Geleerde lessen
- Zorg ervoor dat alle betrokken partijen het verschil tussen hoge beschikbaarheid en herstel na noodgevallen (DR) begrijpen: een veelvoorkomende valkuil is om de twee concepten te verwarren en niet overeen te komen met de bijbehorende oplossingen.
- Bespreek met de belanghebbenden van het bedrijf over hun verwachtingen met betrekking tot de volgende aspecten om de beoogde herstelpunten (RPO's) en beoogde hersteltijd (RPO's) te definiëren:
- Hoeveel downtime ze kunnen verdragen, houd er rekening mee dat meestal, hoe sneller het herstel, hoe hoger de kosten.
- Het type incidenten waarvan ze willen worden beschermd, waarbij de gerelateerde kans op een dergelijke gebeurtenis wordt vermeld. De kans dat een server uitvalt, is bijvoorbeeld hoger dan een natuurramp die van invloed is op alle datacenters in een regio.
- Welke gevolgen heeft het systeem dat niet beschikbaar is voor hun bedrijf?
- Het budget operationele uitgaven (OPEX) voor de oplossing.
- Bedenk welke verslechterde serviceopties uw eindgebruikers kunnen accepteren. Dit kan het volgende omvatten:
- Als de opnamepijplijnen niet werken, hebben ze nog steeds toegang tot visualisatiedashboards, zelfs zonder de meest recente gegevens. Als de opnamepijplijnen niet werken, hebben eindgebruikers nog steeds toegang tot hun gegevens.
- Leestoegang hebben, maar geen schrijftoegang.
- Metrische RTO- en RPO-doelgegevens kunnen definiëren welke strategie voor herstel na noodgevallen u wilt implementeren:
- Actief/actief.
- Actief/passief.
- Actief/opnieuw implementeren bij noodgeval.
- Houd rekening met uw eigen samengestelde serviceniveaudoelstelling (SLO) om rekening te houden met de toelaatbare downtime.
- Zorg ervoor dat u alle onderdelen begrijpt die van invloed kunnen zijn op de beschikbaarheid van uw systemen, zoals:
- Identiteitsbeheer.
- Netwerktopologie.
- Geheim/sleutelbeheer.
- Gegevensbronnen
- Automation/job scheduler.
- Bronopslagplaats en implementatiepijplijnen (GitHub, Azure DevOps).
- Vroege detectie van storingen is ook een manier om RTO- en RPO-waarden aanzienlijk te verlagen. Hier volgen enkele aspecten die moeten worden behandeld:
- Definieer wat een storing is en hoe deze wordt toegewezen aan de definitie van een storing van Microsoft. De Definitie van Microsoft is beschikbaar op de pagina Azure Service Level Agreement (SLA) op product- of serviceniveau.
- Een efficiënt bewakings- en waarschuwingssysteem met verantwoordelijke teams om die metrische gegevens en waarschuwingen tijdig te controleren, helpt het doel te bereiken.
- Met betrekking tot het ontwerp van het abonnement kan de extra infrastructuur voor herstel na noodgevallen worden opgeslagen in het oorspronkelijke abonnement. PaaS-services (platform as a Service), zoals Azure Data Lake Storage Gen2 of Azure Data Factory, hebben doorgaans systeemeigen functies waarmee failover naar secundaire exemplaren in andere regio's wordt toegestaan terwijl ze zich in het oorspronkelijke abonnement bevinden. Sommige klanten kunnen overwegen om een toegewezen resourcegroep te hebben voor resources die alleen worden gebruikt in noodherstelscenario's voor kostendoeleinden.
- Er moet worden opgemerkt dat abonnementslimieten kunnen fungeren als een beperking voor deze benadering.
- Andere beperkingen kunnen de ontwerpcomplexiteit en beheerbesturingselementen omvatten om ervoor te zorgen dat de DR-resourcegroepen niet worden gebruikt voor zakelijke werkstromen (BAU).
- Ontwerp de DR-werkstroom op basis van de kritiek en afhankelijkheden van een oplossing. Probeer bijvoorbeeld geen Azure Analysis Services-exemplaar opnieuw op te bouwen voordat uw datawarehouse actief is, omdat er een fout optreedt. Laat ontwikkellabs later in het proces staan en herstel eerst de belangrijkste bedrijfsoplossingen.
- Probeer hersteltaken te identificeren die kunnen worden geparallelliseerd in oplossingen, waardoor het totale aantal RTO's wordt verminderd.
- Als Azure Data Factory in een oplossing wordt gebruikt, vergeet dan niet om zelf-hostende integratieruntimes in het bereik op te nemen. Azure Site Recovery is ideaal voor deze machines.
- Handmatige bewerkingen moeten zoveel mogelijk worden geautomatiseerd om menselijke fouten te voorkomen, met name wanneer deze onder druk staan. U wordt aangeraden het volgende te doen:
- Gebruik resource-inrichting via Bicep-, ARM-sjablonen of PowerShell-scripts.
- Versiebeheer van broncode en resourceconfiguratie aannemen.
- Gebruik CI/CD-releasepijplijnen in plaats van klik-ops.
- Aangezien u een plan voor failover hebt, moet u rekening houden met procedures om terug te vallen op de primaire exemplaren.
- Definieer duidelijke indicatoren en metrische gegevens om te controleren of de failover is geslaagd en dat oplossingen actief zijn of dat de situatie weer normaal is (ook wel primair functioneel genoemd).
- Bepaal of uw SLA's (Service Level Agreements) hetzelfde moeten blijven na een failover of als u een verminderde service toestaat.
- Deze beslissing is sterk afhankelijk van het bedrijfsproces dat wordt ondersteund. De failover voor een ruimtereserveringssysteem ziet er bijvoorbeeld veel anders uit dan een kern operationeel systeem.
- Een RTO/RPO-definitie moet zijn gebaseerd op specifieke gebruikersscenario's in plaats van op infrastructuurniveau. Als u dit doet, krijgt u meer granulariteit over welke processen en onderdelen eerst moeten worden hersteld als er een storing of noodgeval is.
- Zorg ervoor dat u capaciteitscontroles opneemt in de doelregio voordat u verdergaat met een failover: als er een grote ramp is, moet u er rekening mee houden dat veel klanten tegelijkertijd proberen een failover uit te voeren naar dezelfde gekoppelde regio, wat vertragingen of conflicten kan veroorzaken bij het inrichten van de resources.
- Als deze risico's onaanvaardbaar zijn, moet een actief/actief of actief/passief herstelstrategie worden overwogen.
- Er moet een plan voor herstel na noodgevallen worden gemaakt en onderhouden om het herstelproces en de eigenaren van de actie vast te leggen. Houd er ook rekening mee dat mensen mogelijk verlof hebben, dus zorg ervoor dat u secundaire contactpersonen opneemt.
- Regelmatige noodherstelanalyses moeten worden uitgevoerd om de werkstroom voor herstel na noodgeval te valideren, dat deze voldoet aan de vereiste RTO/RPO en om de verantwoordelijke teams te trainen.
- Back-ups van gegevens en configuratie moeten ook regelmatig worden getest om ervoor te zorgen dat ze 'geschikt voor doel' zijn om herstelactiviteiten te ondersteunen.
- Vroege samenwerking met teams die verantwoordelijk zijn voor het inrichten van netwerken, identiteiten en resources, maakt overeenstemming mogelijk over de meest optimale oplossing met betrekking tot:
- Gebruikers en verkeer van uw primaire naar uw secundaire site omleiden. Concepten zoals DNS-omleiding of het gebruik van specifieke hulpprogramma's, zoals Azure Traffic Manager , kunnen worden geëvalueerd.
- Hoe u op een tijdige en veilige manier toegang en rechten aan de secundaire site kunt bieden.
- Tijdens een noodgeval is effectieve communicatie tussen de vele betrokken partijen essentieel voor de efficiënte en snelle uitvoering van het plan. Teams kan het volgende omvatten:
- Besluitvormers.
- Incidentresponsteam.
- Beïnvloede interne gebruikers en teams.
- Externe teams.
- De indeling van de verschillende resources op het juiste moment zorgt voor efficiëntie in de uitvoering van het noodherstelplan.
Overwegingen
Antipatroon
- Kopieer/plak deze artikelreeks Deze reeks artikelen is bedoeld om klanten te voorzien van richtlijnen voor het volgende detailniveau voor een azure-specifiek dr-proces. Als zodanig is het gebaseerd op de algemene IP-adressen en referentiearchitecturen van Microsoft in plaats van op één klantspecifieke Azure-implementatie.
Hoewel de verstrekte details een solide basiskennis kunnen ondersteunen, moeten klanten hun eigen specifieke context, implementatie en vereisten toepassen voordat ze een 'fit for purpose'-strategie en -proces krijgen.
Het behandelen van herstel na noodgevallen als een technisch proces dat zakelijke belanghebbenden hebben, spelen een belangrijke rol bij het definiëren van de vereisten voor herstel na noodgeval en het voltooien van de bedrijfsvalidatiestappen die nodig zijn om een serviceherstel te bevestigen. Ervoor zorgen dat zakelijke belanghebbenden betrokken zijn bij alle DR-activiteiten, bieden een DR-proces dat 'geschikt voor doel' is, de bedrijfswaarde vertegenwoordigt en uitvoerbaar is.
Dr-plannen voor 'instellen en vergeten' Azure ontwikkelen zich voortdurend, net zoals het gebruik van verschillende onderdelen en services van individuele klanten. Een "fit for purpose" DR-proces moet zich met hen ontwikkelen. Ofwel via het SDLC-proces (Software Development Life Cycle) of periodieke beoordelingen, moeten klanten regelmatig opnieuw naar hun DR-plan gaan. Het doel is om ervoor te zorgen dat het serviceherstelplan geldig is en dat eventuele verschillen tussen onderdelen, services of oplossingen zijn verwerkt.
Op papier gebaseerde evaluaties Terwijl de end-to-end simulatie van een DR-gebeurtenis moeilijk zal zijn in een modern data-ecosysteem, moeten er inspanningen worden geleverd om zo dicht mogelijk bij een volledige simulatie van betrokken onderdelen te komen. Regelmatig geplande oefeningen bouwen het "spiergeheugen" dat door de organisatie is vereist om het DR-plan met vertrouwen uit te voeren.
Afhankelijk van Microsoft om dit alles te doen binnen de Microsoft Azure-services, is er een duidelijke verdeling van verantwoordelijkheid, verankerd door de cloudservicelaag die wordt gebruikt:
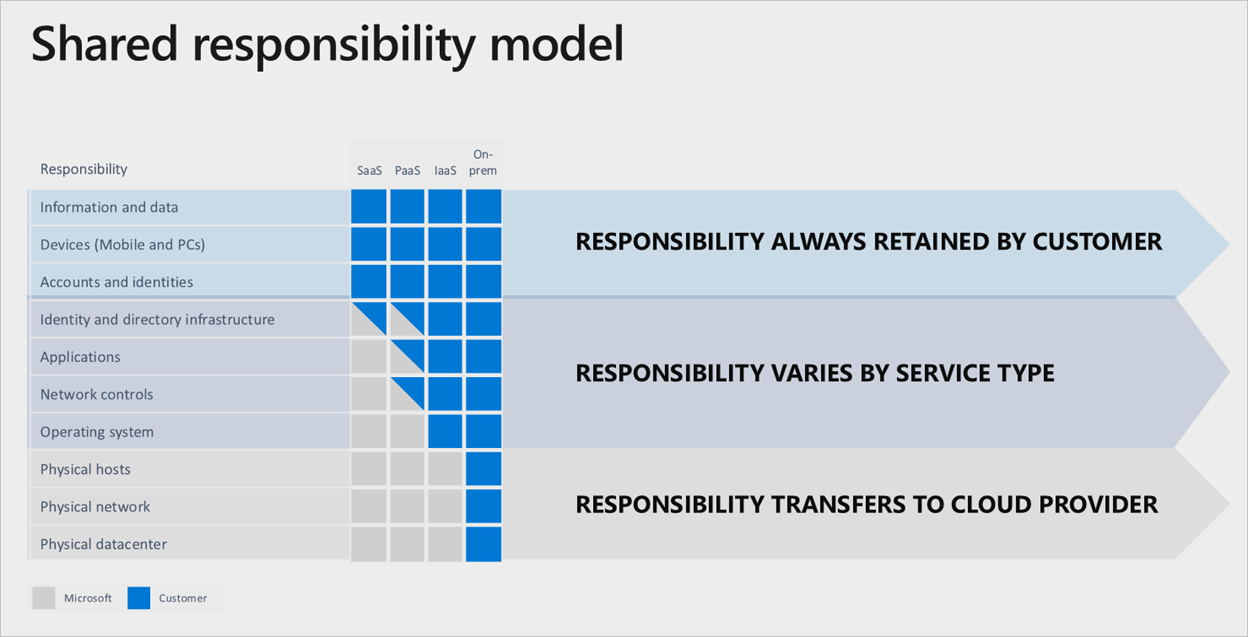 Zelfs als er een volledige SaaS-stack (Software as a Service) wordt gebruikt, behoudt de klant nog steeds de verantwoordelijkheid om ervoor te zorgen dat de accounts, identiteiten en gegevens juist/up-to-date zijn, samen met de apparaten die worden gebruikt om te communiceren met de Azure-services.
Zelfs als er een volledige SaaS-stack (Software as a Service) wordt gebruikt, behoudt de klant nog steeds de verantwoordelijkheid om ervoor te zorgen dat de accounts, identiteiten en gegevens juist/up-to-date zijn, samen met de apparaten die worden gebruikt om te communiceren met de Azure-services.
Gebeurtenisbereik en -strategie
Bereik van noodgeval
Verschillende gebeurtenissen hebben een ander effect en daarom een ander antwoord. In het volgende diagram ziet u dit voor een noodgeval: 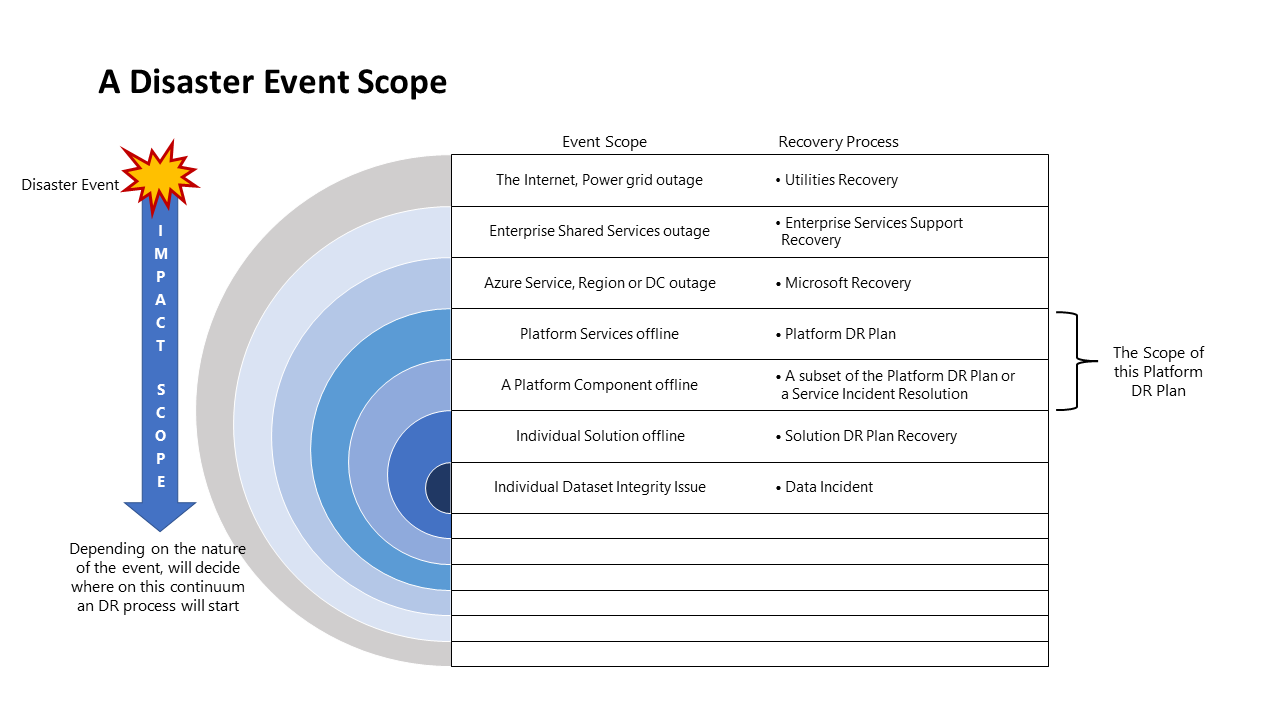
Opties voor strategie voor noodgevallen
Er zijn vier algemene opties voor een strategie voor herstel na noodgevallen:
- Wacht op Microsoft - Zoals de naam al aangeeft, is de oplossing offline totdat het volledige herstel van services in de getroffen regio door Microsoft is voltooid. Nadat de oplossing is hersteld, wordt de oplossing gevalideerd door de klant en vervolgens bijgewerkt voor serviceherstel.
- Opnieuw implementeren bij noodgeval : de oplossing wordt handmatig opnieuw geïmplementeerd in een volledig nieuwe regio, na noodgevallen.
- Warm reserve (actief/passief): er wordt een secundaire gehoste oplossing gemaakt in een alternatieve regio en onderdelen worden geïmplementeerd om minimale capaciteit te garanderen. De onderdelen ontvangen echter geen productieverkeer. De secundaire services in de alternatieve regio kunnen worden 'uitgeschakeld' of worden uitgevoerd op een lager prestatieniveau totdat een DR-gebeurtenis plaatsvindt.
- Hot Spare (actief/actief): de oplossing wordt gehost in een actieve/actieve installatie in meerdere regio's. De secundaire gehoste oplossing ontvangt, verwerkt en dient gegevens als onderdeel van het grotere systeem.
Impact van dr-strategie
Hoewel de operationele kosten die worden toegeschreven aan de hogere servicetolerantieniveaus, vaak de KDD (Key Design Decision) voor een DR-strategie overheerst. Er zijn andere belangrijke overwegingen.
Notitie
Kostenoptimalisatie is een van de vijf pijlers van architecturale uitmuntendheid met het Azure Well-Architected Framework. Het doel is om onnodige uitgaven te verminderen en operationele efficiëntie te verbeteren.
Het dr-scenario voor dit gewerkte voorbeeld is een volledige regionale Azure-storing die rechtstreeks van invloed is op de primaire regio die als host fungeert voor het Contoso-gegevensplatform.
Voor dit storingsscenario zijn de relatieve impact op de vier strategieën voor herstel na noodgevallen op hoog niveau: 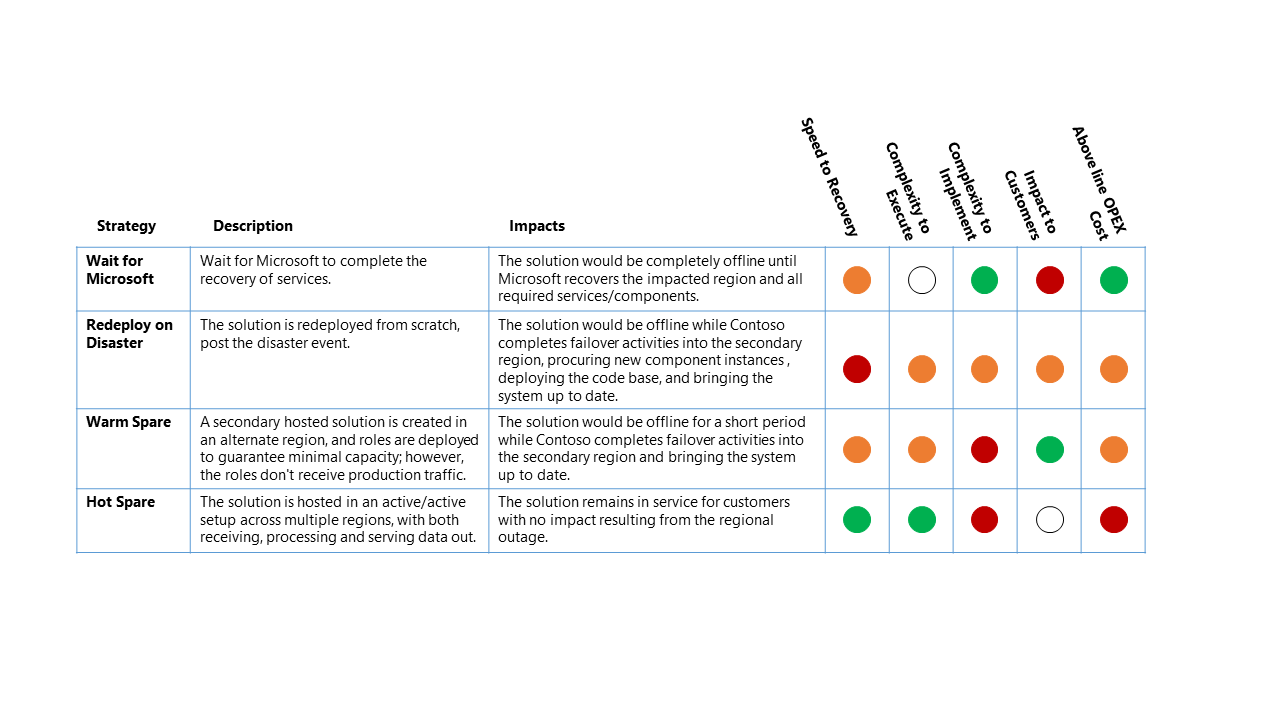
Classificatiesleutel
- Beoogde hersteltijd (RTO): De verwachte verstreken tijd van de noodgebeurtenis tot platformserviceherstel.
- Complexiteit die moet worden uitgevoerd: de complexiteit voor de organisatie om de herstelactiviteiten uit te voeren.
- Complexiteit die moet worden geïmplementeerd: de complexiteit voor de organisatie om de STRATEGIE voor herstel na noodgeval te implementeren.
- Impact op klanten: de directe impact op klanten van de dataplatformservice van de DR-strategie.
- Boven regel OPEX-kosten: de extra kosten die worden verwacht bij het implementeren van deze strategie, zoals hogere maandelijkse facturering voor Azure voor extra onderdelen en aanvullende resources die nodig zijn voor ondersteuning.
Notitie
De bovenstaande tabel moet worden gelezen als een vergelijking tussen de opties: een strategie met een groene indicator is beter voor die classificatie dan een andere strategie met een gele of rode indicator.
Volgende stappen
Nu u meer hebt geleerd over de aanbevelingen met betrekking tot het scenario, kunt u leren hoe u dit scenario kunt implementeren