Partitioneren van Service Fabric-betrouwbare services
Dit artikel bevat een inleiding tot de basisconcepten van het partitioneren van betrouwbare services van Azure Service Fabric. Partitioneren maakt gegevensopslag op de lokale machines mogelijk, zodat gegevens en rekenkracht samen kunnen worden geschaald.
Tip
Een volledig voorbeeld van de code in dit artikel is beschikbaar op GitHub.
Partitionering
Partitionering is niet uniek voor Service Fabric. In feite is het een kernpatroon van het bouwen van schaalbare services. In bredere zin kunnen we denken aan partitionering als concept van het verdelen van de status (gegevens) en het berekenen in kleinere toegankelijke eenheden om de schaalbaarheid en prestaties te verbeteren. Een bekende vorm van partitionering is gegevenspartitionering, ook wel bekend als sharding.
Stateless Service Fabric-services partitioneren
Voor stateless services kunt u denken aan een partitie die een logische eenheid is die een of meer exemplaren van een service bevat. In afbeelding 1 ziet u een staatloze service met vijf exemplaren die zijn verdeeld over een cluster met één partitie.
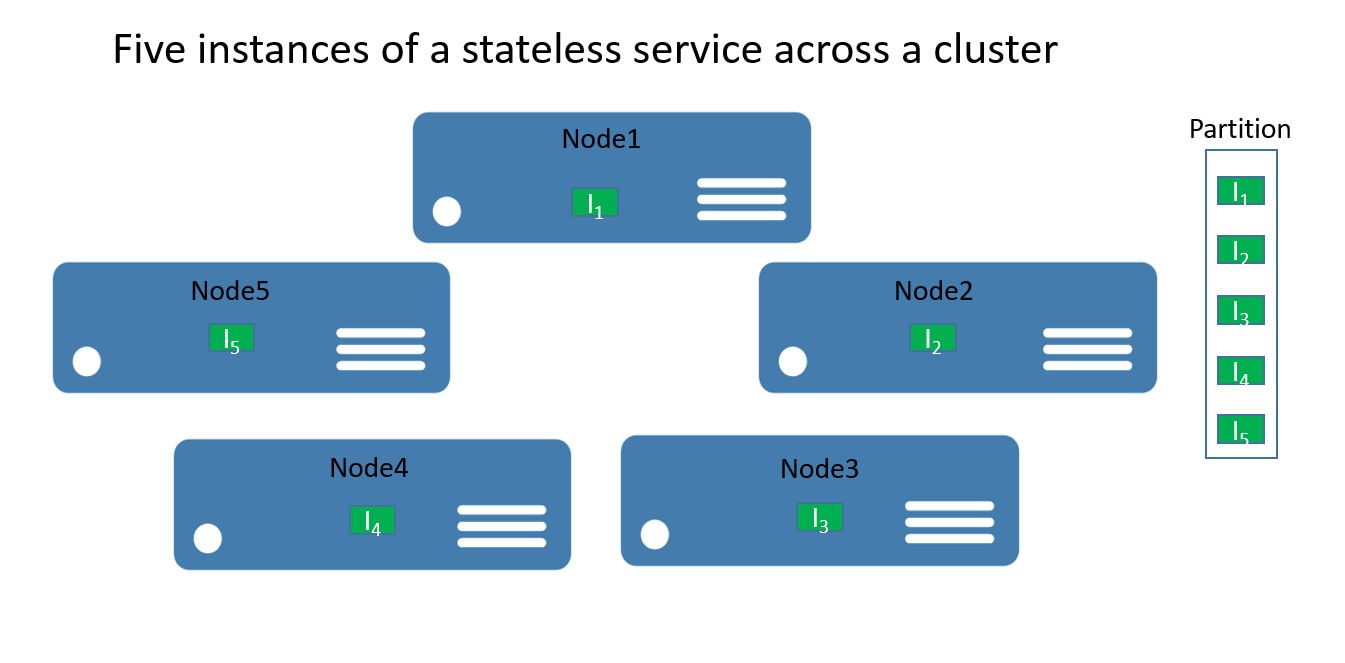
Er zijn echt twee soorten stateless serviceoplossingen. De eerste is een service die de status extern behoudt, bijvoorbeeld in een database in Azure SQL Database (zoals een website waarin de sessiegegevens en -gegevens worden opgeslagen). De tweede is alleen rekenservices (zoals een rekenmachine of afbeeldingsminiaturen) die geen permanente status beheren.
In beide gevallen is het partitioneren van een staatloze service een zeer zeldzame scenario-schaalbaarheid en beschikbaarheid normaal gesproken bereikt door meer exemplaren toe te voegen. De enige keer dat u meerdere partities voor stateless service-exemplaren wilt overwegen, is wanneer u moet voldoen aan speciale routeringsaanvragen.
Denk bijvoorbeeld aan een geval waarin gebruikers met id's in een bepaald bereik alleen worden bediend door een bepaald service-exemplaar. Een ander voorbeeld van wanneer u een staatloze service kunt partitioneren, is wanneer u een echt gepartitioneerde back-end hebt (bijvoorbeeld een shard-database in SQL Database) en u wilt bepalen welk service-exemplaar naar de database-shard moet schrijven, of ander voorbereidingswerk moet uitvoeren binnen de staatloze service waarvoor dezelfde partitioneringsgegevens zijn vereist als die in de back-end wordt gebruikt. Deze typen scenario's kunnen ook op verschillende manieren worden opgelost en vereisen niet noodzakelijkerwijs servicepartitionering.
De rest van deze procedure is gericht op stateful services.
Stateful Service Fabric-services partitioneren
Met Service Fabric kunt u eenvoudig schaalbare stateful services ontwikkelen door een eersteklas manier te bieden om de status (gegevens) te partitioneren. Conceptueel gezien kunt u denken aan een partitie van een stateful service als een schaaleenheid die zeer betrouwbaar is via replica's die zijn verdeeld en verdeeld over de knooppunten in een cluster.
Partitionering in de context van Stateful Service Fabric-services verwijst naar het proces om te bepalen dat een bepaalde servicepartitie verantwoordelijk is voor een deel van de volledige status van de service. (Zoals eerder vermeld, is een partitie een set replica's. Een goed ding met Service Fabric is dat de partities op verschillende knooppunten worden geplaatst. Hierdoor kunnen ze groeien tot de resourcelimiet van een knooppunt. Naarmate de gegevens moeten toenemen, worden partities groter en worden partities in Service Fabric opnieuw verdeeld over knooppunten. Dit zorgt voor een voortgezet efficiënt gebruik van hardwarebronnen.
Als u een voorbeeld wilt geven, begint u met een cluster met vijf knooppunten en een service die is geconfigureerd voor 10 partities en een doel van drie replica's. In dit geval verdeelt Service Fabric de replica's over het cluster en verdeelt u twee primaire replica's per knooppunt. Als u het cluster nu wilt uitschalen naar 10 knooppunten, zou Service Fabric de primaire replica's opnieuw verdelen over alle 10 knooppunten . Als u terugschaalde naar 5 knooppunten, zou Service Fabric alle replica's over de 5 knooppunten opnieuw verdelen.
In afbeelding 2 ziet u de distributie van 10 partities vóór en na het schalen van het cluster.
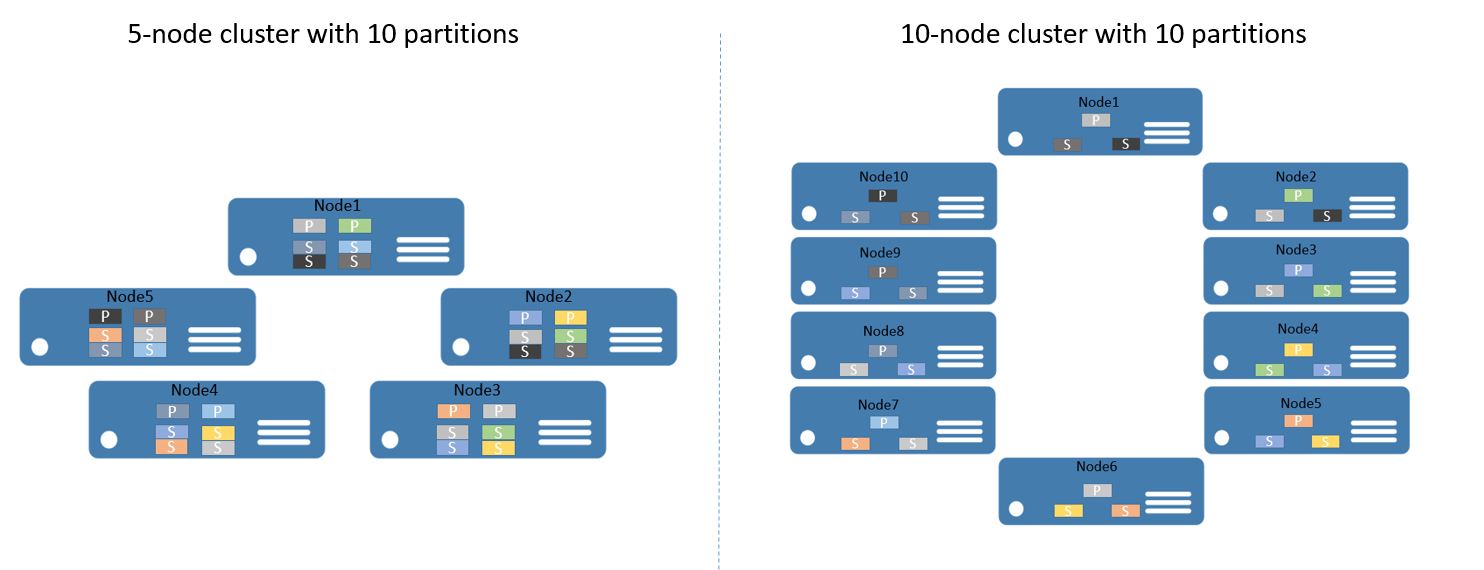
Als gevolg hiervan wordt de uitschaal bereikt omdat aanvragen van clients worden gedistribueerd over computers, de algehele prestaties van de toepassing worden verbeterd en conflicten over de toegang tot segmenten van gegevens worden verminderd.
Partitionering plannen
Voordat u een service implementeert, moet u altijd rekening houden met de partitioneringsstrategie die nodig is om uit te schalen. Er zijn verschillende manieren, maar ze richten zich allemaal op wat de toepassing moet bereiken. Laten we voor de context van dit artikel enkele van de belangrijkste aspecten overwegen.
Een goede benadering is om na te denken over de structuur van de status die moet worden gepartitioneerd, als eerste stap.
Laten we een eenvoudig voorbeeld nemen. Als u een service voor een peiling voor de hele provincie zou bouwen, kunt u een partitie maken voor elke stad in de provincie. Vervolgens kunt u de stemmen opslaan voor elke persoon in de stad in de partitie die overeenkomt met die stad. Afbeelding 3 illustreert een set mensen en de stad waarin ze zich bevinden.
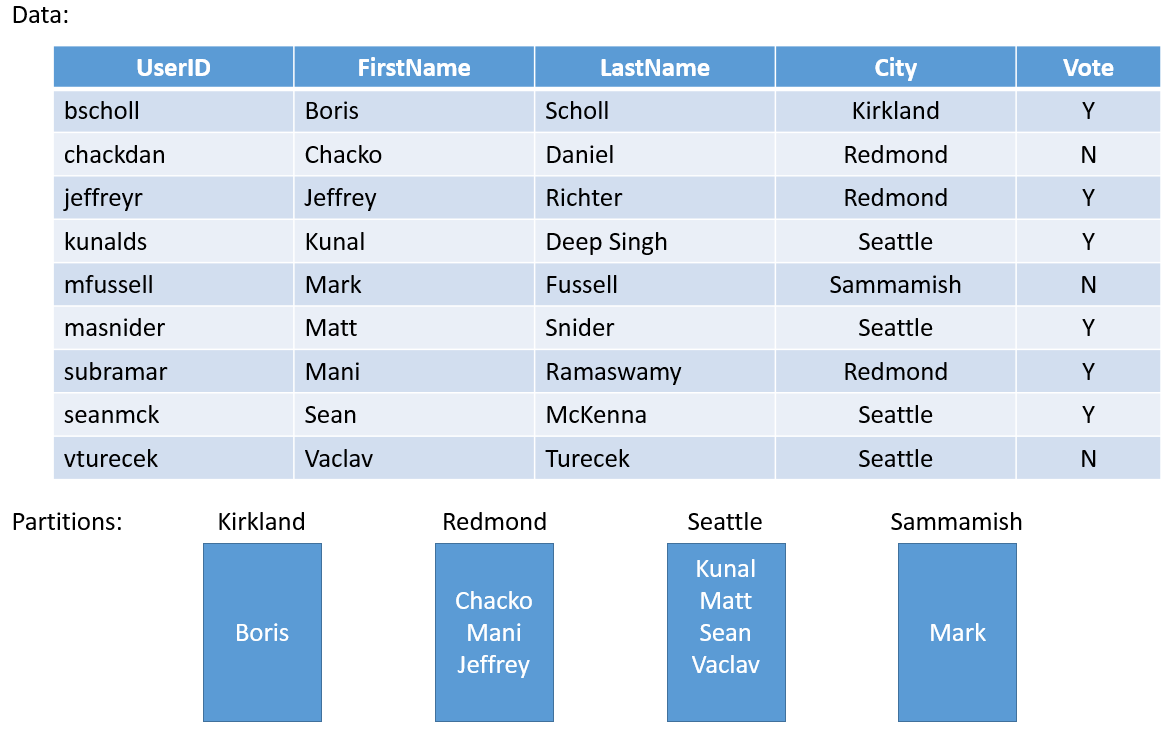
Naarmate de bevolking van steden sterk varieert, kunt u eindigen met een aantal partities die veel gegevens bevatten (bijvoorbeeld Seattle) en andere partities met zeer weinig staat (bijvoorbeeld Kirkland). Wat is de impact van het hebben van partities met ongelijke hoeveelheden status?
Als u nog eens nadenkt over het voorbeeld, kunt u gemakkelijk zien dat de partitie met de stemmen voor Seattle meer verkeer krijgt dan de Kirkland één. Service Fabric zorgt er standaard voor dat er ongeveer hetzelfde aantal primaire en secundaire replica's op elk knooppunt is. U kunt dus terechtkomen met knooppunten die replica's bevatten die meer verkeer leveren en andere die minder verkeer leveren. U wilt bij voorkeur warme en koude plekken zoals deze in een cluster vermijden.
Om dit te voorkomen, moet u twee dingen doen, vanuit een partitioneringspunt:
- Probeer de status te partitioneren, zodat deze gelijkmatig over alle partities wordt verdeeld.
- Rapportbelasting van elk van de replica's voor de service. (Raadpleeg dit artikel voor meer informatie over hoe u dit artikel leest Metrische gegevens en belasting). Service Fabric biedt de mogelijkheid om belasting te rapporteren die wordt verbruikt door services, zoals hoeveelheid geheugen of aantal records. Op basis van de gerapporteerde metrische gegevens detecteert Service Fabric dat sommige partities hogere belastingen leveren dan andere partities en het cluster opnieuw verdelen door replica's naar geschiktere knooppunten te verplaatsen, zodat over het algemeen geen knooppunt overbelast is.
Soms kunt u niet weten hoeveel gegevens zich in een bepaalde partitie bevinden. Een algemene aanbeveling is om eerst beide te doen, door een partitioneringsstrategie te gebruiken die de gegevens gelijkmatig over de partities verspreidt en ten tweede door belasting te rapporteren. De eerste methode voorkomt situaties die in het stemvoorbeeld worden beschreven, terwijl de tweede helpt tijdelijke verschillen in toegang of belasting in de loop van de tijd weg te vlakken.
Een ander aspect van partitieplanning is om het juiste aantal partities te kiezen om mee te beginnen. Vanuit het perspectief van Service Fabric is er niets dat voorkomt dat u begint met een hoger aantal partities dan verwacht voor uw scenario. Ervan uitgaande dat het maximum aantal partities een geldige benadering is.
In zeldzame gevallen hebt u mogelijk meer partities nodig dan u in eerste instantie hebt gekozen. Aangezien u het aantal partities na het feit niet kunt wijzigen, moet u een aantal geavanceerde partitiemethoden toepassen, zoals het maken van een nieuw service-exemplaar van hetzelfde servicetype. U moet ook een aantal logica aan de clientzijde implementeren waarmee de aanvragen worden doorgestuurd naar het juiste service-exemplaar, op basis van de kennis aan de clientzijde die uw clientcode moet onderhouden.
Een andere overweging voor partitioneringsplanning is de beschikbare computerbronnen. Aangezien de status moet worden geopend en opgeslagen, moet u het volgende doen:
- Netwerkbandbreedtelimieten
- Limieten voor systeemgeheugen
- Schijfopslaglimieten
Wat gebeurt er als u resourcebeperkingen krijgt in een actief cluster? Het antwoord is dat u het cluster eenvoudig kunt uitschalen om aan de nieuwe vereisten te voldoen.
De handleiding voor capaciteitsplanning biedt richtlijnen voor het bepalen hoeveel knooppunten uw cluster nodig heeft.
Aan de slag met partitioneren
In deze sectie wordt beschreven hoe u aan de slag gaat met het partitioneren van uw service.
Service Fabric biedt een keuze uit drie partitieschema's:
- Ranged partitionering (ook wel bekend als UniformInt64Partition).
- Benoemde partitionering. Toepassingen die dit model gebruiken, hebben meestal gegevens die in een bucket kunnen worden geplaatst, binnen een gebonden set. Enkele veelvoorkomende voorbeelden van gegevensvelden die worden gebruikt als partitiesleutels, zijn regio's, postcodes, klantgroepen of andere bedrijfsgrenzen.
- Singleton partitionering. Singleton-partities worden doorgaans gebruikt wanneer de service geen extra routering vereist. Staatloze services maken bijvoorbeeld standaard gebruik van dit partitioneringsschema.
Benoemde en Singleton-partitioneringsschema's zijn speciale vormen van bereikpartities. De Visual Studio-sjablonen voor Service Fabric maken standaard gebruik van bereikpartitionering, omdat dit het meest voorkomende en nuttige is. De rest van dit artikel is gericht op het bereikpartitioneringsschema.
Bereikpartitioneringsschema
Dit wordt gebruikt om een geheel getalbereik op te geven (geïdentificeerd door een lage sleutel en hoge sleutel) en een aantal partities (n). Er worden n partities gemaakt, die elk verantwoordelijk zijn voor een niet-overlappende subbereik van het totale partitiesleutelbereik. Een bereikpartitioneringsschema met een lage sleutel van 0, een hoge sleutel van 99 en een telling van 4 zou bijvoorbeeld vier partities maken, zoals hieronder wordt weergegeven.
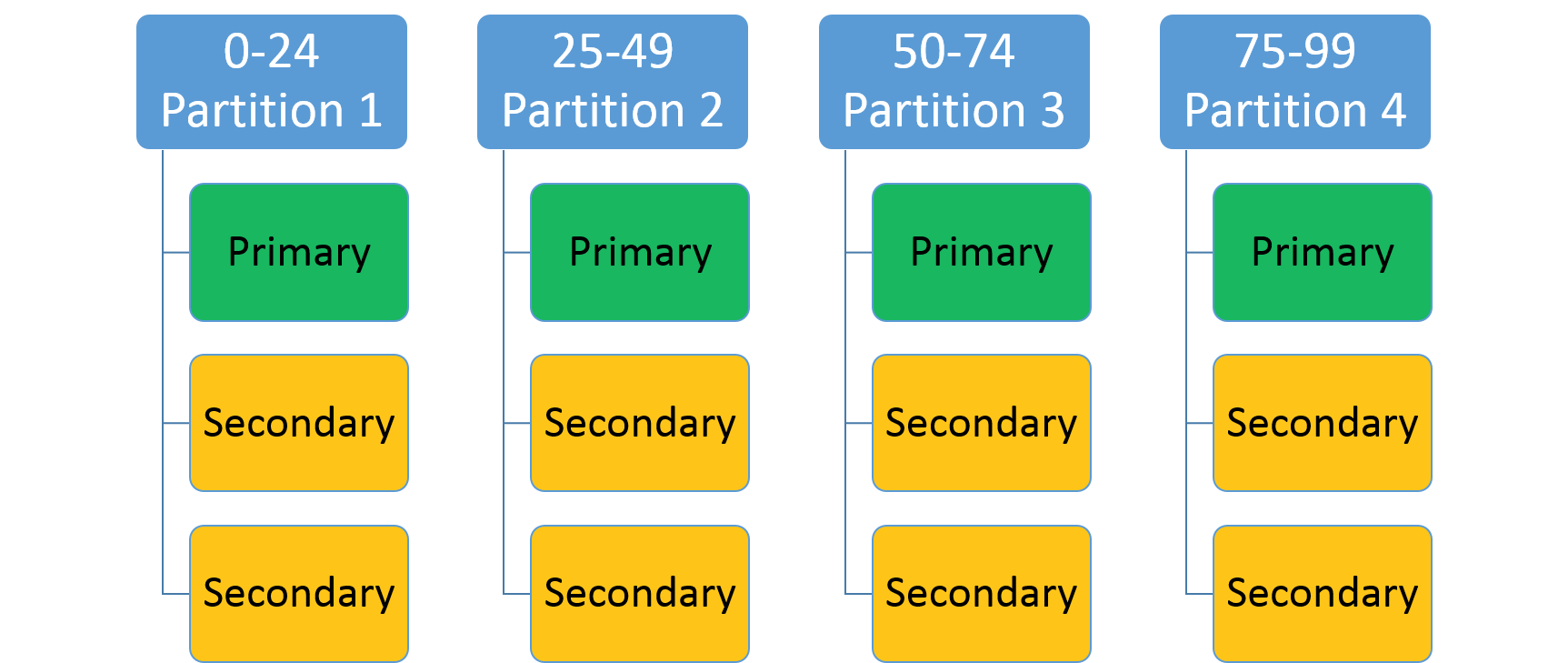
Een veelvoorkomende benadering is het maken van een hash op basis van een unieke sleutel in de gegevensset. Enkele veelvoorkomende voorbeelden van sleutels zijn een voertuigidentificatienummer (VIN), een werknemer-id of een unieke tekenreeks. Door deze unieke sleutel te gebruiken, genereert u vervolgens een hash-code, modulus het sleutelbereik, om te gebruiken als uw sleutel. U kunt de boven- en ondergrenzen van het toegestane sleutelbereik opgeven.
Een hash-algoritme selecteren
Een belangrijk onderdeel van hashing is het selecteren van uw hash-algoritme. Een overweging is of het doel is om vergelijkbare sleutels in de buurt van elkaar te groeperen (lokaliteitsgevoelige hashing)- of als activiteit breed moet worden verdeeld over alle partities (distributie-hashing), wat gebruikelijker is.
De kenmerken van een goed algoritme voor distributie-hashing zijn dat het eenvoudig te berekenen is, het heeft weinig conflicten en het distribueert de sleutels gelijkmatig. Een goed voorbeeld van een efficiënt hash-algoritme is het hash-algoritme FNV-1 .
Een goede resource voor algemene opties voor hashcodealgoritmen is de Wikipedia-pagina over hashfuncties.
Een stateful service bouwen met meerdere partities
Laten we uw eerste betrouwbare stateful service met meerdere partities maken. In dit voorbeeld maakt u een zeer eenvoudige toepassing waarin u alle achternamen wilt opslaan die beginnen met dezelfde letter in dezelfde partitie.
Voordat u code schrijft, moet u nadenken over de partities en partitiesleutels. U hebt 26 partities nodig (één voor elke letter in het alfabet), maar hoe zit het met de lage en hoge sleutels? Omdat we letterlijk één partitie per letter willen hebben, kunnen we 0 gebruiken als de lage sleutel en 25 als de hoge sleutel, omdat elke letter een eigen sleutel is.
Notitie
Dit is een vereenvoudigd scenario, omdat de verdeling in werkelijkheid ongelijk zou zijn. Achternamen die beginnen met de letters 'S' of 'M' komen vaker voor dan de namen die beginnen met 'X' of 'Y'.
Open Visual Studio>File>New>Project.
Kies in het dialoogvenster Nieuw project de Service Fabric-toepassing.
Roep het project 'AlphabetPartitions' aan.
Kies stateful service in het dialoogvenster Een service maken en noem deze 'Alphabet.Processing'.
Stel het aantal partities in. Open het ApplicationManifest.xml bestand in de map ApplicationPackageRoot van het project AlphabetPartitions en werk de parameter Processing_PartitionCount bij naar 26, zoals hieronder wordt weergegeven.
<Parameter Name="Processing_PartitionCount" DefaultValue="26" />U moet ook de eigenschappen LowKey en HighKey van het Element StatefulService in de ApplicationManifest.xml bijwerken, zoals hieronder wordt weergegeven.
<Service Name="Alphabet.Processing"> <StatefulService ServiceTypeName="Alphabet.ProcessingType" TargetReplicaSetSize="[Processing_TargetReplicaSetSize]" MinReplicaSetSize="[Processing_MinReplicaSetSize]"> <UniformInt64Partition PartitionCount="[Processing_PartitionCount]" LowKey="0" HighKey="25" /> </StatefulService> </Service>Open een eindpunt op een poort om de service toegankelijk te maken door het eindpuntelement van ServiceManifest.xml (in de map PackageRoot) toe te voegen voor de Service Alphabet.Processing, zoals hieronder wordt weergegeven:
<Endpoint Name="ProcessingServiceEndpoint" Port="8089" Protocol="http" Type="Internal" />De service is nu geconfigureerd om te luisteren naar een intern eindpunt met 26 partities.
Vervolgens moet u de methode van de
CreateServiceReplicaListeners()verwerkingsklasse overschrijven.Notitie
Voor dit voorbeeld wordt ervan uitgegaan dat u een eenvoudige HttpCommunicationListener gebruikt. Zie Het Reliable Service-communicatiemodel voor meer informatie over betrouwbare servicecommunicatie.
Een aanbevolen patroon voor de URL waarop een replica luistert, is de volgende indeling:
{scheme}://{nodeIp}:{port}/{partitionid}/{replicaid}/{guid}U wilt dus uw communicatielistener configureren om te luisteren naar de juiste eindpunten en met dit patroon.Meerdere replica's van deze service kunnen worden gehost op dezelfde computer, dus dit adres moet uniek zijn voor de replica. Daarom bevinden partitie-id en replica-id zich in de URL. HttpListener kan luisteren op meerdere adressen op dezelfde poort, zolang het URL-voorvoegsel uniek is.
De extra GUID is er voor een geavanceerd geval waarbij secundaire replica's ook luisteren naar alleen-lezen aanvragen. Als dat het geval is, wilt u ervoor zorgen dat een nieuw uniek adres wordt gebruikt bij het overstappen van primaire naar secundaire client om clients te dwingen het adres opnieuw op te lossen. '+' wordt hier gebruikt als het adres, zodat de replica luistert op alle beschikbare hosts (IP, FQDN, localhost, enzovoort) In de onderstaande code ziet u een voorbeeld.
protected override IEnumerable<ServiceReplicaListener> CreateServiceReplicaListeners() { return new[] { new ServiceReplicaListener(context => this.CreateInternalListener(context))}; } private ICommunicationListener CreateInternalListener(ServiceContext context) { EndpointResourceDescription internalEndpoint = context.CodePackageActivationContext.GetEndpoint("ProcessingServiceEndpoint"); string uriPrefix = String.Format( "{0}://+:{1}/{2}/{3}-{4}/", internalEndpoint.Protocol, internalEndpoint.Port, context.PartitionId, context.ReplicaOrInstanceId, Guid.NewGuid()); string nodeIP = FabricRuntime.GetNodeContext().IPAddressOrFQDN; string uriPublished = uriPrefix.Replace("+", nodeIP); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInternalRequest); }Het is ook de moeite waard om te vermelden dat de gepubliceerde URL iets verschilt van het luister-URL-voorvoegsel. De luister-URL wordt aan HttpListener gegeven. De gepubliceerde URL is de URL die wordt gepubliceerd naar de Service Fabric Naming Service, die wordt gebruikt voor servicedetectie. Clients vragen dit adres via die detectieservice. Het adres dat clients krijgen, moet het werkelijke IP- of FQDN-adres van het knooppunt hebben om verbinding te kunnen maken. U moet dus '+' vervangen door het IP- of FQDN-adres van het knooppunt, zoals hierboven wordt weergegeven.
De laatste stap is het toevoegen van de verwerkingslogica aan de service, zoals hieronder wordt weergegeven.
private async Task ProcessInternalRequest(HttpListenerContext context, CancellationToken cancelRequest) { string output = null; string user = context.Request.QueryString["lastname"].ToString(); try { output = await this.AddUserAsync(user); } catch (Exception ex) { output = ex.Message; } using (HttpListenerResponse response = context.Response) { if (output != null) { byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } } private async Task<string> AddUserAsync(string user) { IReliableDictionary<String, String> dictionary = await this.StateManager.GetOrAddAsync<IReliableDictionary<String, String>>("dictionary"); using (ITransaction tx = this.StateManager.CreateTransaction()) { bool addResult = await dictionary.TryAddAsync(tx, user.ToUpperInvariant(), user); await tx.CommitAsync(); return String.Format( "User {0} {1}", user, addResult ? "successfully added" : "already exists"); } }ProcessInternalRequestleest de waarden van de queryreeksparameter die wordt gebruikt voor het aanroepen van de partitie en aanroepenAddUserAsyncom de achternaam toe te voegen aan de betrouwbare woordenlijstdictionary.Laten we een stateless service aan het project toevoegen om te zien hoe u een bepaalde partitie kunt aanroepen.
Deze service fungeert als een eenvoudige webinterface die de achternaam accepteert als een querytekenreeksparameter, bepaalt de partitiesleutel en verzendt deze naar de Service Alphabet.Processing voor verwerking.
Kies in het dialoogvenster Een service maken de optie Stateless service en noem deze 'Alphabet.Web', zoals hieronder wordt weergegeven.
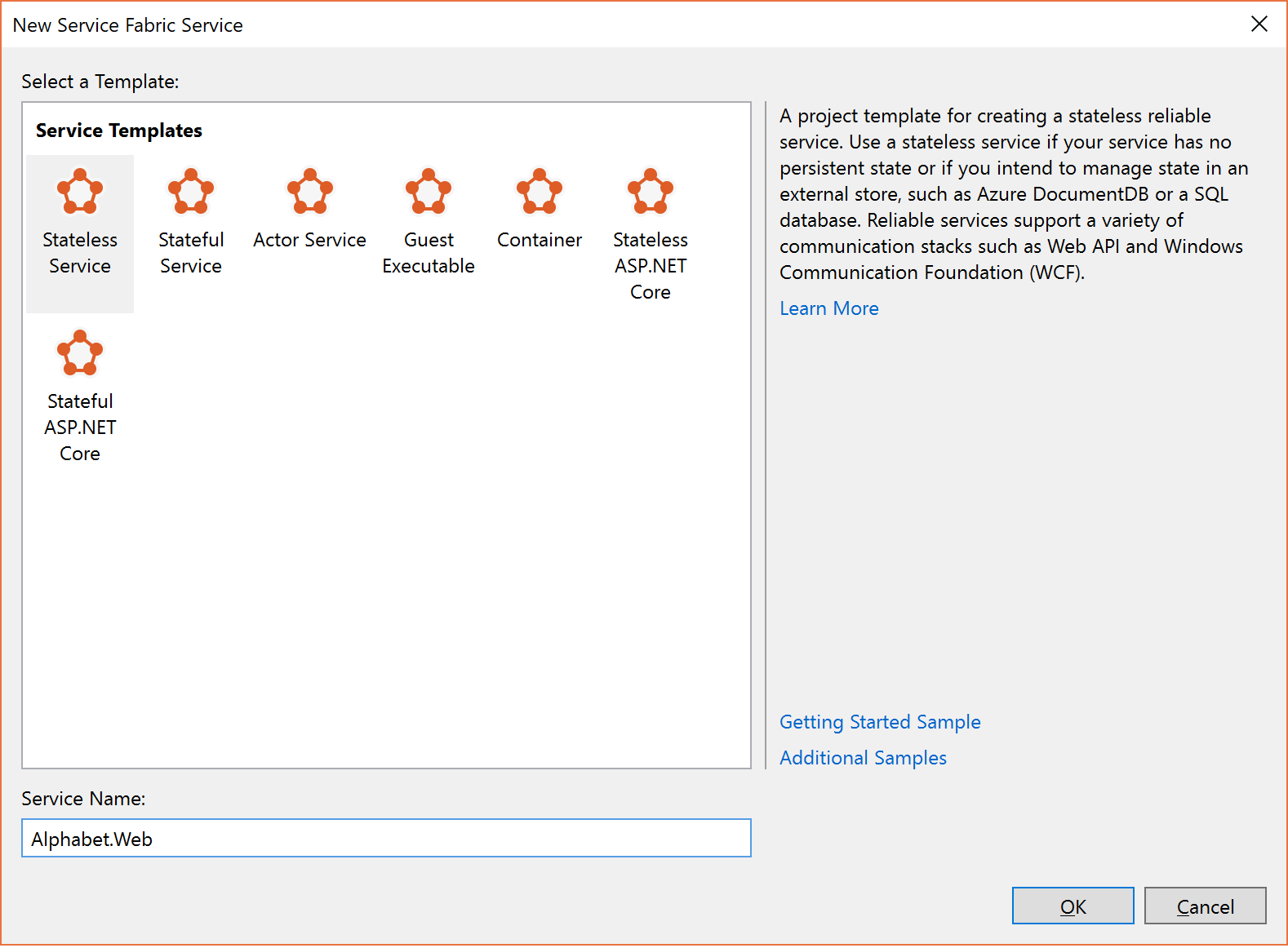 .
.Werk de eindpuntgegevens in de ServiceManifest.xml van de Alphabet.WebApi-service bij om een poort te openen, zoals hieronder wordt weergegeven.
<Endpoint Name="WebApiServiceEndpoint" Protocol="http" Port="8081"/>U moet een verzameling ServiceInstanceListeners in het klasseweb retourneren. U kunt er ook voor kiezen om een eenvoudige HttpCommunicationListener te implementeren.
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners() { return new[] {new ServiceInstanceListener(context => this.CreateInputListener(context))}; } private ICommunicationListener CreateInputListener(ServiceContext context) { // Service instance's URL is the node's IP & desired port EndpointResourceDescription inputEndpoint = context.CodePackageActivationContext.GetEndpoint("WebApiServiceEndpoint") string uriPrefix = String.Format("{0}://+:{1}/alphabetpartitions/", inputEndpoint.Protocol, inputEndpoint.Port); var uriPublished = uriPrefix.Replace("+", FabricRuntime.GetNodeContext().IPAddressOrFQDN); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInputRequest); }Nu moet u de verwerkingslogica implementeren. HttpCommunicationListener roept aan
ProcessInputRequestwanneer er een aanvraag binnenkomt. Laten we dus verdergaan en de onderstaande code toevoegen.private async Task ProcessInputRequest(HttpListenerContext context, CancellationToken cancelRequest) { String output = null; try { string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A'); ResolvedServicePartition partition = await this.servicePartitionResolver.ResolveAsync(alphabetServiceUri, partitionKey, cancelRequest); ResolvedServiceEndpoint ep = partition.GetEndpoint(); JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri); output = String.Format( "Result: {0}. <p>Partition key: '{1}' generated from the first letter '{2}' of input value '{3}'. <br>Processing service partition ID: {4}. <br>Processing service replica address: {5}", result, partitionKey, firstLetterOfLastName, lastname, partition.Info.Id, primaryReplicaAddress); } catch (Exception ex) { output = ex.Message; } using (var response = context.Response) { if (output != null) { output = output + "added to Partition: " + primaryReplicaAddress; byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } }Laten we het stapsgewijs doorlopen. De code leest de eerste letter van de querytekenreeksparameter
lastnamein een tekenreeks. Vervolgens wordt de partitiesleutel voor deze letter bepaald door de hexadecimale waarde vanAde hexadecimale waarde van de voorletter van de achternamen af te trekken.string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A');Voor dit voorbeeld gebruiken we 26 partities met één partitiesleutel per partitie. Vervolgens verkrijgen we de servicepartitie
partitionvoor deze sleutel met behulp van deResolveAsyncmethode voor hetservicePartitionResolverobject.servicePartitionResolveris gedefinieerd alsprivate readonly ServicePartitionResolver servicePartitionResolver = ServicePartitionResolver.GetDefault();De
ResolveAsyncmethode gebruikt de service-URI, de partitiesleutel en een annuleringstoken als parameters. De service-URI voor de verwerkingsservice isfabric:/AlphabetPartitions/Processing. Vervolgens krijgen we het eindpunt van de partitie.ResolvedServiceEndpoint ep = partition.GetEndpoint()Ten slotte bouwen we de eindpunt-URL plus de querytekenreeks en roepen we de verwerkingsservice aan.
JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri);Zodra de verwerking is voltooid, schrijven we de uitvoer terug.
De laatste stap is het testen van de service. Visual Studio maakt gebruik van toepassingsparameters voor lokale en cloudimplementatie. Als u de service met 26 partities lokaal wilt testen, moet u het
Local.xmlbestand bijwerken in de map ApplicationParameters van het project AlphabetPartitions, zoals hieronder wordt weergegeven:<Parameters> <Parameter Name="Processing_PartitionCount" Value="26" /> <Parameter Name="WebApi_InstanceCount" Value="1" /> </Parameters>Zodra u klaar bent met de implementatie, kunt u de service en alle bijbehorende partities controleren in Service Fabric Explorer.
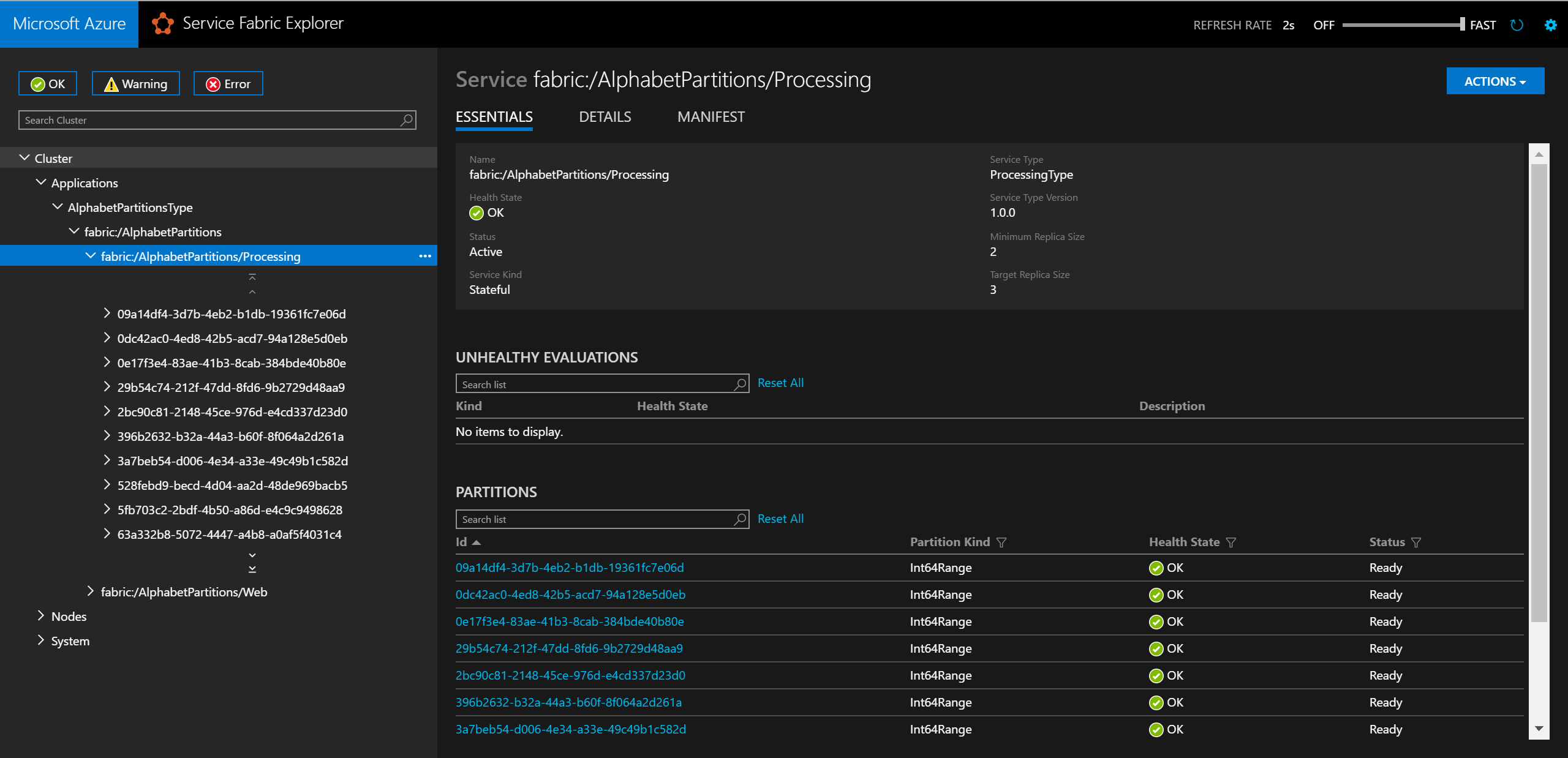
In een browser kunt u de partitioneringslogica testen door deze in te voeren
http://localhost:8081/?lastname=somename. U ziet dat elke achternaam die begint met dezelfde letter wordt opgeslagen in dezelfde partitie.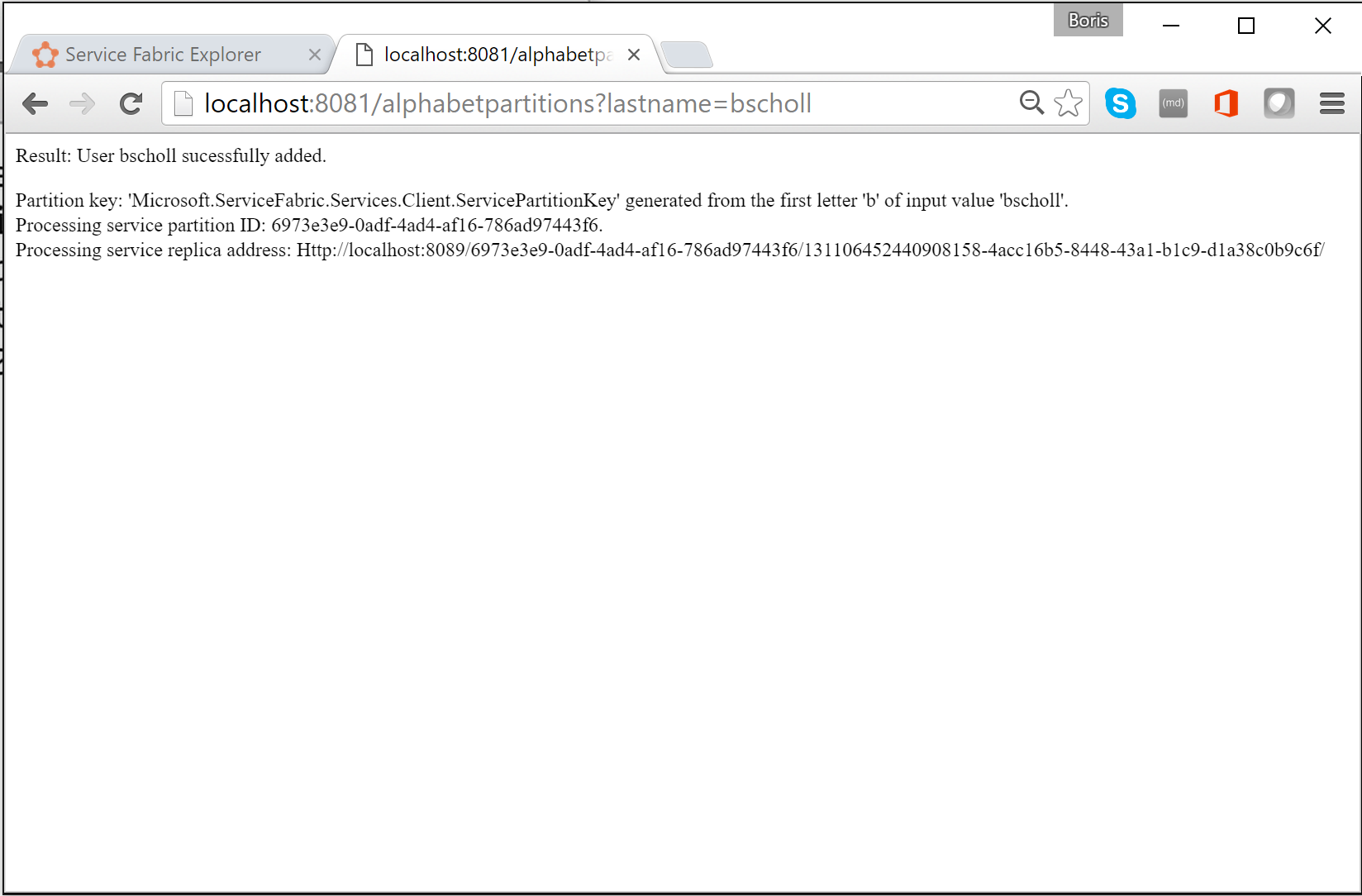
De volledige oplossing van de code die in dit artikel wordt gebruikt, is hier beschikbaar: https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/tree/classic/Services/AlphabetPartitions.
Volgende stappen
Meer informatie over Service Fabric-services: