Architectuurhandleiding voor queryverwerking
van toepassing op:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
De SQL Server Database Engine verwerkt query's op verschillende gegevensopslagarchitecturen, zoals lokale tabellen, gepartitioneerde tabellen en tabellen die zijn verdeeld over meerdere servers. In de volgende secties wordt beschreven hoe SQL Server query's verwerkt en het hergebruik van query's optimaliseert via caching van het uitvoeringsplan.
Uitvoeringsmodi
De SQL Server Database Engine kan Transact-SQL instructies verwerken met behulp van twee verschillende verwerkingsmodi:
- Uitvoering in rijmodus
- Uitvoering van batchmodus
Uitvoering van rijmodus
Rijmodusuitvoering is een queryverwerkingsmethode die wordt gebruikt met traditionele RDBMS-tabellen, waarbij gegevens in rijindeling worden opgeslagen. Wanneer een query wordt uitgevoerd en toegang krijgt tot gegevens in rijopslagtabellen, lezen de operatoren van de uitvoeringsstructuur en onderliggende operators elke vereiste rij voor alle kolommen die zijn opgegeven in het tabelschema. Uit elke rij die wordt gelezen, haalt SQL Server vervolgens de kolommen op die vereist zijn voor de resultatenset, zoals wordt verwezen door een SELECT-instructie, JOIN-predicaat of filterpredicaat.
Notitie
De uitvoering van rijmodus is zeer efficiënt voor OLTP-scenario's, maar kan minder efficiënt zijn bij het scannen van grote hoeveelheden gegevens, bijvoorbeeld in datawarehousingscenario's.
Uitvoering van batchmodus
uitvoering van batchmodus is een queryverwerkingsmethode die wordt gebruikt om meerdere rijen samen te verwerken (vandaar de termbatch). Elke kolom in een batch wordt opgeslagen als een vector in een afzonderlijk geheugengebied, dus batchmodusverwerking is gebaseerd op vectoren. Batchmodusverwerking maakt ook gebruik van algoritmen die zijn geoptimaliseerd voor de CPU's met meerdere kernen en meer geheugendoorvoer die op moderne hardware worden gevonden.
Toen deze voor het eerst werd geïntroduceerd, werd de uitvoering van de batchmodus nauw geïntegreerd met en geoptimaliseerd, de columnstore-opslagindeling. Vanaf SQL Server 2019 (15.x) en in Azure SQL Database zijn voor batchmodusuitvoering echter geen columnstore-indexen meer vereist. Zie Batch-modus in rowstorevoor meer informatie.
Batchmodus verwerking werkt waar mogelijk op gecomprimeerde gegevens en elimineert de exchange-operator die door de uitvoering in de rijmodus wordt gebruikt. Het resultaat is beter parallellisme en snellere prestaties.
Wanneer een query wordt uitgevoerd in de batchmodus en gegevens in columnstore-indexen opent, lezen de operators van de uitvoeringsstructuur en onderliggende operators meerdere rijen samen in kolomsegmenten. SQL Server leest alleen de kolommen die vereist zijn voor het resultaat, zoals wordt verwezen door een SELECT-instructie, JOIN-predicaat of filterpredicaat. Zie Columnstore Index Architecturevoor meer informatie over columnstore-indexen.
Notitie
Batchmodusuitvoering is zeer efficiënt in datawarehousing-scenario's waarbij grote hoeveelheden gegevens worden gelezen en samengevoegd.
Verwerking van SQL-instructies
Het verwerken van één Transact-SQL-instructie is de meest eenvoudige manier waarop SQL Server Transact-SQL instructies uitvoert. De stappen voor het verwerken van één SELECT instructie die verwijst naar alleen lokale basistabellen (geen weergaven of externe tabellen) illustreren het basisproces.
Volgorde van logische operatoren
Wanneer meer dan één logische operator wordt gebruikt in een instructie, wordt NOT eerst geëvalueerd, vervolgens ANDen ten slotte OR. Rekenkundige en bitsgewijze operators worden verwerkt vóór logische operators. Zie Operator-prioriteitvoor meer informatie.
In het volgende voorbeeld heeft de kleurvoorwaarde betrekking op productmodel 21 en niet op productmodel 20, omdat AND voorrang heeft op OR.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
U kunt de betekenis van de query wijzigen door haakjes toe te voegen om de evaluatie van de OR eerst af te dwingen. Met de volgende query worden alleen producten gevonden onder modellen 20 en 21 die rood zijn.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
Het gebruik van haakjes, zelfs als ze niet nodig zijn, kan de leesbaarheid van query's verbeteren en de kans op een subtiele fout verminderen vanwege de prioriteit van de operator. Er is geen aanzienlijke prestatiestraf bij het gebruik van haakjes. Het volgende voorbeeld is beter leesbaar dan het oorspronkelijke voorbeeld, hoewel ze syntactisch hetzelfde zijn.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
SELECT-instructies optimaliseren
Een SELECT verklaring is niet-procedureel; er worden niet de exacte stappen vermeld die de databaseserver moet gebruiken om de aangevraagde gegevens op te halen. Dit betekent dat de databaseserver de instructie moet analyseren om de meest efficiënte manier te bepalen om de aangevraagde gegevens te extraheren. Dit wordt aangeduid als het optimaliseren van de SELECT-instructie. Het onderdeel dat dit doet, wordt de Query Optimizer genoemd. De invoer voor queryoptimalisatie bestaat uit de query, het databaseschema (tabel- en indexdefinities) en de databasestatistieken. De output van de Query Optimizer is een queryuitvoeringsplan, ook wel een query- of uitvoeringsplan genoemd. De inhoud van een uitvoeringsplan wordt verderop in dit artikel uitgebreider beschreven.
De invoer en uitvoer van de Query Optimizer tijdens de optimalisatie van één SELECT-instructie worden geïllustreerd in het volgende diagram:

Een SELECT-instructie definieert alleen het volgende:
- De indeling van de resultatenset. Dit wordt meestal opgegeven in de selectielijst. Andere componenten, zoals
ORDER BYenGROUP BYhebben echter ook invloed op de uiteindelijke vorm van de resultatenset. - De tabellen die de brongegevens bevatten. Dit wordt opgegeven in de
FROM-clausule. - Hoe de tabellen logisch met elkaar samenhangen voor de
SELECT-instructie. Dit wordt gedefinieerd in de joinspecificaties, die kunnen worden weergegeven in deWHEREclausule of in eenONclausule naFROM. - De voorwaarden waaraan de rijen in de brontabellen moeten voldoen om in aanmerking te komen voor de
SELECT-instructie. Deze worden opgegeven in deWHERE- enHAVING-clausules.
Een queryuitvoeringsplan is een definitie van het volgende:
De volgorde waarin de brontabellen worden geopend.
Normaal gesproken zijn er veel reeksen waarin de databaseserver toegang heeft tot de basistabellen om de resultatenset te bouwen. Als deSELECT-instructie bijvoorbeeld verwijst naar drie tabellen, kan de databaseserver eerst toegang krijgen totTableA, de gegevens uitTableAgebruiken om overeenkomende rijen uitTableBte extraheren en vervolgens de gegevens uitTableBgebruiken om gegevens uitTableCte extraheren. De andere reeksen waarin de databaseserver toegang heeft tot de tabellen, zijn:
TableC,TableB,TableAof
TableB,TableA,TableCof
TableB,TableC,TableAof
TableC,TableA,TableBDe methoden die worden gebruikt om gegevens uit elke tabel te extraheren.
Over het algemeen zijn er verschillende methoden voor toegang tot de gegevens in elke tabel. Als er slechts een paar rijen met specifieke sleutelwaarden vereist zijn, kan de databaseserver een index gebruiken. Als alle rijen in de tabel vereist zijn, kan de databaseserver de indexen negeren en een tabelscan uitvoeren. Als alle rijen in een tabel vereist zijn, maar er een index is waarvan de sleutelkolommen zich in eenORDER BYbevinden, kan het uitvoeren van een indexscan in plaats van een tabelscan een afzonderlijk soort resultatenset opslaan. Als een tabel erg klein is, zijn tabelscans mogelijk de meest efficiënte methode voor bijna alle toegang tot de tabel.De methoden die worden gebruikt voor het berekenen van berekeningen en het filteren, aggregeren en sorteren van gegevens uit elke tabel.
Naarmate gegevens worden geopend vanuit tabellen, zijn er verschillende methoden om berekeningen uit te voeren op gegevens zoals scalaire waarden berekenen en gegevens te aggregeren en sorteren zoals gedefinieerd in de querytekst, bijvoorbeeld bij het gebruik van eenGROUP BY- ofORDER BY-component, en het filteren van gegevens, bijvoorbeeld wanneer u eenWHERE- ofHAVING-component gebruikt.
Het proces van het selecteren van één uitvoeringsplan uit mogelijk veel mogelijke plannen wordt optimalisatie genoemd. Query Optimizer is een van de belangrijkste onderdelen van de database-engine. Hoewel de Query Optimizer enige overhead gebruikt om de query te analyseren en een plan te selecteren, wordt deze overhead doorgaans meerdere keren opgeslagen wanneer de Query Optimizer een efficiënt uitvoeringsplan kiest. Twee bouwbedrijven kunnen bijvoorbeeld identieke blauwdrukken voor een huis krijgen. Als één bedrijf een paar dagen aan het begin doorbrengt om te plannen hoe ze het huis gaan bouwen en het andere bedrijf begint te bouwen zonder planning, zal het bedrijf dat de tijd neemt om het project te plannen waarschijnlijk eerst eindigen.
Sql Server Query Optimizer is een optimalisatie op basis van kosten. Elk mogelijk uitvoeringsplan heeft een bijbehorende kosten in termen van de hoeveelheid gebruikte rekenresources. De Query Optimizer moet de mogelijke plannen analyseren en het abonnement kiezen met de laagste geschatte kosten. Sommige complexe SELECT-instructies hebben duizenden mogelijke uitvoeringsplannen. In deze gevallen analyseert de Query Optimizer niet alle mogelijke combinaties. In plaats daarvan worden complexe algoritmen gebruikt om een uitvoeringsplan te vinden dat redelijk dicht bij de minimale kosten ligt.
De SQL Server Query Optimizer kiest niet alleen het uitvoeringsplan met de laagste resourcekosten; het kiest het plan dat resultaten retourneert aan de gebruiker met een redelijke kosten in resources en die de resultaten het snelst retourneert. Het parallel verwerken van een query maakt bijvoorbeeld meestal gebruik van meer resources dan het serieel verwerken, maar voltooit de query sneller. De SQL Server Query Optimizer gebruikt een parallel uitvoeringsplan om resultaten te retourneren als de belasting op de server niet nadelig wordt beïnvloed.
De SQL Server Query Optimizer is afhankelijk van distributiestatistieken wanneer de resourcekosten van verschillende methoden worden geschat voor het extraheren van gegevens uit een tabel of index. Distributiestatistieken worden bewaard voor kolommen en indexen en bevatten informatie over de dichtheid1 van de onderliggende gegevens. Dit wordt gebruikt om de selectiviteit van de waarden in een bepaalde index of kolom aan te geven. In een tabel die auto's vertegenwoordigt, hebben veel auto's bijvoorbeeld dezelfde fabrikant, maar elke auto heeft een uniek voertuigidentificatienummer (VIN). Een index van de VIN is selectiever dan een index van de fabrikant, omdat VIN een lagere dichtheid heeft dan de fabrikant. Als de indexstatistieken niet actueel zijn, is de queryoptimalisatie mogelijk niet de beste keuze voor de huidige status van de tabel. Zie Statisticsvoor meer informatie over densiteit.
1 Dichtheid definieert de verdeling van unieke waarden in de gegevens of het gemiddelde aantal dubbele waarden voor een bepaalde kolom. Naarmate de dichtheid afneemt, neemt de selectiviteit van een waarde toe.
De SQL Server Query Optimizer is belangrijk omdat de databaseserver dynamisch kan worden aangepast aan veranderende omstandigheden in de database zonder dat er invoer van een programmeur of databasebeheerder nodig is. Hierdoor kunnen programmeurs zich richten op het beschrijven van het uiteindelijke resultaat van de query. Ze kunnen vertrouwen dat de SQL Server Query Optimizer een efficiënt uitvoeringsplan bouwt voor de status van de database telkens wanneer de instructie wordt uitgevoerd.
Notitie
SQL Server Management Studio heeft drie opties voor het weergeven van uitvoeringsplannen:
- Het Geschatte uitvoeringsplan, het gecompileerde plan, zoals geproduceerd door de Query Optimizer.
- Het werkelijke uitvoeringsplan, dat hetzelfde is als het gecompileerde plan plus de uitvoeringscontext. Dit omvat runtime-informatie die beschikbaar is nadat de uitvoering is voltooid, zoals uitvoeringswaarschuwingen of in nieuwere versies van de database-engine, de verstreken en CPU-tijd die tijdens de uitvoering is gebruikt.
- De Live Query Statistics, die hetzelfde zijn als het gecompileerde plan plus de uitvoeringscontext. Dit omvat runtime-informatie tijdens de uitvoeringsvoortgang en wordt elke seconde bijgewerkt. Runtime-informatie omvat bijvoorbeeld het werkelijke aantal rijen dat door de operatoren stroomt.
Een SELECT-instructie verwerken
De basisstappen die SQL Server gebruikt om één SELECT-instructie te verwerken, zijn onder andere:
- De parser scant de
SELECTinstructie en breekt deze op in logische eenheden, zoals trefwoorden, expressies, operators en id's. - Een querystructuur, ook wel een reeksstructuur genoemd, wordt gebouwd met een beschrijving van de logische stappen die nodig zijn om de brongegevens te transformeren in de indeling die is vereist voor de resultatenset.
- Query Optimizer analyseert verschillende manieren waarop de brontabellen kunnen worden geopend. Vervolgens selecteert u de reeks stappen die de resultaten het snelst retourneren terwijl u minder resources gebruikt. De querystructuur wordt bijgewerkt om deze exacte reeks stappen vast te leggen. De uiteindelijke, geoptimaliseerde versie van de querystructuur wordt het uitvoeringsplan genoemd.
- De relationele engine begint met het uitvoeren van het uitvoeringsplan. Wanneer de stappen die gegevens uit de basistabellen vereisen worden verwerkt, vraagt de relationele engine dat de opslagengine gegevens uit de gevraagde gegevensreeksen doorgeeft aan de relationele engine.
- De relationele engine verwerkt de gegevens die worden geretourneerd door de opslagengine in de indeling die is gedefinieerd voor de resultatenset en retourneert de resultatenset naar de client.
Evaluatie van constant vouwen en expressies
SQL Server evalueert enkele constante expressies vroeg om de queryprestaties te verbeteren. Dit wordt ook wel constant vouwen genoemd. Een constante is een letterlijke Transact-SQL, zoals 3, 'ABC', '2005-12-31', 1.0e3of 0x12345678.
Vouwbare expressies
SQL Server maakt gebruik van constant vouwen met de volgende typen expressies:
- Rekenkundige expressies, zoals
1 + 1en5 / 3 * 2, die alleen constanten bevatten. - Logische expressies, zoals
1 = 1en1 > 2 AND 3 > 4, die alleen constanten bevatten. - Ingebouwde functies die worden beschouwd als vouwbaar door SQL Server, waaronder
CASTenCONVERT. Over het algemeen is een intrinsieke functie vouwbaar als deze alleen een functie is van de invoer en niet van andere contextuele informatie, zoals SET-opties, taalinstellingen, databaseopties en versleutelingssleutels. Niet-deterministische functies zijn niet vouwbaar. Deterministische ingebouwde functies kunnen worden gevouwen, met enkele uitzonderingen. - Deterministische methoden van door de gebruiker gedefinieerde CLR-typen en deterministische, door de gebruiker gedefinieerde CLR-functies (te beginnen met SQL Server 2012 (11.x)). Zie Constant Folding voor CLR User-Defined Functions and Methodsvoor meer informatie.
Notitie
Er wordt een uitzondering gemaakt voor grote objecttypen. Als het uitvoertype van het vouwproces een groot objecttype is (tekst, ntext, afbeelding, nvarchar(max), varchar(max), varbinary(max) of XML), vouwt SQL Server de expressie niet.
Niet-samenvouwbare expressies
Alle andere expressietypen kunnen niet worden gevouwen. In het bijzonder zijn de volgende typen expressies niet vouwbaar:
- Niet-stante expressies, zoals een expressie waarvan het resultaat afhankelijk is van de waarde van een kolom.
- Expressies waarvan de resultaten afhankelijk zijn van een lokale variabele of parameter, zoals @x.
- Niet-deterministische functies.
- Door de gebruiker gedefinieerde Transact-SQL functies1.
- Expressies waarvan de resultaten afhankelijk zijn van taalinstellingen.
- Expressies waarvan de resultaten afhankelijk zijn van SET-opties.
- Expressies waarvan de resultaten afhankelijk zijn van serverconfiguratieopties.
1 Vóór SQL Server 2012 (11.x) waren deterministische scalaire door de gebruiker gedefinieerde CLR-functies en methoden van door de gebruiker gedefinieerde CLR-typen niet vouwbaar.
Voorbeelden van vouwbare en niet-vouwbare constante expressies
Houd rekening met de volgende query:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
Als de PARAMETERIZATION databaseoptie niet is ingesteld op FORCED voor deze query, wordt de expressie 117.00 + 1000.00 geëvalueerd en vervangen door het resultaat, 1117.00, voordat de query wordt gecompileerd. Voordelen van deze constante vouw zijn onder andere:
- De expressie hoeft niet herhaaldelijk tijdens runtime te worden geëvalueerd.
- De waarde van de expressie nadat deze is geëvalueerd, wordt door de Query Optimizer gebruikt om de grootte van de resultatenset van het gedeelte van de query
TotalDue > 117.00 + 1000.00te schatten.
Als dbo.f daarentegen een scalaire door de gebruiker gedefinieerde functie is, wordt de expressie dbo.f(100) niet gevouwen, omdat SQL Server geen expressies vouwt die door de gebruiker gedefinieerde functies omvatten, zelfs als ze deterministisch zijn. Zie Geforceerde parameterisatie verderop in dit artikel voor meer informatie over parameters.
Expressie-evaluatie
Daarnaast worden sommige expressies die niet constant zijn gevouwen, maar waarvan de argumenten al bij het compileren bekend zijn, ongeacht of het parameters of constanten zijn, geëvalueerd door de cardinaliteitsschatting die onderdeel is van de optimizer tijdens de optimalisatie.
Met name de volgende ingebouwde functies en speciale operators worden geëvalueerd tijdens het compileren als al hun invoer bekend is: UPPER, LOWER, RTRIM, DATEPART( YY only ), GETDATE, CASTen CONVERT. De volgende operators worden ook tijdens het compileren geëvalueerd als al hun invoer bekend is:
- Rekenkundige operatoren: +, -, *, /, unaire -
- Logische operators:
AND,OR,NOT - Vergelijkingsoperatoren: <, >, <=, >=, <>,
LIKE,IS NULL,IS NOT NULL
Er worden geen andere functies of operators geëvalueerd door de Query Optimizer tijdens de schatting van de kardinaliteit.
Voorbeelden van evaluatie van compilatietijdexpressie
Beschouw deze opgeslagen procedure:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
Tijdens de optimalisatie van de instructie SELECT in de procedure probeert de Query Optimizer de verwachte kardinaliteit van de resultatenset voor de voorwaarde OrderDate > @d+1te evalueren. De expressie @d+1 is niet constant opgevouwen, omdat @d een parameter is. Tijdens optimalisatietijd is de waarde van de parameter echter bekend. Hierdoor kan de Query Optimizer de grootte van de resultatenset nauwkeurig schatten, zodat het een goed queryplan kan selecteren.
Bekijk nu een voorbeeld dat vergelijkbaar is met de vorige, behalve dat een lokale variabele @d2@d+1 in de query vervangt en de expressie wordt geëvalueerd in een SET-instructie in plaats van in de query.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
Wanneer de SELECT-instructie in MyProc2 is geoptimaliseerd in SQL Server, is de waarde van @d2 niet bekend. Query Optimizer gebruikt daarom een standaardschatting voor de selectiviteit van OrderDate > @d2(in dit geval 30 procent).
Andere verklaringen verwerken
De basisstappen die worden beschreven voor het verwerken van een SELECT instructie zijn van toepassing op andere Transact-SQL-instructies, zoals INSERT, UPDATEen DELETE.
UPDATE- en DELETE-instructies moeten beide zijn gericht op de set rijen die moeten worden gewijzigd of verwijderd. Het proces voor het identificeren van deze rijen is hetzelfde proces dat wordt gebruikt om de bronrijen te identificeren die bijdragen aan de resultatenset van een SELECT-instructie. De instructies UPDATE en INSERT bevatten mogelijk ingesloten SELECT instructies waarmee de gegevenswaarden worden bijgewerkt of ingevoegd.
Zelfs DDL-instructies (Data Definition Language), zoals CREATE PROCEDURE of ALTER TABLE, worden uiteindelijk omgezet in een reeks relationele bewerkingen op de systeemcatalogustabellen en soms (zoals ALTER TABLE ADD COLUMN) voor de gegevenstabellen.
Werktabellen
De relationele engine moet mogelijk een werktabel maken om een logische bewerking uit te voeren die is opgegeven in een Transact-SQL-instructie. Werktabellen zijn interne tabellen die worden gebruikt voor het opslaan van tussenliggende resultaten. Werktabellen worden gegenereerd voor bepaalde GROUP BY, ORDER BYof UNION queries. Als een ORDER BY component bijvoorbeeld verwijst naar kolommen die niet worden gedekt door indexen, moet de relationele engine mogelijk een werktabel genereren om de resultatenset in de aangevraagde volgorde te sorteren. Werktabellen worden soms ook gebruikt als spools die het resultaat van het uitvoeren van een deel van een queryplan tijdelijk bevatten. Werktabellen zijn ingebouwd in tempdb en worden automatisch verwijderd wanneer ze niet meer nodig zijn.
Resolutie weergeven
De SQL Server-queryprocessor behandelt geïndexeerde en niet-geïndexeerde weergaven anders:
- De rijen van een geïndexeerde weergave worden opgeslagen in de database in dezelfde indeling als een tabel. Als de queryoptimalisatie besluit een geïndexeerde weergave in een queryplan te gebruiken, wordt de geïndexeerde weergave op dezelfde manier behandeld als een basistabel.
- Alleen de definitie van een niet-geïndexeerde weergave wordt opgeslagen, niet de rijen van de weergave. Query Optimizer bevat de logica van de weergavedefinitie in het uitvoeringsplan dat wordt gebouwd voor de Transact-SQL-instructie die verwijst naar de niet-geïndexeerde weergave.
De logica die wordt gebruikt door sql Server Query Optimizer om te bepalen wanneer een geïndexeerde weergave moet worden gebruikt, is vergelijkbaar met de logica die wordt gebruikt om te bepalen wanneer een index in een tabel moet worden gebruikt. Als de gegevens in de geïndexeerde weergave alle of een deel van de instructie Transact-SQL dekt en de Query Optimizer bepaalt dat een index in de weergave het goedkope toegangspad is, kiest de Query Optimizer de index, ongeacht of er in de query naar de weergave wordt verwezen.
Wanneer een Transact-SQL instructie verwijst naar een niet-geïndexeerde weergave, analyseert de parser en Query Optimizer de bron van zowel de Transact-SQL-instructie als de weergave en lost deze vervolgens op in één uitvoeringsplan. Er is geen plan voor de Transact-SQL-verklaring noch een afzonderlijk plan voor de weergave.
Bekijk bijvoorbeeld de volgende weergave:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
Op basis van deze weergave voeren beide Transact-SQL-instructies dezelfde bewerkingen uit op de basistabellen en produceren ze dezelfde resultaten:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
De functie SQL Server Management Studio Showplan laat zien dat de relationele engine hetzelfde uitvoeringsplan bouwt voor beide SELECT instructies.
Hints gebruiken bij weergaven
Hints die in weergaven in een query worden geplaatst, kunnen conflicteren met andere hints die worden ontdekt wanneer de weergave wordt uitgebreid om toegang tot de basistabellen te krijgen. Wanneer dit gebeurt, retourneert de query een fout. Bekijk bijvoorbeeld de volgende weergave die een tabelhint in de definitie bevat:
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
Stel nu dat u deze query invoert:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
De query mislukt omdat de hint SERIALIZABLE die wordt toegepast op weergave Person.AddrState in de query wordt doorgegeven aan tabellen Person.Address en Person.StateProvince in de weergave wanneer deze wordt uitgevouwen. Als u de weergave echter uitvouwt, ziet u ook de NOLOCK hint op Person.Address. Omdat de SERIALIZABLE en NOLOCK hints conflicteren, is de resulterende query onjuist.
De PAGLOCK, NOLOCK, ROWLOCK, TABLOCKof TABLOCKX tabelhints conflicteren met elkaar, net zoals de HOLDLOCK, NOLOCK, READCOMMITTED, REPEATABLEREAD, SERIALIZABLE tabelhints.
Hints kunnen worden doorgegeven via niveaus van geneste weergaven. Stel dat een query de HOLDLOCK hint toepast op een view v1. Wanneer v1 is uitgevouwen, vinden we dat weergave v2 deel uitmaakt van de definitie. De definitie van v2bevat een NOLOCK hint voor een van de basistabellen. Maar deze tabel neemt ook de HOLDLOCK hint over van de query in weergave v1. Omdat de NOLOCK en HOLDLOCK hints conflicteren, mislukt de query.
Wanneer de FORCE ORDER hint wordt gebruikt in een query die een weergave bevat, wordt de joinvolgorde van de tabellen in de weergave bepaald door de positie van de weergave in de geordende constructie. De volgende query selecteert bijvoorbeeld uit drie tabellen en een weergave:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
En View1 wordt gedefinieerd zoals wordt weergegeven in het volgende:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
De joinvolgorde in het queryplan is Table1, Table2, TableA, TableB, Table3.
Indexen voor weergaven oplossen
Net als bij een index kiest SQL Server ervoor om alleen een geïndexeerde weergave in het queryplan te gebruiken als de Query Optimizer bepaalt dat dit nuttig is.
Geïndexeerde weergaven kunnen worden gemaakt in elke editie van SQL Server. In sommige edities van sommige oudere versies van SQL Server beschouwt Query Optimizer automatisch de geïndexeerde weergave. In sommige edities van sommige oudere versies van SQL Server moet de hint voor de NOEXPAND tabel worden gebruikt om een geïndexeerde weergave te gebruiken. Automatisch gebruik van een geïndexeerde weergave door de queryoptimalisatie wordt alleen ondersteund in specifieke edities van SQL Server. Azure SQL Database en Azure SQL Managed Instance ondersteunen ook het automatisch gebruik van geïndexeerde weergaven zonder de NOEXPAND hint op te geven.
De SQL Server Query Optimizer maakt gebruik van een geïndexeerde weergave wanneer aan de volgende voorwaarden wordt voldaan:
- Deze sessieopties zijn ingesteld op
ON:ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
- De
NUMERIC_ROUNDABORTsessieoptie is ingesteld op UIT. - Met Query Optimizer wordt een overeenkomst gevonden tussen de weergaveindexkolommen en -elementen in de query, zoals:
- Zoekvoorwaarde predicaten in de WHERE-component
- Joinbewerkingen
- Aggregatiefuncties
-
GROUP BY-clausules - Tabelverwijzingen
- De geschatte kosten voor het gebruik van de index hebben de laagste kosten van eventuele toegangsmechanismen die door de Query Optimizer worden beschouwd.
- Elke tabel waarnaar in de query wordt verwezen (rechtstreeks of door een weergave uit te vouwen voor toegang tot de onderliggende tabellen) die overeenkomt met een tabelverwijzing in de geïndexeerde weergave, moet dezelfde set hints hebben toegepast in de query.
Notitie
De hints voor READCOMMITTED en READCOMMITTEDLOCK worden altijd als verschillende hints in deze context beschouwd, ongeacht het huidige isolatieniveau van transacties.
Behalve de vereisten voor de SET opties en tabelhints, zijn dit dezelfde regels die de Query Optimizer gebruikt om te bepalen of een tabelindex een query omvat. Er hoeft niets anders te worden opgegeven in de query voor een geïndexeerde weergave die moet worden gebruikt.
Een query hoeft niet expliciet te verwijzen naar een geïndexeerde weergave in de FROM component voor de Query Optimizer om de geïndexeerde weergave te gebruiken. Als de query verwijzingen bevat naar kolommen in de basistabellen die ook aanwezig zijn in de geïndexeerde weergave en de Query Optimizer schattingen maakt dat het gebruik van de geïndexeerde weergave het laagste mechanisme voor toegang tot kosten biedt, kiest de Query Optimizer de geïndexeerde weergave, vergelijkbaar met de manier waarop deze basistabelindexen kiest wanneer ze niet rechtstreeks in een query worden verwezen. De queryoptimalisatie kan de weergave kiezen wanneer deze kolommen bevat waarnaar niet wordt verwezen door de query, zolang de weergave de laagste kostenoptie biedt voor het dekken van een of meer van de kolommen die in de query zijn opgegeven.
Query Optimizer behandelt een geïndexeerde weergave waarnaar in de FROM-component wordt verwezen als een standaardweergave. De queryoptimalisatie breidt de definitie van de weergave uit naar de query aan het begin van het optimalisatieproces. Vervolgens wordt het vergelijken van geïndexeerde weergaven uitgevoerd. De geïndexeerde weergave kan worden gebruikt in het uiteindelijke uitvoeringsplan dat is geselecteerd door queryoptimalisatie, of in plaats daarvan kan het plan de benodigde gegevens uit de weergave materialiseren door toegang te krijgen tot de basistabellen waarnaar wordt verwezen door de weergave. De Query Optimizer kiest het alternatief voor de laagste kosten.
Hints gebruiken met geïndexeerde weergaven
U kunt voorkomen dat indexen voor een query worden gebruikt met behulp van de EXPAND VIEWS queryhint, of u kunt de NOEXPAND tabelhint gebruiken om het gebruik van een index af te dwingen voor een geïndexeerde weergave die is opgegeven in de FROM component van een query. U moet echter de Query Optimizer dynamisch laten bepalen welke toegangsmethoden voor elke query moeten worden gebruikt. Beperk uw gebruik van EXPAND en NOEXPAND tot specifieke gevallen waarin testen hebben aangetoond dat ze de prestaties aanzienlijk verbeteren.
De
EXPAND VIEWS-optie geeft aan dat de query-optimalisator geen weergave-indexen moet gebruiken voor de hele query.Wanneer
NOEXPANDis opgegeven voor een weergave, houdt de Query Optimizer rekening met het gebruik van indexen die zijn gedefinieerd in de weergave.NOEXPANDopgegeven met de optioneleINDEX()component dwingt de Query Optimizer om de opgegeven indexen te gebruiken.NOEXPANDkan alleen worden opgegeven voor een geïndexeerde weergave en kan niet worden opgegeven voor een weergave die niet is geïndexeerd. Automatisch gebruik van een geïndexeerde weergave door de queryoptimalisatie wordt alleen ondersteund in specifieke edities van SQL Server. Azure SQL Database en Azure SQL Managed Instance ondersteunen ook het automatisch gebruik van geïndexeerde weergaven zonder deNOEXPANDhint op te geven.
Wanneer noch NOEXPAND noch EXPAND VIEWS is opgegeven in een query die een weergave bevat, wordt de weergave uitgebreid voor toegang tot onderliggende tabellen. Als de query waaruit de weergave bestaat, tabelhints bevat, worden deze hints doorgegeven aan de onderliggende tabellen. (Dit proces wordt in meer detail uitgelegd in Weergaveresolutie.) Zolang de set hints die aanwezig zijn in de onderliggende tabellen van de weergave identiek zijn aan elkaar, komt de query in aanmerking voor overeenkomst met een geïndexeerde weergave. Meestal komen deze hints overeen met elkaar, omdat ze rechtstreeks vanuit de weergave worden overgenomen. Als de query echter verwijst naar tabellen in plaats van weergaven en de hints die rechtstreeks op deze tabellen worden toegepast, zijn deze niet identiek, dan komt een dergelijke query niet in aanmerking voor overeenkomsten met een geïndexeerde weergave. Als de INDEX, PAGLOCK, ROWLOCK, TABLOCKX, UPDLOCKof XLOCK hints van toepassing zijn op de tabellen die in de query worden genoemd na het uitbreiden van de weergave, komt de query niet in aanmerking voor overeenkomende geïndexeerde weergave.
Als een tabelhint in de vorm van INDEX (index_val[ ,...n] ) verwijst naar een weergave in een query en u niet ook de NOEXPAND hint opgeeft, wordt de indexhint genegeerd. Als u het gebruik van een bepaalde index wilt opgeven, gebruikt u NOEXPAND.
Over het algemeen worden, wanneer de Queryoptimizator een geïndexeerde weergave met een query vergelijkt, eventuele hints op de tabellen of weergaven in de query rechtstreeks toegepast op de geïndexeerde weergave. Als de Query Optimizer ervoor kiest geen geïndexeerde weergave te gebruiken, worden hints rechtstreeks doorgegeven aan de tabellen waarnaar in de weergave wordt verwezen. Voor meer informatie, zie 'View Resolution'. Deze doorgifte is niet van toepassing op join-hints. Ze worden alleen toegepast op de oorspronkelijke positie in de query. Join-hints worden niet meegenomen door de queryoptimalisatie bij het koppelen van query's aan geïndexeerde weergaven. Als een queryplan gebruikmaakt van een geïndexeerde weergave die overeenkomt met een deel van een query die een join-hint bevat, wordt de join-hint niet gebruikt in het plan.
Hints zijn niet toegestaan in de definities van geïndexeerde weergaven. In de compatibiliteitsmodus 80 en hoger negeert SQL Server hints in geïndexeerde weergavedefinities bij het onderhouden ervan of bij het uitvoeren van query's die gebruikmaken van geïndexeerde weergaven. Hoewel het gebruik van hints in geïndexeerde weergavedefinities geen syntaxisfout veroorzaakt in de compatibiliteitsmodus 80, worden deze genegeerd.
Zie tabelhints (Transact-SQL)voor meer informatie.
Gedistribueerde gepartitioneerde weergaven oplossen
De SQL Server-queryprocessor optimaliseert de prestaties van gedistribueerde gepartitioneerde weergaven. Het belangrijkste aspect van gedistribueerde gepartitioneerde weergaveprestaties is het minimaliseren van de hoeveelheid gegevens die tussen lidservers worden overgedragen.
SQL Server bouwt intelligente, dynamische plannen die efficiënt gebruikmaken van gedistribueerde query's voor toegang tot gegevens uit externe lidtabellen:
- De queryprocessor gebruikt OLE DB om eerst de definities van de controlebeperkingen uit elke lidtabel op te halen. Hierdoor kan de queryprocessor de verdeling van sleutelwaarden over de lidtabellen in kaart brengen.
- De query-processor vergelijkt de sleutelbereiken die zijn opgegeven in een Transact-SQL instructie
WHEREclausule met het overzicht dat laat zien hoe de rijen gedistribueerd worden in de lidtabellen. De queryprocessor bouwt vervolgens een queryuitvoeringsplan dat gebruikmaakt van gedistribueerde query's om alleen de externe rijen op te halen die nodig zijn om de Transact-SQL-instructie te voltooien. Het uitvoeringsplan is ook zodanig gebouwd dat elke toegang tot externe lidtabellen, voor gegevens of metagegevens, wordt uitgesteld totdat de informatie is vereist.
Denk bijvoorbeeld aan een systeem waarin een Customers tabel is gepartitioneerd op Server1 (CustomerID van 1 tot en met 3299999), Server2 (CustomerID van 3300000 tot 6599999) en Server3 (CustomerID van 66000000 tot 9999999).
Overweeg het uitvoeringsplan dat is gebouwd voor deze query die wordt uitgevoerd op Server1:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
Het uitvoeringsplan voor deze query extraheert de rijen met CustomerID-sleutelwaarden van 3200000 tot 3299999 uit de lokale ledentabel en voert een gedistribueerde query uit om de rijen met sleutelwaarden van 3300000 tot en met 3400000 van Server2 op te halen.
De SQL Server-queryprocessor kan ook dynamische logica bouwen in queryuitvoeringsplannen voor Transact-SQL instructies waarin de sleutelwaarden niet bekend zijn wanneer het plan moet worden gebouwd. Denk bijvoorbeeld aan deze opgeslagen procedure:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server kan niet voorspellen welke sleutelwaarde wordt opgegeven door de parameter @CustomerIDParameter telkens wanneer de procedure wordt uitgevoerd. Omdat de sleutelwaarde niet kan worden voorspeld, kan de queryverwerker ook niet voorspellen welk onderdeel van de tabel moet worden geopend. Om dit geval te verwerken, bouwt SQL Server een uitvoeringsplan met voorwaardelijke logica, aangeduid als dynamische filters, om te bepalen welke lidtabel wordt geopend, op basis van de waarde van de invoerparameter. Ervan uitgaande dat de GetCustomer opgeslagen procedure is uitgevoerd op Server1, kan de logica van het uitvoeringsplan worden weergegeven zoals wordt weergegeven in het volgende:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
SQL Server bouwt soms deze typen dynamische uitvoeringsplannen, zelfs voor query's die niet worden geparameteriseerd. Query Optimizer kan een query parameteriseren, zodat het uitvoeringsplan opnieuw kan worden gebruikt. Als de Query Optimizer een query parameteriseert die verwijst naar een gepartitioneerde weergave, kan de Query Optimizer niet langer aannemen dat de vereiste rijen afkomstig zijn van een opgegeven basistabel. Vervolgens moet het dynamische filters in het uitvoeringsplan gebruiken.
Opgeslagen procedure en triggeruitvoering
SQL Server slaat alleen de bron op voor opgeslagen procedures en triggers. Wanneer een opgeslagen procedure of trigger voor het eerst wordt uitgevoerd, wordt de bron gecompileerd in een uitvoeringsplan. Als de opgeslagen procedure of trigger opnieuw wordt uitgevoerd voordat het uitvoeringsplan verouderd is uit het geheugen, detecteert de relationele engine het bestaande plan en wordt het opnieuw gebruikt. Als het plan uit het geheugen is verdwenen, wordt er een nieuw plan gebouwd. Dit proces is vergelijkbaar met het proces dat SQL Server volgt voor alle Transact-SQL instructies. Het belangrijkste prestatievoordeel dat opgeslagen procedures en triggers hebben in SQL Server in vergelijking met batches van dynamische Transact-SQL is dat hun Transact-SQL instructies altijd hetzelfde zijn. Daarom komt de relationele engine eenvoudig overeen met bestaande uitvoeringsplannen. Opgeslagen procedure- en triggerplannen kunnen eenvoudig opnieuw worden gebruikt.
Het uitvoeringsplan voor opgeslagen procedures en triggers wordt afzonderlijk uitgevoerd van het uitvoeringsplan voor de batch die de opgeslagen procedure aanroept of de trigger activeert. Dit maakt het mogelijk om de opgeslagen procedure te hergebruiken en uitvoeringsplannen te activeren.
Uitvoeringsplan opslaan in cache en hergebruik
SQL Server heeft een pool geheugen die wordt gebruikt om zowel uitvoeringsplannen als gegevensbuffers op te slaan. Het percentage van de pool dat is toegewezen aan uitvoeringsplannen of gegevensbuffers fluctueert dynamisch, afhankelijk van de status van het systeem. Het deel van de geheugengroep die wordt gebruikt om uitvoeringsplannen op te slaan, wordt de plancache genoemd.
De plancache heeft twee opslagplaatsen voor alle gecompileerde plannen.
- De objectplannen cacheopslag (OBJCP) wordt gebruikt voor plannen voor persistente objecten (opgeslagen procedures, functies en triggers).
- De SQL-plannen cachestore (SQLCP) die worden gebruikt voor plannen die betrekking hebben op automatisch geparameteriseerde, dynamische of voorbereide query’s.
De onderstaande query bevat informatie over het geheugengebruik voor deze twee cachearchieven:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Notitie
De plancache heeft twee extra opslagruimtes die niet worden gebruikt voor het opslaan van planningen.
- De Bound Trees cacheopslag (PHDR) die wordt gebruikt voor gegevensstructuren die worden gebruikt tijdens het compileren van plannen voor weergaven, beperkingen en standaardinstellingen. Deze structuren staan bekend als Gebonden Bomen of Algebrizer Trees.
- De Extended Stored Procedures cache-opslag (XPROC) wordt gebruikt voor vooraf gedefinieerde systeemprocedures, zoals
sp_executeSqlofxp_cmdshell, die zijn gedefinieerd met een DLL en niet met Transact-SQL instructies. De structuur in de cache bevat alleen de functienaam en de DLL-naam waarin de procedure wordt geïmplementeerd.
SQL Server-uitvoeringsplannen hebben de volgende hoofdonderdelen:
Gecompileerd plan (of queryplan)
Het queryplan dat door het compilatieproces wordt geproduceerd, is meestal een nieuwe, alleen-lezen gegevensstructuur die door een willekeurig aantal gebruikers wordt gebruikt. Er wordt informatie opgeslagen over:Fysieke operators die de bewerking implementeren die wordt beschreven door logische operators.
De volgorde van deze operators, waarmee de volgorde wordt bepaald waarin gegevens worden geopend, gefilterd en geaggregeerd.
Het aantal geschatte gegevensrijen dat door de operatoren wordt verwerkt.
Notitie
In nieuwere versies van de database-engine wordt ook informatie over de statistiekenobjecten die zijn gebruikt voor kardinaliteitschatting opgeslagen.
Welke ondersteuningsobjecten moeten worden gemaakt, zoals werktabellen of werkbestanden in
tempdb. Er worden geen gebruikerscontext- of runtimegegevens opgeslagen in het queryplan. Er zijn nooit meer dan één of twee kopieën van het queryplan in het geheugen: één kopie voor alle seriële uitvoeringen en een andere voor alle parallelle uitvoeringen. De parallelle kopie omvat alle parallelle uitvoeringen, ongeacht de mate van parallelle uitvoering.
uitvoeringscontext
Elke gebruiker die momenteel de query uitvoert, heeft een gegevensstructuur die de gegevens bevat die specifiek zijn voor de uitvoering, zoals parameterwaarden. Deze gegevensstructuur wordt de uitvoeringscontext genoemd. De structuur van de uitvoeringscontextgegevens wordt opnieuw gebruikt, maar de inhoud ervan is dat niet. Als een andere gebruiker dezelfde query uitvoert, worden de gegevensstructuren opnieuw geïnitialiseerd met de context voor de nieuwe gebruiker.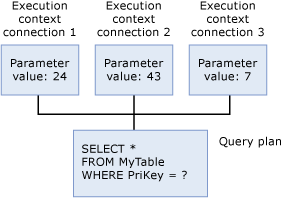
Wanneer een Transact-SQL instructie wordt uitgevoerd in SQL Server, kijkt de database-engine eerst door de plancache om te controleren of er een bestaand uitvoeringsplan voor dezelfde Transact-SQL instructie bestaat. De Transact-SQL-instructie komt in aanmerking als bestaande als deze letterlijk overeenkomt met een eerder uitgevoerde Transact-SQL-instructie met een plan in de cache, teken per teken. SQL Server hergebruikt elk bestaand plan dat wordt gevonden, waardoor de overhead van het opnieuw compileren van de Transact-SQL-instructie wordt bespaard. Als er geen uitvoeringsplan bestaat, genereert SQL Server een nieuw uitvoeringsplan voor de query.
Notitie
De uitvoeringsplannen voor sommige Transact-SQL-instructies worden niet bewaard in de plancache, zoals bulkbewerkingsinstructies die worden uitgevoerd in rowstore of instructies met letterlijke tekenreeksen die groter zijn dan 8 kB. Deze plannen bestaan alleen terwijl de query wordt uitgevoerd.
SQL Server heeft een efficiënt algoritme om eventuele bestaande uitvoeringsplannen voor een specifieke Transact-SQL instructie te vinden. In de meeste systemen zijn de minimale resources die door deze scan worden gebruikt, kleiner dan de resources die worden opgeslagen door bestaande plannen opnieuw te kunnen gebruiken in plaats van elke Transact-SQL instructie te compileren.
De algoritmen die overeenkomen met nieuwe Transact-SQL-instructies voor bestaande, ongebruikte uitvoeringsplannen in de plancache, vereisen dat alle objectverwijzingen volledig zijn gekwalificeerd. Stel dat Person het standaardschema is voor de gebruiker die de onderstaande SELECT instructies uitvoert. Hoewel in dit voorbeeld niet is vereist dat de Person tabel volledig is gekwalificeerd om uit te voeren, betekent dit dat de tweede instructie niet overeenkomt met een bestaand plan, maar dat de derde wordt vergeleken:
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
Het wijzigen van een van de volgende SET-opties voor een bepaalde uitvoering heeft invloed op de mogelijkheid om plannen opnieuw te gebruiken, omdat de database-engine constant vouwen uitvoert en deze opties van invloed zijn op de resultaten van dergelijke expressies:
ANSI_NULL_DFLT_OFF
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
NUMERIC_ROUNDABORT
ANSI_NULL_DFLT_ON
TAAL
CONCAT_NULL_YIELDS_NULL
DATUMNOTATIE
ANSI_WARNINGS
QUOTED_IDENTIFIER
ANSI_NULLS (ANSI-normen voor NULL waarden)
NO_BROWSETABLE
ANSI_DEFAULTS
Meerdere plannen voor dezelfde query in de cache opslaan
Query's en uitvoeringsplannen zijn uniek identificeerbaar in de database-engine, net als een vingerafdruk:
- De hash- van het queryplan is een binaire hash-waarde die wordt berekend in het uitvoeringsplan voor een bepaalde query en wordt gebruikt om vergelijkbare uitvoeringsplannen op unieke wijze te identificeren.
- De query-hash- is een binaire hashwaarde die wordt berekend op de Transact-SQL tekst van een query en wordt gebruikt om query's uniek te identificeren.
Een gecompileerd plan kan worden opgehaald uit de plancache met behulp van een Plan Handle. Dit is een tijdelijke id die alleen constant blijft terwijl het plan in de cache blijft. De plangreep is een hash-waarde die is afgeleid van het gecompileerd plan van de hele batch. De plangreep voor een gecompileerd plan blijft hetzelfde, zelfs als een of meer instructies in de batch opnieuw worden gecompileerd.
Notitie
Als een plan is samengesteld voor een batch in plaats van één instructie, kan het plan voor afzonderlijke instructies in de batch worden opgehaald met behulp van de planreferentie en de instructie-offsets.
De sys.dm_exec_requests DMV bevat de kolommen statement_start_offset en statement_end_offset voor elke record, die verwijzen naar de huidige uitvoeringsinstructie van een batch of persistent object. Zie sys.dm_exec_requests (Transact-SQL)voor meer informatie.
De sys.dm_exec_query_stats DMV bevat ook deze kolommen voor elke record, die verwijzen naar de positie van een instructie in een batch of persistent object. Zie sys.dm_exec_query_stats (Transact-SQL)voor meer informatie.
De specifieke Transact-SQL tekst van een batch wordt opgeslagen in een afzonderlijke geheugenruimte, los van de plancache, genaamd de SQL Manager cache (SQLMGR). De Transact-SQL-tekst voor een gecompileerd plan kan uit de SQL Manager-cache worden opgehaald met behulp van een SQL Handle, een tijdelijke identificator die alleen constant blijft zolang ten minste één plan dat ernaar verwijst in de plancache blijft. De SQL-handle is een hash-waarde die is afgeleid van de volledige batchtekst en is gegarandeerd uniek voor elke batch.
Notitie
Net als bij een gecompileerd plan wordt de Transact-SQL tekst per batch opgeslagen, inclusief de opmerkingen. De SQL-handle bevat de MD5-hash van de volledige batchtekst en is gegarandeerd uniek voor elke batch.
De onderstaande query bevat informatie over het geheugengebruik voor de sql Manager-cache:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
Er is een 1:N-relatie tussen een SQL-handle en plangrepen. Een dergelijke voorwaarde treedt op wanneer de cachesleutel voor de gecompileerde plannen anders is. Dit kan gebeuren als gevolg van wijzigingen in SET-opties tussen twee uitvoeringen van dezelfde batch.
Houd rekening met de volgende SQL opgeslagen procedure:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
Controleer wat u in de plancache kunt vinden met behulp van de onderstaande query:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
Dit is de resultatenset.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Voer nu de opgeslagen procedure uit met een andere parameter, maar geen andere wijzigingen in de uitvoeringscontext:
EXEC usp_SalesByCustomer 8
GO
Controleer nogmaals wat er in de plancache te vinden is. Dit is de resultaatset.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
U ziet dat het usecounts is verhoogd tot 2, wat betekent dat hetzelfde plan in de cache opnieuw is gebruikt as-is, omdat de structuur van de uitvoeringscontextgegevens opnieuw is gebruikt. Wijzig nu de optie SET ANSI_DEFAULTS en voer de opgeslagen procedure uit met dezelfde parameter.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
Controleer nogmaals wat er te vinden is in de plancache. Dit is de resultaatset.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
U ziet nu twee vermeldingen in de sys.dm_exec_cached_plans DMV-uitvoer:
- In de kolom
usecountswordt de waarde1weergegeven in het eerste record, wat het plan is dat eenmaal metSET ANSI_DEFAULTS OFFwordt uitgevoerd. - In de kolom
usecountswordt de waarde weergegeven2in de tweede record. Dit is het plan dat wordt uitgevoerd metSET ANSI_DEFAULTS ON, omdat deze twee keer is uitgevoerd. - De andere
memory_object_addressverwijst naar een andere invoer van het uitvoeringsplan in de plancache. Desql_handlewaarde is echter hetzelfde voor beide vermeldingen, omdat ze verwijzen naar dezelfde batch.- De uitvoering met
ANSI_DEFAULTSingesteld op UIT heeft een nieuweplan_handleen is beschikbaar voor hergebruik voor aanroepen die dezelfde set SET-opties hebben. De nieuwe plangreep is nodig omdat de uitvoeringscontext opnieuw is geïnitialiseerd vanwege gewijzigde SET-opties. Maar dat activeert geen nieuwecompilie: beide vermeldingen verwijzen naar hetzelfde plan en dezelfde query, zoals wordt aangetoond door dezelfdequery_plan_hashenquery_hashwaarden.
- De uitvoering met
Wat dit feitelijk betekent, is dat we twee planvermeldingen in de cache hebben die overeenkomen met dezelfde batch, en het onderstreept het belang ervoor te zorgen dat de plancache, die door SET-opties wordt beïnvloed, gelijk is, wanneer dezelfde query's herhaaldelijk worden uitgevoerd, om plannen hergebruiken te optimaliseren en de grootte van de plancache tot het noodzakelijke minimum te beperken.
Tip
Een veelvoorkomende valkuil is dat verschillende clients verschillende standaardwaarden kunnen hebben voor de SET-opties. Met een verbinding die via SQL Server Management Studio is gemaakt, wordt bijvoorbeeld automatisch QUOTED_IDENTIFIER ingesteld op AAN, terwijl SQLCMD QUOTED_IDENTIFIER instelt op UIT. Het uitvoeren van dezelfde query's van deze twee clients resulteert in meerdere plannen (zoals beschreven in het bovenstaande voorbeeld).
Uitvoeringsplannen verwijderen uit de plancache
Uitvoeringsplannen blijven in de plankaartcache staan zolang er voldoende geheugen is om ze op te slaan. Wanneer er geheugenbelasting bestaat, gebruikt de SQL Server Database Engine een kostengebaseerde benadering om te bepalen welke uitvoeringsplannen moeten worden verwijderd uit de plancache. Als u een kostengebaseerde beslissing wilt nemen, neemt de SQL Server Database Engine een huidige kostenvariabele voor elk uitvoeringsplan toe en verlaagt deze volgens de volgende factoren.
Wanneer een gebruikersproces een uitvoeringsplan in de cache invoegt, stelt het gebruikersproces de huidige kosten in die gelijk zijn aan de oorspronkelijke querycompilatiekosten; voor ad-hoc uitvoeringsplannen stelt het gebruikersproces de huidige kosten in op nul. Telkens wanneer een gebruikersproces verwijst naar een uitvoeringsplan, worden de huidige kosten opnieuw ingesteld op de oorspronkelijke compileerkosten; voor ad-hoc uitvoeringsplannen verhoogt het gebruikersproces de huidige kosten. Voor alle abonnementen is de maximale waarde voor de huidige kosten de oorspronkelijke compileerkosten.
Wanneer er geheugenbelasting bestaat, reageert de SQL Server Database Engine door uitvoeringsplannen uit de plancache te verwijderen. Als u wilt bepalen welke plannen u wilt verwijderen, onderzoekt de SQL Server Database Engine herhaaldelijk de status van elk uitvoeringsplan en verwijdert u plannen wanneer de huidige kosten nul zijn. Een uitvoeringsplan met nul huidige kosten wordt niet automatisch verwijderd wanneer geheugendruk bestaat; deze wordt alleen verwijderd wanneer de SQL Server Database Engine het plan onderzoekt en de huidige kosten nul zijn. Bij het onderzoeken van een uitvoeringsplan pusht de SQL Server Database Engine de huidige kosten naar nul door de huidige kosten te verlagen als een query momenteel geen gebruik maakt van het plan.
De SQL Server Database Engine onderzoekt herhaaldelijk de uitvoeringsplannen totdat er voldoende zijn verwijderd om te voldoen aan de geheugenvereisten. Hoewel er geheugenbelasting bestaat, kunnen de kosten van een uitvoeringsplan toenemen en meer dan één keer afnemen. Wanneer geheugenbelasting niet meer bestaat, stopt de SQL Server Database Engine met het verlagen van de huidige kosten van ongebruikte uitvoeringsplannen en blijven alle uitvoeringsplannen in de plancache staan, zelfs als de kosten nul zijn.
De SQL Server Database Engine gebruikt de resourcemonitor en gebruikerswerkthreads om geheugen vrij te maken van de plancache als reactie op geheugendruk. De resourcemonitor en gebruikerswerkersdraad kunnen plannen gelijktijdig onderzoeken om de huidige kosten van elk ongebruikt uitvoeringsplan te verlagen. De resourcemonitor verwijdert uitvoeringsplannen uit de plancache wanneer er globale geheugenbelasting bestaat. Het maakt geheugen vrij om beleid af te dwingen voor systeemgeheugen, procesgeheugen, resourcegroepgeheugen en maximale grootte voor alle caches.
De maximale grootte voor alle caches is een functie van de grootte van de buffergroep en kan het maximale servergeheugen niet overschrijden. Zie de max server memory-instelling in sp_configurevoor meer informatie over het configureren van het maximale servergeheugen.
De werkdraad van de gebruiker verwijdert uitvoeringsplannen uit de plancache wanneer er sprake is van cachegeheugenbelasting. Ze dwingen beleidsregels af voor maximale grootte van één cache en maximale vermeldingen in één cache.
In de volgende voorbeelden ziet u welke uitvoeringsplannen worden verwijderd uit de plancache:
- Er wordt vaak naar een uitvoeringsplan verwezen, zodat de kosten nooit naar nul gaan. Het plan blijft in de plancache en wordt niet verwijderd, tenzij er geheugendruk is en de huidige kosten nul zijn.
- Er wordt een ad-hocuitvoeringsplan ingevoegd en er wordt niet opnieuw naar verwezen totdat er geheugendruk optreedt. Omdat ad-hocplannen worden geïnitialiseerd met de huidige kosten van nul, zal de SQL Server Database Engine, wanneer het het uitvoeringsplan onderzoekt, de huidige kosten van nul zien en het plan uit de plancache verwijderen. Het ad-hocuitvoeringsplan blijft in de plancache met een huidige kost van nul wanneer er geen geheugendruk bestaat.
Als u handmatig één of alle plannen uit de cache wilt verwijderen, gebruikt u DBCC FREEPROCCACHE-.
DBCC FREESYSTEMCACHE kan ook worden gebruikt om alle caches te wissen, inclusief de plancache. Vanaf SQL Server 2016 (13.x) kunt u de ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE gebruiken om de procedurecache (plan) voor de betreffende database te wissen.
Een wijziging in sommige configuratie-instellingen via sp_configure en reconfigure zorgt er ook voor dat plannen uit de plancache worden verwijderd. U vindt de lijst met deze configuratie-instellingen in de sectie Opmerkingen van het DBCC FREEPROCCACHE artikel. Als u een configuratiewijziging zoals deze wijzigt, wordt het volgende informatieve bericht in het foutenlogboek vastgelegd:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Uitvoeringsplannen opnieuw compileren
Bepaalde wijzigingen in een database kunnen ertoe leiden dat een uitvoeringsplan inefficiënt of ongeldig is, op basis van de nieuwe status van de database. SQL Server detecteert de wijzigingen die een uitvoeringsplan ongeldig maken en markeert het plan als ongeldig. Er moet vervolgens een nieuw plan worden gecompileerd voor de volgende verbinding waarmee de query wordt uitgevoerd. De voorwaarden die een plan ongeldig maken, zijn onder andere:
- Wijzigingen die zijn aangebracht in een tabel of weergave waarnaar wordt verwezen door de query (
ALTER TABLEenALTER VIEW). - Wijzigingen die zijn aangebracht in één procedure, waardoor alle plannen voor die procedure uit de cache (
ALTER PROCEDURE) worden verwijderd. - Wijzigingen in indexen die door het uitvoeringsplan worden gebruikt.
- Updates voor statistieken die door het uitvoeringsplan worden gebruikt, die expliciet zijn gegenereerd op basis van een instructie, zoals
UPDATE STATISTICS, of automatisch worden gegenereerd. - Een index verwijderen die wordt gebruikt door het uitvoeringsplan.
- Een expliciete aanroep van
sp_recompile. - Grote aantallen wijzigingen in sleutels (gegenereerd door
INSERTofDELETEinstructies van andere gebruikers die een tabel wijzigen waarnaar wordt verwezen door de query). - Als het aantal rijen in de ingevoegde of verwijderde tabellen aanzienlijk toeneemt voor tabellen met triggers.
- Een opgeslagen procedure uitvoeren met behulp van de optie
WITH RECOMPILE.
De meeste hercompilaties zijn vereist voor de juistheid van de instructie of voor het verkrijgen van mogelijk snellere uitvoeringsplannen voor query's.
In SQL Server-versies vóór 2005, wanneer een instructie in een batch hercompilatie veroorzaakt, is de hele batch, ongeacht of deze worden verzonden via een opgeslagen procedure, trigger, ad-hocbatch of voorbereide instructie, opnieuw gecompileerd. Vanaf SQL Server 2005 (9.x) wordt alleen de instructie in de batch die recompilatie activeert, opnieuw gecompileerd. Er zijn ook extra typen hercompilaties in SQL Server 2005 (9.x) en hoger vanwege de uitgebreide functieset.
Recompilatie op instructieniveau levert prestaties op omdat in de meeste gevallen een klein aantal instructies hercompilaties en de bijbehorende boetes veroorzaakt, wat betreft CPU-tijd en vergrendelingen. Deze boetes worden daarom vermeden voor de andere verklaringen in de batch die niet opnieuw hoeven te worden gecompileerd.
De sql_statement_recompile uitgebreide gebeurtenis (XEvent) rapporteert hercompilaties op instructieniveau. Deze XEvent vindt plaats wanneer een hercompilatie op instructieniveau vereist is voor elk type batch. Dit omvat opgeslagen procedures, triggers, ad-hoc batches en query's. Batches kunnen worden verzonden via verschillende interfaces, waaronder sp_executesql, dynamische SQL, Prepare-methoden of Execute-methoden.
De kolom recompile_cause van sql_statement_recompile XEvent bevat een geheel getal dat de reden voor de hercompilatie aangeeft. De volgende tabel bevat de mogelijke oorzaken:
Schema gewijzigd
Statistieken gewijzigd
Uitgestelde compilatie
De optie SET is gewijzigd
Tijdelijke tabel is gewijzigd
Externe rijenset is gewijzigd
FOR BROWSE machtiging gewijzigd
Querymeldingsomgeving gewijzigd
De gepartitioneerde weergave is gewijzigd
Cursoropties gewijzigd
OPTION (RECOMPILE) aangevraagd
Geparameteriseerd plan leeggemaakt
Plan dat invloed heeft op de databaseversie gewijzigd
Query Store-plan dat beleid afdwingt gewijzigd
Het afdwingen van een Query Store-plan is mislukt
Query Store mist het plan
Notitie
In SQL Server-versies waar XEvents niet beschikbaar zijn, kan de SQL Server Profiler SP:Recompile traceringsgebeurtenis worden gebruikt voor het melden van hercompilaties op instructieniveau.
De traceringsgebeurtenis SQL:StmtRecompile rapporteert ook hercompilaties op instructieniveau. Deze traceringsgebeurtenis kan ook worden gebruikt voor het bijhouden en opsporen van hercompilaties.
Terwijl SP:Recompile alleen genereert voor opgeslagen procedures en triggers, genereert SQL:StmtRecompile voor opgeslagen procedures, triggers, ad-hoc batches, batches die worden uitgevoerd met behulp van sp_executesql, voorbereide query's en dynamische SQL.
De kolom EventSubClass van SP:Recompile en SQL:StmtRecompile bevat een geheel getal dat de reden voor de hercompilatie aangeeft. De codes worden hier beschreven.
Notitie
Wanneer de AUTO_UPDATE_STATISTICS databaseoptie is ingesteld op ON, worden query's opnieuw gecompileerd wanneer ze gericht zijn op tabellen of geïndexeerde weergaven waarvan de statistieken zijn bijgewerkt of waarvan de kardinaliteit aanzienlijk is gewijzigd sinds de laatste uitvoering.
Dit gedrag is van toepassing op standaard door de gebruiker gedefinieerde tabellen, tijdelijke tabellen en de ingevoegde en verwijderde tabellen die zijn gemaakt door DML-triggers. Als de queryprestaties worden beïnvloed door overmatige hercompilaties, kunt u overwegen deze instelling te wijzigen in OFF. Wanneer de optie AUTO_UPDATE_STATISTICS database is ingesteld op OFF, worden er geen hercompilaties uitgevoerd op basis van statistieken of kardinaliteitswijzigingen, met uitzondering van de ingevoegde en verwijderde tabellen die zijn gemaakt door DML-INSTEAD OF-triggers. Omdat deze tabellen worden gemaakt in tempdb, is de hercompilatie van query's die er toegang toe hebben, afhankelijk van de instelling van AUTO_UPDATE_STATISTICS in tempdb.
In SQL Server vóór 2005 blijven query's opnieuw compileren op basis van kardinaliteitswijzigingen in de DML-trigger ingevoegde en verwijderde tabellen, zelfs wanneer deze instelling is OFF.
Parameters en het hergebruik van het uitvoeringsplan
Het gebruik van parameters, waaronder parametermarkeringen in ADO-, OLE DB- en ODBC-toepassingen, kan het hergebruik van uitvoeringsplannen verhogen.
Waarschuwing
Het gebruik van parameters of parametermarkeringen voor het opslaan van waarden die door eindgebruikers worden getypt, is veiliger dan het samenvoegen van de waarden in een tekenreeks die vervolgens wordt uitgevoerd met behulp van een API-methode voor gegevenstoegang, de EXECUTE-instructie of de sp_executesql opgeslagen procedure.
Het enige verschil tussen de volgende twee SELECT-instructies is de waarden die in de WHERE-voorwaarde worden vergeleken.
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Het enige verschil tussen de uitvoeringsplannen voor deze query's is de waarde die is opgeslagen voor de vergelijking met de kolom ProductSubcategoryID. Hoewel het doel is dat SQL Server altijd herkent dat de instructies in wezen hetzelfde plan genereren en de plannen opnieuw gebruiken, detecteert SQL Server dit soms niet in complexe Transact-SQL instructies.
Door constanten van de Transact-SQL instructie te scheiden met behulp van parameters kan de relationele engine dubbele plannen herkennen. U kunt parameters op de volgende manieren gebruiken:
Gebruik in Transact-SQL
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmDeze methode wordt aanbevolen voor Transact-SQL scripts, opgeslagen procedures of triggers die dynamisch SQL-instructies genereren.
ADO, OLE DB en ODBC gebruiken parametermarkeringen. Parametermarkeringen zijn vraagtekens (?) die een constante in een SQL-instructie vervangen en zijn gebonden aan een programmavariabele. U doet bijvoorbeeld het volgende in een ODBC-toepassing:
Gebruik
SQLBindParameterom een geheel getalvariabele te binden aan de eerste parametermarkering in een SQL-instructie.Plaats de waarde van het gehele getal in de variabele.
Voer de instructie uit, waarbij u de parametermarkering (?) opgeeft:
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
De SQL Server Native Client OLE DB-provider en de SQL Server Native Client ODBC-stuurprogramma die is opgenomen in SQL Server, gebruiken
sp_executesqlom statements naar SQL Server te verzenden wanneer er parametermarkeringen in toepassingen worden gebruikt.Opgeslagen procedures ontwerpen, die standaard parameters gebruiken.
Als u niet expliciet parameters in het ontwerp van uw toepassingen inbouwt, kunt u ook vertrouwen op sql Server Query Optimizer om automatisch bepaalde query's te parameteriseren met behulp van het standaardgedrag van eenvoudige parameterisatie. U kunt ook afdwingen dat Query Optimizer alle query's in de database parameteriseren door de optie PARAMETERIZATION van de instructie ALTER DATABASE in te stellen op FORCED.
Wanneer geforceerde parameterisatie is ingeschakeld, kan eenvoudige parameterisatie nog steeds plaatsvinden. De volgende query kan bijvoorbeeld niet worden geparameteriseerd volgens de regels voor geforceerde parameters:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
Het kan echter worden geparameteriseerd volgens eenvoudige parameterisatieregels. Wanneer geforceerde parameterisatie wordt geprobeerd, maar mislukt, wordt eenvoudige parameterisatie nog steeds geprobeerd.
Eenvoudige parameterisatie
In SQL Server verhoogt het gebruik van parameters of parametermarkeringen in Transact-SQL-instructies het vermogen van de relationele engine om nieuwe Transact-SQL-instructies af te stemmen met bestaande, eerder gecompileerde uitvoeringsplannen.
Waarschuwing
Het gebruik van parameters of parametermarkeringen voor het opslaan van waarden die door eindgebruikers zijn getypt, is veiliger dan het samenvoegen van de waarden in een tekenreeks die vervolgens wordt uitgevoerd met behulp van een API-methode voor gegevenstoegang, de EXECUTE-instructie of de sp_executesql opgeslagen procedure.
Als een Transact-SQL instructie zonder parameters wordt uitgevoerd, parameteriseert SQL Server de instructie intern om de mogelijkheid te vergroten om deze te vergelijken met een bestaand uitvoeringsplan. Dit proces wordt eenvoudige parameterisatie genoemd. In SQL Server-versies vóór 2005 werd het proces automatisch parameterisatie genoemd.
Houd rekening met deze instructie:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
De waarde 1 aan het einde van de instructie kan worden opgegeven als parameter. De relationele engine bouwt het uitvoeringsplan voor deze batch alsof er een parameter is opgegeven in plaats van de waarde 1. Vanwege deze eenvoudige parameterisatie herkent SQL Server dat de volgende twee instructies in wezen hetzelfde uitvoeringsplan genereren en het eerste plan voor de tweede instructie opnieuw gebruiken:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Bij het verwerken van complexe Transact-SQL instructies kan de relationele engine moeite hebben om te bepalen welke expressies kunnen worden geparameteriseerd. Als u de mogelijkheid van de relationele engine wilt vergroten om complexe Transact-SQL instructies te koppelen aan bestaande, ongebruikte uitvoeringsplannen, geeft u expliciet de parameters op met behulp van sp_executesql of parametermarkeringen.
Notitie
Wanneer de +, -, *, /of % rekenkundige operatoren worden gebruikt om impliciete of expliciete conversie van int-, smallint-, tinyint- of bigint-constantewaarden uit te voeren op de float-, reële, decimale of numerieke gegevenstypen, past SQL Server specifieke regels toe om het type en de precisie van de expressieresultaten te berekenen. Deze regels verschillen echter, afhankelijk van of de query al dan niet wordt geparameteriseerd. Daarom kunnen vergelijkbare expressies in query's in sommige gevallen verschillende resultaten opleveren.
Onder het standaardgedrag van eenvoudige parameterisatie wordt met SQL Server een relatief kleine klasse query's geparameteraliseerd. U kunt echter opgeven dat alle query's in een database worden geparameteriseerd, afhankelijk van bepaalde beperkingen, door de optie PARAMETERIZATION van de opdracht ALTER DATABASE in te stellen op FORCED. Dit kan de prestaties verbeteren van databases die te maken hebben met grote hoeveelheden gelijktijdige query's door de frequentie van querycompilaties te verminderen.
U kunt ook opgeven dat één query en alle andere query's die syntactisch gelijkwaardig zijn, maar alleen verschillen in de parameterwaarden, worden geparameteriseerd.
Tip
Wanneer u een Object-Relational Toewijzingsoplossing (ORM) gebruikt, zoals Entity Framework (EF), worden toepassingsquery's zoals handmatige LINQ-querystructuren of bepaalde onbewerkte SQL-query's mogelijk niet geparameteriseerd, wat van invloed is op het opnieuw gebruiken van plannen en de mogelijkheid om query's in de Query Store bij te houden. Zie voor meer informatie EF Query-caching en parameterisering en EF Raw SQL-query's.
Geforceerde parameterisatie
U kunt het standaardgedrag voor eenvoudige parameters van SQL Server overschrijven door op te geven dat alle SELECT, INSERT, UPDATEen DELETE instructies in een database worden geparameteriseerd, afhankelijk van bepaalde beperkingen. Geforceerde parameterisatie wordt ingeschakeld door de optie PARAMETERIZATION in te stellen op FORCED in de instructie ALTER DATABASE. Geforceerde parameterisatie kan de prestaties van bepaalde databases verbeteren door de frequentie van querycompilaties en hercompilaties te verminderen. Databases die kunnen profiteren van geforceerde parameterisatie zijn over het algemeen databases die te maken hebben met grote hoeveelheden gelijktijdige query's van bronnen zoals point-of-sale-toepassingen.
Wanneer de optie PARAMETERIZATION is ingesteld op FORCED, wordt elke letterlijke waarde die wordt weergegeven in een SELECT, INSERT, UPDATEof DELETE instructie, die in een willekeurige vorm is ingediend, geconverteerd naar een parameter tijdens het compileren van query's. De uitzonderingen zijn letterlijke waarden die worden weergegeven in de volgende queryconstructies:
-
INSERT...EXECUTEverklaringen. - Instructies in de inhoud van opgeslagen procedures, triggers of door de gebruiker gedefinieerde functies. SQL Server gebruikt al queryplannen voor deze routines.
- Voorbereide instructies die al zijn geparameteriseerd in de toepassing aan de clientzijde.
- Instructies die XQuery-methodeaanroepen bevatten, waarbij de methode wordt weergegeven in een context waarin de argumenten doorgaans worden geparameteriseerd, zoals een
WHERE-component. Als de methode wordt weergegeven in een context waarin de argumenten niet worden geparameteriseerd, wordt de rest van de instructie geparameteriseerd. - Verklaringen in een Transact-SQL cursor. (
SELECTinstructies in API-cursors worden met parameters ingesteld.) - Verouderde queryconstructies.
- Elke instructie die wordt uitgevoerd in de context van
ANSI_PADDINGofANSI_NULLSingesteld opOFF. - Instructies die meer dan 2097 letterlijke waarden bevatten die in aanmerking komen voor parameterisatie.
- Verklaringen die verwijzen naar variabelen, zoals
WHERE T.col2 >= @bb. - Uitspraken die de
RECOMPILEquery hint bevatten. - Verklaringen die een
COMPUTE-clausule bevatten. - Uitspraken die een
WHERE CURRENT OF-clausule bevatten.
Daarnaast worden de volgende querycomponenten niet geparameteriseerd. In deze gevallen worden alleen de clausules niet geparameteriseerd. Andere componenten binnen dezelfde query kunnen in aanmerking komen voor geforceerde parameterisatie.
- De <select_list> van een
SELECTverklaring. Dit omvatSELECTlijsten met subquery's enSELECTlijsten inINSERTinstructies. - Subquery
SELECTinstructies die in eenIF-instructie worden weergegeven. - De
TOP,TABLESAMPLE,HAVING,GROUP BY,ORDER BY,OUTPUT...INTOofwelFOR XMLclausules van een query. - Argumenten, direct of als subexpressies, naar
OPENROWSET,OPENQUERY,OPENDATASOURCE,OPENXML, of eenFULLTEXT-operator. - Het patroon en escape-teken argumenten van een
LIKE-clausule. - Het stijlargument van een
CONVERT-clausule. - Constanten binnen een
IDENTITY-clausule. - Constanten die zijn opgegeven met behulp van de syntaxis van de ODBC-extensie.
- Constant vouwbare expressies die argumenten zijn van de operatoren
+,-,*,/en%. Bij het overwegen van geschiktheid voor geforceerde parameterisatie beschouwt SQL Server een expressie als constant-vouwbaar wanneer aan een van de volgende voorwaarden wordt voldaan:- Er worden geen kolommen, variabelen of subquery's weergegeven in de expressie.
- De expressie bevat een
CASE-clausule.
- Argumenten voor het opvragen van hintclausules. Deze omvatten het number_of_rows argument van de
FASTqueryhint, het number_of_processors argument van deMAXDOPqueryhint en het aantal argument van deMAXRECURSIONqueryhint.
Parameterisatie vindt plaats op het niveau van afzonderlijke Transact-SQL instructies. Met andere woorden, afzonderlijke instructies in een batch worden geparameteriseerd. Na het compileren wordt een geparameteriseerde query uitgevoerd in de context van de batch waarin deze oorspronkelijk is verzonden. Als een uitvoeringsplan voor een query in de cache is opgeslagen, kunt u bepalen of de query is geparameteriseerd door te verwijzen naar de SQL-kolom van de sys.syscacheobjects dynamische beheerweergave. Als een query wordt geparameteriseerd, komen de namen en gegevenstypen van parameters vóór de tekst van de ingediende batch in deze kolom, zoals (@1 tinyint).
Notitie
Parameternamen zijn willekeurig. Gebruikers of toepassingen mogen niet afhankelijk zijn van een bepaalde naamgevingsvolgorde. Het volgende kan ook veranderen tussen versies van SQL Server en Service Pack-upgrades: parameternamen, de keuze van letterlijke waarden die worden geparameteriseerd en de afstand in de geparameteriseerde tekst.
Gegevenstypen van parameters
Wanneer SQL Server literalwaarden omzet, worden de parameters omgezet naar de volgende gegevenstypen:
- Letterlijke waarden voor gehele getallen waarvan de grootte anders binnen het gegevenstype int past, worden int geparameteraliseerd. Grotere letterlijke waarden voor gehele getallen die deel uitmaken van predicaten die een vergelijkingsoperator omvatten (inclusief
<,<=,=,!=,>,>=,!<,!>,<>,ALL,ANY,SOME,BETWEENenIN) parameteriseren naar numeriek(38,0). Grotere letterlijke waarden die geen onderdelen van predicaten zijn waarbij vergelijkingsoperators parameteriseren naar numeriek waarvan de precisie net groot genoeg is om de grootte te ondersteunen en waarvan de schaal 0 is. - Letterlijke numerieke waarden met vaste punten die delen van predicaten zijn waarbij vergelijkingsoperators parameteriseren naar numeriek waarvan de precisie 38 is en waarvan de schaal net groot genoeg is om de grootte te ondersteunen. Numerieke letterlijke waarden met vaste punten die geen onderdeel zijn van predikaten waarbij vergelijkingsoperatoren betrokken zijn, worden geparameteriseerd naar numeriek, waarvan de precisie en schaal net groot genoeg zijn om hun omvang te ondersteunen.
- Numerieke floating-point nummers worden geparameteriseerd naar float(53).
- Letterlijke waarden voor niet-Unicode-tekenreeksen worden geparameteraliseerd naar varchar(8000) als de letterlijke waarde binnen 8000 tekens past en op varchar(max) als deze groter is dan 8000 tekens.
- Letterlijke waarden voor Unicode-tekenreeksen worden geparameteraliseerd naar nvarchar(4000) als de letterlijke waarde binnen 4000 Unicode-tekens past en op nvarchar(max) als de letterlijke waarde groter is dan 4000 tekens.
- Binaire letterlijke waarden parameteriseren in varbinary(8000) als de letterlijke waarde binnen 8000 bytes past. Als deze groter is dan 8000 bytes, wordt deze geconverteerd naar varbinary(max).
- Geldtype-literals worden geparameteriseerd tot geld.
Richtlijnen voor het gebruik van geforceerde parameters
Houd rekening met het volgende wanneer u de optie PARAMETERIZATION instelt op GEFORCEERD:
- Geforceerde parameterisatie wijzigt de letterlijke constanten in een query in parameters bij het compileren van een query. Daarom kan de Query Optimizer suboptimale plannen voor query's kiezen. Met name de Query Optimizer is minder geneigd de query te koppelen aan een geïndexeerde weergave of een index op een berekende kolom. Het kan ook suboptimale plannen kiezen voor query's die zijn geplaatst op gepartitioneerde tabellen en gedistribueerde gepartitioneerde weergaven. Geforceerde parameterisatie mag niet worden gebruikt voor omgevingen die sterk afhankelijk zijn van geïndexeerde weergaven en indexen op berekende kolommen. Over het algemeen mag de optie
PARAMETERIZATION FORCEDalleen worden gebruikt door ervaren databasebeheerders nadat is vastgesteld dat dit geen negatieve invloed heeft op de prestaties. - Gedistribueerde query's die verwijzen naar meer dan één database komen in aanmerking voor geforceerde parameterisatie, zolang de optie
PARAMETERIZATIONis ingesteld opFORCEDin de database waarvan de context van de query wordt uitgevoerd. - Als u de
PARAMETERIZATION-optie instelt opFORCED, spoelt dit alle queryplannen uit de plancache van een database door, behalve die plannen die momenteel worden gecompileerd, opnieuw worden gecompileerd of worden uitgevoerd. Plannen voor query's die worden samengesteld of uitgevoerd tijdens de wijziging van de instelling, worden geparameteriseerd wanneer de query de volgende keer wordt uitgevoerd. - Het instellen van de optie
PARAMETERIZATIONis een onlinebewerking waarvoor geen exclusieve vergrendelingen op databaseniveau zijn vereist. - De huidige instelling van de optie
PARAMETERIZATIONblijft behouden bij het opnieuw verbinden of herstellen van een database.
U kunt het gedrag van geforceerde parameterisatie overschrijven door op te geven dat eenvoudige parameterisatie wordt uitgevoerd op één query, en alle andere parameters die syntactisch gelijkwaardig zijn, maar alleen verschillen in hun parameterwaarden. U kunt daarentegen opgeven dat geforceerde parameterisatie wordt uitgevoerd op slechts een set syntactisch equivalente query's, zelfs als geforceerde parameterisatie is uitgeschakeld in de database. Plangidsen worden hiervoor gebruikt.
Notitie
Wanneer de optie PARAMETERIZATION is ingesteld op FORCED, kan het rapporteren van foutberichten verschillen van wanneer de optie PARAMETERIZATION is ingesteld op SIMPLE: er kunnen meerdere foutberichten worden gerapporteerd onder geforceerde parameterisatie, waarbij minder berichten worden gerapporteerd onder eenvoudige parameterisatie en de regelnummers waarin fouten optreden, onjuist kunnen worden gerapporteerd.
SQL-instructies voorbereiden
De relationele SQL Server-engine introduceert volledige ondersteuning voor het voorbereiden van Transact-SQL instructies voordat ze worden uitgevoerd. Als een toepassing meerdere keren een Transact-SQL-instructie moet uitvoeren, kan deze de database-API gebruiken om het volgende te doen:
- Bereid de verklaring één keer voor. Hiermee wordt de Transact-SQL instructie gecompileerd in een uitvoeringsplan.
- Voer het vooraf gecompileerde uitvoeringsplan uit telkens wanneer deze de instructie moet uitvoeren. Dit voorkomt dat u de Transact-SQL instructie na de eerste keer opnieuw moet compileren voor elke uitvoering. Het voorbereiden en uitvoeren van instructies wordt beheerd door API-functies en -methoden. Het maakt geen deel uit van de Transact-SQL taal. Het voorbereidings-/uitvoermodel voor het uitvoeren van Transact-SQL instructies wordt ondersteund door de SQL Server Native Client OLE DB-provider en het ODBC-stuurprogramma van de SQL Server Native Client. Bij een voorbereidingsaanvraag verzendt de provider of het stuurprogramma de instructie naar SQL Server met een aanvraag om de instructie voor te bereiden. SQL Server compileert een uitvoeringsplan en retourneert een ingang voor dat plan naar de provider of het stuurprogramma. Bij een uitvoeringsaanvraag verzendt de provider of het stuurprogramma de server een aanvraag om het plan uit te voeren dat aan de ingang is gekoppeld.
Voorbereide instructies kunnen niet worden gebruikt voor het maken van tijdelijke objecten op SQL Server. Voorbereide instructies kunnen niet verwijzen naar door het systeem opgeslagen procedures die tijdelijke objecten maken, zoals tijdelijke tabellen. Deze procedures moeten rechtstreeks worden uitgevoerd.
Overtollig gebruik van het voorbereidings-/uitvoermodel kan de prestaties verminderen. Als een instructie slechts eenmaal wordt uitgevoerd, vereist een directe uitvoering slechts één retour van het netwerk naar de server. Het voorbereiden en uitvoeren van een Transact-SQL-instructie die slechts één keer wordt uitgevoerd, vereist een extra netwerkronde; één ronde om de instructie voor te bereiden en één ronde om deze uit te voeren.
Het opstellen van een verklaring is effectiever als er gebruik wordt gemaakt van parametermarkeringen. Stel dat een toepassing af en toe wordt gevraagd productgegevens op te halen uit de AdventureWorks voorbeelddatabase. Er zijn twee manieren waarop de toepassing dit kan doen.
Met behulp van de eerste manier kan de toepassing een afzonderlijke query uitvoeren voor elk aangevraagd product:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
Met behulp van de tweede manier doet de toepassing het volgende:
Hiervoor bereidt men een verklaring voor die een parametermarkering (?) bevat.
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;Hiermee wordt een programmavariabele gebonden aan de parametermarkering.
Telkens wanneer productgegevens nodig zijn, vult u de afhankelijke variabele met de sleutelwaarde en voert u de instructie uit.
De tweede manier is efficiënter wanneer de instructie meer dan drie keer wordt uitgevoerd.
In SQL Server heeft het voorbereidings-/uitvoeringsmodel geen aanzienlijk prestatievoordeel ten opzichte van directe uitvoering, vanwege de manier waarop SQL Server uitvoeringsplannen hergebruikt. SQL Server heeft efficiënte algoritmen voor het vergelijken van de huidige Transact-SQL-instructies met uitvoeringsplannen die worden gegenereerd voor eerdere uitvoeringen van dezelfde Transact-SQL-instructie. Als een toepassing meerdere keren een Transact-SQL-instructie met parametermarkeringen uitvoert, gebruikt SQL Server het uitvoeringsplan opnieuw vanaf de eerste uitvoering voor de tweede en volgende uitvoeringen (tenzij het plan ouder is dan de plancache). Het prepare/execute-model heeft nog steeds de volgende voordelen:
- Het vinden van een uitvoeringsplan door een identificatiehandle is efficiënter ten opzichte van de algoritmen die worden gebruikt om een Transact-SQL-verklaring aan bestaande uitvoeringsplannen te koppelen.
- De toepassing kan bepalen wanneer het uitvoeringsplan wordt gemaakt en wanneer het opnieuw wordt gebruikt.
- Het prepare/execute-model is overdraagbaar naar andere databases, waaronder eerdere versies van SQL Server.
Parametergevoeligheid
Parametergevoeligheid, ook wel 'parameter sniffing' genoemd, verwijst naar een proces waarbij SQL Server tijdens de compilatie of hercompilatie de huidige parameterwaarden onderzoekt en deze overhandigt aan de Query Optimizer, zodat ze kunnen worden gebruikt om potentieel efficiëntere query-uitvoeringsplannen te genereren.
Parameterwaarden worden gelezen tijdens de compilatie of hercompilatie voor de volgende typen batches:
- Opgeslagen procedures
- Queries die worden ingediend via
sp_executesql - Voorbereide queries
Zie voor meer informatie over het oplossen van problemen met incorrecte parametersniffing:
- parametergevoelige problemen onderzoeken en oplossen
- parameters en het uitvoeringsplan opnieuw gebruiken
- optimalisatie van parametergevoelig plan
- Het oplossen van problemen met parametergevoelige query-uitvoeringsplannen in Azure SQL Database
- Problemen met parametergevoelige query-uitvoeringsplan oplossen in Azure SQL Managed Instance
Notitie
Voor query's die gebruikmaken van de RECOMPILE hint, worden zowel parameterwaarden als huidige waarden van lokale variabelen aan het licht gebracht. De waarden die worden afgesnuffeld (van parameters en lokale variabelen) zijn die waarden die zich in de batch bevinden net vóór de instructie met de RECOMPILE hint. Met name voor parameters worden de waarden die samen met de batchaanroep zijn meegekomen, niet opgenomen.
Parallelle queryverwerking
SQL Server biedt parallelle query's voor het optimaliseren van query-uitvoering en indexbewerkingen voor computers met meer dan één microprocessor (CPU). Omdat SQL Server een query- of indexbewerking parallel kan uitvoeren met behulp van verschillende werkthreads van het besturingssysteem, kan de bewerking snel en efficiënt worden voltooid.
Tijdens queryoptimalisatie zoekt SQL Server naar query's of indexbewerkingen die kunnen profiteren van parallelle uitvoering. Voor deze query's voegt SQL Server exchange-operators in het queryuitvoeringsplan in om de query voor te bereiden op parallelle uitvoering. Een exchange-operator is een operator in een queryuitvoeringsplan dat procesbeheer, herdistributie van gegevens en stroombeheer biedt. De exchange-operator bevat de Distribute Streams, Repartition Streamsen Gather Streams logische operatoren als subtypen, waarvan een of meer kunnen worden weergegeven in de Showplan-uitvoer van een queryplan voor een parallelle query.
Belangrijk
Bepaalde constructies remmen het vermogen van SQL Server om parallellisme te gebruiken voor het volledige uitvoeringsplan, of onderdelen of het uitvoeringsplan.
Constructies die parallellisme remmen, zijn onder andere:
Scalaire UDFs
Zie Door de gebruiker gedefinieerde functies makenvoor meer informatie over scalaire door de gebruiker gedefinieerde functies. Vanaf SQL Server 2019 (15.x) heeft de SQL Server Database Engine de mogelijkheid om deze functies inline te zetten en het gebruik van parallelle uitvoering tijdens het verwerken van query's te ontgrendelen. Zie Intelligente queryverwerking in SQL-databasesvoor meer informatie over scalaire UDF-inlining.Externe Query
Voor meer informatie over remote query's, zie Showplan Logical and Physical Operators Reference.dynamische cursors
Voor meer informatie over cursors, zie DECLARE CURSOR.recursieve queries
Zie Richtlijnen voor het definiëren en gebruiken van recursieve algemene tabelexpressies en Recursie in T-SQLvoor meer informatie over recursie.Multi-statement tabelwaardefuncties (MSTVF's)
Voor meer informatie over MSTVF's, zie Door de gebruiker gedefinieerde functies (Database Engine) maken.TOP-trefwoord
Zie TOP (Transact-SQL)voor meer informatie.
Een queryuitvoeringsplan kan het kenmerk NonParallelPlanReason bevatten in het element QueryPlan, waarin wordt beschreven waarom parallellisme niet is gebruikt. Waarden voor dit kenmerk zijn:
| NonParallelPlanReden-waarde | Beschrijving |
|---|---|
| MaxDOP ingesteld op één | Maximale mate van parallelle uitvoering ingesteld op 1. |
| Geschatte DOP Is Eén | Geschatte mate van parallelle uitvoering is 1. |
| NoParallelWithRemoteQuery | Parallellisme wordt niet ondersteund voor externe query's. |
| NoParallelDynamicCursor | Parallelle plannen worden niet ondersteund voor dynamische cursors. |
| NoParallelFastForwardCursor | Parallelle plannen worden niet ondersteund voor snelle cursors. |
| Geen Parallelle Cursoropvraag op Bladwijzer | Parallelle plannen worden niet ondersteund voor cursors die via bladwijzer worden opgehaald. |
| GeenParallelIndexMakenInNietEnterpriseEditie | Het maken van parallelle indexen wordt niet ondersteund voor een niet-Enterprise-editie. |
| GeenParallelePlannenInDesktopOfExpressEditie | Parallel plannen worden niet ondersteund voor Desktop- en Express-editie. |
| NonParallelizableIntrinsicFunction | Query verwijst naar een niet-parallelle, intrinsieke functie. |
| CLR-gebruikersgedefinieerde functie vereist gegevensaccess | Parallellisme wordt niet ondersteund voor een CLR UDF waarvoor gegevenstoegang is vereist. |
| TSQLGebruikersgedefinieerdefunctiesNietParalleliseerbaar | Query verwijst naar een door de gebruiker gedefinieerde T-SQL-functie die niet parallelliseerbaar was. |
| Tabellenvariabelentransacties ondersteunen geen parallel geneste transactie | Transacties met tabelvariabelen bieden geen ondersteuning voor parallelle geneste transacties. |
| DMLQueryGeeftUitvoeraanClient | De DML-query retourneert uitvoer naar de client en kan niet parallell worden uitgevoerd. |
| Gemengde Seriële En Parallelle Online Indexbouw Niet Ondersteund | Niet-ondersteunde combinatie van seriële en parallelle plannen voor één online indexopbouw. |
| KanGeenGeldigParallelPlanGenereren | Verificatie van het parallelle plan mislukt, teruggeschakeld naar serieel. |
| If it requires translation: GeenParallelVoorGeoptimaliseerdeGeheugentabellen | Parallellisme wordt niet ondersteund voor de In-Memory OLTP-tabellen waarnaar wordt verwezen. |
| Geen Parallelle Bewerking op Geheugen-geoptimaliseerde Tabel | Parallellisme wordt niet ondersteund voor DML op een In-Memory OLTP-tabel. |
| NoParallelVoorInEigenTaalGecompileerdeModule | Parallellisme wordt niet ondersteund voor systeemeigen gecompileerde modules waarnaar wordt verwezen. |
| NoRangesResumableCreate | Het genereren van het operationele bereik is mislukt voor een hervatbare maakbewerking. |
Nadat exchange-operators zijn ingevoegd, is het resultaat een uitvoeringsplan voor parallelle query's. Een parallelle-queryuitvoeringsplan kan meer dan één worker thread gebruiken. Een serieel uitvoeringsplan, dat wordt gebruikt door een niet-parallelle (seriële) query, gebruikt slechts één werkrolthread voor de uitvoering ervan. Het werkelijke aantal worker threads dat door een parallelle query wordt gebruikt, wordt bepaald tijdens de initialisatie van de uitvoering van het queryplan en wordt bepaald door de complexiteit van het plan en de mate van parallelisme.
Graad van parallellisme (DOP) bepaalt het maximum aantal CPU's dat wordt gebruikt; dit betekent niet het aantal worker threads dat wordt gebruikt. De DOP-limiet wordt ingesteld per taak. Het is niet per aanvraag of per query limiet. Dit betekent dat tijdens een parallelle uitvoering van een query één aanvraag meerdere taken kan uitvoeren die zijn toegewezen aan een scheduler-. Meer processors dan opgegeven door de MAXDOP kunnen gelijktijdig worden gebruikt op een bepaald moment van de uitvoering van query's wanneer verschillende taken gelijktijdig worden uitgevoerd. Voor meer informatie, zie de handleiding voor thread- en taakarchitectuur .
De SQL Server Query Optimizer maakt geen gebruik van een parallel uitvoeringsplan voor een query als aan een van de volgende voorwaarden wordt voldaan:
- Het seriële uitvoeringsplan is triviaal of overschrijdt niet de kostendrempel voor parallelle uitvoering.
- Het seriële uitvoeringsplan heeft een lagere totale geschatte substructuurkosten dan elk parallel uitvoeringsplan dat door de optimizer is verkend.
- De query bevat scalaire of relationele operators die niet parallel kunnen worden uitgevoerd. Bepaalde operators kunnen ertoe leiden dat een sectie van het queryplan in seriële modus wordt uitgevoerd of dat het hele plan in seriële modus wordt uitgevoerd.
Notitie
De totale geschatte substructuurkosten van een parallel plan kunnen lager zijn dan de drempelwaarde voor parallelle uitvoering. Dit geeft aan dat de totale geschatte substructuurkosten van het seriële plan deze hebben overschreden en dat het queryplan met de lagere geschatte substructuurkosten is gekozen.
Mate van parallelisme (DOP)
SQL Server detecteert automatisch de beste mate van parallelle uitvoering voor elk exemplaar van een DDL-bewerking (Parallel Query Execution of Index Data Definition Language). Dit gebeurt op basis van de volgende criteria:
Of SQL Server wordt uitgevoerd op een computer met meer dan één microprocessor of CPU-, zoals een symmetrische multiprocessingcomputer (SMP). Alleen computers met meer dan één CPU kunnen parallelle query's gebruiken.
Of voldoende werkrolthreads beschikbaar zijn. Voor elke query- of indexbewerking is een bepaald aantal worker threads nodig om uit te voeren. Voor het uitvoeren van een parallel plan zijn meer werkthreads nodig dan een serieel plan, en het aantal vereiste werkthreads neemt toe met de mate van parallelle uitvoering. Wanneer niet kan worden voldaan aan de vereiste voor worker threads van het parallelle plan voor een specifieke mate van parallellisme, verlaagt de SQL Server Database Engine automatisch de mate van parallellisme of laat het parallelle plan volledig los binnen de opgegeven workloadcontext. Vervolgens wordt het seriële plan (één werkthread) uitgevoerd.
Het -type query- of indexbewerking werd uitgevoerd. Indexbewerkingen die een index maken of herbouwen, of een geclusterde index verwijderen en query's die cpu-cycli gebruiken, zijn de beste kandidaten voor een parallel plan. Samenvoegingen van grote tabellen, grote aggregaties en sortering van grote resultatensets zijn bijvoorbeeld goede kandidaten. Eenvoudige query's, vaak gevonden in toepassingen voor transactieverwerking, vinden de aanvullende coördinatie die nodig is om een query parallel uit te voeren, wegen op tegen de mogelijke prestatieverbeteringen. Om onderscheid te maken tussen query's die profiteren van parallelle uitvoering en query's die geen voordeel hebben, vergelijkt de SQL Server Database Engine de geschatte kosten voor het uitvoeren van de query- of indexbewerking met de kostendrempel voor parallellisme waarde. Gebruikers kunnen de standaardwaarde van 5 wijzigen met behulp van sp_configure als de juiste tests hebben vastgesteld dat een andere waarde beter geschikt is voor de actieve workload.
Of er voldoende rijen zijn omte verwerken. Als de queryoptimalisatie bepaalt dat het aantal rijen te laag is, worden exchange-operators niet geïntroduceerd om de rijen te distribueren. De operatoren worden dus serieel uitgevoerd. Het uitvoeren van de operators in een serieel plan voorkomt scenario's wanneer de opstart-, distributie- en coördinatiekosten de winsten overschrijden die worden bereikt door parallelle uitvoering van operatoren.
Of huidige distributiestatistieken beschikbaar zijn. Als de hoogste mate van parallelle uitvoering niet mogelijk is, worden lagere graden overwogen voordat het parallelle plan wordt verlaten. Wanneer u bijvoorbeeld een geclusterde index in een weergave maakt, kunnen distributiestatistieken niet worden geëvalueerd, omdat de geclusterde index nog niet bestaat. In dit geval kan de SQL Server Database Engine niet de hoogste mate van parallelle uitvoering bieden voor de indexbewerking. Sommige operators, zoals sorteren en scannen, kunnen echter nog steeds profiteren van parallelle uitvoering.
Notitie
Parallelle indexbewerkingen zijn alleen beschikbaar in sql Server Enterprise-, Developer- en Evaluation-edities.
Tijdens de uitvoering bepaalt de SQL Server Database Engine of de huidige systeemworkload en configuratiegegevens die eerder zijn beschreven, parallelle uitvoering mogelijk maken. Als parallel uitvoering gerechtvaardigd is, bepaalt de SQL Server Database Engine het optimale aantal werkthreads en verspreidt de uitvoering van het parallelle plan over deze werkthreads. Wanneer een query- of indexbewerking wordt uitgevoerd op meerdere werkthreads voor parallelle uitvoering, wordt hetzelfde aantal werkthreads gebruikt totdat de bewerking is voltooid. De SQL Server Database Engine heroverweegt het optimale aantal worker thread beslissingen telkens wanneer een uitvoeringsplan wordt opgehaald uit plancache. Een uitvoering van een query kan bijvoorbeeld resulteren in het gebruik van een serieel plan, een latere uitvoering van dezelfde query kan leiden tot een parallel plan met behulp van drie werkrolthreads. Een derde uitvoering kan leiden tot een parallel plan met behulp van vier werkrolthreads.
De update- en verwijderoperators in een parallel queryuitvoeringsplan worden serieel uitgevoerd, maar de WHERE component van een UPDATE of een DELETE instructie kan parallel worden uitgevoerd. De werkelijke gegevenswijzigingen worden vervolgens serieel toegepast op de database.
Tot SQL Server 2012 (11.x) wordt de invoegoperator ook serieel uitgevoerd. Het SELECT-gedeelte van een INSERT-instructie kan echter parallel worden uitgevoerd. De werkelijke gegevenswijzigingen worden vervolgens serieel toegepast op de database.
Vanaf SQL Server 2014 (12.x) en databasecompatibiliteitsniveau 110 kan de SELECT ... INTO-instructie parallel worden uitgevoerd. Andere vormen van invoegoperators werken op dezelfde manier als beschreven voor SQL Server 2012 (11.x).
Vanaf SQL Server 2016 (13.x) en databasecompatibiliteitsniveau 130 kan de INSERT ... SELECT-instructie parallel worden uitgevoerd bij het invoegen in heaps of geclusterde columnstore-indexen (CCI) en met behulp van de TABLOCK-hint. Invoegen in lokale tijdelijke tabellen (geïdentificeerd door het #-voorvoegsel) en globale tijdelijke tabellen (geïdentificeerd door ##-voorvoegsels) zijn ook ingeschakeld voor parallellisme met behulp van de TABLOCK-hint. Zie INSERT (Transact-SQL)voor meer informatie.
Statische en sleutelsetgestuurde cursors kunnen worden gevuld door parallelle uitvoeringsplannen. Het gedrag van dynamische cursors kan echter alleen worden aangeboden door seriële uitvoering. Query Optimizer genereert altijd een serieel uitvoeringsplan voor een query die deel uitmaakt van een dynamische cursor.
Mate van parallelle uitvoering negeren
De mate van parallelle uitvoering stelt het aantal processors in dat moet worden gebruikt in parallelle uitvoering van het plan. Deze configuratie kan op verschillende niveaus worden ingesteld:
Serverniveau, met behulp van de maximale mate van parallelle uitvoering (MAXDOP)serverconfiguratieoptie.
van toepassing op: SQL ServerNotitie
SQL Server 2019 (15.x) introduceert automatische aanbevelingen voor het instellen van de MAXDOP-serverconfiguratieoptie tijdens het installatieproces. Met de gebruikersinterface van setup kunt u de aanbevolen instellingen accepteren of uw eigen waarde invoeren. Zie Database Engine Configuration - MaxDOP-paginavoor meer informatie.
Werklastniveau door gebruik te maken van de configuratieoptie MAX_DOPResource Governor-workloadgroep.
Van toepassing op: SQL ServerDatabaseniveau, met behulp van de MAXDOPdatabaseconfiguratie.
van toepassing op: SQL Server en Azure SQL DatabaseQuery- of indexinstructieniveau, met behulp van de MAXDOP--queryhint of de MAXDOP--indexoptie. U kunt bijvoorbeeld de MAXDOP-optie gebruiken om het aantal processors dat is toegewezen aan een online indexbewerking te beheren, te verhogen of te verminderen. Op deze manier kunt u de resources verdelen die worden gebruikt door een indexbewerking met die van de gelijktijdige gebruikers.
van toepassing op: SQL Server en Azure SQL Database
Als u de maximale mate van parallelle uitvoering instelt op 0 (standaard), kan SQL Server alle beschikbare processors gebruiken tot maximaal 64 processors in een parallelle uitvoering van een plan. Hoewel SQL Server een runtimedoel van 64 logische processors instelt wanneer de optie MAXDOP is ingesteld op 0, kan een andere waarde indien nodig handmatig worden ingesteld. Als u MAXDOP instelt op 0 voor query's en indexen, kan SQL Server alle beschikbare processors gebruiken tot maximaal 64 processors voor de opgegeven query's of indexen in een parallelle uitvoering van het plan. MAXDOP is geen afgedwongen waarde voor alle parallelle query's, maar eerder een voorlopig doel voor alle query's die in aanmerking komen voor parallelle uitvoering. Dit betekent dat als er tijdens runtime onvoldoende werkthreads beschikbaar zijn, een query kan worden uitgevoerd met een lagere mate van parallelle uitvoering dan de configuratieoptie MAXDOP-server.
Fooi
Zie MAXDOP-aanbevelingen voor richtlijnen voor het configureren van MAXDOP op server-, database-, query- of hintniveau voor meer informatie.
Voorbeeld van parallelle query
De volgende query telt het aantal orders dat in een specifiek kwartaal is geplaatst, vanaf 1 april 2000, en waarin ten minste één regelitem van de order is ontvangen door de klant later dan de vastgelegde datum. Deze query bevat het aantal van dergelijke orders gegroepeerd op elke volgordeprioriteit en gesorteerd in oplopende prioriteitsvolgorde.
In dit voorbeeld worden theoretische tabel- en kolomnamen gebruikt.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
Stel dat de volgende indexen zijn gedefinieerd in de tabellen lineitem en orders:
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
Hier volgt een mogelijk parallel plan dat is gegenereerd voor de query die eerder werd weergegeven:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
In de onderstaande afbeelding ziet u een queryplan dat is uitgevoerd met een mate van parallelle uitvoering die gelijk is aan 4 en waarbij een join met twee tabellen wordt uitgevoerd.
Het parallelle plan bevat drie parallellismeoperators. Zowel de operator Indexzoeken van de o_datkey_ptr-index als de indexscanoperator van de l_order_dates_idx-index worden parallel uitgevoerd. Dit produceert verschillende exclusieve streams. Dit kan worden bepaald op basis van de dichtstbijzijnde parallellismeoperators boven respectievelijk de operators Indexscan en Indexzoekopdracht. Beide zijn bezig met het herverdelen van het type uitwisseling. Dat wil gezegd dat ze alleen gegevens tussen de streams herschikken en hetzelfde aantal streams op hun uitvoer produceren als bij hun invoer. Dit aantal streams is gelijk aan de mate van parallelle uitvoering.
De operator voor parallelle uitvoering boven de operator l_order_dates_idx Indexscan herpartitioneert de invoerstromen met behulp van de waarde van L_ORDERKEY als sleutel. Op deze manier eindigen dezelfde waarden van L_ORDERKEY in dezelfde uitvoerstroom. Tegelijkertijd behouden uitvoerstromen de volgorde op de L_ORDERKEY kolom om te voldoen aan de invoervereiste van de operator Samenvoegen.
De operator voor parallelle uitvoering boven de operator IndexZoeken herpartitioneert de invoerstromen met behulp van de waarde van O_ORDERKEY. Omdat de invoer niet is gesorteerd op de O_ORDERKEY-kolomwaarden en dit de joinkolom in de Merge Join-operator is, zorgt de Sorteer-operator tussen de Parallellisme en Merge Join-operators ervoor dat de invoer wordt gesorteerd voor de Merge Join-operator op de joinkolommen. De Sort-operator, net als de Merge Join-operator, wordt parallel uitgevoerd.
De bovenste parallelisme-operator verzamelt resultaten van verschillende stromen in één stroom. Gedeeltelijke aggregaties die worden uitgevoerd door de operator Stream Aggregate onder de operator parallellisme, worden vervolgens samengevoegd tot één SUM waarde voor elke verschillende waarde van de O_ORDERPRIORITY in de operator Stream Aggregate boven de operator parallellisme. Omdat dit plan twee uitwisselingssegmenten heeft, waarbij de mate van parallelle uitvoering gelijk is aan 4, worden er acht werkthreads gebruikt.
Voor meer informatie over de operators die in dit voorbeeld worden gebruikt, zie de Referentie voor Logische en Fysieke Operators van Showplan.
Parallelle indexbewerkingen
De queryplannen die zijn gebouwd voor de indexbewerkingen die een index maken of herbouwen, of een geclusterde index verwijderen, maken parallelle bewerkingen met meerdere werkrollen mogelijk op computers met meerdere microprocessors.
Notitie
Parallelle indexbewerkingen zijn alleen beschikbaar in Enterprise Edition, te beginnen met SQL Server 2008 (10.0.x).
SQL Server gebruikt dezelfde algoritmen om de mate van parallelle uitvoering (het totale aantal afzonderlijke werkthreads dat moet worden uitgevoerd) te bepalen voor indexbewerkingen, net als voor andere query's. De maximale mate van parallelle uitvoering voor een indexbewerking is onderworpen aan de maximale mate van parallelle uitvoering serverconfiguratieoptie. U kunt de maximale mate van parallelle uitvoering voor afzonderlijke indexbewerkingen overschrijven door de optie MAXDOP-index in te stellen in de instructies CREATE INDEX, ALTER INDEX, DROP INDEX en ALTER TABLE.
Wanneer de SQL Server Database Engine een indexuitvoeringsplan bouwt, wordt het aantal parallelle bewerkingen ingesteld op de laagste waarde van het volgende:
- Het aantal microprocessoren ofwel processoren in de computer.
- Het getal dat is opgegeven in de serverconfiguratieoptie 'maximale mate van parallellisme'.
- Het aantal CPU's dat nog onder een werkdrempel ligt voor SQL Server-werkthreads.
Op een computer met acht CPU's, maar waarbij de maximale mate van parallelle uitvoering is ingesteld op 6, worden er niet meer dan zes parallelle werkrolthreads gegenereerd voor een indexbewerking. Als vijf cpu's op de computer de drempelwaarde voor SQL Server-werk overschrijden wanneer een indexuitvoeringsplan is gebouwd, geeft het uitvoeringsplan slechts drie parallelle werkthreads op.
De belangrijkste fasen van een parallelle indexbewerking zijn onder andere:
- Een coördinerende werkdraad scant de tabel snel en willekeurig om de verdeling van de indexsleutels in te schatten. De coördinerende werknemerthread stelt de grenzen van sleutelbereiken vast, waarmee een aantal sleutelbereiken wordt gecreëerd dat gelijk is aan het aantal parallelle bewerkingen, waarbij elk sleutelbereik naar schatting een vergelijkbaar aantal rijen omvat. Als er bijvoorbeeld vier miljoen rijen in de tabel staan en de mate van parallelle uitvoering 4 is, bepaalt de coördinerende worker-thread de sleutelwaarden die de grenzen aangeven van vier sets rijen met 1 miljoen rijen in elke set. Als er niet voldoende sleutelbereiken kunnen worden vastgesteld om alle CPU's te gebruiken, wordt de mate van parallelle uitvoering dienovereenkomstig verminderd.
- De coördinerende werkthread verzendt een aantal werkthreads dat overeenkomt met de mate van parallelle bewerkingen en wacht tot deze werkthreads klaar zijn met hun werk. Elke werkrolthread scant de basistabel met behulp van een filter waarmee alleen rijen worden opgehaald met sleutelwaarden binnen het bereik dat is toegewezen aan de werkrolthread. Elke workerthread bouwt een indexstructuur voor de rijen in zijn sleutelwaardenbereik. In het geval van een gepartitioneerde index bouwt elke worker-thread een opgegeven aantal partities. Partities worden niet gedeeld tussen de worker threads.
- Nadat alle parallelle werkrolthreads zijn voltooid, verbindt de coördinerende werkrolthread de indexsubeenheden in één index. Deze fase is alleen van toepassing op offline indexbewerkingen.
Afzonderlijke CREATE TABLE- of ALTER TABLE-instructies kunnen meerdere beperkingen hebben waarvoor een index moet worden gemaakt. Deze bewerkingen voor het maken van meerdere indexen worden uitgevoerd in reeksen, hoewel elke afzonderlijke bewerking voor het maken van een index een parallelle bewerking kan zijn op een computer met meerdere CPU's.
Architectuur voor gedistribueerde query's
Microsoft SQL Server ondersteunt twee methoden voor het verwijzen naar heterogene OLE DB-gegevensbronnen in Transact-SQL instructies:
Namen van gekoppelde servers
De door het systeem opgeslagen proceduressp_addlinkedserverensp_addlinkedsrvloginworden gebruikt om een servernaam te geven aan een OLE DB-gegevensbron. Objecten in deze gekoppelde servers kunnen worden verwezen in Transact-SQL instructies met behulp van vierdelige namen. Als een gekoppelde servernaam vanDeptSQLSrvrbijvoorbeeld is gedefinieerd voor een ander exemplaar van SQL Server, verwijst de volgende instructie naar een tabel op die server:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;De naam van de gekoppelde server kan ook worden opgegeven in een
OPENQUERYinstructie om een rijenset te openen vanuit de OLE DB-gegevensbron. Deze rijenset kan vervolgens worden gebruikt als een tabel in Transact-SQL-instructies.Ad-hoc connectornamen
Voor onregelmatige verwijzingen naar een gegevensbron worden deOPENROWSET- ofOPENDATASOURCE-functies opgegeven met de informatie die nodig is om verbinding te maken met de gekoppelde server. De rijenset kan op dezelfde manier worden verwezen als naar een tabel in Transact-SQL-instructies.SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
SQL Server gebruikt OLE DB om te communiceren tussen de relationele engine en de opslagengine. De relationele engine breekt elke Transact-SQL instructie op in een reeks bewerkingen op eenvoudige OLE DB-rijensets die door de opslagengine van de basistabellen worden geopend. Dit betekent dat de relationele engine ook eenvoudige OLE DB-rijensets kan openen op een OLE DB-gegevensbron.
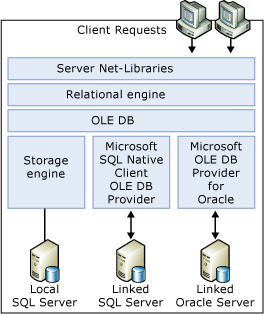
De relationele engine maakt gebruik van de OLE DB Application Programming Interface (API) om de rijensets op gekoppelde servers te openen, de rijen op te halen en transacties te beheren.
Voor elke OLE DB-gegevensbron die wordt geopend als een gekoppelde server, moet er een OLE DB-provider aanwezig zijn op de server waarop SQL Server wordt uitgevoerd. De set Transact-SQL bewerkingen die kunnen worden gebruikt voor een specifieke OLE DB-gegevensbron, is afhankelijk van de mogelijkheden van de OLE DB-provider.
Voor elk exemplaar van SQL Server kunnen leden van de sysadmin vaste serverfunctie het gebruik van ad-hocconnectornamen voor een OLE DB-provider in- of uitschakelen met behulp van de eigenschap SQL Server DisallowAdhocAccess. Wanneer ad-hoctoegang is ingeschakeld, kan elke gebruiker die is aangemeld bij dat exemplaar Transact-SQL instructies met ad-hocconnectornamen uitvoeren, waarbij wordt verwezen naar een willekeurige gegevensbron in het netwerk die toegankelijk is via die OLE DB-provider. Als u de toegang tot gegevensbronnen wilt beheren, kunnen leden van de rol sysadmin ad-hoctoegang voor die OLE DB-provider uitschakelen, waardoor gebruikers worden beperkt tot alleen die gegevensbronnen waarnaar wordt verwezen door gekoppelde servernamen die door de beheerders zijn gedefinieerd. Ad-hoctoegang is standaard ingeschakeld voor de SQL Server OLE DB-provider en uitgeschakeld voor alle andere OLE DB-providers.
Met gedistribueerde query's kunnen gebruikers toegang krijgen tot een andere gegevensbron (bijvoorbeeld bestanden, niet-relationele gegevensbronnen zoals Active Directory, enzovoort) met behulp van de beveiligingscontext van het Microsoft Windows-account waaronder de SQL Server-service wordt uitgevoerd. SQL Server imiteert de aanmelding op de juiste wijze voor Windows-aanmeldingen; Dit is echter niet mogelijk voor SQL Server-aanmeldingen. Hierdoor heeft een gedistribueerde querygebruiker mogelijk toegang tot een andere gegevensbron waarvoor ze geen machtigingen hebben, maar het account waarop de SQL Server-service wordt uitgevoerd, heeft wel machtigingen. Gebruik sp_addlinkedsrvlogin om de specifieke aanmeldingen te definiëren die zijn geautoriseerd voor toegang tot de bijbehorende gekoppelde server. Dit controle-element is niet beschikbaar voor ad-hocnamen. Wees daarom voorzichtig bij het inschakelen van een OLE DB-provider voor ad-hoc toegang.
Indien mogelijk voert SQL Server relationele bewerkingen uit, zoals joins, beperkingen, projecties, sorteringen en groeperingen van bewerkingen naar de OLE DB-gegevensbron. SQL Server scant de basistabel niet standaard in SQL Server en voert de relationele bewerkingen zelf uit. SQL Server voert een query uit op de OLE DB-provider om het niveau van SQL-grammatica te bepalen dat wordt ondersteund en pusht op basis van die informatie zoveel mogelijk relationele bewerkingen naar de provider.
SQL Server geeft een mechanisme op voor een OLE DB-provider om statistieken te retourneren die aangeven hoe sleutelwaarden worden gedistribueerd in de OLE DB-gegevensbron. Hierdoor kan de SQL Server Query Optimizer het patroon van gegevens in de gegevensbron beter analyseren op basis van de vereisten van elke Transact-SQL-instructie, waardoor de mogelijkheid van Query Optimizer wordt vergroot om optimale uitvoeringsplannen te genereren.
Verbeteringen in queryverwerking voor gepartitioneerde tabellen en indexen
SQL Server 2008 (10.0.x) verbeterde queryverwerkingsprestaties voor gepartitioneerde tabellen voor veel parallelle plannen, wijzigt de manier waarop parallelle en seriële plannen worden weergegeven en verbeterde partitioneringsgegevens in zowel compileer- als runtime-uitvoeringsplannen. In dit artikel worden deze verbeteringen beschreven, wordt uitgelegd hoe u de queryuitvoeringsplannen van gepartitioneerde tabellen en indexen interpreteert en aanbevolen procedures biedt voor het verbeteren van de queryprestaties op gepartitioneerde objecten.
Notitie
Tot SQL Server 2014 (12.x) worden gepartitioneerde tabellen en indexen alleen ondersteund in de edities SQL Server Enterprise, Developer en Evaluation. Vanaf SQL Server 2016 (13.x) SP1 worden gepartitioneerde tabellen en indexen ook ondersteund in sql Server Standard-editie.
Nieuwe partitiebewuste zoekbewerking
In SQL Server wordt de interne weergave van een gepartitioneerde tabel gewijzigd, zodat de tabel wordt weergegeven als een multicolumn-index met PartitionID als de voorloopkolom.
PartitionID is een verborgen berekende kolom die intern wordt gebruikt om de ID van de partitie met een specifieke rij weer te geven. Stel dat de tabel T, gedefinieerd als T(a, b, c), is gepartitioneerd op kolom a en een geclusterde index heeft op kolom b. In SQL Server wordt deze gepartitioneerde tabel intern behandeld als een niet-gepartitioneerde tabel met het schema T(PartitionID, a, b, c) en een geclusterde index op de samengestelde sleutel (PartitionID, b). Hierdoor kan de Query Optimizer zoekbewerkingen uitvoeren op basis van PartitionID op elke gepartitioneerde tabel of index.
Partitie-verwijdering wordt nu uitgevoerd in deze zoekbewerking.
Bovendien wordt de queryoptimalisatie uitgebreid, zodat een zoek- of scanbewerking met één voorwaarde kan worden uitgevoerd op PartitionID (als de logische voorloopkolom) en mogelijk andere indexsleutelkolommen, en vervolgens een zoekactie op het tweede niveau, met een andere voorwaarde, kan worden uitgevoerd op een of meer extra kolommen, voor elke afzonderlijke waarde die voldoet aan de kwalificatie voor de zoekbewerking op het eerste niveau. Met deze bewerking, een zogenaamde skip scan, kan de Query Optimizer een zoek- of scanbewerking uitvoeren op basis van één voorwaarde om te bepalen welke partities moeten worden geopend en een zoekbewerking op het tweede niveau binnen die operator om rijen van deze partities te retourneren die aan een andere voorwaarde voldoen. Denk bijvoorbeeld aan de volgende query.
SELECT * FROM T WHERE a < 10 and b = 2;
In dit voorbeeld wordt ervan uitgegaan dat tabel T, gedefinieerd als T(a, b, c), is gepartitioneerd op kolom a en een geclusterde index heeft op kolom b. De partitiegrenzen voor tabel T worden gedefinieerd door de volgende partitiefunctie:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
Om de query op te lossen, voert de queryprocessor een zoekbewerking op het eerste niveau uit om te zoeken naar elke partitie die rijen bevat die voldoen aan de voorwaarde T.a < 10. Hiermee worden de partities geïdentificeerd die moeten worden geopend. Binnen elke geïdentificeerde partitie voert de processor vervolgens een tweede niveauzoeking uit in de geclusterde index op kolom b om de rijen te vinden die voldoen aan de voorwaarde T.b = 2 en T.a < 10.
De volgende afbeelding is een logische weergave van de scanbewerking overslaan. Het toont tabel T met gegevens in kolommen a en b. De partities zijn genummerd 1 tot en met 4 met de partitiegrenzen die worden weergegeven door gestreepte verticale lijnen. Een zoekbewerking op het eerste niveau voor de partities (niet weergegeven in de afbeelding) heeft vastgesteld dat partities 1, 2 en 3 voldoen aan de zoekvoorwaarde die wordt geïmpliceerd door de partitionering die is gedefinieerd voor de tabel en het predicaat op kolom a. Dat wil zeggen, T.a < 10. Het pad dat wordt doorkruist door het tweede-niveau zoekgedeelte van de skip-scanbewerking, wordt geïllustreerd door de gekromde lijn. In wezen zoekt de skip scan-bewerking naar elk van deze partities voor rijen die aan de voorwaarde b = 2voldoen. De totale kosten van de skip-scanbewerking zijn dezelfde als die van drie afzonderlijke index-opzoekingen.
Partitioneringsgegevens weergeven in queryuitvoeringsplannen
De uitvoeringsplannen van query's op gepartitioneerde tabellen en indexen kunnen worden onderzocht met behulp van de Transact-SQL SET-instructies SET SHOWPLAN_XML of SET STATISTICS XML, of met behulp van de uitvoer van het grafische uitvoeringsplan in SQL Server Management Studio. U kunt bijvoorbeeld het compileertijd-uitvoeringsplan weergeven door Geschat uitvoeringsplan weergeven op de werkbalk van de queryeditor te selecteren en het runtime-uitvoeringsplan opnemen door Werkelijke uitvoeringsplan opnemente selecteren.
Met deze hulpprogramma's kunt u de volgende informatie vaststellen:
- De bewerkingen zoals
scans,seeks,inserts,updates,mergesendeletesdie toegang hebben tot gepartitioneerde tabellen of indexen. - De partities die worden geopend door de query. Het totale aantal partities dat wordt geopend en de bereiken van aaneengesloten partities die worden geopend, zijn bijvoorbeeld beschikbaar in uitvoeringsplannen voor runtime.
- Wanneer de skip scan-operatie wordt gebruikt tijdens een zoek- of scanproces om gegevens uit een of meer partities op te halen.
Verbeteringen in partitiegegevens
SQL Server biedt verbeterde partitioneringsinformatie voor zowel compileer- als runtime-uitvoeringsplannen. Uitvoeringsplannen bieden nu de volgende informatie:
- Een optioneel
Partitionedkenmerk dat aangeeft dat een operator, zoals eenseek,scan,insert,update,mergeofdelete, wordt uitgevoerd op een gepartitioneerde tabel. - Een nieuw
SeekPredicateNew-element met eenSeekKeyssubelement datPartitionIDbevat als de belangrijkste indexsleutelkolom en filtervoorwaarden waarmee het bereik wordt opgegeven opPartitionID. De aanwezigheid van tweeSeekKeys-subelementen duidt erop dat een skip-scanbewerking opPartitionIDwordt gebruikt. - Samenvattende informatie die het totale aantal benaderde partities geeft. Deze informatie is alleen beschikbaar in runtime-abonnementen.
Bekijk de volgende query in de gepartitioneerde tabel fact_salesom te laten zien hoe deze informatie wordt weergegeven in zowel de uitvoer van het grafische uitvoeringsplan als de XML Showplan-uitvoer. Met deze query worden gegevens in twee partities bijgewerkt.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
In de volgende afbeelding ziet u de eigenschappen van de operator Clustered Index Seek in het runtime-uitvoeringsplan voor deze query. Zie 'Voorbeeld' in dit artikel als u de definitie van de fact_sales tabel en de partitiedefinitie wilt bekijken.

Gepartitioneerd kenmerk
Wanneer een operator zoals indexzoeken wordt uitgevoerd op een gepartitioneerde tabel of index, wordt het kenmerk Partitioned weergegeven in het compileer- en runtime-plan en wordt ingesteld op True (1). Het kenmerk wordt niet weergegeven wanneer het is ingesteld op False (0).
Het kenmerk Partitioned kan worden weergegeven in de volgende fysieke en logische operators:
- Tabelscan
- Indexscan
- Indexzoeken
- Invoegen
- Bijwerken
- Verwijderen
- Samenvoegen
Zoals in de vorige afbeelding wordt weergegeven, wordt dit kenmerk weergegeven in de eigenschappen van de operator waarin het is gedefinieerd. In de XML Showplan-uitvoer wordt dit kenmerk weergegeven als Partitioned="1" in het RelOp knooppunt van de operator waarin deze is gedefinieerd.
Nieuw zoekpredicaat
In xml Showplan-uitvoer wordt het element SeekPredicateNew weergegeven in de operator waarin het is gedefinieerd. Het kan maximaal twee exemplaren van het SeekKeys subelement bevatten. Het eerste SeekKeys item geeft de zoekbewerking op het eerste niveau op het partitie-id-niveau van de logische index aan. Dat wil gezegd, deze zoekopdracht bepaalt de partities die moeten worden geopend om te voldoen aan de voorwaarden van de query. Het tweede SeekKeys-item specificeert het zoekgedeelte op de tweede laag van de skipscanbewerking die plaatsvindt binnen elke partitie die in de eerste-laagseek wordt geïdentificeerd.
Samenvatting van partitie-informatie
In uitvoeringsplannen voor runtime biedt overzichtsinformatie over partities een telling van de partities die worden geopend en de identiteit van de werkelijke partities die worden geopend. U kunt deze informatie gebruiken om te controleren of de juiste partities worden geopend in de query en dat alle andere partities worden verwijderd uit overweging.
De volgende informatie wordt verstrekt: Actual Partition Counten Partitions Accessed.
Actual Partition Count is het totale aantal partities dat door de query wordt geopend.
Partitions Accessed, in de uitvoer van een XML-showplan, is de samenvattingsinformatie van de partitie die wordt weergegeven in het nieuwe RuntimePartitionSummary-element binnen het RelOp-knooppunt van de operator waarin deze is gedefinieerd. In het volgende voorbeeld ziet u de inhoud van het element RuntimePartitionSummary, waarmee wordt aangegeven dat er twee totale partities worden geopend (partities 2 en 3).
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
Partitiegegevens weergeven met behulp van andere Showplan-methoden
De Showplan-methoden SHOWPLAN_ALL, SHOWPLAN_TEXTen STATISTICS PROFILE de partitiegegevens die in dit artikel worden beschreven, niet rapporteren, met de volgende uitzondering. Als onderdeel van het predicaat SEEK worden de te openen partities geïdentificeerd door een bereikpredicaat in de berekende kolom die de partitie-id vertegenwoordigt. In het volgende voorbeeld ziet u het predicaat SEEK voor een Clustered Index Seek operator. Partities 2 en 3 worden geopend en de zoekoperator filtert op de rijen die voldoen aan de voorwaarde date_id BETWEEN 20080802 AND 20080902.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
Interpreteer uitvoeringsplannen voor gepartitioneerde heaps
Een gepartitioneerde heap wordt behandeld als een logische index op de partitie-ID. Partitie-eliminatie van een gepartitioneerde heap wordt weergegeven in een uitvoeringsplan als een Table Scan-operator met een SEEK-predicaat op partitie-ID. In het volgende voorbeeld ziet u de weergegeven Showplan-informatie:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
Interpreteer uitvoeringsplannen voor samengestelde samenvoegingen
Join collocation kan optreden wanneer twee tabellen worden gepartitioneerd met dezelfde of equivalente partitioneringsfunctie en de partitioneringskolommen van beide zijden van de join worden opgegeven in de joinvoorwaarde van de query. Query Optimizer kan een plan genereren waarbij de partities van elke tabel met gelijke partitie-id's afzonderlijk worden samengevoegd. Gecolloceerde joins kunnen sneller zijn dan niet-gecolloceerde joins, omdat ze mogelijk minder geheugen en verwerkingstijd vereisen. De Query Optimizer kiest een niet-gecolloceerd plan of een gecolloceerd plan op basis van kostenramingen.
In een gecolloceerd plan leest de Nested Loops join een of meer gekoppelde tabel- of indexpartities van de binnenzijde. De getallen binnen de Constant Scan operators vertegenwoordigen de partitienummers.
Wanneer parallelle plannen voor collocated joins worden gegenereerd voor gepartitioneerde tabellen of indexen, verschijnt er een Parallelism-operator tussen de Constant Scan- en de Nested Loops-join-operators. In dit geval leest en werkt elke werkthread aan de buitenzijde van de join op een verschillende partitie.
In de volgende afbeelding wordt een parallel queryplan voor een collocated join getoond.
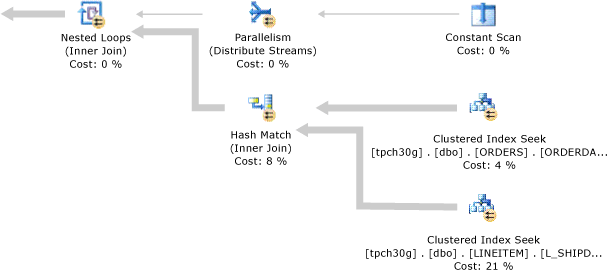
Strategie voor parallelle uitvoering van query's voor gepartitioneerde objecten
De queryprocessor maakt gebruik van een parallelle uitvoeringsstrategie voor query's die een selectie maken uit gepartitioneerde objecten. Als onderdeel van de uitvoeringsstrategie bepaalt de queryprocessor welke tabelpartities nodig zijn voor de query en de hoeveelheid werkthreads die aan elke partitie worden toegewezen. In de meeste gevallen wijst de query-processor een gelijk of bijna gelijk aantal werkthreads toe aan elke partitie en voert de query vervolgens parallel over de partities uit. In de volgende alinea's wordt de toewijzing van worker threads in meer detail uitgelegd.
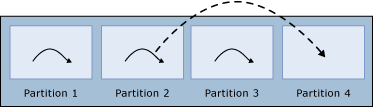
Als het aantal werkrolthreads kleiner is dan het aantal partities, wijst de queryprocessor elke werkrolthread toe aan een andere partitie, waardoor in eerste instantie een of meer partities zonder toegewezen werkrolthread worden achtergelaten. Wanneer een werkrolthread klaar is met het uitvoeren van een partitie, wijst de queryprocessor deze toe aan de volgende partitie totdat aan elke partitie één werkrolthread is toegewezen. Dit is het enige geval waarin de query-processor werkthreads naar andere partities herverdeelt.
Toont dat de worker thread opnieuw is toegewezen nadat hij is voltooid. Als het aantal werkthreads gelijk is aan het aantal partities, kent de queryprocessor één werkthread toe aan elke partitie. Wanneer een werkdraad klaar is, wordt deze niet opnieuw ingedeeld in een andere partitie.

Als het aantal worker-threads groter is dan het aantal partities, wijst de queryprocessor een gelijk aantal worker-threads toe aan elke partitie. Als het aantal werkdraad niet exact een veelvoud is van het aantal partities, wijst de queryprocessor een extra werkdraad toe aan sommige partities om alle beschikbare werkdraad te kunnen gebruiken. Als er slechts één partitie is, worden alle worker threads aan die partitie toegewezen. In het onderstaande diagram zijn er vier partities en 14 werknemer-draad. Aan elke partitie zijn drie werkthreads toegewezen en twee partities hebben een extra werkthread voor in totaal 14 werkthreadtoewijzingen. Wanneer een worker thread klaar is, wordt deze niet toegewezen aan een andere partitie.

Hoewel de bovenstaande voorbeelden een eenvoudige manier voorstellen om worker threads toe te wijzen, is de werkelijke strategie complexer en houdt ze rekening met andere variabelen die optreden tijdens het uitvoeren van query's. Als de tabel bijvoorbeeld is gepartitioneerd en een geclusterde index heeft op kolom A en een query de predicaatcomponent heeft WHERE A IN (13, 17, 25), wijst de queryprocessor een of meer werkthreads toe aan elk van deze drie zoekwaarden (A=13, A=17 en A=25) in plaats van elke tabelpartitie. Het is alleen nodig om de query uit te voeren in de partities die deze waarden bevatten. Als al deze zoekcriteria zich in dezelfde tabelpartitie bevinden, worden alle worker threads toegewezen aan dezelfde tabelpartitie.
Stel dat de tabel vier partities heeft op kolom A met grenspunten (10, 20, 30), een index op kolom B en dat de query een predicaatcomponent heeft WHERE B IN (50, 100, 150). Omdat de tabelpartities zijn gebaseerd op de waarden van A, kunnen de waarden van B optreden in een van de tabelpartities. De queryprocessor zoekt dus naar elk van de drie waarden van B (50, 100, 150) in elk van de vier tabelpartities. De queryprocessor zal werkthreads evenredig toewijzen, zodat elk van deze 12 queryscans parallel kan worden uitgevoerd.
| Tabelpartities op basis van kolom A | Zoekt naar kolom B in elke tabelpartitie |
|---|---|
| Tabelpartitie 1: < 10 | B=50, B=100, B=150 |
| Tabelpartitie 2: Een >= 10 EN A < 20 | B=50, B=100, B=150 |
| Tabelpartitie 3: A >= 20 EN A < 30 | B=50, B=100, B=150 |
| Partitie 4 van de tabel: A >= 30 | B=50, B=100, B=150 |
Beste werkwijzen
Voor het verbeteren van de prestaties van query's die toegang hebben tot een grote hoeveelheid gegevens uit grote gepartitioneerde tabellen en indexen, raden we de volgende aanbevolen procedures aan:
- Streep elke partitie over veel schijven. Dit is vooral relevant bij het gebruik van draaiende schijven.
- Gebruik indien mogelijk een server met voldoende hoofdgeheugen om vaak gebruikte partities of alle partities in het geheugen aan te passen om de I/O-kosten te verlagen.
- Als de gegevens die u opvraagt niet in het geheugen passen, comprimeert u de tabellen en indexen. Dit vermindert de I/O-kosten.
- Gebruik een server met snelle processors en zo veel processorkernen als u zich kunt veroorloven, om te profiteren van parallelle queryverwerkingsmogelijkheden.
- Zorg ervoor dat de server voldoende I/O-controllerbandbreedte heeft.
- Maak een geclusterde index op elke grote gepartitioneerde tabel om gebruik te maken van B-tree scanoptimalisaties.
- Volg de best practice-aanbevelingen in het witboek, The Data Loading Performance Guide, wanneer gegevens bulksgewijs in gepartitioneerde tabellen worden geladen.
Voorbeeld
In het volgende voorbeeld wordt een testdatabase gemaakt met één tabel met zeven partities. Gebruik de hulpprogramma's die eerder zijn beschreven bij het uitvoeren van de query's in dit voorbeeld om partitioneringsgegevens weer te geven voor zowel compileertijd- als runtimeplannen.
Notitie
In dit voorbeeld worden meer dan 1 miljoen rijen in de tabel ingevoegd. Het uitvoeren van dit voorbeeld kan enkele minuten duren, afhankelijk van uw hardware. Controleer voordat u dit voorbeeld uitvoert of er meer dan 1,5 GB schijfruimte beschikbaar is.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
Verwante inhoud
- Logische en fysieke showplan-operatorreferenties
- Overzicht van uitgebreide gebeurtenissen
- Aanbevolen procedures voor het bewaken van workloads met Query Store-
- Kardinaliteitschatting (SQL Server)
- Intelligent queryverwerking in SQL-databases
- operator-prioriteit (Transact-SQL)
- Overzicht van uitvoeringsplan
- Performance Center voor SQL Server Database Engine en Azure SQL Database