In dit artikel worden enkele strategieën beschreven voor het partitioneren van gegevens in verschillende Azure-gegevensarchieven. Zie Gegevenspartitioneringvoor algemene richtlijnen over het partitioneren van gegevens en best practices.
Partitioneren van Azure SQL Database
Eén SQL-database heeft een limiet voor het volume aan gegevens dat deze kan bevatten. Doorvoer wordt beperkt door architecturale factoren en het aantal gelijktijdige verbindingen dat wordt ondersteund.
Elastische pools horizontale schaalaanpassing voor een SQL-database ondersteunen. Met elastische pools kunt u uw gegevens partitioneren in shards die zijn verspreid over meerdere SQL-databases. U kunt ook shards toevoegen of verwijderen als het gegevensvolume dat u moet verwerken, groeit en verkleint. Elastische pools kunnen ook helpen conflicten te verminderen door de belasting over databases te verdelen.
Elke shard wordt geïmplementeerd als een SQL-database. Een shard kan meer dan één gegevensset bevatten (een shardlet-genoemd). Elke database onderhoudt metagegevens die de shardlets beschrijven die deze bevat. Een shardlet kan één gegevensitem zijn of een groep items die dezelfde shardlet-sleutel delen. In een multitenant-toepassing kan de shardlet-sleutel bijvoorbeeld de tenant-id zijn en kunnen alle gegevens voor een tenant in dezelfde shardlet worden bewaard.
Clienttoepassingen zijn verantwoordelijk voor het koppelen van een gegevensset aan een shardlet-sleutel. Een afzonderlijke SQL Database fungeert als een globale shard-toewijzingsbeheerder. Deze database bevat een lijst met alle shards en shardlets in het systeem. De toepassing maakt verbinding met de shard-toewijzingsbeheerdatabase om een kopie van de shard-toewijzing te verkrijgen. Hiermee wordt de shard-toewijzing lokaal in de cache opgeslagen en wordt de toewijzing gebruikt om gegevensaanvragen naar de juiste shard te routeren. Deze functionaliteit is verborgen achter een reeks API's die zijn opgenomen in de Elastic Database-clientbibliotheek, die beschikbaar is voor Java en .NET.
Zie Uitschalen met Azure SQL Databasevoor meer informatie over elastische pools.
Als u de latentie wilt verminderen en de beschikbaarheid wilt verbeteren, kunt u de globale database van shard-toewijzingsbeheer repliceren. Met de Premium-prijscategorieën kunt u actieve geo-replicatie configureren om continu gegevens naar databases in verschillende regio's te kopiëren.
U kunt ook Azure SQL Data Sync of Azure Data Factory gebruiken om de shard-toewijzingsbeheerdatabase te repliceren in verschillende regio's. Deze vorm van replicatie wordt periodiek uitgevoerd en is geschikter als de shard-toewijzing onregelmatig verandert en geen Premium-laag vereist.
Elastic Database biedt twee schema's voor het toewijzen van gegevens aan shardlets en het opslaan ervan in shards:
Een lijst-shardtoewijzing koppelt één sleutel aan een shardlet. In een systeem met meerdere tenants kunnen de gegevens voor elke tenant bijvoorbeeld worden gekoppeld aan een unieke sleutel en worden opgeslagen in een eigen shardlet. Om isolatie te garanderen, kan elke shardlet binnen een eigen shard worden bewaard.

Download een Visio-bestand van dit diagram.
Een bereik-shardtoewijzing koppelt een set aaneengesloten sleutelwaarden aan een shardlet. U kunt bijvoorbeeld de gegevens groeperen voor een set tenants (elk met een eigen sleutel) binnen dezelfde shardlet. Dit schema is minder duur dan de eerste, omdat tenants gegevensopslag delen, maar minder isolatie hebben.

Een Visio-bestand downloaden van dit diagram
Eén shard kan de gegevens voor verschillende shardlets bevatten. U kunt bijvoorbeeld lijst-shardlets gebruiken om gegevens op te slaan voor verschillende niet-aaneengesloten tenants in dezelfde shard. U kunt ook bereik-shardlets en lijst-shardlets in dezelfde shard combineren, hoewel ze worden aangepakt via verschillende kaarten. In het volgende diagram ziet u deze benadering:

Download een Visio-bestand van dit diagram.
Elastische pools maken het mogelijk om shards toe te voegen en te verwijderen naarmate het volume aan gegevens afneemt en groeit. Clienttoepassingen kunnen shards dynamisch maken en verwijderen en transparant het shard-toewijzingsbeheer bijwerken. Het verwijderen van een shard is echter een destructieve bewerking waarvoor ook alle gegevens in die shard moeten worden verwijderd.
Als een toepassing een shard moet splitsen in twee afzonderlijke shards of shards moet combineren, gebruikt u het hulpprogramma voor splitsen en samenvoegen . Dit hulpprogramma wordt uitgevoerd als een Azure-webservice en migreert gegevens veilig tussen shards.
Het partitioneringsschema kan de prestaties van uw systeem aanzienlijk beïnvloeden. Het kan ook van invloed zijn op de snelheid waarmee shards moeten worden toegevoegd of verwijderd, of dat gegevens opnieuw moeten worden gepartitioneerd tussen shards. Houd rekening met de volgende punten:
Groepeer gegevens die samen worden gebruikt in dezelfde shard en vermijd bewerkingen die toegang hebben tot gegevens uit meerdere shards. Een shard is een SQL-database op eigen recht en joins tussen databases moeten aan de clientzijde worden uitgevoerd.
Hoewel SQL Database geen ondersteuning biedt voor joins tussen databases, kunt u de elastic database-hulpprogramma's gebruiken om query's met meerdere shards uit te voeren. Een multi-shardquery verzendt afzonderlijke query's naar elke database en voegt de resultaten samen.
Ontwerp geen systeem met afhankelijkheden tussen shards. Beperkingen voor referentiële integriteit, triggers en opgeslagen procedures in de ene database kunnen niet verwijzen naar objecten in een andere database.
Als u referentiegegevens hebt die vaak door query's worden gebruikt, kunt u overwegen deze gegevens over shards te repliceren. Met deze methode kunt u de noodzaak om gegevens aan meerdere databases toe te voegen, verwijderen. In het ideale geval moeten dergelijke gegevens statisch of langzaam worden verplaatst, om de replicatie-inspanning te minimaliseren en de kans op verlopen gegevens te verminderen.
Shardlets die deel uitmaken van dezelfde shard-toewijzing moeten hetzelfde schema hebben. Deze regel wordt niet afgedwongen door SQL Database, maar gegevensbeheer en query's worden erg complex als elke shardlet een ander schema heeft. Maak in plaats daarvan afzonderlijke shard-toewijzingen voor elk schema. Houd er rekening mee dat gegevens die tot verschillende shardlets behoren, in dezelfde shard kunnen worden opgeslagen.
Transactionele bewerkingen worden alleen ondersteund voor gegevens binnen een shard en niet voor shards. Transacties kunnen shardlets omvatten zolang ze deel uitmaken van dezelfde shard. Dus als uw bedrijfslogica transacties moet uitvoeren, slaat u de gegevens op in dezelfde shard of implementeert u uiteindelijke consistentie.
Plaats shards dicht bij de gebruikers die toegang hebben tot de gegevens in die shards. Deze strategie helpt de latentie te verminderen.
Vermijd een combinatie van zeer actieve en relatief inactieve shards. Probeer de belasting gelijkmatig over shards te verdelen. Hiervoor moeten de shardingsleutels mogelijk worden gehasht. Als u shards geolocatiet, moet u ervoor zorgen dat de hash-sleutels worden toegewezen aan shardlets die zijn opgeslagen in shards die dicht bij de gebruikers zijn opgeslagen die toegang hebben tot die gegevens.
Azure Table Storage partitioneren
Azure Table Storage is een sleutel-waardearchief dat is ontworpen rond partitionering. Alle entiteiten worden opgeslagen in een partitie en partities worden intern beheerd door Azure Table Storage. Elke entiteit die in een tabel is opgeslagen, moet een tweeledige sleutel opgeven die het volgende omvat:
de partitiesleutel. Dit is een tekenreekswaarde waarmee de partitie wordt bepaald waar Azure Table Storage de entiteit plaatst. Alle entiteiten met dezelfde partitiesleutel worden opgeslagen in dezelfde partitie.
De rijsleutel. Dit is een tekenreekswaarde die de entiteit binnen de partitie identificeert. Alle entiteiten binnen een partitie worden lexisch gesorteerd, in oplopende volgorde, op deze sleutel. De combinatie van de partitiesleutel/rijsleutel moet uniek zijn voor elke entiteit en mag niet langer zijn dan 1 kB.
Als een entiteit wordt toegevoegd aan een tabel met een eerder ongebruikte partitiesleutel, maakt Azure Table Storage een nieuwe partitie voor deze entiteit. Andere entiteiten met dezelfde partitiesleutel worden opgeslagen in dezelfde partitie.
Met dit mechanisme wordt effectief een automatische uitschaalstrategie geïmplementeerd. Elke partitie wordt op dezelfde server opgeslagen in een Azure-datacenter om ervoor te zorgen dat query's die gegevens ophalen uit één partitie snel worden uitgevoerd.
Microsoft heeft schaalbaarheidsdoelen gepubliceerd voor Azure Storage. Als uw systeem deze limieten waarschijnlijk overschrijdt, kunt u overwegen om entiteiten in meerdere tabellen te splitsen. Gebruik verticale partitionering om de velden te verdelen in de groepen die waarschijnlijk samen worden geopend.
In het volgende diagram ziet u de logische structuur van een voorbeeldopslagaccount. Het opslagaccount bevat drie tabellen: Klantgegevens, Productgegevens en Ordergegevens.
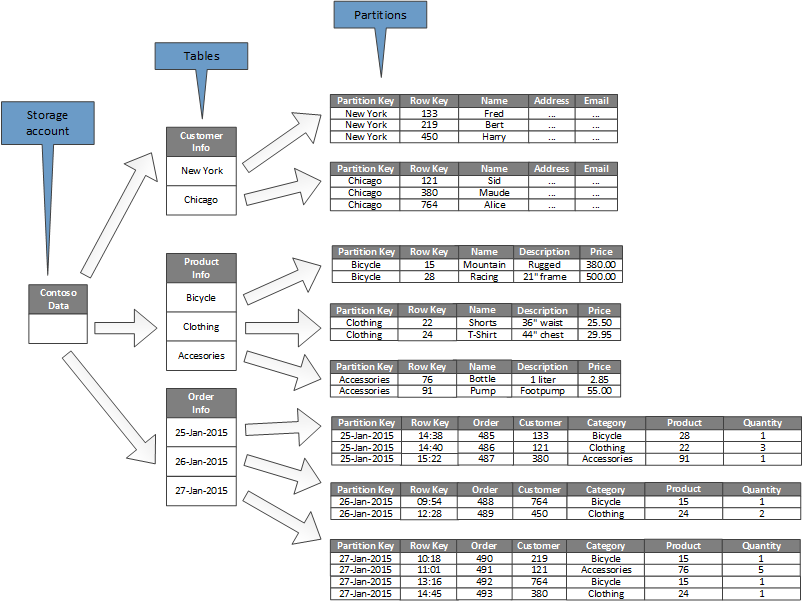
Elke tabel heeft meerdere partities.
- In de tabel Klantgegevens worden de gegevens gepartitioneerd op basis van de plaats waar de klant zich bevindt. De rijsleutel bevat de klant-id.
- In de tabel Productgegevens worden producten gepartitioneerd op productcategorie en bevat de rijcode het productnummer.
- In de tabel Ordergegevens worden de orders gepartitioneerd op orderdatum en geeft de rijsleutel de tijd aan waarop de order is ontvangen. Alle gegevens worden geordend op basis van de rijsleutel in elke partitie.
Houd rekening met de volgende punten wanneer u uw entiteiten ontwerpt voor Azure Table Storage:
Selecteer een partitiesleutel en rijsleutel door hoe de gegevens worden geopend. Kies een combinatie van partitiesleutels/rijtoetsen die het merendeel van uw query's ondersteunt. De meest efficiënte query's halen gegevens op door de partitiesleutel en de rijsleutel op te geven. Query's die een partitiesleutel en een bereik met rijsleutels opgeven, kunnen worden voltooid door één partitie te scannen. Dit is relatief snel omdat de gegevens in rijsleutelvolgorde worden opgeslagen. Als query's niet opgeven welke partitie moet worden gescand, moet elke partitie worden gescand.
Als een entiteit één natuurlijke sleutel heeft, gebruikt u deze als partitiesleutel en geeft u een lege tekenreeks op als rijsleutel. Als een entiteit een samengestelde sleutel heeft die bestaat uit twee eigenschappen, selecteert u de langzaamst veranderende eigenschap als de partitiesleutel en de andere als rijsleutel. Als een entiteit meer dan twee sleuteleigenschappen heeft, gebruikt u een samenvoeging van eigenschappen om de partitie- en rijsleutels op te geven.
Als u regelmatig query's uitvoert waarmee gegevens worden opgezoekd met behulp van andere velden dan de partitie- en rijsleutels, kunt u overwegen het patroon indextabel te implementerenof een ander gegevensarchief te gebruiken dat indexering ondersteunt, zoals Azure Cosmos DB.
Als u partitiesleutels genereert met behulp van een monotone reeks (zoals '0001', '0002', '0003') en elke partitie slechts een beperkte hoeveelheid gegevens bevat, kan Azure Table Storage deze partities fysiek groeperen op dezelfde server. In Azure Storage wordt ervan uitgegaan dat de toepassing waarschijnlijk query's uitvoert voor een aaneengesloten bereik van partities (bereikquery's) en is geoptimaliseerd voor dit geval. Deze aanpak kan echter leiden tot hotspots, omdat alle invoegingen van nieuwe entiteiten waarschijnlijk aan één uiteinde het aaneengesloten bereik zijn geconcentreerd. Het kan ook de schaalbaarheid verminderen. Als u de belasting gelijkmatiger wilt verdelen, kunt u overwegen om de partitiesleutel te hashen.
Azure Table Storage ondersteunt transactionele bewerkingen voor entiteiten die deel uitmaken van dezelfde partitie. Een toepassing kan meerdere bewerkingen voor invoegen, bijwerken, verwijderen, vervangen of samenvoegen uitvoeren als een atomische eenheid, zolang de transactie niet meer dan 100 entiteiten bevat en de nettolading van de aanvraag niet groter is dan 4 MB. Bewerkingen die meerdere partities omvatten, zijn niet transactioneel en vereisen mogelijk dat u uiteindelijke consistentie implementeert. Zie Entiteitsgroeptransacties uitvoerenvoor meer informatie over tabelopslag en transacties.
Houd rekening met de granulariteit van de partitiesleutel:
Het gebruik van dezelfde partitiesleutel voor elke entiteit resulteert in één partitie die op één server wordt bewaard. Hiermee voorkomt u dat de partitie wordt uitgeschaald en wordt de belasting op één server gericht. Als gevolg hiervan is deze benadering alleen geschikt voor het opslaan van een klein aantal entiteiten. Het zorgt er echter voor dat alle entiteiten kunnen deelnemen aan entiteitsgroeptransacties.
Als u een unieke partitiesleutel gebruikt voor elke entiteit, zorgt u ervoor dat de table storage-service een afzonderlijke partitie voor elke entiteit maakt, wat mogelijk resulteert in een groot aantal kleine partities. Deze benadering is schaalbaarder dan het gebruik van één partitiesleutel, maar entiteitsgroeptransacties zijn niet mogelijk. Query's die meer dan één entiteit ophalen, kunnen ook betrekking hebben op het lezen van meer dan één server. Als de toepassing echter bereikquery's uitvoert, kan het gebruik van een monotone reeks voor de partitiesleutels helpen om deze query's te optimaliseren.
Als u de partitiesleutel deelt in een subset van entiteiten, kunt u gerelateerde entiteiten in dezelfde partitie groeperen. Bewerkingen die betrekking hebben op gerelateerde entiteiten kunnen worden uitgevoerd met behulp van entiteitsgroeptransacties en query's die een set gerelateerde entiteiten ophalen, kunnen worden voldaan door toegang te krijgen tot één server.
Zie ontwerphandleiding voor Azure Storage-tabellen en Schaalbare partitioneringsstrategievoor meer informatie.
Azure Blob Storage partitioneren
Met Azure Blob Storage kunt u grote binaire objecten opslaan. Gebruik blok-blobs in scenario's wanneer u snel grote hoeveelheden gegevens moet uploaden of downloaden. Gebruik pagina-blobs voor toepassingen waarvoor willekeurige in plaats van seriële toegang tot delen van de gegevens is vereist.
Elke blob (blok of pagina) wordt bewaard in een container in een Azure Storage-account. U kunt containers gebruiken om gerelateerde blobs te groeperen die dezelfde beveiligingsvereisten hebben. Deze groepering is logisch in plaats van fysiek. In een container heeft elke blob een unieke naam.
De partitiesleutel voor een blob is accountnaam + containernaam + blobnaam. De partitiesleutel wordt gebruikt om gegevens te partitioneren in bereiken en deze bereiken worden verdeeld over het systeem. Blobs kunnen op veel servers worden gedistribueerd om de toegang tot deze servers uit te schalen, maar één blob kan alleen worden bediend door één server.
Als uw naamgevingsschema tijdstempels of numerieke id's gebruikt, kan dit leiden tot overmatig verkeer naar één partitie, waardoor het systeem wordt beperkt tot effectieve taakverdeling. Als u bijvoorbeeld dagelijkse bewerkingen hebt die gebruikmaken van een blobobject met een tijdstempel zoals jjjj-mm-dd, wordt al het verkeer voor die bewerking naar één partitieserver verzonden. In plaats daarvan kunt u de naam vooraf laten gaan door een hash met drie cijfers. Zie Naamconventie voor partities voor meer informatie.
De acties voor het schrijven van één blok of pagina zijn atomisch, maar bewerkingen die blokken, pagina's of blobs omvatten, zijn dat niet. Als u consistentie wilt garanderen bij het uitvoeren van schrijfbewerkingen tussen blokken, pagina's en blobs, moet u een schrijfvergrendeling uitschakelen met behulp van een bloblease.
Azure Storage-wachtrijen partitioneren
Met Azure Storage-wachtrijen kunt u asynchrone berichten tussen processen implementeren. Een Azure Storage-account kan een willekeurig aantal wachtrijen bevatten en elke wachtrij kan een willekeurig aantal berichten bevatten. De enige beperking is de ruimte die beschikbaar is in het opslagaccount. De maximale grootte van een afzonderlijk bericht is 64 kB. Als u berichten nodig hebt die groter zijn dan dit, kunt u in plaats daarvan Azure Service Bus-wachtrijen gebruiken.
Elke opslagwachtrij heeft een unieke naam in het opslagaccount dat het bevat. Wachtrijen voor Azure-partities op basis van de naam. Alle berichten voor dezelfde wachtrij worden opgeslagen in dezelfde partitie, die wordt beheerd door één server. Verschillende wachtrijen kunnen worden beheerd door verschillende servers om de belasting te verdelen. De toewijzing van wachtrijen aan servers is transparant voor toepassingen en gebruikers.
Gebruik in een grootschalige toepassing niet dezelfde opslagwachtrij voor alle exemplaren van de toepassing, omdat deze methode ertoe kan leiden dat de server die als host fungeert voor de wachtrij een hot spot wordt. Gebruik in plaats daarvan verschillende wachtrijen voor verschillende functionele gebieden van de toepassing. Azure Storage-wachtrijen bieden geen ondersteuning voor transacties, dus het doorsturen van berichten naar verschillende wachtrijen heeft weinig invloed op de consistentie van berichten.
Een Azure Storage-wachtrij kan maximaal 2000 berichten per seconde verwerken. Als u berichten met een hogere snelheid wilt verwerken, kunt u overwegen om meerdere wachtrijen te maken. Maak bijvoorbeeld in een globale toepassing afzonderlijke opslagwachtrijen in afzonderlijke opslagaccounts om toepassingsexemplaren te verwerken die in elke regio worden uitgevoerd.
Partitionering van Azure Service Bus
Azure Service Bus maakt gebruik van een berichtenbroker voor het afhandelen van berichten die worden verzonden naar een Service Bus-wachtrij of -onderwerp. Standaard worden alle berichten die naar een wachtrij of onderwerp worden verzonden, verwerkt door hetzelfde berichtbrokerproces. Met deze architectuur kan een beperking worden ingesteld voor de totale doorvoer van de berichtenwachtrij. U kunt echter ook een wachtrij of onderwerp partitioneren wanneer deze wordt gemaakt. U doet dit door de eigenschap EnablePartitioning van de wachtrij of onderwerpbeschrijving in te stellen op true.
Een gepartitioneerde wachtrij of onderwerp is onderverdeeld in meerdere fragmenten, die elk worden ondersteund door een afzonderlijk berichtenarchief en berichtenbroker. Service Bus neemt de verantwoordelijkheid voor het maken en beheren van deze fragmenten. Wanneer een toepassing een bericht plaatst in een gepartitioneerde wachtrij of onderwerp, wijst Service Bus het bericht toe aan een fragment voor die wachtrij of dat onderwerp. Wanneer een toepassing een bericht ontvangt van een wachtrij of abonnement, controleert Service Bus elk fragment op het volgende beschikbare bericht en geeft deze vervolgens door aan de toepassing voor verwerking.
Deze structuur helpt de belasting over berichtbrokers en berichtenarchieven te verdelen, de schaalbaarheid te vergroten en de beschikbaarheid te verbeteren. Als de berichtenbroker of het berichtenarchief voor één fragment tijdelijk niet beschikbaar is, kan Service Bus berichten ophalen uit een van de resterende beschikbare fragmenten.
Service Bus wijst als volgt een bericht toe aan een fragment:
Als het bericht deel uitmaakt van een sessie, worden alle berichten met dezelfde waarde voor de eigenschap SessionId naar hetzelfde fragment verzonden.
Als het bericht niet bij een sessie hoort, maar de afzender een waarde heeft opgegeven voor de eigenschap PartitionKey, worden alle berichten met dezelfde PartitionKey waarde naar hetzelfde fragment verzonden.
Notitie
Als de eigenschappen SessionId en PartitionKey beide zijn opgegeven, moeten ze worden ingesteld op dezelfde waarde of wordt het bericht geweigerd.
Als de eigenschappen SessionId en PartitionKey voor een bericht niet zijn opgegeven, maar dubbele detectie is ingeschakeld, wordt de eigenschap MessageId gebruikt. Alle berichten met dezelfde MessageId worden doorgestuurd naar hetzelfde fragment.
Als berichten geen SessionId, PartitionKey, of eigenschap MessageId bevatten, wijst Service Bus berichten opeenvolgend toe aan fragmenten. Als een fragment niet beschikbaar is, gaat Service Bus verder met de volgende. Dit betekent dat een tijdelijke fout in de berichteninfrastructuur ervoor zorgt dat de berichtverzendingsbewerking niet mislukt.
Houd rekening met de volgende punten bij het bepalen of u een Service Bus-berichtenwachtrij of -onderwerp wilt partitioneren:
Service Bus-wachtrijen en -onderwerpen worden gemaakt binnen het bereik van een Service Bus-naamruimte. Service Bus staat momenteel maximaal 100 gepartitioneerde wachtrijen of onderwerpen per naamruimte toe.
Elke Service Bus-naamruimte legt quota op voor de beschikbare resources, zoals het aantal abonnementen per onderwerp, het aantal gelijktijdige verzend- en ontvangstaanvragen per seconde en het maximum aantal gelijktijdige verbindingen dat tot stand kan worden gebracht. Deze quota worden beschreven in Service Bus-quota's. Als u verwacht deze waarden te overschrijden, maakt u extra naamruimten met hun eigen wachtrijen en onderwerpen en verspreidt u het werk over deze naamruimten. Maak in een globale toepassing bijvoorbeeld afzonderlijke naamruimten in elke regio en configureer toepassingsexemplaren om de wachtrijen en onderwerpen in de dichtstbijzijnde naamruimte te gebruiken.
Berichten die worden verzonden als onderdeel van een transactie moeten een partitiesleutel opgeven. Dit kan een SessionId, PartitionKeyof eigenschap MessageId zijn. Alle berichten die als onderdeel van dezelfde transactie worden verzonden, moeten dezelfde partitiesleutel opgeven, omdat ze moeten worden verwerkt door hetzelfde berichtenbrokerproces. U kunt geen berichten verzenden naar verschillende wachtrijen of onderwerpen binnen dezelfde transactie.
Gepartitioneerde wachtrijen en onderwerpen kunnen niet worden geconfigureerd om automatisch te worden verwijderd wanneer ze niet actief worden.
Gepartitioneerde wachtrijen en onderwerpen kunnen momenteel niet worden gebruikt met het Advanced Message Queuing Protocol (AMQP) als u platformoverschrijdende of hybride oplossingen bouwt.
Partitioneren van Azure Cosmos DB
Azure Cosmos DB for NoSQL- is een NoSQL-database voor het opslaan van JSON-documenten. Een document in een Azure Cosmos DB-database is een JSON-geserialiseerde weergave van een object of ander stukje gegevens. Er worden geen vaste schema's afgedwongen, behalve dat elk document een unieke id moet bevatten.
Documenten zijn ingedeeld in verzamelingen. U kunt gerelateerde documenten in een verzameling groeperen. In een systeem dat bijvoorbeeld blogposts onderhoudt, kunt u de inhoud van elk blogbericht opslaan als een document in een verzameling. U kunt ook verzamelingen maken voor elk onderwerptype. U kunt ook in een multitenant-toepassing, zoals een systeem waarin verschillende auteurs hun eigen blogberichten beheren, blogs partitioneren op auteur en afzonderlijke verzamelingen maken voor elke auteur. De opslagruimte die aan verzamelingen is toegewezen, is elastisch en kan naar behoefte verkleinen of vergroten.
Azure Cosmos DB biedt ondersteuning voor het automatisch partitioneren van gegevens op basis van een door de toepassing gedefinieerde partitiesleutel. Een logische partitie is een partitie waarin alle gegevens voor één partitiesleutelwaarde worden opgeslagen. Alle documenten die dezelfde waarde voor de partitiesleutel delen, worden binnen dezelfde logische partitie geplaatst. Azure Cosmos DB distribueert waarden volgens hash van de partitiesleutel. Een logische partitie heeft een maximale grootte van 20 GB. Daarom is de keuze van de partitiesleutel een belangrijke beslissing tijdens het ontwerp. Kies een eigenschap met een breed scala aan waarden en zelfs toegangspatronen. Zie Partition and scale in Azure Cosmos DBvoor meer informatie.
Notitie
Elke Azure Cosmos DB-database heeft een prestatieniveau waarmee wordt bepaald hoeveel resources deze krijgt. Een prestatieniveau is gekoppeld aan een aanvraageenheid (RU) frequentielimiet. De RU-frequentielimiet specificeert het volume van resources dat is gereserveerd en beschikbaar is voor exclusief gebruik door die verzameling. De kosten van een verzameling zijn afhankelijk van het prestatieniveau dat voor die verzameling is geselecteerd. Hoe hoger het prestatieniveau (en ru-frequentielimiet) hoe hoger de kosten. U kunt het prestatieniveau van een verzameling aanpassen met behulp van Azure Portal. Zie aanvraageenheden in Azure Cosmos DBvoor meer informatie.
Als het partitioneringsmechanisme dat Azure Cosmos DB biedt niet voldoende is, moet u de gegevens mogelijk sharden op toepassingsniveau. Documentverzamelingen bieden een natuurlijk mechanisme voor het partitioneren van gegevens in één database. De eenvoudigste manier om sharding te implementeren, is door voor elke shard een verzameling te maken. Containers zijn logische resources en kunnen een of meer servers omvatten. Containers met een vaste grootte hebben een maximale doorvoer van 20 GB en 10.000 RU/s. Onbeperkte containers hebben geen maximale opslaggrootte, maar moeten een partitiesleutel opgeven. Met sharding van toepassingen moet de clienttoepassing aanvragen doorsturen naar de juiste shard, meestal door een eigen toewijzingsmechanisme te implementeren op basis van bepaalde kenmerken van de gegevens die de shardsleutel definiëren.
Alle databases worden gemaakt in de context van een Azure Cosmos DB-databaseaccount. Eén account kan meerdere databases bevatten en geeft aan in welke regio's de databases worden gemaakt. Elk account dwingt ook een eigen toegangsbeheer af. U kunt Azure Cosmos DB-accounts gebruiken om shards (verzamelingen binnen databases) dicht bij de gebruikers te vinden die toegang nodig hebben en beperkingen af te dwingen, zodat alleen die gebruikers verbinding met hen kunnen maken.
Houd rekening met de volgende punten bij het bepalen hoe u gegevens partitioneert met Azure Cosmos DB for NoSQL:
De resources die beschikbaar zijn voor een Azure Cosmos DB-database, zijn onderhevig aan de quotumbeperkingen van het account. Elke database kan een aantal verzamelingen bevatten en elke verzameling is gekoppeld aan een prestatieniveau dat de RU-frequentielimiet (gereserveerde doorvoer) voor die verzameling bepaalt. Zie Azure-abonnements- en servicelimieten, quota en beperkingenvoor meer informatie.
Elk document moet een kenmerk hebben dat kan worden gebruikt om dat document uniek te identificeren in de verzameling waarin het wordt bewaard. Dit kenmerk verschilt van de shardsleutel, waarmee wordt gedefinieerd welke verzameling het document bevat. Een verzameling kan een groot aantal documenten bevatten. In theorie is het alleen beperkt door de maximale lengte van de document-id. De document-id mag maximaal 255 tekens bevatten.
Alle bewerkingen op basis van een document worden uitgevoerd binnen de context van een transactie. Transacties zijn gericht op de verzameling waarin het document zich bevindt. Als een bewerking mislukt, wordt het uitgevoerde werk teruggedraaid. Hoewel een document onderhevig is aan een bewerking, zijn alle aangebrachte wijzigingen onderhevig aan isolatie op momentopnameniveau. Dit mechanisme garandeert dat als bijvoorbeeld een aanvraag voor het maken van een nieuw document mislukt, een andere gebruiker die tegelijkertijd een query op de database uitvoert, geen gedeeltelijk document ziet dat vervolgens wordt verwijderd.
Databasequery's zijn ook gericht op het verzamelingsniveau. Eén query kan gegevens ophalen uit slechts één verzameling. Als u gegevens uit meerdere verzamelingen wilt ophalen, moet u elke verzameling afzonderlijk opvragen en de resultaten samenvoegen in uw toepassingscode.
Azure Cosmos DB ondersteunt programmeerbare items die allemaal kunnen worden opgeslagen in een verzameling naast documenten. Deze omvatten opgeslagen procedures, door de gebruiker gedefinieerde functies en triggers (geschreven in JavaScript). Deze items hebben toegang tot elk document binnen dezelfde verzameling. Bovendien worden deze items uitgevoerd binnen het bereik van de omgevingstransactie (in het geval van een trigger die wordt geactiveerd als gevolg van een bewerking voor maken, verwijderen of vervangen die wordt uitgevoerd op basis van een document), of door een nieuwe transactie te starten (in het geval van een opgeslagen procedure die wordt uitgevoerd als gevolg van een expliciete clientaanvraag). Als de code in een programmeerbare item een uitzondering genereert, wordt de transactie teruggedraaid. U kunt opgeslagen procedures en triggers gebruiken om integriteit en consistentie tussen documenten te behouden, maar deze documenten moeten allemaal deel uitmaken van dezelfde verzameling.
De verzamelingen die u in de databases wilt opslaan, moeten waarschijnlijk niet de doorvoerlimieten overschrijden die zijn gedefinieerd door de prestatieniveaus van de verzamelingen. Zie aanvraageenheden in Azure Cosmos DBvoor meer informatie. Als u verwacht deze limieten te bereiken, kunt u overwegen om verzamelingen over databases in verschillende accounts te splitsen om de belasting per verzameling te verminderen.
Partitionering van Azure AI Search
De mogelijkheid om te zoeken naar gegevens is vaak de primaire methode voor navigatie en verkenning die wordt geboden door veel webtoepassingen. Hiermee kunnen gebruikers snel resources vinden (bijvoorbeeld producten in een e-commercetoepassing) op basis van combinaties van zoekcriteria. De AI Search-service biedt zoekmogelijkheden voor volledige tekst via webinhoud en bevat functies zoals type-ahead, voorgestelde query's op basis van bijna-overeenkomsten en facetnavigatie. Zie Wat is AI Search?.
AI Search slaat doorzoekbare inhoud op als JSON-documenten in een database. U definieert indexen die de doorzoekbare velden in deze documenten opgeven en deze definities verstrekken aan AI Search. Wanneer een gebruiker een zoekaanvraag indient, gebruikt AI Search de juiste indexen om overeenkomende items te vinden.
Om conflicten te verminderen, kan de opslag die wordt gebruikt door AI Search worden onderverdeeld in 1, 2, 3, 4, 6 of 12 partities, en elke partitie kan maximaal 6 keer worden gerepliceerd. Het product van het aantal partities vermenigvuldigd met het aantal replica's wordt de zoekeenheid (SU)genoemd. Eén exemplaar van AI Search kan maximaal 36 RU's bevatten (een database met 12 partities ondersteunt maximaal 3 replica's).
U wordt gefactureerd voor elke SU die aan uw service is toegewezen. Naarmate het volume van doorzoekbare inhoud toeneemt of de snelheid van zoekaanvragen toeneemt, kunt u SU's toevoegen aan een bestaand exemplaar van AI Search om de extra belasting af te handelen. AI Search zelf distribueert de documenten gelijkmatig over de partities. Er worden momenteel geen handmatige partitioneringsstrategieën ondersteund.
Elke partitie kan maximaal 15 miljoen documenten bevatten of 300 GB opslagruimte in beslag nemen (afhankelijk van wat kleiner is). U kunt maximaal 50 indexen maken. De prestaties van de service variëren en zijn afhankelijk van de complexiteit van de documenten, de beschikbare indexen en de gevolgen van netwerklatentie. Gemiddeld moet één replica (1 SU) 15 query's per seconde (QPS) kunnen verwerken, hoewel het raadzaam is om benchmarking uit te voeren met uw eigen gegevens om een nauwkeurigere meting van doorvoer te verkrijgen. Zie Service-limieten in AI Searchvoor meer informatie.
Notitie
U kunt een beperkte set gegevenstypen opslaan in doorzoekbare documenten, waaronder tekenreeksen, Booleaanse waarden, numerieke gegevens, datum/tijd-gegevens en enkele geografische gegevens. Zie de pagina Ondersteunde gegevenstypen (AI Search) op de Website van Microsoft voor meer informatie.
U hebt beperkte controle over hoe AI Search gegevens partitioneert voor elk exemplaar van de service. In een globale omgeving kunt u echter mogelijk de prestaties verbeteren en latentie en conflicten verder verminderen door de service zelf te partitioneren met behulp van een van de volgende strategieën:
Maak een exemplaar van AI Search in elke geografische regio en zorg ervoor dat clienttoepassingen worden omgeleid naar het dichtstbijzijnde beschikbare exemplaar. Deze strategie vereist dat updates voor doorzoekbare inhoud tijdig worden gerepliceerd in alle exemplaren van de service.
Maak twee lagen van AI Search:
- Een lokale service in elke regio die de gegevens bevat die het vaakst worden geopend door gebruikers in die regio. Gebruikers kunnen hier aanvragen voor snelle maar beperkte resultaten doorsturen.
- Een globale service die alle gegevens omvat. Gebruikers kunnen hier aanvragen doorsturen voor tragere maar volledigere resultaten.
Deze methode is het meest geschikt wanneer er een aanzienlijke regionale variatie is in de gegevens die worden doorzocht.
Partitioneren van Azure Cache voor Redis
Azure Cache voor Redis biedt een gedeelde cacheservice in de cloud die is gebaseerd op het redis-sleutel-waardegegevensarchief. Zoals de naam al aangeeft, is Azure Cache voor Redis bedoeld als een cacheoplossing. Gebruik deze alleen voor het opslaan van tijdelijke gegevens en niet als een permanent gegevensarchief. Toepassingen die gebruikmaken van Azure Cache voor Redis, moeten kunnen blijven functioneren als de cache niet beschikbaar is. Azure Cache voor Redis ondersteunt primaire/secundaire replicatie om hoge beschikbaarheid te bieden, maar beperkt momenteel de maximale cachegrootte tot 53 GB. Als u meer ruimte nodig hebt dan dit, moet u extra caches maken. Zie Azure Cache voor Redis voor meer informatie.
Het partitioneren van een Redis-gegevensarchief omvat het splitsen van de gegevens tussen exemplaren van de Redis-service. Elk exemplaar vormt één partitie. Azure Cache voor Redis abstraheert de Redis-services achter een gevel en maakt ze niet rechtstreeks beschikbaar. De eenvoudigste manier om partitionering te implementeren, is door meerdere Exemplaren van Azure Cache voor Redis te maken en de gegevens over deze exemplaren te verdelen.
U kunt elk gegevensitem koppelen aan een id (een partitiesleutel) die aangeeft welke cache het gegevensitem opslaat. De logica van de clienttoepassing kan deze id vervolgens gebruiken om aanvragen naar de juiste partitie te routeren. Dit schema is heel eenvoudig, maar als het partitioneringsschema verandert (bijvoorbeeld als er extra Exemplaren van Azure Cache voor Redis worden gemaakt), moeten clienttoepassingen mogelijk opnieuw worden geconfigureerd.
Systeemeigen Redis (niet Azure Cache voor Redis) ondersteunt partitionering aan de serverzijde op basis van Redis-clustering. In deze benadering kunt u de gegevens gelijkmatig verdelen over servers met behulp van een hash-mechanisme. Elke Redis-server slaat metagegevens op die het bereik van hashsleutels beschrijft die de partitie bevat en bevat ook informatie over welke hash-sleutels zich in de partities op andere servers bevinden.
Clienttoepassingen verzenden eenvoudig aanvragen naar een van de deelnemende Redis-servers (waarschijnlijk het dichtstbijzijnde). De Redis-server onderzoekt de clientaanvraag. Als het lokaal kan worden opgelost, wordt de aangevraagde bewerking uitgevoerd. Anders wordt de aanvraag doorgestuurd naar de juiste server.
Dit model wordt geïmplementeerd met behulp van Redis-clustering en wordt uitgebreid beschreven in de zelfstudie Redis-cluster pagina op de Redis-website. Redis-clustering is transparant voor clienttoepassingen. Extra Redis-servers kunnen worden toegevoegd aan het cluster (en de gegevens kunnen opnieuw worden gepartitioneerd) zonder dat u de clients opnieuw hoeft te configureren.
Belangrijk
Azure Cache voor Redis ondersteunt momenteel alleen Redis-clustering in premium-laag.
De pagina Partitionering: het splitsen van gegevens tussen meerdere Redis-exemplaren op de Redis-website biedt meer informatie over het implementeren van partitionering met Redis. In de rest van deze sectie wordt ervan uitgegaan dat u partitionering aan de clientzijde of proxy-ondersteuning implementeert.
Houd rekening met de volgende punten bij het bepalen hoe u gegevens partitioneren met Azure Cache voor Redis:
Azure Cache voor Redis is niet bedoeld om te fungeren als een permanent gegevensarchief, dus ongeacht het partitioneringsschema dat u implementeert, moet uw toepassingscode gegevens kunnen ophalen van een locatie die niet de cache is.
Gegevens die vaak samen worden geopend, moeten in dezelfde partitie worden bewaard. Redis is een krachtig sleutel-waardearchief dat verschillende sterk geoptimaliseerde mechanismen biedt voor het structureren van gegevens. Deze mechanismen kunnen een van de volgende zijn:
- Eenvoudige tekenreeksen (binaire gegevens tot 512 MB lang)
- Geaggregeerde typen, zoals lijsten (die kunnen fungeren als wachtrijen en stacks)
- Sets (geordende en ongeordend)
- Hashes (waarmee gerelateerde velden kunnen worden gegroepeerd, zoals de items die de velden in een object vertegenwoordigen)
Met de statistische typen kunt u veel gerelateerde waarden koppelen aan dezelfde sleutel. Een Redis-sleutel identificeert een lijst, set of hash in plaats van de gegevensitems die deze bevat. Deze typen zijn allemaal beschikbaar met Azure Cache voor Redis en worden beschreven door de Gegevenstypen pagina op de Redis-website. In een deel van een e-commercesysteem dat bijvoorbeeld de orders bijhoudt die door klanten worden geplaatst, kunnen de details van elke klant worden opgeslagen in een Redis-hash die wordt gesleuteld met behulp van de klant-id. Elke hash kan een verzameling order-id's voor de klant bevatten. Een afzonderlijke Redis-set kan de orders bevatten, opnieuw gestructureerd als hashes en worden gesleuteld met behulp van de order-id. In afbeelding 8 ziet u deze structuur. Redis implementeert geen vorm van referentiële integriteit, dus het is de verantwoordelijkheid van de ontwikkelaar om de relaties tussen klanten en orders te onderhouden.
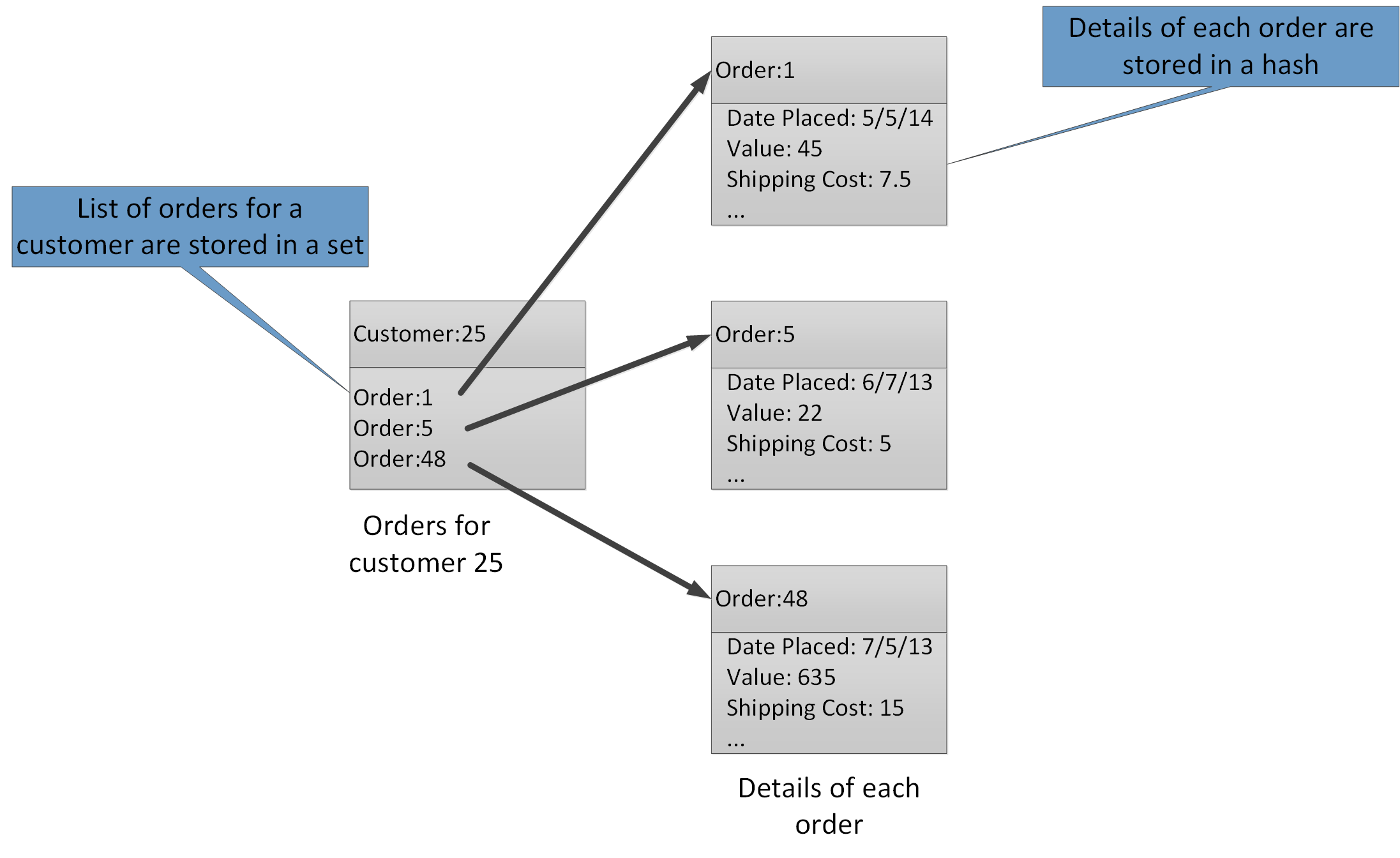
Afbeelding 8. Voorgestelde structuur in Redis-opslag voor het vastleggen van klantorders en hun details.
Notitie
In Redis zijn alle sleutels binaire gegevenswaarden (zoals Redis-tekenreeksen) en kunnen ze maximaal 512 MB aan gegevens bevatten. In theorie kan een sleutel vrijwel elke informatie bevatten. We raden u echter aan een consistente naamconventie te gebruiken voor sleutels die beschrijvend zijn voor het type gegevens en waarmee de entiteit wordt geïdentificeerd, maar niet te lang is. Een veelvoorkomende benadering is het gebruik van sleutels van het formulier 'entity_type:ID'. U kunt bijvoorbeeld 'customer:99' gebruiken om de sleutel voor een klant aan te geven met de id 99.
U kunt verticale partitionering implementeren door gerelateerde informatie op te slaan in verschillende aggregaties in dezelfde database. In een e-commercetoepassing kunt u bijvoorbeeld veelgebruikte informatie over producten opslaan in één Redis-hash en minder vaak gebruikte gedetailleerde informatie in een andere. Beide hashes kunnen dezelfde product-id gebruiken als onderdeel van de sleutel. U kunt bijvoorbeeld 'product: nn' gebruiken (waarbij nn de product-id is) voor de productgegevens en 'product_details: nn' voor de gedetailleerde gegevens. Deze strategie kan helpen bij het verminderen van het aantal gegevens dat de meeste query's waarschijnlijk zullen ophalen.
U kunt een Redis-gegevensarchief opnieuw partitioneren, maar houd er rekening mee dat het een complexe en tijdrovende taak is. Redis-clustering kan gegevens automatisch opnieuw partitioneren, maar deze mogelijkheid is niet beschikbaar met Azure Cache voor Redis. Wanneer u uw partitioneringsschema ontwerpt, moet u daarom voldoende vrije ruimte in elke partitie achterlaten om de verwachte gegevensgroei in de loop van de tijd mogelijk te maken. Houd er echter rekening mee dat Azure Cache voor Redis is bedoeld om gegevens tijdelijk in de cache op te cachen en dat gegevens die in de cache zijn opgeslagen, een beperkte levensduur kunnen hebben die is opgegeven als een TTL-waarde (Time-to-Live). Voor relatief vluchtige gegevens kan de TTL kort zijn, maar voor statische gegevens kan de TTL veel langer zijn. Vermijd het opslaan van grote hoeveelheden langlopende gegevens in de cache als het volume van deze gegevens waarschijnlijk de cache vult. U kunt een verwijderingsbeleid opgeven dat ervoor zorgt dat Azure Cache voor Redis gegevens verwijdert als er ruimte is in een Premium-
Notitie
Wanneer u Azure Cache voor Redis gebruikt, geeft u de maximale grootte van de cache op (van 250 MB tot 53 GB) door de juiste prijscategorie te selecteren. Nadat een Azure Cache voor Redis is gemaakt, kunt u de grootte echter niet vergroten (of verkleinen).
Redis-batches en -transacties kunnen niet meerdere verbindingen omvatten, dus alle gegevens die worden beïnvloed door een batch of transactie, moeten in dezelfde database (shard) worden bewaard.
Notitie
Een reeks bewerkingen in een Redis-transactie is niet noodzakelijkerwijs atomisch. De opdrachten die een transactie opstellen, worden geverifieerd en in de wachtrij geplaatst voordat ze worden uitgevoerd. Als er tijdens deze fase een fout optreedt, wordt de hele wachtrij verwijderd. Nadat de transactie is verzonden, worden de opdrachten in de wachtrij echter op volgorde uitgevoerd. Als een opdracht mislukt, wordt alleen die opdracht niet meer uitgevoerd. Alle vorige en volgende opdrachten in de wachtrij worden uitgevoerd. Ga voor meer informatie naar de pagina Transactions op de Redis-website.
Redis ondersteunt een beperkt aantal atomische bewerkingen. De enige bewerkingen van dit type die ondersteuning bieden voor meerdere sleutels en waarden zijn MGET- en MSET-bewerkingen. MGET-bewerkingen retourneren een verzameling waarden voor een opgegeven lijst met sleutels en MSET-bewerkingen slaan een verzameling waarden op voor een opgegeven lijst met sleutels. Als u deze bewerkingen wilt gebruiken, moeten de sleutel-waardeparen waarnaar wordt verwezen door de MSET- en MGET-opdrachten worden opgeslagen in dezelfde database.
Partitioneren van Azure Service Fabric
Azure Service Fabric is een microservicesplatform dat een runtime biedt voor gedistribueerde toepassingen in de cloud. Service Fabric biedt ondersteuning voor uitvoerbare .NET-gastbestanden, stateful en stateless services en containers. Stateful services bieden een betrouwbare verzameling om gegevens permanent op te slaan in een sleutel-waardeverzameling in het Service Fabric-cluster. Zie Richtlijnen en aanbevelingen voor betrouwbare verzamelingen in Azure Service Fabricvoor meer informatie over strategieën voor het partitioneren van sleutels in een betrouwbare verzameling.
Volgende stappen
Overzicht van Azure Service Fabric- is een inleiding tot Azure Service Fabric.
Reliable Services van Service Fabric partitioneren biedt meer informatie over betrouwbare services in Azure Service Fabric.
Azure Event Hubs partitioneren
Azure Event Hubs is ontworpen voor gegevensstreaming op grote schaal en partitioneren is ingebouwd in de service om horizontaal schalen mogelijk te maken. Elke consument leest alleen een specifieke partitie van de berichtstroom.
De gebeurtenisuitgever is alleen op de hoogte van de partitiesleutel en niet van de partitie waarop de gebeurtenissen worden gepubliceerd. Deze ontkoppeling van sleutel en partitie schermt de afzender af, zodat deze niet te veel te weten hoeft te komen over de downstreamverwerking. (Het is ook mogelijk gebeurtenissen rechtstreeks naar een bepaalde partitie te verzenden, maar over het algemeen wordt dit niet aanbevolen.)
Houd rekening met schaal op lange termijn wanneer u het aantal partities selecteert. Nadat een Event Hub is gemaakt, kunt u het aantal partities niet wijzigen.
Volgende stappen
Zie Wat is Event Hubs voor meer informatie over het gebruik van partities in Event Hubs?.
Zie Beschikbaarheid en consistentie in Event Hubsvoor overwegingen over afwegingen tussen beschikbaarheid en consistentie.