Als u een model wilt trainen, start u een trainingstaak. Alleen voltooide taken maken een model. Trainingstaken verlopen na zeven dagen. Na deze tijd kunt u de taakgegevens niet meer ophalen. Als uw trainingstaak is voltooid en er een model is gemaakt, wordt dit niet beïnvloed door het verlopen van de taak. U kunt slechts één trainingstaak tegelijk uitvoeren en u kunt geen andere taken in hetzelfde project starten.
De trainingstijden kunnen zich vanaf een paar seconden bevinden bij het omgaan met eenvoudige projecten, tot een paar uur wanneer u de maximumlimiet van utterances bereikt.
Modelevaluatie wordt automatisch geactiveerd nadat de training is voltooid. Het evaluatieproces begint met het getrainde model om voorspellingen uit te voeren op de uitingen in de testset en vergelijkt de voorspelde resultaten met de opgegeven labels (waarmee een basislijn van waarheid wordt vastgesteld). De resultaten worden geretourneerd, zodat u de prestaties van het model kunt bekijken.
Vereisten
Een project gemaakt met een geconfigureerd Azure Blob Storage-account
Voordat u het trainingsproces start, worden gelabelde uitingen in uw project onderverdeeld in een trainingsset en een testset. Elk van deze dient een andere functie.
De trainingsset wordt gebruikt bij het trainen van het model. Dit is de set waaruit het model de gelabelde uitingen leert.
De testset is een blinde set die tijdens de training niet is geïntroduceerd in het model, maar alleen tijdens de evaluatie.
Nadat het model is getraind, kan het model worden gebruikt om voorspellingen te doen van de uitingen in de testset. Deze voorspellingen worden gebruikt om metrische evaluatiegegevens te berekenen.
Het wordt aanbevolen om ervoor te zorgen dat al uw intenties adequaat worden vertegenwoordigd in zowel de trainings- als testset.
Indelingswerkstroom ondersteunt twee methoden voor het splitsen van gegevens:
Automatisch de testset splitsen op basis van trainingsgegevens: het systeem splitst uw getagde gegevens tussen de trainings- en testsets op basis van de percentages die u kiest. De aanbevolen percentagesplitsing is 80% voor training en 20% voor testen.
Notitie
Als u de testset automatisch splitst op basis van de optie trainingsgegevens , worden alleen de gegevens die aan de trainingsset zijn toegewezen, gesplitst volgens de opgegeven percentages.
Gebruik een handmatige splitsing van trainings- en testgegevens: met deze methode kunnen gebruikers definiëren welke utterances tot welke set moeten behoren. Deze stap is alleen ingeschakeld als u uitingen hebt toegevoegd aan uw testset tijdens het labelen.
Notitie
U kunt alleen utterances toevoegen in de trainingsgegevensset voor niet-verbonden intenties.
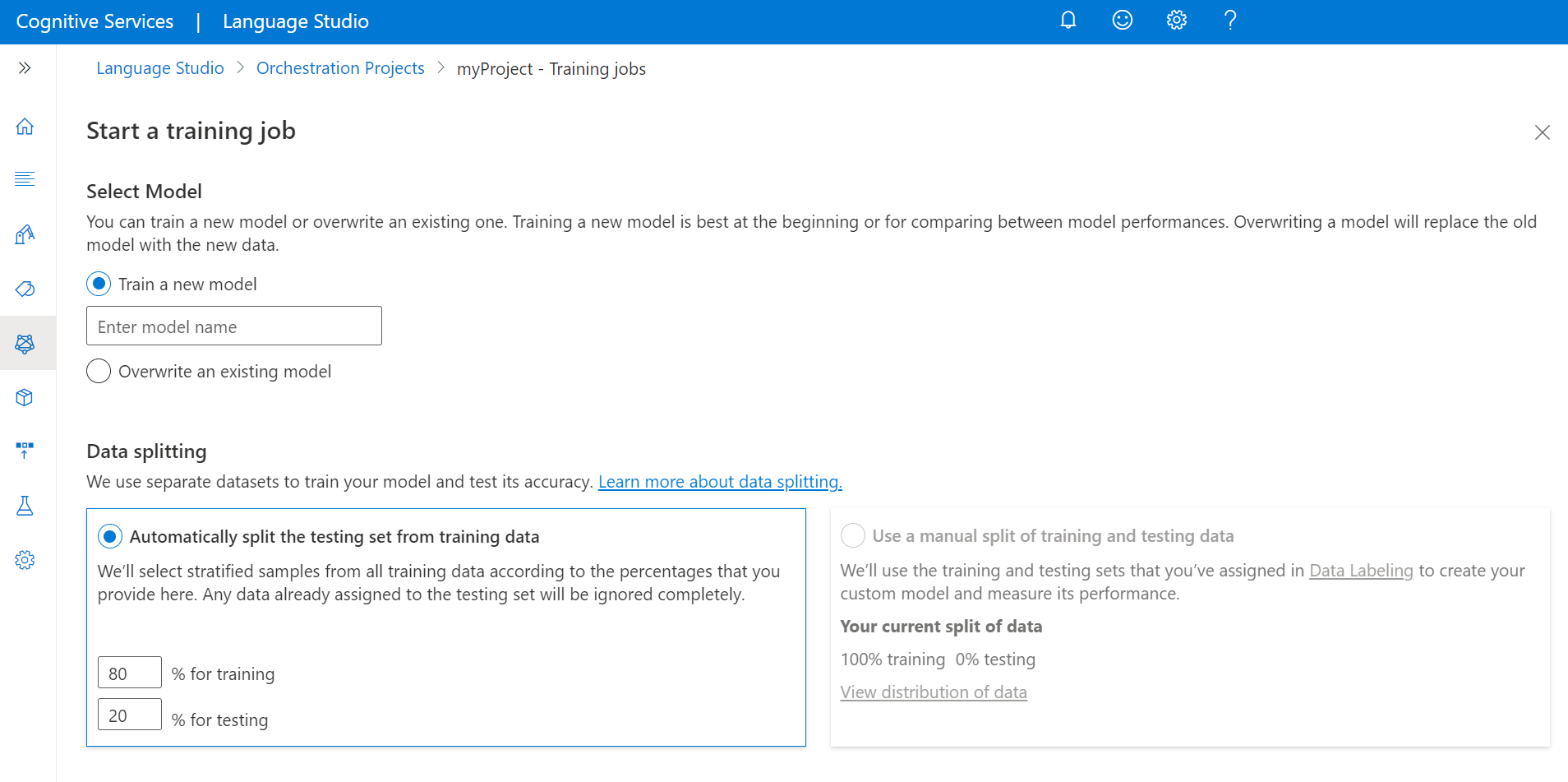
Ga als volgende te werk om uw model te trainen vanuit Language Studio:
Selecteer Trainingstaken in het menu aan de linkerkant.
Selecteer Een trainingstaak starten in het bovenste menu.
Selecteer Een nieuw model trainen en typ de naam van het model in het tekstvak. U kunt ook een bestaand model overschrijven door deze optie te selecteren en het model te kiezen dat u wilt overschrijven in de vervolgkeuzelijst. Het overschrijven van een getraind model kan niet ongedaan worden gemaakt, maar dit heeft geen invloed op uw geïmplementeerde modellen totdat u het nieuwe model implementeert.
Als u uw project hebt ingeschakeld om uw gegevens handmatig te splitsen bij het taggen van uw utterances, ziet u twee opties voor het splitsen van gegevens:
Automatisch de testset splitsen op basis van trainingsgegevens: uw getagde uitingen worden willekeurig verdeeld tussen de trainings- en testsets, afhankelijk van de percentages die u kiest. De standaardpercentagesplitsing is 80% voor training en 20% voor testen. Als u deze waarden wilt wijzigen, kiest u welke set u wilt wijzigen en typt u de nieuwe waarde.
Notitie
Als u de testset automatisch splitst op basis van de optie trainingsgegevens , worden alleen de uitingen in uw trainingsset gesplitst op basis van de opgegeven percentages.
Gebruik een handmatige splitsing van trainings- en testgegevens: wijs elke uiting toe aan de trainings- of testset tijdens de tagstap van het project.
Notitie
Gebruik een handmatige splitsing van de optie voor trainings- en testgegevens alleen als u uitingen toevoegt aan de testset op de pagina taggegevens. Anders wordt deze uitgeschakeld.
Selecteer de knop Trainen .
Notitie
Alleen voltooide trainingstaken genereren modellen.
Training kan enige tijd duren tussen een paar minuten en een paar uur op basis van de grootte van uw getagde gegevens.
U kunt slechts één trainingstaak tegelijk uitvoeren. U kunt geen andere trainingstaak starten voor hetzelfde project totdat de actieve taak is voltooid.
Maak een POST-aanvraag met behulp van de volgende URL, headers en JSON-hoofdtekst om een trainingstaak te verzenden.
Aanvraag-URL
Gebruik de volgende URL bij het maken van uw API-aanvraag. Vervang de waarden van de tijdelijke aanduiding hieronder door uw eigen waarden.
Trainingsmodus. Slechts één modus voor training is beschikbaar in indeling, dat wil standardwel.
standard
trainingConfigVersion
{CONFIG-VERSION}
De versie van het trainingsconfiguratiemodel. Standaard wordt de nieuwste modelversie gebruikt.
2022-05-01
kind
percentage
Splitsmethoden. Mogelijke waarden zijn percentage en manual. Zie hoe u een model traint voor meer informatie.
percentage
trainingSplitPercentage
80
Percentage van uw getagde gegevens die moeten worden opgenomen in de trainingsset. Aanbevolen waarde is 80.
80
testingSplitPercentage
20
Percentage van uw getagde gegevens die moeten worden opgenomen in de testset. Aanbevolen waarde is 20.
20
Notitie
De trainingSplitPercentage en testingSplitPercentage zijn alleen vereist als Kind deze is ingesteld percentage op en de som van beide percentages moet gelijk zijn aan 100.
Zodra u uw API-aanvraag hebt verzonden, ontvangt u een 202 antwoord dat aangeeft dat het is gelukt. Pak de operation-location waarde uit in de antwoordheaders. Deze wordt als volgt opgemaakt:
Selecteer de id van de trainingstaak in de lijst. Er wordt een zijvenster weergegeven waarin u de voortgang van de training, de taakstatus en andere details voor deze taak kunt controleren.
Training kan enige tijd duren, afhankelijk van de grootte van uw trainingsgegevens en complexiteit van uw schema. U kunt de volgende aanvraag gebruiken om de status van de trainingstaak te peilen totdat deze is voltooid.
Gebruik de volgende GET-aanvraag om de status van de trainingsvoortgang van uw model op te halen. Vervang de waarden van de tijdelijke aanduiding hieronder door uw eigen waarden.
De naam voor uw project. Deze waarde is hoofdlettergevoelig.
EmailApp
{JOB-ID}
De id voor het zoeken naar de trainingsstatus van uw model. Dit is de location headerwaarde die u hebt ontvangen toen u uw trainingstaak hebt ingediend.
Als u een trainingstaak vanuit Language Studio wilt annuleren, gaat u naar de pagina Model trainen . Selecteer de trainingstaak die u wilt annuleren en selecteer Annuleren in het bovenste menu.
Maak een POST-aanvraag met behulp van de volgende URL, headers en JSON-hoofdtekst om een trainingstaak te annuleren.
Aanvraag-URL
Gebruik de volgende URL bij het maken van uw API-aanvraag. Vervang de waarden van de tijdelijke aanduiding hieronder door uw eigen waarden.
Gebruik de volgende header om uw aanvraag te verifiëren.
Sleutel
Weergegeven als
Ocp-Apim-Subscription-Key
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen.
Zodra u uw API-aanvraag hebt verzonden, ontvangt u een 202-antwoord dat aangeeft dat uw trainingstaak is geannuleerd. Een geslaagde aanroepresultaten met een header Operation-Location die wordt gebruikt om de status van de taak te controleren.