Intelligente toepassingen
van toepassing op:![]() Azure SQL Database
Azure SQL Database![]() SQL-database in Fabric
SQL-database in Fabric
Dit artikel bevat een overzicht van het gebruik van ai-opties (kunstmatige intelligentie), zoals OpenAI en vectoren, voor het bouwen van intelligente toepassingen met Azure SQL Database en Fabric SQL Database, die veel van deze functies van Azure SQL Database deelt.
Bezoek voor monsters en voorbeelden de opslagplaats SQL AI Samples.
Bekijk deze video in de Azure SQL Database Essentials-serie voor een kort overzicht van het bouwen van een ai-toepassing die gereed is voor AI:
Overzicht
Met grote taalmodellen (LLM's) kunnen ontwikkelaars AI-toepassingen maken met een vertrouwde gebruikerservaring.
Het gebruik van LLM's in toepassingen biedt meer waarde en een verbeterde gebruikerservaring wanneer de modellen op het juiste moment toegang hebben tot de juiste gegevens vanuit de database van uw toepassing. Dit proces staat bekend als Rag (Retrieval Augmented Generation) en Azure SQL Database en Fabric SQL database hebben veel functies die ondersteuning bieden voor dit nieuwe patroon, waardoor het een geweldige database is om intelligente toepassingen te bouwen.
De volgende koppelingen bevatten voorbeeldcode van verschillende opties voor het bouwen van intelligente toepassingen:
| AI-optie | Beschrijving |
|---|---|
| Azure OpenAI | Genereer insluitingen voor RAG en integreer met elk model dat wordt ondersteund door Azure OpenAI. |
| vectoren | Meer informatie over het opslaan en opvragen van vectoren in de database. |
| Azure AI Search | Gebruik uw database samen met Azure AI Search om LLM op uw gegevens te trainen. |
| Intelligent-toepassingen | Leer hoe u een end-to-end-oplossing maakt met behulp van een gemeenschappelijk patroon dat in elk scenario kan worden gerepliceerd. |
| Copilot-vaardigheden in Azure SQL Database | Meer informatie over de set AI-ondersteunde functies die zijn ontworpen voor het stroomlijnen van het ontwerp, het beheer, de optimalisatie en de status van Azure SQL Database-gestuurde toepassingen. |
| Copilot-vaardigheden in Fabric SQL Database | Meer informatie over de reeks AI-ondersteunde ervaringen die zijn ontworpen om het ontwerp, de werking, de optimalisatie en de gezondheid van SQL-database-gestuurde Fabric-toepassingen te stroomlijnen. |
Belangrijkste concepten voor het implementeren van RAG met Azure OpenAI
Deze sectie bevat belangrijke concepten die essentieel zijn voor het implementeren van RAG met Azure OpenAI in Azure SQL Database of Fabric SQL Database.
Ophaal-Versterkte Generatie (RAG)
RAG is een techniek die het vermogen van de LLM verbetert om relevante en informatieve antwoorden te produceren door extra gegevens uit externe bronnen op te halen. Rag kan bijvoorbeeld query's uitvoeren op artikelen of documenten die domeinspecifieke kennis bevatten met betrekking tot de vraag of prompt van de gebruiker. De LLM kan deze opgehaalde gegevens vervolgens gebruiken als verwijzing bij het genereren van het antwoord. Een eenvoudig RAG-patroon met behulp van Azure SQL Database kan bijvoorbeeld zijn:
- Gegevens invoegen in een tabel.
- Koppel Azure SQL Database aan Azure AI Search.
- Maak een Azure OpenAI GPT4-model en verbind het met Azure AI Search.
- Chat en stel vragen over uw gegevens met behulp van het getrainde Azure OpenAI-model vanuit uw toepassing en vanuit Azure SQL Database.
Het RAG-patroon, met prompt engineering, is bedoeld om de responskwaliteit te verbeteren door meer contextuele informatie aan het model te bieden. RAG maakt het mogelijk om een bredere knowledgebase toe te passen door relevante externe bronnen in het generatieproces op te nemen, wat resulteert in uitgebreidere en geïnformeerde antwoorden. Voor meer informatie over grounding LLMs, zie Grounding LLMs - Microsoft Community Hub.
Prompten en prompt-ontwikkeling
Een prompt verwijst naar specifieke tekst of informatie die dient als instructie voor een LLM of als contextuele gegevens waarop de LLM kan bouwen. Een prompt kan verschillende vormen aannemen, zoals een vraag, een instructie of zelfs een codefragment.
Voorbeeldprompts die kunnen worden gebruikt om een antwoord van een LLM te genereren:
- instructies: geef richtlijnen aan de LLM
- primaire inhoud: geeft informatie aan de LLM voor verwerking
- Voorbeelden: help het model aan een bepaalde taak of een bepaald proces te koppelen
- Cues: de uitvoer van de LLM in de juiste richting sturen
- Ondersteunende inhoud: vertegenwoordigt aanvullende informatie die de LLM kan gebruiken om uitvoer te genereren
Het proces voor het maken van goede prompts voor een scenario wordt prompt engineeringgenoemd. Zie Azure OpenAI Servicevoor meer informatie over prompts en best practices voor prompt-engineering.
Tokens
Tokens zijn kleine stukken tekst die worden gegenereerd door de invoertekst op te splitsen in kleinere segmenten. Deze segmenten kunnen woorden of groepen tekens zijn, variërend van één teken tot een heel woord. Het woord hamburger wordt bijvoorbeeld onderverdeeld in tokens zoals ham, buren ger terwijl een kort en gemeenschappelijk woord zoals pear als één token wordt beschouwd.
In Azure OpenAI wordt invoertekst die aan de API wordt verstrekt, omgezet in tokens (tokenized). Het aantal tokens dat in elke API-aanvraag wordt verwerkt, is afhankelijk van factoren zoals de lengte van de invoer-, uitvoer- en aanvraagparameters. Het aantal tokens dat wordt verwerkt, heeft ook invloed op de reactietijd en doorvoer van de modellen. Er zijn limieten voor het aantal tokens dat elk model kan aannemen in één aanvraag/reactie van Azure OpenAI. Zie quota en limieten van de Azure OpenAI-servicevoor meer informatie.
Vectoren
Vectoren zijn geordende matrices van getallen (meestal floats) die informatie over sommige gegevens kunnen vertegenwoordigen. Een afbeelding kan bijvoorbeeld worden weergegeven als een vector van pixelwaarden, of een tekenreeks met tekst kan worden weergegeven als een vector- of ASCII-waarden. Het proces voor het omzetten van gegevens in een vector wordt vectorisatiegenoemd. Zie Vectorsvoor meer informatie.
Inbeddingen
Insluitingen zijn vectoren die belangrijke functies van gegevens vertegenwoordigen. Insluitingen worden vaak geleerd met behulp van een Deep Learning-model en machine learning- en AI-modellen gebruiken ze als functies. Insluitingen kunnen ook semantische overeenkomsten tussen vergelijkbare concepten vastleggen. Bij het genereren van een insluiting voor de woorden person en human, verwachten we bijvoorbeeld dat hun insluitingen (vectorweergave) vergelijkbaar zijn in waarde, omdat de woorden ook semantisch vergelijkbaar zijn.
Azure OpenAI bevat modellen voor het maken van insluitingen op basis van tekstgegevens. De service breekt tekst op in tokens en genereert insluitingen met behulp van modellen die vooraf zijn getraind door OpenAI. Zie Insluitingen maken met Azure OpenAIvoor meer informatie.
Vector zoeken
Vectorzoekopdrachten verwijzen naar het proces van het vinden van alle vectoren in een gegevensset die semantisch vergelijkbaar zijn met een specifieke queryvector. Daarom zoekt een queryvector voor het woord human de gehele woordenlijst door op semantisch vergelijkbare woorden, en moet het woord person als een dichte overeenkomst vinden. Deze nabijheid, of afstand, wordt gemeten met behulp van een metrische overeenkomst, zoals cosinus-gelijkenis. De dichtere vectoren zijn vergelijkbaar, hoe kleiner is de afstand tussen deze vectoren.
Overweeg een scenario waarin u een query uitvoert op miljoenen documenten om de meest vergelijkbare documenten in uw gegevens te vinden. U kunt insluitingen maken voor uw gegevens en documenten opvragen met behulp van Azure OpenAI. Vervolgens kunt u een vectorzoekopdracht uitvoeren om de meest vergelijkbare documenten uit uw gegevensset te vinden. Het uitvoeren van een vectorzoekopdracht in een paar voorbeelden is echter triviaal. Het uitvoeren van dezelfde zoekopdracht op duizenden of miljoenen gegevenspunten wordt lastig. Er zijn ook compromissen tussen uitgebreide zoek- en dichtstbijzijnde buren (ANN) zoekmethoden, waaronder latentie, doorvoer, nauwkeurigheid en kosten, die allemaal afhankelijk zijn van de vereisten van uw toepassing.
Vectoren in Azure SQL Database kunnen efficiënt worden opgeslagen en opgevraagd, zoals beschreven in de volgende secties, waardoor exact dichtstbijzijnde buren zoeken met geweldige prestaties mogelijk is. U hoeft niet te beslissen tussen nauwkeurigheid en snelheid: u kunt beide hebben. Het opslaan van vector-insluitingen naast de gegevens in een geïntegreerde oplossing minimaliseert de noodzaak om gegevenssynchronisatie te beheren en versnelt uw time-to-market voor de ontwikkeling van AI-toepassingen.
Azure OpenAI
Insluiten is het proces van het weergeven van de echte wereld als gegevens. Tekst, afbeeldingen of geluiden kunnen worden geconverteerd naar insluitingen. Azure OpenAI-modellen kunnen echte informatie transformeren in insluitingen. De modellen zijn beschikbaar als REST-eindpunten en kunnen dus eenvoudig worden gebruikt vanuit Azure SQL Database met behulp van de sp_invoke_external_rest_endpoint systeem opgeslagen procedure:
DECLARE @retval INT, @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX);
SET @payload = JSON_OBJECT('input': @text);
EXEC @retval = sp_invoke_external_rest_endpoint @url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
SELECT CAST([key] AS INT) AS [vector_value_id],
CAST([value] AS FLOAT) AS [vector_value]
FROM OPENJSON(JSON_QUERY(@response, '$.result.data[0].embedding'));
Het gebruik van een aanroep naar een REST-service om insluitingen te krijgen, is slechts een van de integratieopties die u hebt bij het werken met SQL Database en OpenAI. U kunt een van de beschikbare modellen toegang krijgen tot gegevens die zijn opgeslagen in Azure SQL Database om oplossingen te maken waar uw gebruikers met de gegevens kunnen werken, zoals in het volgende voorbeeld.
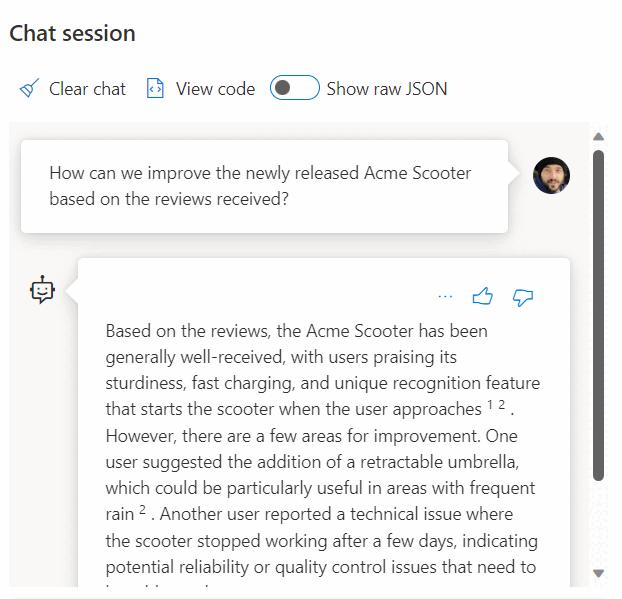
Zie de volgende artikelen voor meer voorbeelden over het gebruik van SQL Database en OpenAI:
- Afbeeldingen genereren met Azure OpenAI Service (DALL-E) en Azure SQL Database
- OpenAI REST-eindpunten gebruiken met Azure SQL Database
Vectoren
Vectorgegevenstype
In november 2024 is de nieuwe vector gegevenstype geïntroduceerd in Azure SQL Database.
Het toegewezen vector type maakt efficiënte en geoptimaliseerde opslag van vectorgegevens mogelijk en wordt geleverd met een set functies om ontwikkelaars te helpen vector- en gelijkeniszoekopdrachten te stroomlijnen. Het berekenen van de afstand tussen twee vectoren kan worden uitgevoerd in één regel code met behulp van de nieuwe VECTOR_DISTANCE functie. Zie Overzicht van vectoren in de SQL Database Enginevoor meer informatie over de vector gegevenstype en gerelateerde functies.
Bijvoorbeeld:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[embedding] [vector](1536) NOT NULL,
)
GO
SELECT TOP(10)
*
FROM
[dbo].[wikipedia_articles_embeddings_titles_vector]
ORDER BY
VECTOR_DISTANCE('cosine', @my_reference_vector, embedding)
Vectoren in oudere versies van SQL Server
Hoewel oudere versies van de SQL Server-engine, tot en met SQL Server 2022, geen systeemeigen vector type hebben, is een vector niets meer dan een geordende tuple en relationele databases zijn geweldig bij het beheren van tuples. U kunt een tuple beschouwen als de formele term voor een rij in een tabel.
Azure SQL Database biedt ook ondersteuning voor columnstore-indexen en uitvoering van batchmodus. Een op vector gebaseerde benadering wordt gebruikt voor batchmodusverwerking, wat betekent dat elke kolom in een batch een eigen geheugenlocatie heeft waar deze als vector wordt opgeslagen. Dit zorgt voor een snellere en efficiëntere verwerking van gegevens in batches.
In het volgende voorbeeld ziet u hoe een vector kan worden opgeslagen in SQL Database:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[vector_value_id] [int] NOT NULL,
[vector_value] [float] NOT NULL
)
GO
CREATE CLUSTERED COLUMNSTORE INDEX ixc
ON dbo.wikipedia_articles_embeddings_titles_vector
ORDER (article_id);
GO
Zie Vector similarity search with Azure SQL Database and OpenAIvoor een voorbeeld dat gebruikmaakt van een algemene subset van Wikipedia-artikelen met embeddings die met behulp van OpenAI al zijn gegenereerd.
Een andere optie voor het gebruik van Vector Search in Azure SQL Database is integratie met Azure AI met behulp van de geïntegreerde vectorisatiemogelijkheden: Vector Search met Azure SQL Database en Azure AI Search
Azure AI Search
RAG-patronen implementeren met Azure SQL Database en Azure AI Search. U kunt ondersteunde chatmodellen uitvoeren op gegevens die zijn opgeslagen in Azure SQL Database, zonder dat u modellen hoeft te trainen of af te stemmen, dankzij de integratie van Azure AI Search met Azure OpenAI en Azure SQL Database. Door modellen op uw gegevens uit te voeren, kunt u met grotere nauwkeurigheid en snelheid met uw gegevens chatten en ze analyseren.
- Azure OpenAI op uw gegevens
- Augmented Generation (RAG) ophalen in Azure AI Search
- Vector Search met Azure SQL Database en Azure AI Search
Intelligente toepassingen
Azure SQL Database kan worden gebruikt om intelligente toepassingen te bouwen die AI-functies bevatten, zoals aanbevelingen en RAG (Retrieval Augmented Generation), zoals in het volgende diagram wordt gedemonstreert:

Voor een end-to-end voorbeeld om een door AI ondersteunde toepassing te bouwen met "sessions abstract" als voorbeeldgegevensset, zie:
- Hoe ik in 1 uur een sessiebeveelaar heb gemaakt met behulp van OpenAI.
- Het gebruik van Retrieval Augmented Generation om een conferentiesessie-assistent te bouwen
LangChain-integratie
LangChain is een bekend framework voor het ontwikkelen van toepassingen die mogelijk worden gemaakt door taalmodellen. Zie voor voorbeelden die laten zien hoe LangChain kan worden gebruikt om een chatbot op uw eigen gegevens te maken:
- langchain-sqlserver PyPI-pakket
Enkele voorbeelden voor het gebruik van Azure SQL met LangChain:
End-to-end voorbeelden:
- in 1 uur een chatbot bouwen op uw eigen gegevens met Azure SQL, Langchain en Chainlit: Bouw een chatbot met behulp van het RAG-patroon op uw eigen gegevens met behulp van Langchain voor het organiseren van LLM-aanroepen en Chainlit voor de gebruikersinterface.
- uw eigen DB Copilot voor Azure SQL bouwen met Azure OpenAI GPT-4: bouw een copilot-achtige ervaring om uw databases te doorzoeken met natuurlijke taal.
Semantische kernelintegratie
Semantische kernel is een opensource-SDK- waarmee u eenvoudig agents kunt bouwen die uw bestaande code kunnen aanroepen. Als zeer uitbreidbare SDK kunt u Semantische kernel gebruiken met modellen uit OpenAI, Azure OpenAI, Hugging Face en meer. Door uw bestaande C#-, Python- en Java-code te combineren met deze modellen, kunt u agents bouwen die vragen beantwoorden en processen automatiseren.
Hier ziet u een voorbeeld van hoe eenvoudig Semantische kernel helpt bij het bouwen van ai-oplossingen:
- De ultieme chatbot?: Bouw een chatbot op uw eigen gegevens met zowel NL2SQL- als RAG-patronen voor de ultieme gebruikerservaring.
Microsoft Copilot-vaardigheden in Azure SQL Database
Microsoft Copilot-vaardigheden in Azure SQL Database (preview) is een set AI-ondersteunde ervaringen die zijn ontworpen om het ontwerp, het beheer, de optimalisatie en de gezondheid van Azure SQL Database-gestuurde toepassingen te stroomlijnen. Copilot kan de productiviteit verbeteren door natuurlijke taal aan te bieden voor SQL-conversie en zelfhulp voor databasebeheer.
Copilot biedt relevante antwoorden op gebruikersvragen, vereenvoudigt databasebeheer door gebruik te maken van databasecontext, documentatie, dynamische beheerweergaven, Query Store en andere kennisbronnen. Bijvoorbeeld:
- Databasebeheerders kunnen onafhankelijk databases beheren en problemen oplossen, of meer informatie over de prestaties en mogelijkheden van uw database.
- Ontwikkelaars kunnen vragen stellen over hun gegevens zoals ze zouden doen in tekst of gesprek om een T-SQL-query te genereren. Ontwikkelaars kunnen ook sneller query's schrijven via gedetailleerde uitleg van de gegenereerde query.
Notitie
Microsoft Copilot-vaardigheden in Azure SQL Database zijn momenteel in preview voor een beperkt aantal early adopters. Als u zich wilt registreren voor dit programma, gaat u naar Toegang aanvragen tot Copilot in Azure SQL Database: Preview.
De preview-versie van Copilot voor Azure SQL Database bevat twee Azure Portal-ervaringen:
| Portallocatie | Ervaringen |
|---|---|
| Query-editor in Azure Portal | Natuurlijke taal naar SQL: deze ervaring in de query-editor van de Azure-portal voor Azure SQL Database vertaalt query's in natuurlijke taal in SQL, waardoor databaseinteracties intuïtiever worden. Zie voor een zelfstudie en voorbeelden van natuurlijke taal voor SQL-mogelijkheden Natuurlijke taal voor SQL in de Query-editor (preview) van Azure Portal. |
| Microsoft Copilot voor Azure | Azure Copilot-integratie: met deze ervaring worden Azure SQL-vaardigheden toegevoegd aan Microsoft Copilot voor Azure, zodat klanten zelfhulp krijgen, zodat ze hun databases kunnen beheren en problemen onafhankelijk kunnen oplossen. |
Zie Veelgestelde vragen over Microsoft Copilot-vaardigheden in Azure SQL Database (preview)voor meer informatie.
Microsoft Copilot-vaardigheden in Fabric SQL-database (voorvertoning)
Copilot voor SQL Database in Microsoft Fabric (preview) bevat geïntegreerde AI-hulp met de volgende functies:
Code-voltooiing: Begin met het schrijven van T-SQL in de SQL-queryeditor en Copilot genereert automatisch een codesuggestie om uw query te voltooien. De Tab--toets accepteert de codesuggestie, of je kunt blijven typen om de suggestie te negeren.
Snelle acties: op het lint van de SQL-queryeditor zijn de opties herstellen en Uitleg opties snelle acties. Markeer een SQL-query van uw keuze en selecteer een van de snelle actieknoppen om de geselecteerde actie uit te voeren op uw query.
Oplossing: Copilot kan fouten in uw code oplossen wanneer er foutberichten optreden. Foutscenario's kunnen onjuiste/niet-ondersteunde T-SQL-code, verkeerde spelling en meer omvatten. Copilot geeft ook opmerkingen die de wijzigingen uitleggen en aanbevolen procedures voor SQL voorstellen.
Uitleg: Copilot kan uitleg in natuurlijke taal geven over uw SQL-query en databaseschema in opmerkingenindeling.
chatvenster: gebruik het chatvenster om vragen te stellen aan Copilot via natuurlijke taal. Copilot reageert met een gegenereerde SQL-query of natuurlijke taal op basis van de gestelde vraag.
natuurlijke taal naar SQL: T-SQL-code genereren op basis van aanvragen voor tekst zonder opmaak en suggesties krijgen voor vragen om uw werkstroom te versnellen.
nl-NL: Documentgebaseerde Q&A-: Stel Copilot vragen over algemene SQL-databasemogelijkheden, en Copilot beantwoordt deze in natuurlijke taal. Copilot helpt ook bij het vinden van documentatie met betrekking tot uw aanvraag.
Copilot voor SQL Database maakt gebruik van tabel- en weergavenamen, kolomnamen, primaire sleutel en refererende sleutelmetagegevens om T-SQL-code te genereren. Copilot voor SQL Database gebruikt geen gegevens in tabellen om T-SQL-suggesties te genereren.