Kwaliteit en tokengebruik van geïmplementeerde promptstroomtoepassingen bewaken
Belangrijk
Items die in dit artikel zijn gemarkeerd (preview) zijn momenteel beschikbaar als openbare preview. Deze preview wordt aangeboden zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Het bewaken van toepassingen die in productie zijn geïmplementeerd, is een essentieel onderdeel van de levenscyclus van ai-toepassingen. Wijzigingen in gegevens- en consumentengedrag kunnen in de loop van de tijd invloed hebben op uw toepassing, wat resulteert in verouderde systemen die negatieve invloed hebben op bedrijfsresultaten en organisaties blootstellen aan nalevings-, economische en reputatierisico's.
Notitie
Voor een verbeterde manier om continue bewaking van geïmplementeerde toepassingen (behalve promptstroom) uit te voeren, kunt u overwegen om online evaluatie van Azure AI te gebruiken.
Met Azure AI-bewaking voor generatieve AI-toepassingen kunt u uw toepassingen in productie bewaken voor tokengebruik, generatiekwaliteit en operationele metrische gegevens.
Met integraties voor het bewaken van een promptstroomimplementatie kunt u het volgende doen:
- Verzamel productiedeductiegegevens van uw geïmplementeerde promptstroomtoepassing.
- Pas metrische gegevens voor verantwoorde AI-evaluatie toe, zoals aarding, samenhang, fluency en relevantie, die compatibel zijn met metrische gegevens over de evaluatie van promptstromen.
- Bewaak prompts, voltooiing en het totale tokengebruik voor elke modelimplementatie in uw promptstroom.
- Bewaak operationele metrische gegevens, zoals aantal aanvragen, latentie en foutpercentage.
- Gebruik vooraf geconfigureerde waarschuwingen en standaardinstellingen om bewaking op terugkerende basis uit te voeren.
- Gegevensvisualisaties gebruiken en geavanceerd gedrag configureren in de Azure AI Foundry-portal.
Vereisten
Voordat u de stappen in dit artikel volgt, moet u ervoor zorgen dat u over de volgende vereisten beschikt:
Een Azure-abonnement met een geldige betalingswijze. Gratis of proefabonnementen voor Azure worden niet ondersteund voor dit scenario. Als u geen Azure-abonnement hebt, maakt u eerst een betaald Azure-account .
Een promptstroom die gereed is voor implementatie. Zie Een promptstroom ontwikkelen als u er nog geen hebt.
Op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) wordt gebruikt om toegang te verlenen tot bewerkingen in de Azure AI Foundry-portal. Als u de stappen in dit artikel wilt uitvoeren, moet aan uw gebruikersaccount de Azure AI Developer-rol voor de resourcegroep zijn toegewezen. Zie op rollen gebaseerd toegangsbeheer in de Azure AI Foundry-portal voor meer informatie over machtigingen.
Vereisten voor het bewaken van metrische gegevens
Bewakingsgegevens worden gegenereerd door bepaalde geavanceerde GPT-taalmodellen die zijn geconfigureerd met specifieke evaluatie-instructies (promptsjablonen). Deze modellen fungeren als evaluatormodellen voor reeks-naar-reekstaken. Gebruik van deze techniek om metrische bewakingsgegevens te genereren, toont sterke empirische resultaten en een hoge correlatie met menselijke beoordeling in vergelijking met standaardgeneratieve AI-evaluatiegegevens. Zie voor meer informatie over de evaluatie van promptstromen bulksgewijs testen en evalueren van een stroom en evaluatie en bewaking van metrische gegevens voor generatieve AI.
De GPT-modellen die metrische bewakingsgegevens genereren, zijn als volgt. Deze GPT-modellen worden ondersteund met bewaking en geconfigureerd als uw Azure OpenAI-resource:
- GPT-3.5 Turbo
- GPT-4
- GPT-4-32k
Ondersteunde metrische gegevens voor bewaking
De volgende metrische gegevens worden ondersteund voor bewaking:
| Metrisch | Beschrijving |
|---|---|
| Grondgebondenheid | Meet hoe goed de gegenereerde antwoorden van het model overeenkomen met informatie uit de brongegevens (door de gebruiker gedefinieerde context).) |
| Relevantie | Meet de mate waarin de gegenereerde antwoorden van het model relevant zijn en rechtstreeks gerelateerd zijn aan de gegeven vragen. |
| Samenhang | Meet de mate waarin de gegenereerde antwoorden van het model logisch consistent en verbonden zijn. |
| Vlotheid | Meet de grammaticale vaardigheid van een voorspellend AI-antwoord. |
Kolomnaamtoewijzing
Wanneer u de stroom maakt, moet u ervoor zorgen dat uw kolomnamen zijn toegewezen. De volgende kolomnamen voor invoergegevens worden gebruikt om de veiligheid en kwaliteit van de generatie te meten:
| Naam van invoerkolom | Definitie | Vereist/Optioneel |
|---|---|---|
| Vraag | De oorspronkelijke prompt (ook wel 'invoer' of 'vraag' genoemd) | Vereist |
| Antwoord | De uiteindelijke voltooiing van de API-aanroep die wordt geretourneerd (ook wel 'outputs' of 'answer' genoemd) | Vereist |
| Context | Contextgegevens die naar de API-aanroep worden verzonden, samen met de oorspronkelijke prompt. Als u bijvoorbeeld alleen zoekresultaten van bepaalde gecertificeerde informatiebronnen of website wilt ophalen, kunt u deze context definiëren in de evaluatiestappen. | Optioneel |
Vereiste parameters voor metrische gegevens
De parameters die zijn geconfigureerd in uw gegevensasset bepalen welke metrische gegevens u kunt produceren, volgens deze tabel:
| Metrische gegevens | Vraag | Antwoord | Context |
|---|---|---|---|
| Samenhang | Vereist | Vereist | - |
| Vlotheid | Vereist | Vereist | - |
| Grondgebondenheid | Vereist | Vereist | Vereist |
| Relevantie | Vereist | Vereist | Vereist |
Bewaking instellen voor promptstroom
Als u bewaking voor uw promptstroomtoepassing wilt instellen, moet u eerst uw promptstroomtoepassing implementeren met het verzamelen van de deductiegegevens. Vervolgens kunt u bewaking voor de geïmplementeerde toepassing configureren.
Uw promptstroomtoepassing implementeren met het verzamelen van deductiegegevens
In deze sectie leert u hoe u uw promptstroom implementeert met het inferiëren van gegevensverzameling ingeschakeld. Zie Een stroom implementeren voor realtime deductie voor gedetailleerde informatie over het implementeren van uw promptstroom.
Meld u aan bij Azure AI Foundry.
Als u nog niet in uw project bent, selecteert u het.
Selecteer Promptstroom in de linkernavigatiebalk.
Selecteer de promptstroom die u eerder hebt gemaakt.
Notitie
In dit artikel wordt ervan uitgegaan dat u al een promptstroom hebt gemaakt die gereed is voor implementatie. Zie Een promptstroom ontwikkelen als u er nog geen hebt.
Controleer of uw stroom correct wordt uitgevoerd en of de vereiste invoer en uitvoer zijn geconfigureerd voor de metrische gegevens die u wilt evalueren.
Het leveren van de minimaal vereiste parameters (vraag/invoer en antwoord/uitvoer) biedt slechts twee metrische gegevens: samenhang en vloeiendheid. U moet uw stroom configureren zoals beschreven in de sectie vereisten voor het bewaken van metrische gegevens. In dit voorbeeld worden
question(Vraag) enchat_history(Context) gebruikt als stroominvoer enanswer(Antwoord) als stroomuitvoer.Selecteer Implementeren om te beginnen met het implementeren van uw stroom.
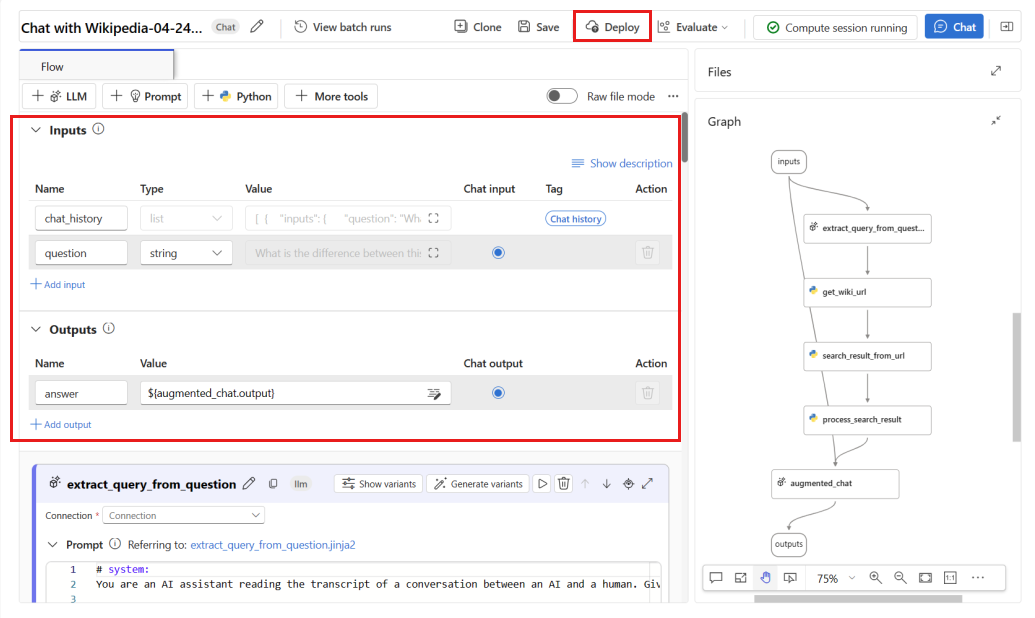
Zorg ervoor dat het verzamelen van gegevens in het implementatievenster is ingeschakeld, waardoor de deductiegegevens van uw toepassing naadloos worden verzameld naar Blob Storage. Deze gegevensverzameling is vereist voor bewaking.
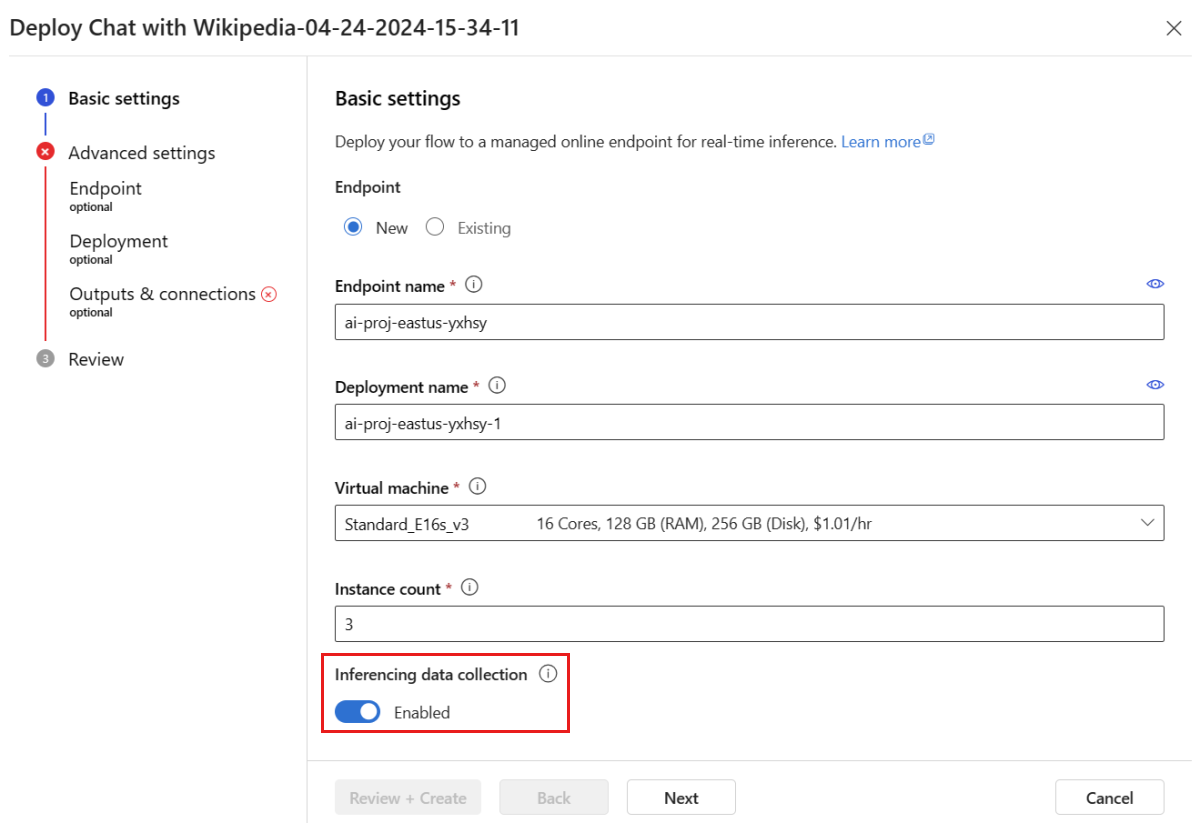
Doorloop de stappen in het implementatievenster om de geavanceerde instellingen te voltooien.
Controleer op de pagina Controleren de implementatieconfiguratie en selecteer Maken om uw stroom te implementeren.
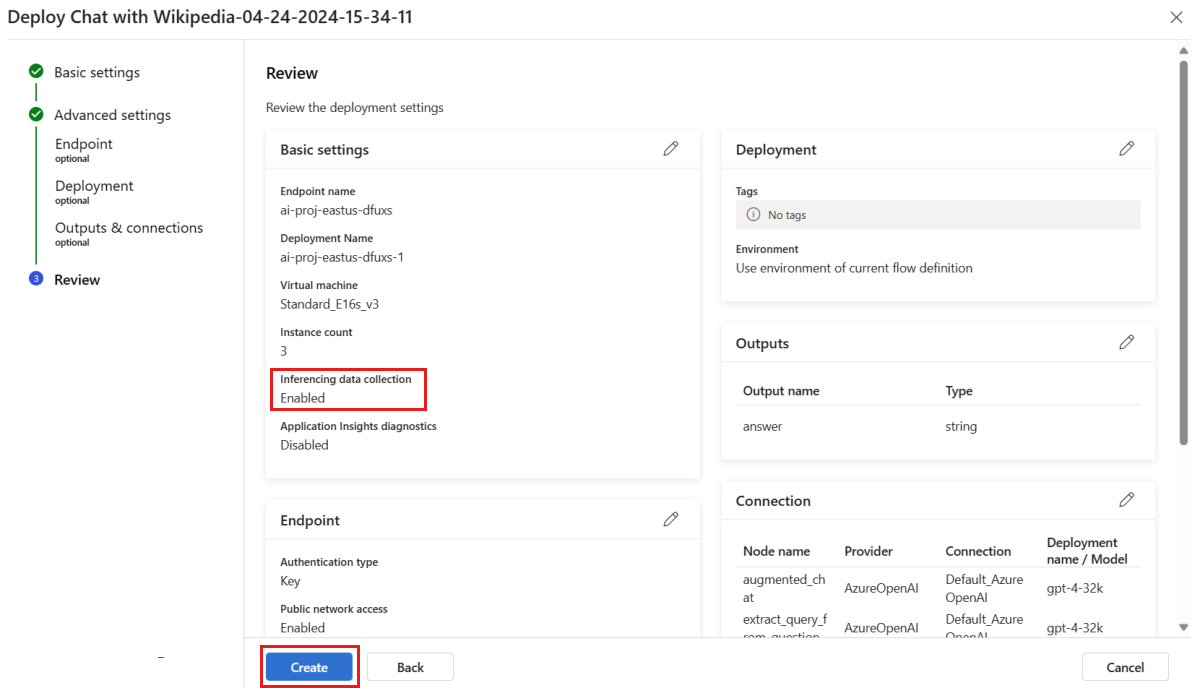
Notitie
Standaard worden alle invoer en uitvoer van uw geïmplementeerde promptstroomtoepassing verzameld naar uw Blob Storage. Wanneer de implementatie wordt aangeroepen door gebruikers, worden de gegevens verzameld die door uw monitor moeten worden gebruikt.
Selecteer het tabblad Testen op de implementatiepagina en test uw implementatie om ervoor te zorgen dat deze goed werkt.
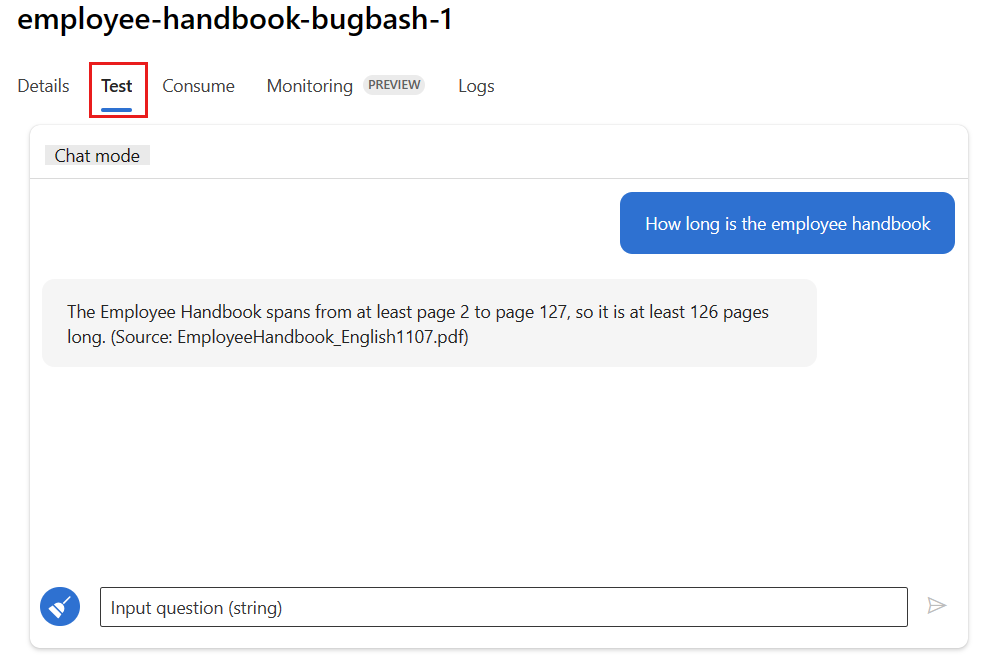
Notitie
Bewaking vereist dat ten minste één gegevenspunt afkomstig is van een andere bron dan het tabblad Testen in de implementatie. U wordt aangeraden de REST API te gebruiken die beschikbaar is op het tabblad Verbruik om voorbeeldaanvragen naar uw implementatie te verzenden. Zie Een online-implementatie maken voor meer informatie over het verzenden van voorbeeldaanvragen naar uw implementatie.




Bewaking configureren
In deze sectie leert u hoe u bewaking configureert voor uw geïmplementeerde promptstroomtoepassing.
Ga in de linkernavigatiebalk naar Mijn assets>modellen en eindpunten.
Selecteer de promptstroomimplementatie die u hebt gemaakt.
Selecteer Inschakelen in het vak Kwaliteitsbewaking inschakelen.
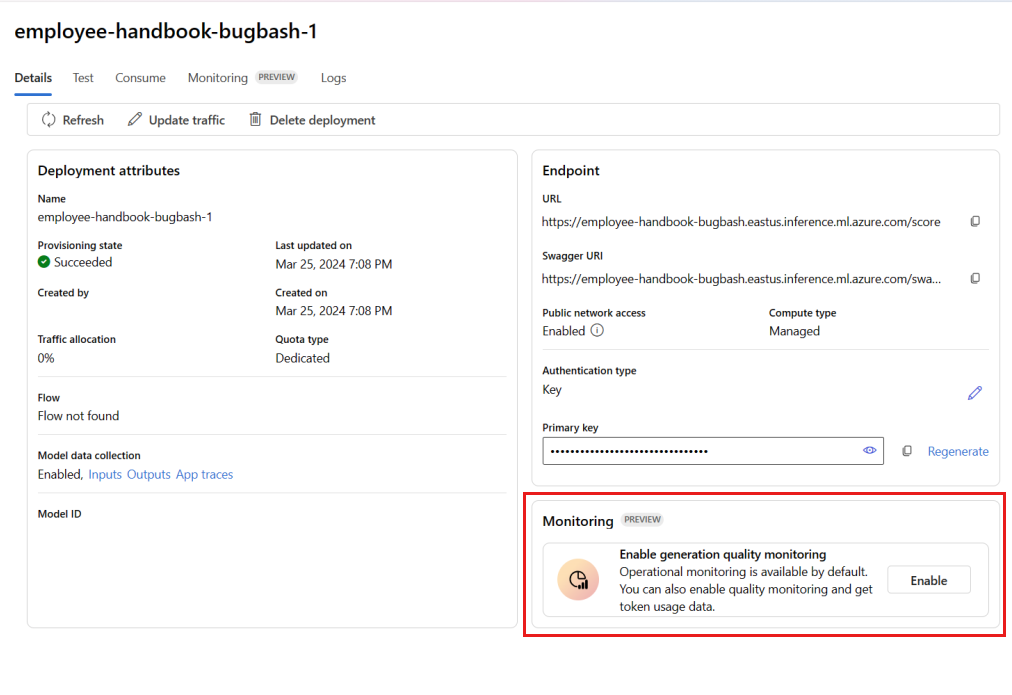
Begin met het configureren van bewaking door de gewenste metrische gegevens te selecteren.
Controleer of uw kolomnamen zijn toegewezen vanuit uw stroom, zoals gedefinieerd in kolomnaamtoewijzing.
Selecteer de Azure OpenAI-verbinding en -implementatie die u wilt gebruiken om bewaking uit te voeren voor uw promptstroomtoepassing.
Selecteer Geavanceerde opties om meer opties te zien die u wilt configureren.
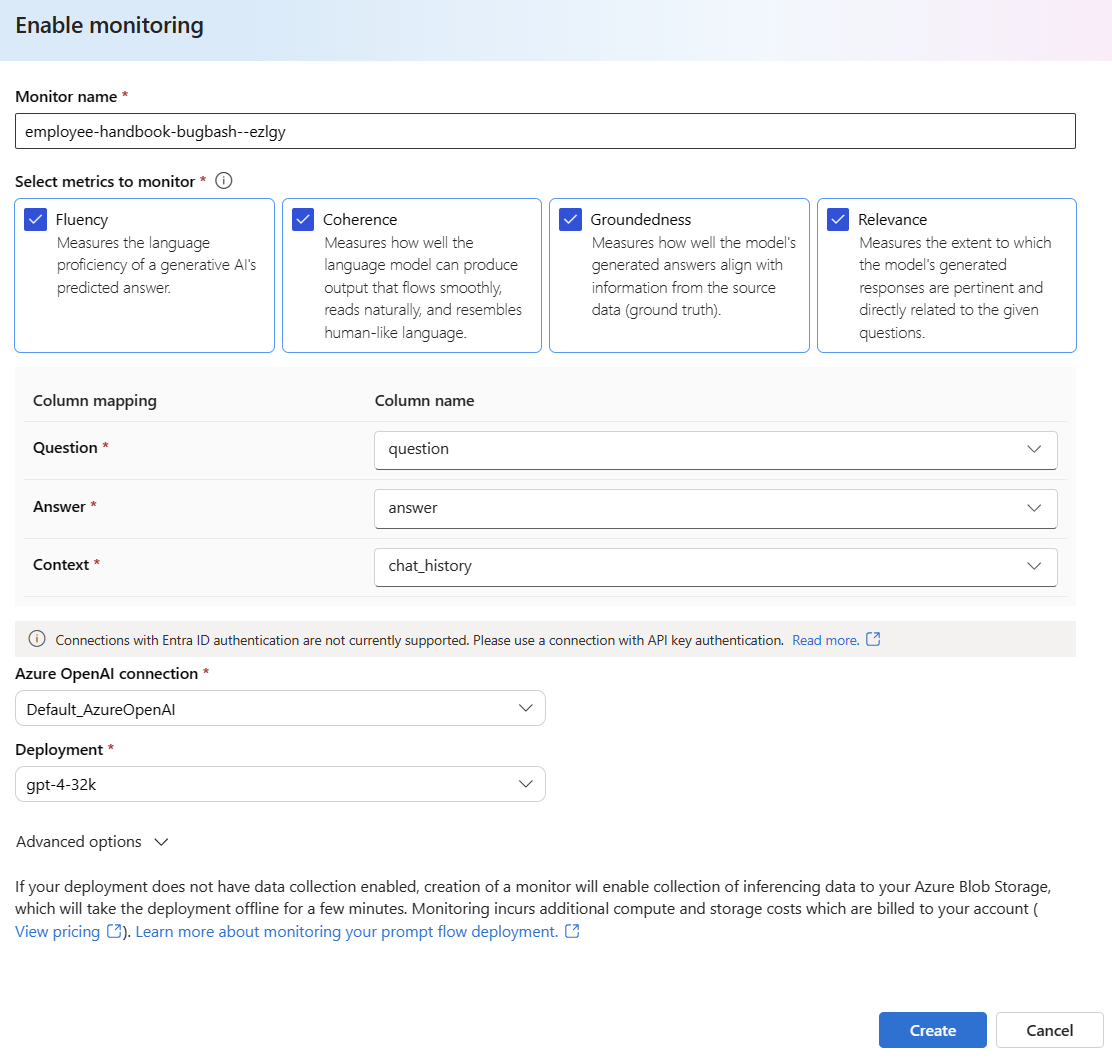
Pas de steekproeffrequentie, drempelwaarden voor uw geconfigureerde metrische gegevens aan en geef de e-mailadressen op die waarschuwingen moeten ontvangen wanneer de gemiddelde score voor een bepaalde metriek onder de drempelwaarde valt.
Notitie
Als voor uw implementatie geen gegevensverzameling is ingeschakeld, schakelt u het maken van een monitor het verzamelen van de deductiegegevens in uw Azure Blob Storage in. Hierdoor wordt de implementatie enkele minuten offline gehaald.
Selecteer Maken om uw monitor te maken.



Bewakingsresultaten gebruiken
Nadat u uw monitor hebt gemaakt, wordt deze dagelijks uitgevoerd om het tokengebruik te berekenen en metrische gegevens over de kwaliteit te genereren.
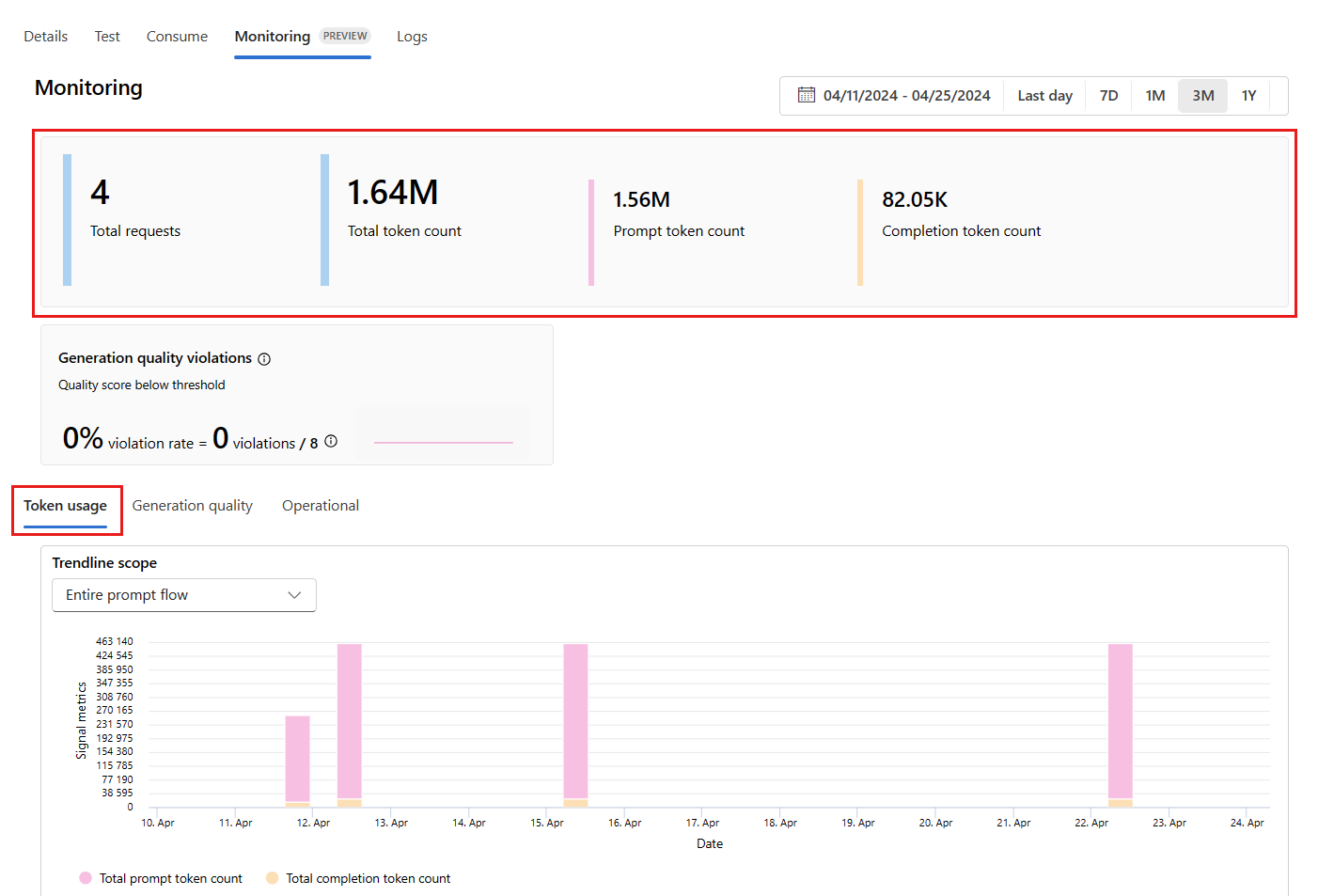
Ga vanuit de implementatie naar het tabblad Bewaking (preview) om de bewakingsresultaten weer te geven. Hier ziet u een overzicht van de bewakingsresultaten tijdens het geselecteerde tijdvenster. U kunt de datumkiezer gebruiken om het tijdvenster te wijzigen van gegevens die u bewaakt. De volgende metrische gegevens zijn beschikbaar in dit overzicht:
- Totaal aantal aanvragen: het totale aantal aanvragen dat tijdens het geselecteerde tijdvenster naar de implementatie is verzonden.
- Totaal aantal tokens: het totale aantal tokens dat door de implementatie wordt gebruikt tijdens het geselecteerde tijdvenster.
- Aantal prompttoken: het aantal prompttokens dat door de implementatie wordt gebruikt tijdens het geselecteerde tijdvenster.
- Aantal voltooiingstokens: het aantal voltooiingstokens dat door de implementatie wordt gebruikt tijdens het geselecteerde tijdvenster.
Bekijk de metrische gegevens op het tabblad Tokengebruik (dit tabblad is standaard geselecteerd). Hier kunt u het tokengebruik van uw toepassing in de loop van de tijd bekijken. U kunt ook de distributie van prompt- en voltooiingstokens in de loop van de tijd bekijken. U kunt het bereik Trendlijn wijzigen om alle tokens in de hele toepassing of het tokengebruik te controleren voor een bepaalde implementatie (bijvoorbeeld gpt-4) die in uw toepassing worden gebruikt.
Ga naar het tabblad Kwaliteit genereren om de kwaliteit van uw toepassing in de loop van de tijd te controleren. De volgende metrische gegevens worden weergegeven in het tijdsdiagram:
- Aantal schendingen: het aantal schendingen voor een bepaalde metrische waarde (bijvoorbeeld Fluency) is de som van schendingen in het geselecteerde tijdvenster. Er treedt een schending op voor een metrische waarde wanneer de metrische gegevens worden berekend (standaard is dagelijks) als de berekende waarde voor de metrische waarde lager is dan de ingestelde drempelwaarde.
- Gemiddelde score: de gemiddelde score voor een bepaalde metriek (bijvoorbeeld Fluency) is de som van de scores voor alle exemplaren (of aanvragen) gedeeld door het aantal exemplaren (of aanvragen) in het geselecteerde tijdvenster.
In de kaart Kwaliteitsschendingen van de generatie wordt de schendingsfrequentie in het geselecteerde tijdvenster weergegeven. Het schendingspercentage is het aantal schendingen gedeeld door het totale aantal mogelijke schendingen. U kunt de drempelwaarden voor metrische gegevens in de instellingen aanpassen. Standaard worden metrische gegevens dagelijks berekend; deze frequentie kan ook worden aangepast in de instellingen.
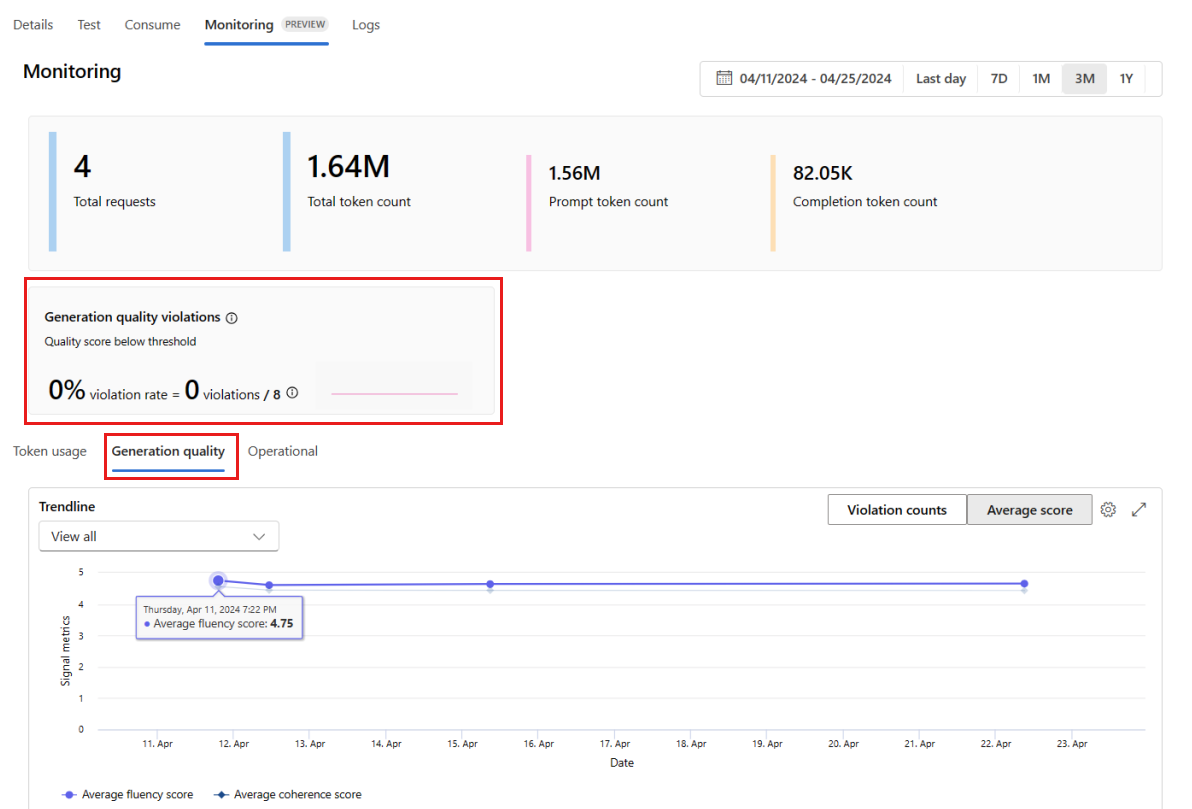
Op het tabblad Bewaking (preview) kunt u ook een uitgebreide tabel weergeven met alle voorbeeldaanvragen die tijdens het geselecteerde tijdvenster naar de implementatie zijn verzonden.
Notitie
Met bewaking wordt de standaardsampling ingesteld op 10%. Dit betekent dat als er 100 aanvragen naar uw implementatie worden verzonden, er 10 worden gesampleerd en gebruikt om de metrische gegevens van de generatiekwaliteit te berekenen. U kunt de samplingfrequentie in de instellingen aanpassen.
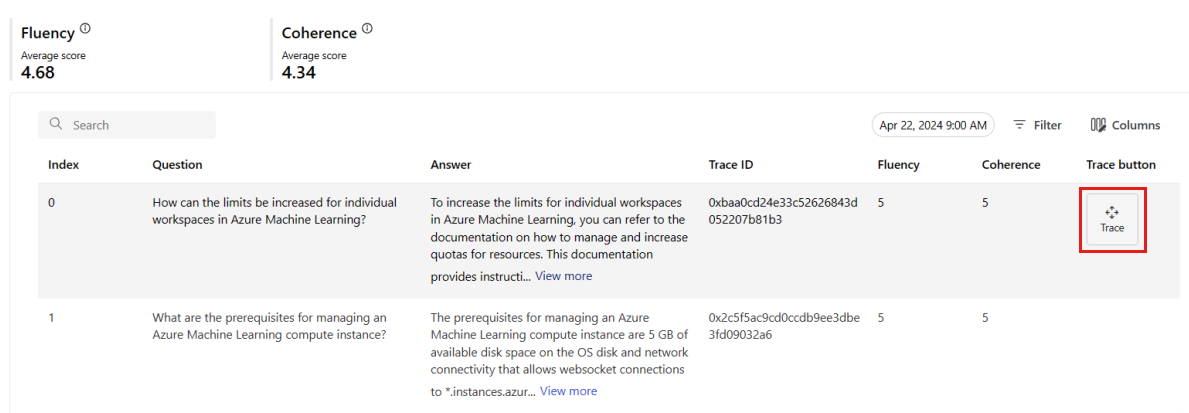
Selecteer de knop Traceren aan de rechterkant van een rij in de tabel om traceringsgegevens voor een bepaalde aanvraag weer te geven. Deze weergave biedt uitgebreide traceringsdetails voor de aanvraag voor uw toepassing.
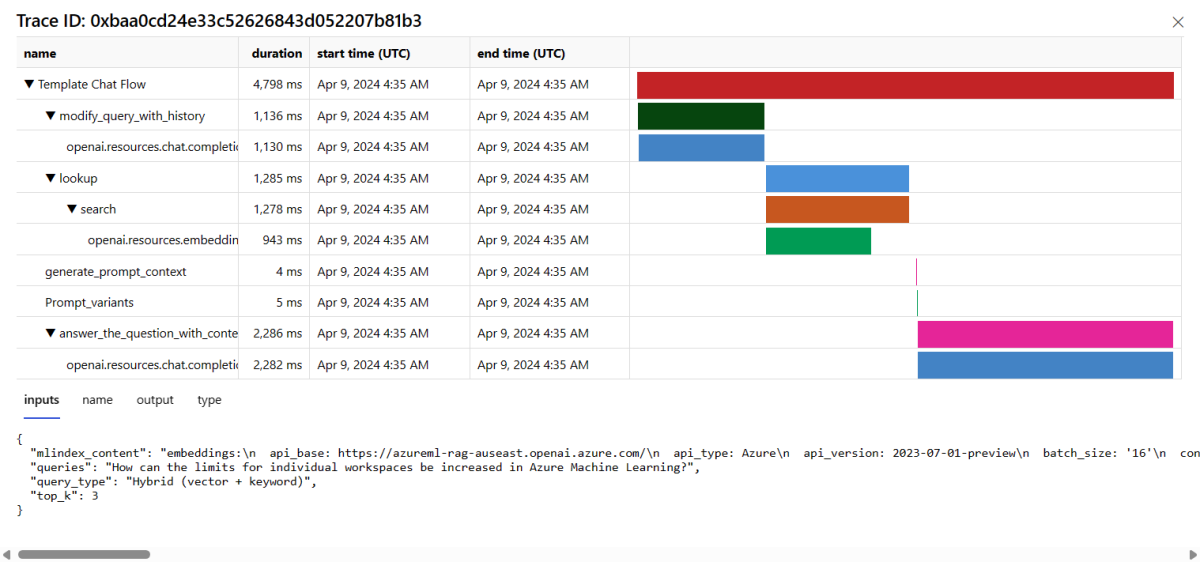
Sluit de traceringsweergave.
Ga naar het tabblad Operationeel om de operationele metrische gegevens voor de implementatie in bijna realtime weer te geven. We ondersteunen de volgende operationele metrische gegevens:
- Aantal aanvragen
- Latentie
- Foutpercentage






De resultaten op het tabblad Bewaking (preview) van uw implementatie bieden inzicht in de prestaties van uw promptstroomtoepassing.
Geavanceerde bewakingsconfiguratie met SDK v2
Bewaking biedt ook ondersteuning voor geavanceerde configuratieopties met de SDK v2. De volgende scenario's worden ondersteund:
Bewaking inschakelen voor tokengebruik
Als u alleen de bewaking van tokengebruik voor uw geïmplementeerde promptstroomtoepassing wilt inschakelen, kunt u het volgende script aanpassen aan uw scenario:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationTokenStatisticsSignal,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
# These variables can be renamed but it is not necessary
monitor_name ="gen_ai_monitor_tokens"
defaulttokenstatisticssignalname ="token-usage-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Create an instance of token statistic signal
token_statistic_signal = GenerationTokenStatisticsSignal()
monitoring_signals = {
defaulttokenstatisticssignalname: token_statistic_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Bewaking voor generatiekwaliteit inschakelen
Als u alleen kwaliteitsbewaking voor de implementatiepromptstroomtoepassing wilt inschakelen, kunt u het volgende script aanpassen aan uw scenario:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationSafetyQualityMonitoringMetricThreshold,
GenerationSafetyQualitySignal,
BaselineDataRange,
LlmData,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
aoai_deployment_name ="INSERT YOUR AOAI DEPLOYMENT NAME"
aoai_connection_name = "INSERT YOUR AOAI CONNECTION NAME"
# These variables can be renamed but it is not necessary
app_trace_name = "app_traces"
app_trace_Version = "1"
monitor_name ="gen_ai_monitor_generation_quality"
defaultgsqsignalname ="gsq-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Set thresholds for passing rate (0.7 = 70%)
aggregated_groundedness_pass_rate = 0.7
aggregated_relevance_pass_rate = 0.7
aggregated_coherence_pass_rate = 0.7
aggregated_fluency_pass_rate = 0.7
# Create an instance of gsq signal
generation_quality_thresholds = GenerationSafetyQualityMonitoringMetricThreshold(
groundedness = {"aggregated_groundedness_pass_rate": aggregated_groundedness_pass_rate},
relevance={"aggregated_relevance_pass_rate": aggregated_relevance_pass_rate},
coherence={"aggregated_coherence_pass_rate": aggregated_coherence_pass_rate},
fluency={"aggregated_fluency_pass_rate": aggregated_fluency_pass_rate},
)
input_data = Input(
type="uri_folder",
path=f"{endpoint_name}-{deployment_name}-{app_trace_name}:{app_trace_Version}",
)
data_window = BaselineDataRange(lookback_window_size="P7D", lookback_window_offset="P0D")
production_data = LlmData(
data_column_names={"prompt_column": "question", "completion_column": "answer", "context_column": "context"},
input_data=input_data,
data_window=data_window,
)
gsq_signal = GenerationSafetyQualitySignal(
connection_id=f"/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{project_name}/connections/{aoai_connection_name}",
metric_thresholds=generation_quality_thresholds,
production_data=[production_data],
sampling_rate=1.0,
properties={
"aoai_deployment_name": aoai_deployment_name,
"enable_action_analyzer": "false",
"azureml.modelmonitor.gsq_thresholds": '[{"metricName":"average_fluency","threshold":{"value":4}},{"metricName":"average_coherence","threshold":{"value":4}}]',
},
)
monitoring_signals = {
defaultgsqsignalname: gsq_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Nadat u uw monitor hebt gemaakt vanuit de SDK, kunt u de bewakingsresultaten gebruiken in de Azure AI Foundry-portal.
Gerelateerde inhoud
- Meer informatie over wat u kunt doen in Azure AI Foundry.
- Krijg antwoorden op veelgestelde vragen in het artikel veelgestelde vragen over Azure AI.