Uw model voor het begrijpen van gesprekstaal trainen
Nadat u klaar bent met het labelen van uw utterances, kunt u beginnen met het trainen van een model. Training is het proces waarbij het model leert van uw gelabelde uitingen.
Als u een model wilt trainen, start u een trainingstaak. Alleen voltooide taken maken een model. Trainingstaken verlopen na zeven dagen. Na deze tijd kunt u de taakgegevens niet meer ophalen. Als uw trainingstaak is voltooid en er een model is gemaakt, wordt dit niet beïnvloed door het verlopen van de taak. U kunt slechts één trainingstaak tegelijk uitvoeren en u kunt geen andere taken in hetzelfde project starten.
De trainingstijden kunnen zich vanaf een paar seconden bevinden bij het omgaan met eenvoudige projecten, tot een paar uur wanneer u de maximumlimiet van utterances bereikt.
Modelevaluatie wordt automatisch geactiveerd nadat de training is voltooid. Het evaluatieproces begint met het getrainde model om voorspellingen uit te voeren op de uitingen in de testset en vergelijkt de voorspelde resultaten met de opgegeven labels (waarmee een basislijn van waarheid wordt vastgesteld).
Vereisten
- Een project gemaakt met een geconfigureerd Azure Blob Storage-account
- Gelabelde utterances
Trainingsgegevens verdelen
Als het gaat om trainingsgegevens, probeert u uw schema goed in balans te houden. Het opnemen van grote hoeveelheden van één intentie en zeer weinig van een andere resulteert in een model dat is vooroordelen ten opzichte van bepaalde intenties.
Om dit scenario aan te pakken, moet u mogelijk de trainingsset omlaag instellen. Of u moet er misschien aan toevoegen. Als u downsample wilt uitvoeren, kunt u het volgende doen:
- Verwijder willekeurig een bepaald percentage van de trainingsgegevens.
- Analyseer de gegevensset en verwijder oververtegenwoordigde dubbele vermeldingen. Dit is een systematischere manier.
Als u wilt toevoegen aan de trainingsset, selecteert u in Language Studio op het tabblad Gegevenslabeling de optie Uitingen voorstellen. Conversational Language Understanding verzendt een aanroep naar Azure OpenAI om vergelijkbare uitingen te genereren.

U moet ook zoeken naar onbedoelde 'patronen' in de trainingsset. Kijk bijvoorbeeld of de trainingsset voor een bepaalde intentie allemaal kleine letters is of begint met een bepaalde woordgroep. In dergelijke gevallen kan het model dat u traint deze onbedoelde vooroordelen in de trainingsset leren in plaats van te generaliseren.
We raden u aan om casing en interpunctiediversiteit in de trainingsset te introduceren. Als uw model variaties moet verwerken, moet u een trainingsset hebben die ook die diversiteit weerspiegelt. Neem bijvoorbeeld enkele uitingen op in de juiste behuizing en sommige in kleine letters.
Gegevens splitsen
Voordat u het trainingsproces start, worden gelabelde uitingen in uw project onderverdeeld in een trainingsset en een testset. Elk van deze dient een andere functie. De trainingsset wordt gebruikt bij het trainen van het model. Dit is de set waaruit het model de gelabelde uitingen leert. De testset is een blinde set die tijdens de training niet is geïntroduceerd in het model, maar alleen tijdens de evaluatie.
Nadat het model is getraind, kan het model worden gebruikt om voorspellingen te doen van de uitingen in de testset. Deze voorspellingen worden gebruikt om metrische evaluatiegegevens te berekenen. Het wordt aanbevolen om ervoor te zorgen dat al uw intenties en entiteiten adequaat worden weergegeven in zowel de trainings- als testset.
Het begrip van gesprekstaal ondersteunt twee methoden voor het splitsen van gegevens:
- Automatisch de testset splitsen op basis van trainingsgegevens: het systeem splitst uw getagde gegevens tussen de trainings- en testsets op basis van de percentages die u kiest. De aanbevolen percentagesplitsing is 80% voor training en 20% voor testen.
Notitie
Als u de testset automatisch splitst op basis van de optie trainingsgegevens , worden alleen de gegevens die aan de trainingsset zijn toegewezen, gesplitst volgens de opgegeven percentages.
- Gebruik een handmatige splitsing van trainings- en testgegevens: met deze methode kunnen gebruikers definiëren welke utterances tot welke set moeten behoren. Deze stap is alleen ingeschakeld als u uitingen hebt toegevoegd aan uw testset tijdens het labelen.
Trainingsmodi
CLU ondersteunt twee modi voor het trainen van uw modellen
Standaardtraining maakt gebruik van snelle machine learning-algoritmen om uw modellen relatief snel te trainen. Dit is momenteel alleen beschikbaar voor Engels en is uitgeschakeld voor elk project dat geen Engels (VS) of Engels (VK) als primaire taal gebruikt. Deze trainingsoptie is gratis. Met standaardtraining kunt u utterances toevoegen en deze snel zonder kosten testen. De weergegeven evaluatiescores moeten u helpen bij het aanbrengen van wijzigingen in uw project en het toevoegen van meer uitingen. Zodra u een paar keer hebt herhaald en incrementele verbeteringen hebt aangebracht, kunt u overwegen geavanceerde training te gebruiken om een andere versie van uw model te trainen.
Geavanceerde training maakt gebruik van de nieuwste machine learning-technologie om modellen aan te passen met uw gegevens. Dit wordt verwacht betere prestatiescores voor uw modellen weer te geven en stelt u in staat om ook de meertalige mogelijkheden van CLU te gebruiken. Geavanceerde training is anders geprijsd. Zie de prijsinformatie voor meer informatie .
Gebruik de evaluatiescores om uw beslissingen te begeleiden. Het kan voorkomen dat een specifiek voorbeeld onjuist wordt voorspeld in geavanceerde training in plaats van wanneer u de standaardtrainingsmodus hebt gebruikt. Als de algehele evaluatieresultaten echter beter gebruikmaken van geavanceerd, is het raadzaam om uw uiteindelijke model te gebruiken. Als dat niet het geval is en u geen meertalige mogelijkheden wilt gebruiken, kunt u model blijven gebruiken dat is getraind met de standaardmodus.
Notitie
U kunt verwachten dat er een verschil in gedrag in intentievertrouwensscores tussen de trainingsmodi wordt weergegeven, omdat elk algoritme de scores anders kalibreert.
Model trainen
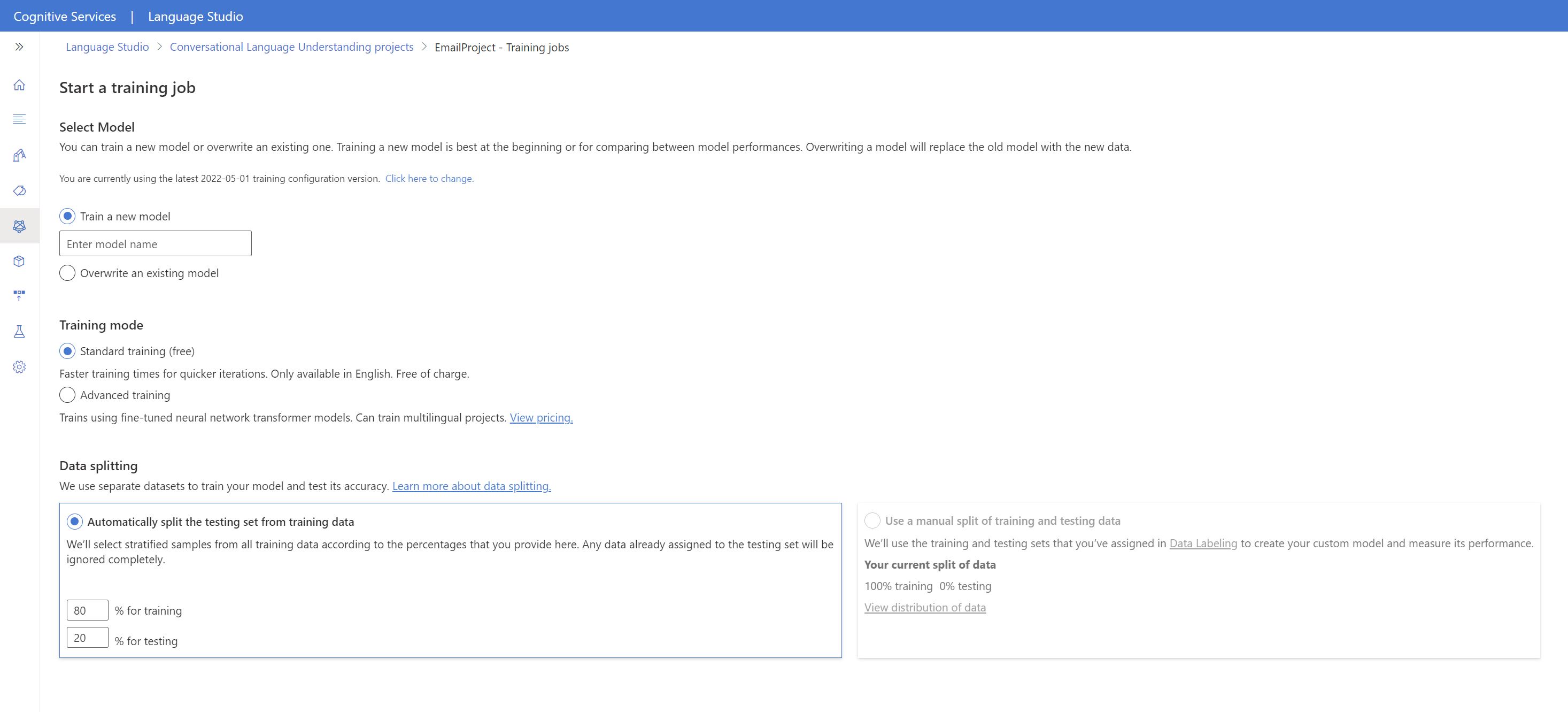
Ga als volgende te werk om uw model te trainen vanuit Language Studio:
Selecteer Model trainen in het menu aan de linkerkant.
Selecteer Een trainingstaak starten in het bovenste menu.
Selecteer Een nieuw model trainen en voer een nieuwe modelnaam in het tekstvak in. Als u een bestaand model anders wilt vervangen door een model dat is getraind op de nieuwe gegevens, selecteert u Een bestaand model overschrijven en selecteert u vervolgens een bestaand model . Het overschrijven van een getraind model kan niet ongedaan worden gemaakt, maar dit heeft geen invloed op uw geïmplementeerde modellen totdat u het nieuwe model implementeert.
Selecteer de trainingsmodus. U kunt Standard-training kiezen voor een snellere training, maar deze is alleen beschikbaar voor engels. U kunt ook geavanceerde training kiezen die wordt ondersteund voor andere talen en meertalige projecten, maar het gaat om langere trainingstijden. Meer informatie over trainingsmodi.
Selecteer een methode voor gegevenssplitsing . U kunt de testset automatisch splitsen op basis van trainingsgegevens , waarbij het systeem uw uitingen splitst tussen de trainings- en testsets, volgens de opgegeven percentages. Of u kunt een handmatige splitsing van trainings- en testgegevens gebruiken. Deze optie is alleen ingeschakeld als u uitingen hebt toegevoegd aan uw testset wanneer u uw utterances hebt gelabeld.
Selecteer de knop Trainen .
Selecteer de id van de trainingstaak in de lijst. Er wordt een deelvenster weergegeven waarin u de voortgang van de training, de taakstatus en andere details voor deze taak kunt controleren.
Notitie
- Alleen voltooide trainingstaken genereren modellen.
- Training kan enige tijd duren tussen een paar minuten en een paar uur op basis van het aantal uitingen.
- U kunt slechts één trainingstaak tegelijk uitvoeren. U kunt pas andere trainingstaken binnen hetzelfde project starten als de actieve taak is voltooid.
- De machine learning die wordt gebruikt om modellen te trainen, wordt regelmatig bijgewerkt. Als u wilt trainen op een eerdere configuratieversie, selecteert u hier om te wijzigen op de pagina Een trainingstaak starten en kiest u een eerdere versie.

Trainingstaak annuleren
Een trainingstaak annuleren vanuit Language Studio
- Selecteer op de pagina Model trainen de trainingstaak die u wilt annuleren en selecteer Annuleren in het bovenste menu.