Generatieve AI-modellen en -toepassingen evalueren met Azure AI Foundry
Als u de prestaties van uw generatieve AI-modellen en -toepassingen grondig wilt evalueren wanneer deze worden toegepast op een aanzienlijke gegevensset, kunt u een evaluatieproces starten. Tijdens deze evaluatie wordt uw model of toepassing getest met de opgegeven gegevensset en worden de prestaties kwantitatief gemeten met zowel wiskundige metrische gegevens als ai-ondersteunde metrische gegevens. Deze evaluatieuitvoering biedt u uitgebreide inzichten in de mogelijkheden en beperkingen van de toepassing.
Als u deze evaluatie wilt uitvoeren, kunt u gebruikmaken van de evaluatiefunctionaliteit in de Azure AI Foundry-portal, een uitgebreid platform dat hulpprogramma's en functies biedt voor het beoordelen van de prestaties en veiligheid van uw generatieve AI-model. In de Azure AI Foundry-portal kunt u gedetailleerde metrische evaluatiegegevens registreren, weergeven en analyseren.
In dit artikel leert u hoe u een evaluatieuitvoering maakt op basis van een model, een testgegevensset of een stroom met ingebouwde metrische evaluatiegegevens van Azure AI Foundry. Voor meer flexibiliteit kunt u een aangepaste evaluatiestroom instellen en de aangepaste evaluatiefunctie gebruiken. Als u alleen een batchuitvoering wilt uitvoeren zonder evaluatie, kunt u ook de aangepaste evaluatiefunctie gebruiken.
Vereisten
Als u een evaluatie wilt uitvoeren met met AI ondersteunde metrische gegevens, moet u het volgende gereed hebben:
- Een testgegevensset in een van deze indelingen:
csvofjsonl. - Een Azure OpenAI-verbinding. Een implementatie van een van deze modellen: GPT 3.5-modellen, GPT 4-modellen of Davinci-modellen. Alleen vereist wanneer u ai-ondersteunde kwaliteitsevaluatie uitvoert.
Een evaluatie maken met ingebouwde metrische evaluatiegegevens
Met een evaluatieuitvoering kunt u metrische uitvoer genereren voor elke gegevensrij in uw testgegevensset. U kunt een of meer metrische evaluatiegegevens kiezen om de uitvoer van verschillende aspecten te beoordelen. U kunt een evaluatieuitvoering maken vanuit de evaluatie-, modelcatalogus- of promptstroompagina's in de Azure AI Foundry-portal. Vervolgens wordt een wizard voor het maken van een evaluatie weergegeven om u te begeleiden bij het instellen van een evaluatieuitvoering.
Vanaf de evaluatiepagina
Selecteer Evaluatie>+ Een nieuwe evaluatie maken in het samenvouwbare linkermenu.

Vanaf de pagina modelcatalogus
Selecteer in het samenvouwbare linkermenu modelcatalogus> naar het specifieke model > navigeren naar het tabblad > Benchmark. Probeer het met uw eigen gegevens. Hiermee opent u het evaluatiepaneel van het model om een evaluatieuitvoering te maken op basis van het geselecteerde model.

Vanaf de stroompagina
Selecteer in het samenvouwbare linkermenu promptstroom>Geautomatiseerde evaluatie evalueren>.

Evaluatiedoel
Wanneer u een evaluatie start vanaf de evaluatiepagina, moet u beslissen wat het evaluatiedoel is. Door het juiste evaluatiedoel op te geven, kunnen we de evaluatie aanpassen aan de specifieke aard van uw toepassing, zodat nauwkeurige en relevante metrische gegevens worden gegarandeerd. We ondersteunen drie soorten evaluatiedoel:
- Model en prompt: u wilt de uitvoer evalueren die is gegenereerd door het geselecteerde model en de door de gebruiker gedefinieerde prompt.
- Gegevensset: U hebt uw model al uitvoer gegenereerd in een testgegevensset.
- Promptstroom: u hebt een stroom gemaakt en u wilt de uitvoer van de stroom evalueren.

Evaluatie van gegevensset of promptstroom
Wanneer u de wizard voor het maken van de evaluatie invoert, kunt u een optionele naam opgeven voor de uitvoering van de evaluatie. We bieden momenteel ondersteuning voor het query- en antwoordscenario, dat is ontworpen voor toepassingen die betrekking hebben op het beantwoorden van gebruikersquery's en het leveren van antwoorden met of zonder contextinformatie.
U kunt desgewenst beschrijvingen en tags toevoegen aan evaluatieuitvoeringen voor verbeterde organisatie, context en gebruiksgemak.
U kunt ook het Help-deelvenster gebruiken om de veelgestelde vragen te controleren en uzelf door de wizard te leiden.

Als u een promptstroom evalueert, kunt u de stroom selecteren die u wilt evalueren. Als u de evaluatie start vanaf de pagina Flow, selecteren we automatisch uw stroom die u wilt evalueren. Als u een andere stroom wilt evalueren, kunt u een andere stroom selecteren. Het is belangrijk te weten dat u binnen een stroom meerdere knooppunten hebt, die elk een eigen set varianten kunnen hebben. In dergelijke gevallen moet u het knooppunt en de varianten opgeven die u tijdens het evaluatieproces wilt evalueren.

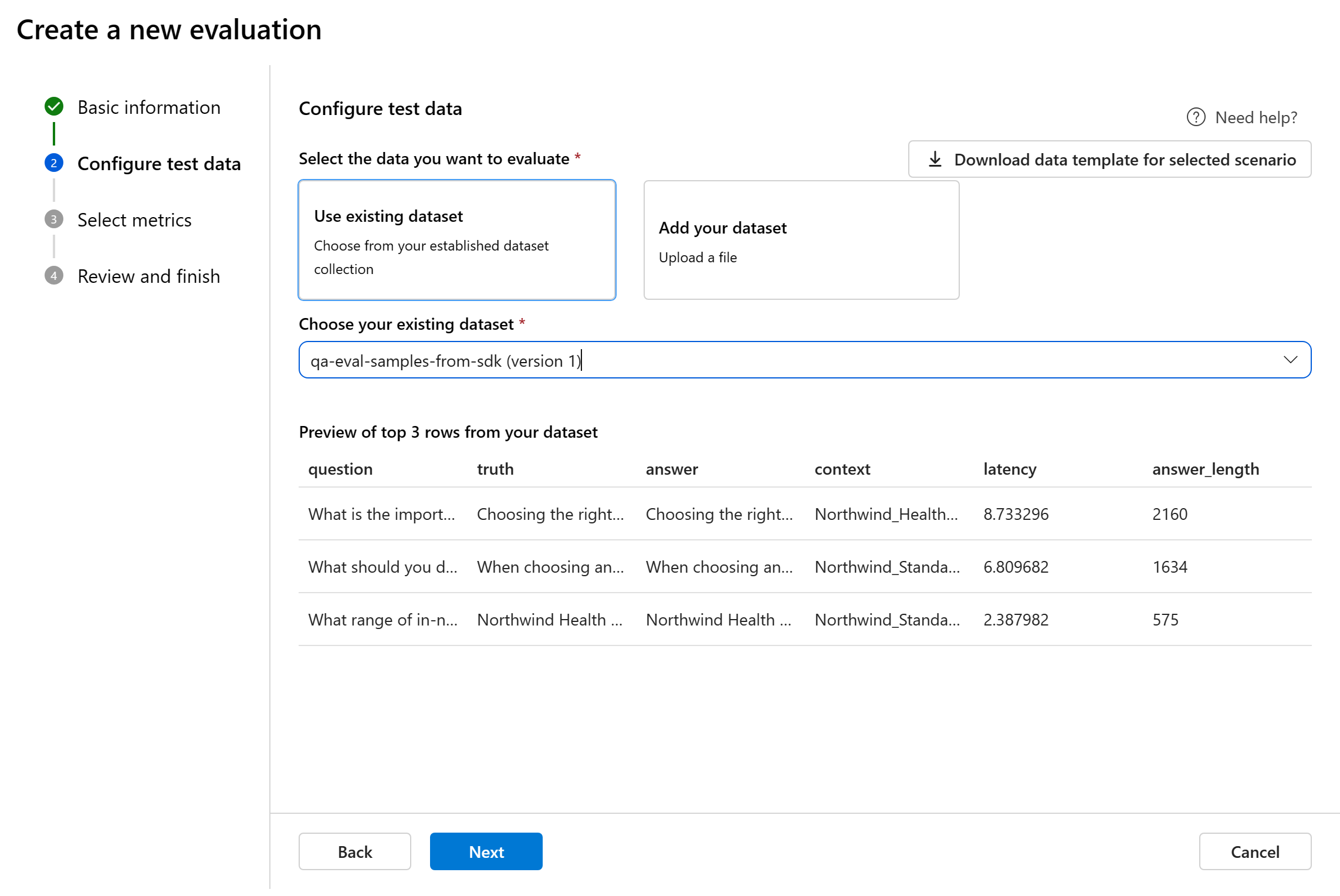
Testgegevens configureren
U kunt kiezen uit bestaande gegevenssets of een nieuwe gegevensset uploaden om te evalueren. In de testgegevensset moet het model gegenereerde uitvoer worden gebruikt voor evaluatie als er in de vorige stap geen stroom is geselecteerd.
Kies een bestaande gegevensset: u kunt de testgegevensset kiezen uit uw bestaande gegevenssetverzameling.
Nieuwe gegevensset toevoegen: U kunt bestanden uploaden vanuit uw lokale opslag. We ondersteunen
.csvalleen bestandsindelingen en.jsonlbestandsindelingen.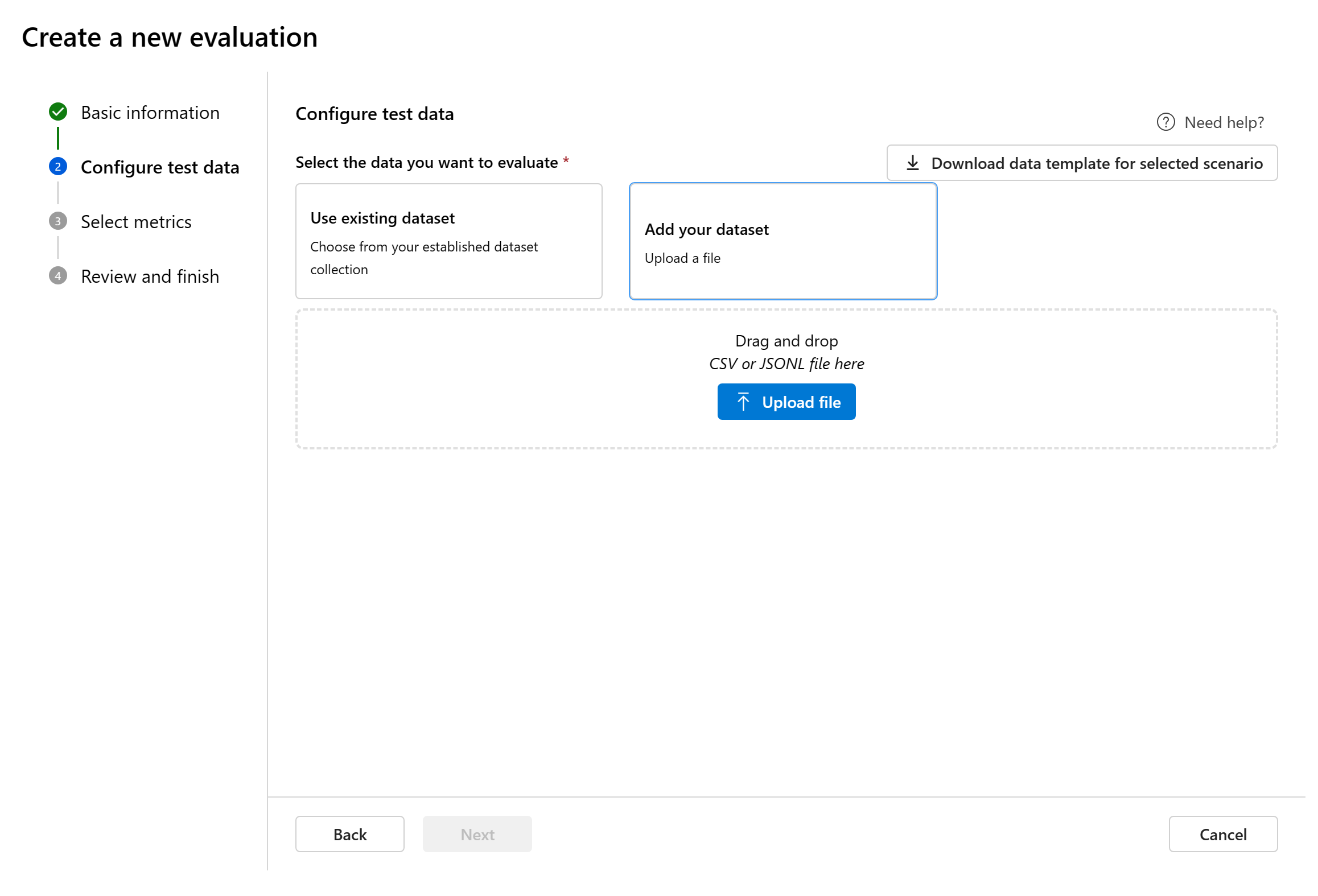
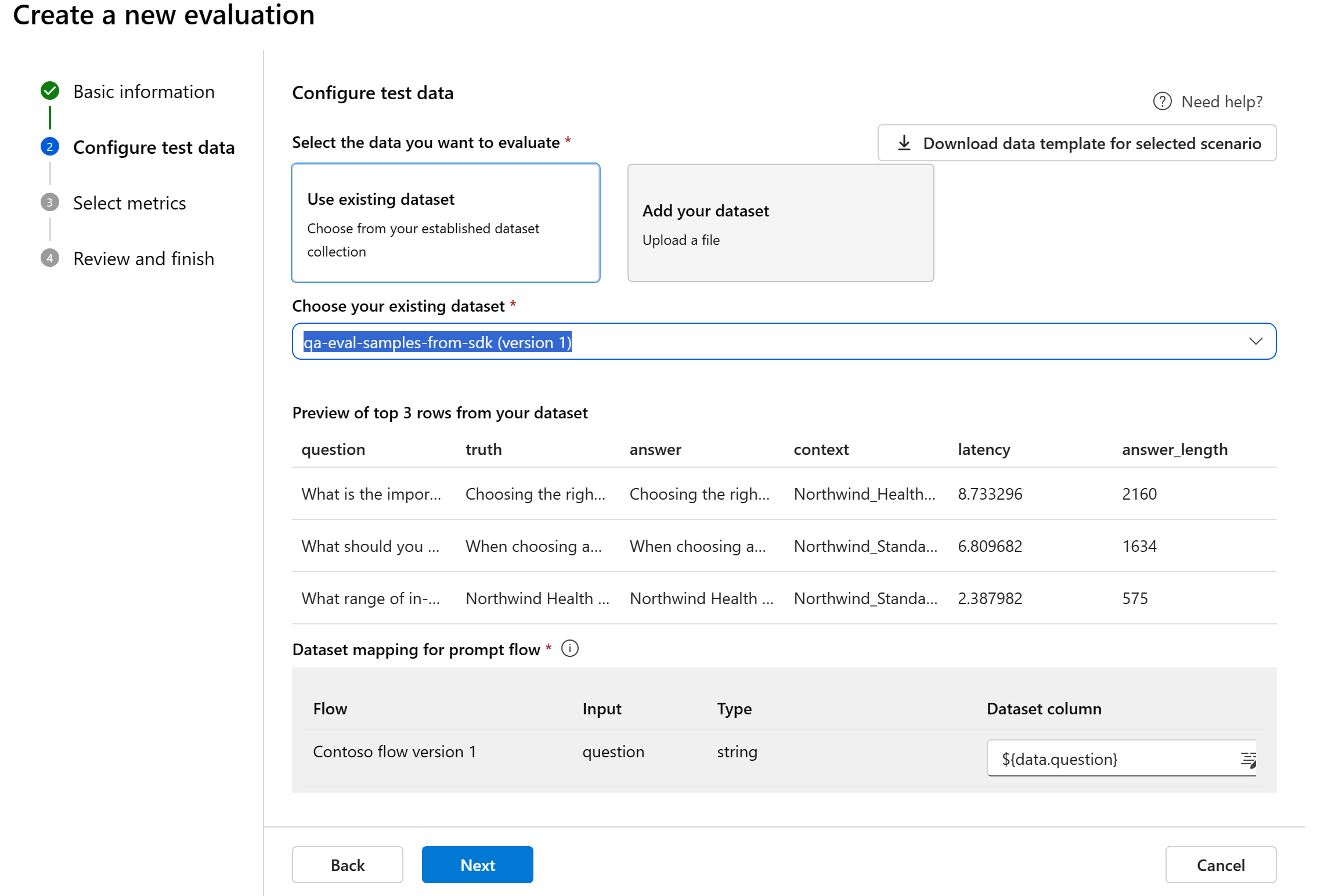
Gegevenstoewijzing voor stroom: Als u een te evalueren stroom selecteert, moet u ervoor zorgen dat uw gegevenskolommen zijn geconfigureerd om te worden afgestemd op de vereiste invoer voor de stroom om een batchuitvoering uit te voeren, waardoor uitvoer voor evaluatie wordt gegenereerd. De evaluatie wordt vervolgens uitgevoerd met behulp van de uitvoer van de stroom. Configureer vervolgens de gegevenstoewijzing voor evaluatie-invoer in de volgende stap.



Metrische gegevens selecteren
We ondersteunen drie soorten metrische gegevens die door Microsoft worden samengesteld om een uitgebreide evaluatie van uw toepassing mogelijk te maken:
- AI-kwaliteit (AI ondersteund): deze metrische gegevens evalueren de algehele kwaliteit en samenhang van de gegenereerde inhoud. Voor het uitvoeren van deze metrische gegevens is een modelimplementatie als rechter vereist.
- AI-kwaliteit (NLP): deze NLP-metrische gegevens zijn wiskundig gebaseerd en ze evalueren ook de algehele kwaliteit van de gegenereerde inhoud. Ze vereisen vaak grondwaargegevens, maar ze vereisen geen modelimplementatie als rechter.
- Metrische gegevens over risico's en veiligheid: deze metrische gegevens richten zich op het identificeren van potentiële inhoudsrisico's en het waarborgen van de veiligheid van de gegenereerde inhoud.

U kunt de tabel raadplegen voor de volledige lijst met metrische gegevens die in elk scenario worden ondersteund. Zie De metrische gegevens evalueren en bewaken voor meer gedetailleerde informatie over elke definitie van metrische gegevens en hoe deze worden berekend.
| AI-kwaliteit (ai ondersteund) | AI-kwaliteit (NLP) | Metrische gegevens over risico en veiligheid |
|---|---|---|
| Geaardheid, relevantie, coherentie, fluency, GPT-gelijkenis | F1 score, ROUGE, score, BLEU score, GLEU score, METEOR score | Aan zichzelf gerelateerde inhoud, haatvolle en oneerlijke inhoud, gewelddadige inhoud, seksuele inhoud, beschermd materiaal, indirecte aanval |
Bij het uitvoeren van ai-ondersteunde kwaliteitsevaluatie moet u een GPT-model opgeven voor het berekeningsproces. Kies een Azure OpenAI-verbinding en een implementatie met GPT-3.5, GPT-4 of het Davinci-model voor onze berekeningen.

Metrische gegevens van AI Quality (NLP) zijn wiskundig gebaseerde metingen waarmee de prestaties van uw toepassing worden beoordeeld. Ze vereisen vaak grondwaargegevens voor berekening. ROUGE is een familie van metrische gegevens. U kunt het TYPE ROUGE selecteren om de scores te berekenen. Verschillende soorten metrische GEGEVENS VAN ROUGE bieden manieren om de kwaliteit van het genereren van tekst te evalueren. ROUGE-N meet de overlapping van n-grammen tussen de kandidaat en referentieteksten.

Voor metrische gegevens over risico's en veiligheid hoeft u geen verbinding en implementatie te bieden. De back-endservice van de Azure AI Foundry-portal voorziet in een GPT-4-model waarmee ernstscores en redeneringen voor inhoudsrisico's kunnen worden gegenereerd, zodat u uw toepassing kunt evalueren op inhoudsschade.
U kunt de drempelwaarde instellen voor het berekenen van de defectfrequentie voor de metrische gegevens over inhoudsschade (inhoud die betrekking heeft op zelfschade, haatvolle en oneerlijke inhoud, gewelddadige inhoud, seksuele inhoud). De defectsnelheid wordt berekend door een percentage exemplaren met ernstniveaus (zeer laag, Laag, Gemiddeld, Hoog) boven een drempelwaarde te nemen. Standaard stellen we de drempelwaarde in als 'Gemiddeld'.
Voor beveiligde materialen en indirecte aanvallen wordt de defectsnelheid berekend door een percentage exemplaren te nemen waarbij de uitvoer 'true' is (Defect Rate = (#trues / #instances) × 100).

Notitie
Met AI ondersteunde risico- en veiligheidsstatistieken worden gehost door de back-endservice van Azure AI Foundry-veiligheidsevaluaties en is alleen beschikbaar in de volgende regio's: VS - oost 2, Frankrijk - centraal, VK - zuid, Zweden - centraal
Gegevenstoewijzing voor evaluatie: u moet opgeven welke gegevenskolommen in uw gegevensset overeenkomen met de invoer die nodig is in de evaluatie. Verschillende metrische evaluatiegegevens vragen om verschillende typen gegevensinvoer voor nauwkeurige berekeningen.

Notitie
Als u evalueert op basis van gegevens, moet 'antwoord' worden toegewezen aan de antwoordkolom in uw gegevensset ${data$response}. Als u van stroom evalueert, moet 'antwoord' afkomstig zijn van stroomuitvoer ${run.outputs.response}.
Raadpleeg de informatie in de tabel voor hulp bij de specifieke vereisten voor gegevenstoewijzing voor elke metriek:
Metrische vereisten voor query's en antwoorden
| Metrische gegevens | Query | Respons | Context | Grondwaar |
|---|---|---|---|---|
| Grondgebondenheid | Vereist: Str | Vereist: Str | Vereist: Str | N.v.t. |
| Samenhang | Vereist: Str | Vereist: Str | N.v.t. | N.v.t. |
| Vlotheid | Vereist: Str | Vereist: Str | N.v.t. | N.v.t. |
| Relevantie | Vereist: Str | Vereist: Str | Vereist: Str | N.v.t. |
| GPT-gelijkenis | Vereist: Str | Vereist: Str | N.v.t. | Vereist: Str |
| F1-score | N.v.t. | Vereist: Str | N.v.t. | Vereist: Str |
| BLEU-score | N.v.t. | Vereist: Str | N.v.t. | Vereist: Str |
| GLEU-score | N.v.t. | Vereist: Str | N.v.t. | Vereist: Str |
| METEOR-score | N.v.t. | Vereist: Str | N.v.t. | Vereist: Str |
| ROUGE-score | N.v.t. | Vereist: Str | N.v.t. | Vereist: Str |
| Inhoud met betrekking tot zelfschade | Vereist: Str | Vereist: Str | N.v.t. | N.v.t. |
| Haatvolle en oneerlijke inhoud | Vereist: Str | Vereist: Str | N.v.t. | N.v.t. |
| Gewelddadige inhoud | Vereist: Str | Vereist: Str | N.v.t. | N.v.t. |
| Seksuele inhoud | Vereist: Str | Vereist: Str | N.v.t. | N.v.t. |
| Beschermd materiaal | Vereist: Str | Vereist: Str | N.v.t. | N.v.t. |
| Indirecte aanval | Vereist: Str | Vereist: Str | N.v.t. | N.v.t. |
- Query: een query die specifieke informatie zoekt.
- Antwoord: het antwoord op de query die door het model wordt gegenereerd.
- Context: de bron die wordt gegenereerd met betrekking tot (dat wil gezegd, documenten grounding)...
- Grond waarheid: het antwoord op query gegenereerd door gebruiker/mens als het ware antwoord.
Controleren en voltooien
Nadat u alle benodigde configuraties hebt voltooid, kunt u controleren en doorgaan met het selecteren van Verzenden om de evaluatieuitvoering te verzenden.

Model en prompt-evaluatie
Als u een nieuwe evaluatie wilt maken voor uw geselecteerde modelimplementatie en een gedefinieerde prompt, gebruikt u het vereenvoudigde deelvenster voor modelevaluatie. Met deze gestroomlijnde interface kunt u evaluaties in één geconsolideerd deelvenster configureren en initiëren.
Algemene informatie
Als u wilt beginnen, kunt u de naam voor de evaluatieuitvoering instellen. Selecteer vervolgens de modelimplementatie die u wilt evalueren. We ondersteunen zowel Azure OpenAI-modellen als andere open modellen die compatibel zijn met Model-as-a-Service (MaaS), zoals Meta Llama en Phi-3-familiemodellen. U kunt desgewenst de modelparameters aanpassen, zoals maximale reactie, temperatuur en top P op basis van uw behoeften.
Geef in het tekstvak Systeembericht de prompt op voor uw scenario. Zie de promptcatalogus voor meer informatie over het maken van uw prompt. U kunt ervoor kiezen om een voorbeeld toe te voegen om de chat weer te geven welke antwoorden u wilt geven. Er wordt geprobeerd antwoorden die u hier toevoegt na te bootsen om ervoor te zorgen dat deze overeenkomen met de regels die u in het systeembericht hebt opgesteld.

Testgegevens configureren
Na het configureren van het model en de prompt stelt u de testgegevensset in die wordt gebruikt voor evaluatie. Deze gegevensset wordt naar het model verzonden om antwoorden voor evaluatie te genereren. U hebt drie opties voor het configureren van uw testgegevens:
- Voorbeeldgegevens genereren
- Bestaande gegevensset gebruiken
- Uw gegevensset toevoegen
Als u geen gegevensset beschikbaar hebt en een evaluatie wilt uitvoeren met een klein voorbeeld, kunt u de optie selecteren om een GPT-model te gebruiken om voorbeeldvragen te genereren op basis van het gekozen onderwerp. Het onderwerp helpt bij het aanpassen van de gegenereerde inhoud aan uw interessegebied. De query's en antwoorden worden in realtime gegenereerd en u kunt ze indien nodig opnieuw genereren.
Notitie
De gegenereerde gegevensset wordt opgeslagen in de blobopslag van het project zodra de evaluatie is gemaakt.

Gegevenstoewijzing
Als u ervoor kiest om een bestaande gegevensset te gebruiken of een nieuwe gegevensset te uploaden, moet u de kolommen van uw gegevensset toewijzen aan de vereiste velden voor evaluatie. Tijdens de evaluatie wordt het antwoord van het model beoordeeld op basis van sleutelinvoer, zoals:
- Query: vereist voor alle metrische gegevens
- Context: optioneel
- Grondwaar: optioneel, vereist voor metrische gegevens van AI-kwaliteit (NLP)
Deze toewijzingen zorgen voor een nauwkeurige afstemming tussen uw gegevens en de evaluatiecriteria.

Metrische evaluatiegegevens kiezen
De laatste stap is om te selecteren wat u wilt evalueren. In plaats van afzonderlijke metrische gegevens te selecteren en vertrouwd te raken met alle beschikbare opties, vereenvoudigen we het proces door u in staat te stellen om metrische categorieën te selecteren die het beste aan uw behoeften voldoen. Wanneer u een categorie kiest, worden alle relevante metrische gegevens in die categorie berekend op basis van de gegevenskolommen die u in de vorige stap hebt opgegeven. Zodra u de metrische categorieën hebt geselecteerd, kunt u Maken selecteren om de evaluatieuitvoering in te dienen en naar de evaluatiepagina gaan om de resultaten te bekijken.
We ondersteunen drie categorieën:
- AI-kwaliteit (ai ondersteund): u moet een Azure OpenAI-modelimplementatie bieden als rechter om de met AI ondersteunde metrische gegevens te berekenen.
- AI-kwaliteit (NLP)
- Veiligheid
| AI-kwaliteit (ai ondersteund) | AI-kwaliteit (NLP) | Veiligheid |
|---|---|---|
| Geaardheid (context vereisen), Relevantie (context vereisen), Coherentie, Vloeiendheid | F1 score, ROUGE, score, BLEU score, GLEU score, METEOR score | Aan zichzelf gerelateerde inhoud, haatvolle en oneerlijke inhoud, gewelddadige inhoud, seksuele inhoud, beschermd materiaal, indirecte aanval |
Een evaluatie maken met een aangepaste evaluatiestroom
U kunt uw eigen evaluatiemethoden ontwikkelen:
Op de stroompagina: Selecteer in het samenvouwbare linkermenu promptstroom>>Evaluatie aangepaste evaluatie.

De evaluators in de evaluatorbibliotheek weergeven en beheren
De evaluatorbibliotheek is een centrale locatie waarmee u de details en status van uw evaluators kunt bekijken. U kunt gecureerde evaluators van Microsoft bekijken en beheren.
Tip
U kunt aangepaste evaluators gebruiken via de promptstroom-SDK. Zie Evalueren met de promptstroom-SDK voor meer informatie.
De evaluatorbibliotheek maakt ook versiebeheer mogelijk. U kunt verschillende versies van uw werk vergelijken, eerdere versies herstellen indien nodig en gemakkelijker samenwerken met anderen.
Als u de evaluatorbibliotheek in de Azure AI Foundry-portal wilt gebruiken, gaat u naar de evaluatiepagina van uw project en selecteert u het tabblad Evaluator-bibliotheek.

U kunt de naam van de evaluator selecteren voor meer informatie. U kunt de naam, beschrijving en parameters zien en alle bestanden controleren die zijn gekoppeld aan de evaluator. Hier volgen enkele voorbeelden van door Microsoft samengestelde evaluators:
- Voor prestatie- en kwaliteits evaluators die door Microsoft zijn samengesteld, kunt u de aantekeningsprompt bekijken op de detailpagina. U kunt deze prompts aanpassen aan uw eigen use-case door de parameters of criteria te wijzigen op basis van uw gegevens en doelstellingen van de Azure AI Evaluation SDK. U kunt bijvoorbeeld Groundedness-Evaluator selecteren en het prompty-bestand controleren waarin wordt weergegeven hoe we de metrische gegevens berekenen.
- Voor risico- en veiligheids evaluators die door Microsoft zijn samengesteld, kunt u de definitie van de metrische gegevens bekijken. U kunt bijvoorbeeld de self-harm-related-content-evaluator selecteren en leren wat het betekent en hoe Microsoft de verschillende ernstniveaus voor deze veiligheidsmetriek bepaalt.
Volgende stappen
Meer informatie over het evalueren van uw generatieve AI-toepassingen:
- Evalueer uw generatieve AI-apps via de speeltuin
- De evaluatieresultaten weergeven
- Meer informatie over technieken voor schadebeperking.
- Transparantienotitie voor azure AI Foundry-veiligheidsevaluaties.