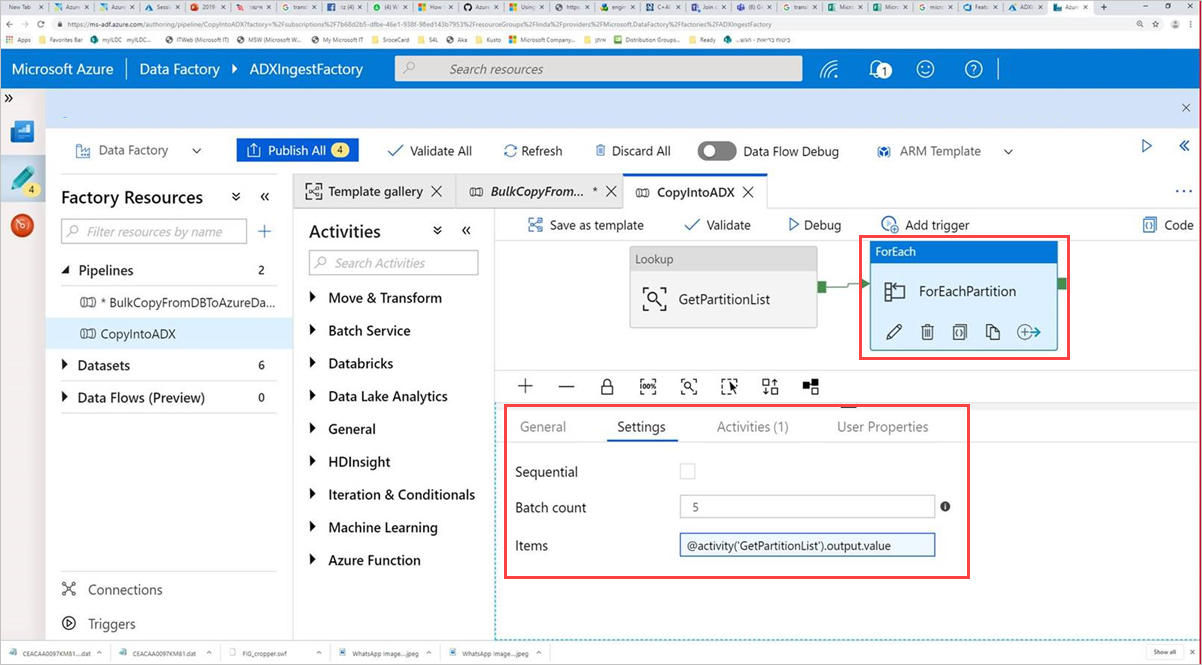
Selecteer de opdrachtactiviteit ForEachPartition, selecteer het tabblad Instellingen en ga als volgt te werk:
a. Voer in het vak Batchaantal een getal in tussen 1 en 50. Deze selectie bepaalt het aantal pijplijnen dat parallel wordt uitgevoerd totdat het aantal ControlTableDataset-rijen is bereikt.
b. Schakel het selectievakje Sequentiële niet in om ervoor te zorgen dat de pijplijnbatches parallel worden uitgevoerd.
Tip
De best practice is om veel pijplijnen parallel uit te voeren, zodat uw gegevens sneller kunnen worden gekopieerd. Als u de efficiëntie wilt verhogen, partitioneert u de gegevens in de brontabel en wijst u één partitie per pijplijn toe op basis van datum en tabel.
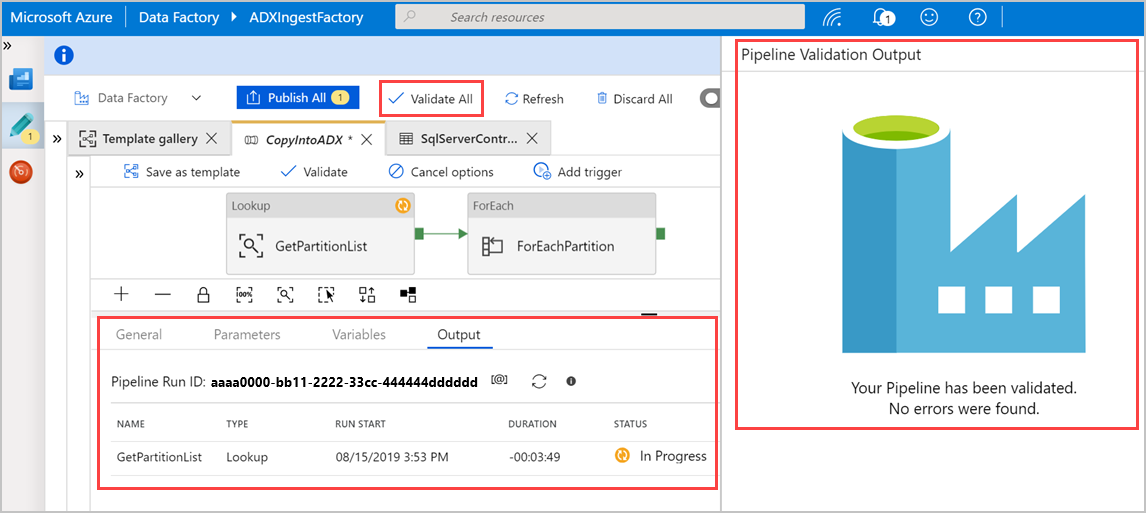
Selecteer Alles valideren om de Azure Data Factory pijplijn te valideren en bekijk vervolgens het resultaat in het deelvenster Uitvoer van pijplijnvalidatie.
Selecteer indien nodig Fouten opsporen en selecteer vervolgens Trigger toevoegen om de pijplijn uit te voeren.
U kunt de sjabloon nu gebruiken om efficiënt grote hoeveelheden gegevens uit uw databases en tabellen te kopiëren.
Gerelateerde inhoud
- Meer informatie over de Azure Data Explorer-connector voor Azure Data Factory.
- Bewerk gekoppelde services, gegevenssets en pijplijnen in de Data Factory-gebruikersinterface.
- Query's uitvoeren op gegevens in de webinterface van Azure Data Explorer.