Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Zodra u een schema voor uw project hebt gemaakt, moet u trainingsuitingen toevoegen aan uw project. De uitingen moeten vergelijkbaar zijn met wat uw gebruikers gebruiken bij interactie met het project. Wanneer u een utterance toevoegt, moet u toewijzen aan welke intentie deze hoort. Nadat de utterance is toegevoegd, labelt u de woorden in uw uiting die u als entiteiten wilt extraheren.
Gegevenslabeling is een cruciale stap in de ontwikkelingslevenscyclus; deze gegevens worden gebruikt in de volgende stap bij het trainen van uw model, zodat uw model kan leren van de gelabelde gegevens. Als u al utterances hebt gelabeld, kunt u deze rechtstreeks importeren in uw project, maar moet u ervoor zorgen dat uw gegevens de geaccepteerde gegevensindeling volgen. Zie Project maken voor meer informatie over het importeren van gelabelde gegevens in uw project. Gelabelde gegevens informeren het model over het interpreteren van tekst en wordt gebruikt voor training en evaluatie.
Vereisten
Voordat u uw gegevens kunt labelen, hebt u het volgende nodig:
- Een project is gemaakt.
Zie de levenscyclus van projectontwikkeling voor meer informatie.
Richtlijnen voor gegevenslabels
Nadat u uw schema hebt gemaakt en uw project hebt gemaakt, moet u uw gegevens labelen. Het labelen van uw gegevens is belangrijk, zodat uw model weet welke woorden en zinnen zijn gekoppeld aan de intenties en entiteiten in uw project. Besteed tijd aan het labelen van uw uitingen: het introduceren en verfijnen van de gegevens die worden gebruikt bij het trainen van uw modellen.
Houd rekening met het volgende wanneer u utterances toevoegt en labelt:
De machine learning-modellen generaliseren op basis van de gelabelde voorbeelden die u opgeeft; hoe meer voorbeelden u opgeeft, hoe meer gegevenspunten het model moet maken om betere generalisaties te maken.
De precisie, consistentie en volledigheid van uw gelabelde gegevens zijn belangrijke factoren voor het bepalen van modelprestaties.
- Label precies: Label elke intentie en entiteit altijd naar het juiste type. Neem alleen op wat u wilt geclassificeerd en geëxtraheerd, vermijd onnodige gegevens in uw labels.
- Label consistent: dezelfde entiteit moet hetzelfde label hebben voor alle utterances.
- Label volledig: Bied verschillende utterances voor elke intentie. Label alle exemplaren van de entiteit in al uw utterances.
Duidelijk labelen van utterances
Zorg ervoor dat de concepten waarnaar uw entiteiten verwijzen goed zijn gedefinieerd en kunnen worden gescheiden. Controleer of u de verschillen op betrouwbare wijze kunt bepalen. Als u dat niet kunt, kan dit gebrek aan onderscheid erop wijzen dat het geleerde onderdeel ook problemen ondervindt.
Als er een overeenkomst is tussen entiteiten, moet u ervoor zorgen dat er een bepaald aspect van uw gegevens is dat een signaal biedt voor het verschil tussen deze entiteiten.
Als u bijvoorbeeld een model hebt gebouwd om vluchten te boeken, kan een gebruiker een uiting gebruiken zoals 'Ik wil een vlucht van Boston naar Seattle'. De oorspronkelijke plaats en bestemmingsstad voor dergelijke uitingen zouden naar verwachting vergelijkbaar zijn. Een signaal om oorsprongsstad te onderscheiden, kan zijn dat het woord vaak voorafgaat.
Zorg ervoor dat u alle exemplaren van elke entiteit labelt in zowel uw trainings- als testgegevens. Een benadering is om de zoekfunctie te gebruiken om alle exemplaren van een woord of woordgroep in uw gegevens te vinden om te controleren of ze correct zijn gelabeld.
Labeltestgegevens voor entiteiten die geen geleerd onderdeel hebben en ook voor de entiteiten die dat doen. Deze procedure helpt ervoor te zorgen dat uw metrische evaluatiegegevens nauwkeurig zijn.
Voor meertalige projecten verhoogt het toevoegen van utterances in andere talen de prestaties van het model in deze talen, maar vermijd het dupliceren van uw gegevens in alle talen die u wilt ondersteunen. Als u bijvoorbeeld de prestaties van een kalenderbot met gebruikers wilt verbeteren, kan een ontwikkelaar voorbeelden meestal toevoegen in het Engels en een aantal in het Spaans of Frans. Ze kunnen utterances toevoegen, zoals:
- "Stel morgen om 12.00 uur een vergadering met Matt en Kevinin." (Engels)
- "Reageer als voorlopig op de wekelijkse updatevergadering ." (Engels)
- "Cancelar mi próxima reunión." (Spaans)
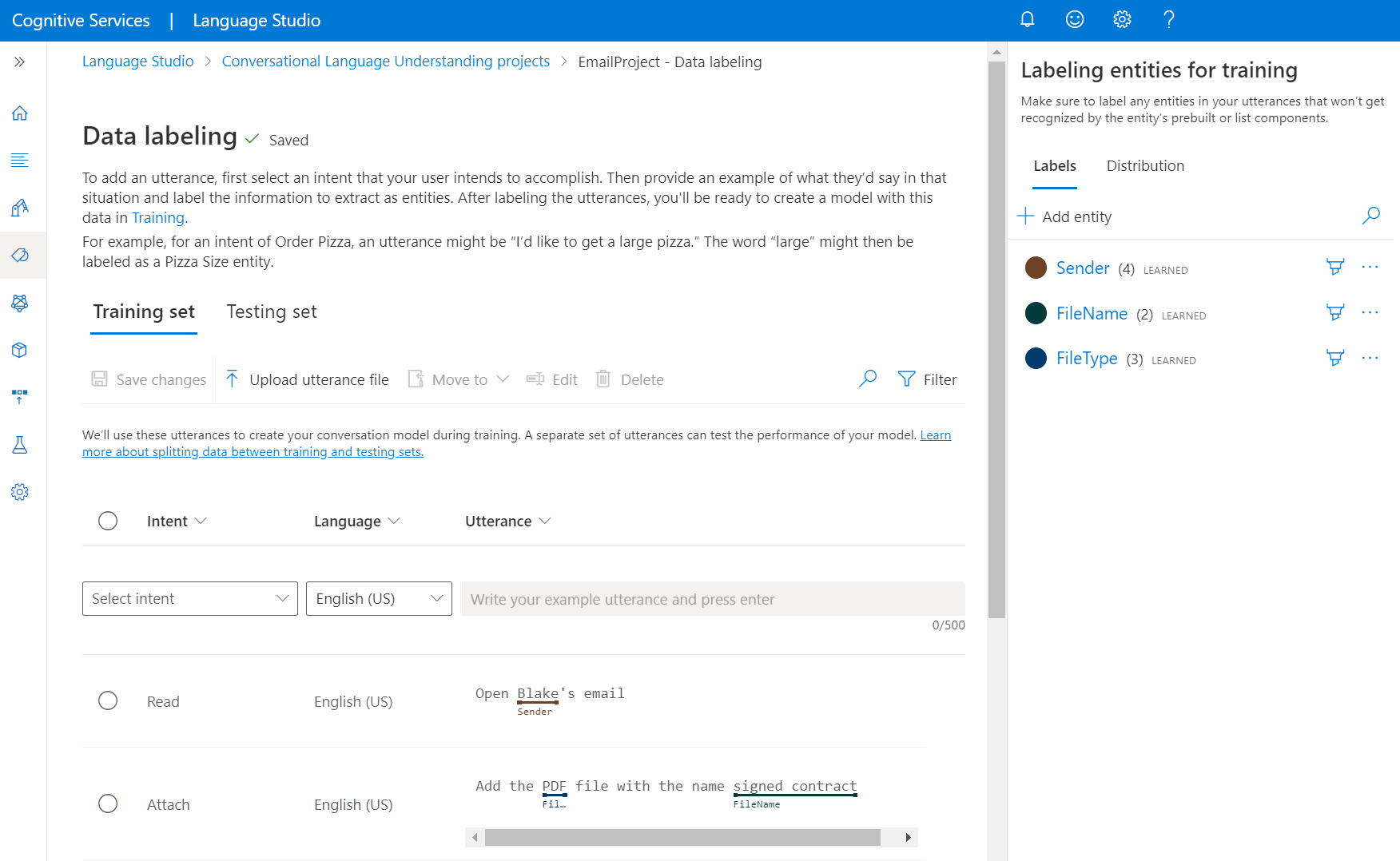
Uw utterances labelen
Gebruik de volgende stappen om uw uitingen te labelen:
Ga naar uw projectpagina in Language Studio.
Selecteer gegevenslabeling in het menu aan de linkerkant. Op deze pagina kunt u beginnen met het toevoegen van uw utterance en het labelen ervan. U kunt uw utterance ook rechtstreeks uploaden door te klikken op het bestand Upload utterance in het bovenste menu, zorg ervoor dat deze de geaccepteerde indeling volgt.
Vanuit de bovenste draaitabellen kunt u de weergave wijzigen in trainingsset of testset. Meer informatie over trainings- en testsets en hoe ze worden gebruikt voor modeltraining en -evaluatie.
Tip
Als u van plan bent om de testset automatisch te splitsen van het splitsen van trainingsgegevens , voegt u al uw uitingen toe aan de trainingsset.
Selecteer in de vervolgkeuzelijst Intentie selecteren een van de intenties, de taal van de uiting (voor meertalige projecten) en de uiting zelf. Druk op Enter in het tekstvak van de uiting om de utterance toe te voegen.
U hebt twee opties voor het labelen van entiteiten in een uiting:
Optie Omschrijving Label met een kwast Selecteer het kwastpictogram naast een entiteit in het rechterdeelvenster en markeer de tekst in de uiting die u wilt labelen. Label met behulp van het inlinemenu Markeer het woord dat u als entiteit wilt labelen en er wordt een menu weergegeven. Selecteer de entiteit waarmee u deze woorden wilt labelen. In het rechterdeelvenster, onder de draaitabel Labels , vindt u alle entiteitstypen in uw project en het aantal gelabelde exemplaren per stuk.
Onder het distributiedraaipunt kunt u de distributie in trainings- en testsets bekijken. U hebt twee opties voor weergave:
- Totaal aantal exemplaren per gelabelde entiteit , waar u het aantal gelabelde exemplaren van een specifieke entiteit kunt bekijken.
- Unieke utterances per gelabelde entiteit waarbij elke utterance wordt geteld als deze ten minste één gelabeld exemplaar van deze entiteit bevat.
- Uitingen per intentie waar u het aantal uitingen per intentie kunt bekijken.


Notitie
Lijst- en vooraf gemaakte onderdelen worden niet weergegeven op de pagina voor gegevenslabels en alle labels hier zijn alleen van toepassing op het geleerde onderdeel.
Een label verwijderen:
- Selecteer in uw uiting de entiteit waaruit u een label wilt verwijderen.
- Blader door het menu dat wordt weergegeven en selecteer Label verwijderen.
Een entiteit verwijderen:
- Selecteer de entiteit die u wilt bewerken in het rechterdeelvenster.
- Selecteer de drie puntjes naast de entiteit en selecteer de gewenste optie in de vervolgkeuzelijst.
Uitingen voorstellen met Azure OpenAI
In CLU gebruikt u Azure OpenAI om uitingen voor te stellen om aan uw project toe te voegen met behulp van GPT-modellen. U moet eerst toegang krijgen en een resource maken in Azure OpenAI. Vervolgens moet u een implementatie maken voor de GPT-modellen. Volg hier de vereiste stappen.
Voordat u aan de slag gaat, is de functie voor suggesties voor utterances alleen beschikbaar als uw taalresource zich in de volgende regio's bevindt:
- VS - oost
- VS - zuid-centraal
- Europa -west
Op de pagina Gegevenslabels:
- Selecteer de knop Uitingen voorstellen. Aan de rechterkant wordt een deelvenster geopend waarin u wordt gevraagd om uw Azure OpenAI-resource en -implementatie te selecteren.
- Bij het selecteren van een Azure OpenAI-resource selecteert u Verbinding maken, zodat uw taalresource directe toegang heeft tot uw Azure OpenAI-resource. Hiermee wordt uw taalresource toegewezen
Cognitive Services Useraan uw Azure OpenAI-resource, zodat uw huidige taalresource toegang heeft tot de service van Azure OpenAI. Als de verbinding mislukt, volgt u deze stappen hieronder om de juiste rol handmatig toe te voegen aan uw Azure OpenAI-resource. - Zodra de resource is verbonden, selecteert u de implementatie. Het aanbevolen model voor de Azure OpenAI-implementatie is
gpt-35-turbo-instruct. - Selecteer de intentie waarvoor u suggesties wilt krijgen. Zorg ervoor dat voor de intentie die u hebt geselecteerd ten minste vijf opgeslagen uitingen zijn ingeschakeld voor uitingssuggesties. De suggesties van Azure OpenAI zijn gebaseerd op de meest recente uitingen die u voor die intentie hebt toegevoegd.
- Selecteer Uitingen genereren. Zodra dit is voltooid, worden de voorgestelde utterances weergegeven met een stippellijn eromheen, met de notitie Gegenereerd door AI. Deze suggesties moeten worden geaccepteerd of afgewezen. Als u een suggestie accepteert, wordt deze gewoon toegevoegd aan uw project, alsof u het zelf hebt toegevoegd. Als u deze weigert, wordt de suggestie volledig verwijderd. Alleen geaccepteerde utterances maken deel uit van uw project en worden gebruikt voor training of testen. U kunt accepteren of weigeren door naast elke utterance op de groene controle of rode annuleringsknoppen te klikken. U kunt ook de
Accept allknoppen enReject allknoppen op de werkbalk gebruiken.

Als u deze functie gebruikt, worden kosten in rekening gebracht voor uw Azure OpenAI-resource voor een vergelijkbaar aantal tokens voor de voorgestelde uitingen die zijn gegenereerd. Meer informatie over de prijzen van Azure OpenAI vindt u hier.
Vereiste configuraties toevoegen aan Azure OpenAI-resource
Als het verbinden van uw taalresource met een Azure OpenAI-resource mislukt, voert u de volgende stappen uit:
Schakel identiteitsbeheer in voor uw taalresource met behulp van de volgende opties:
Uw taalresource moet identiteitsbeheer hebben om deze in te schakelen met behulp van Azure Portal:
- Ga naar uw taalresource
- Selecteer Identiteit in het linkermenu onder de sectie Resourcebeheer
- Ga naar het tabblad Systeem toegewezen en zorg ervoor dat u Status instelt op Aan
Nadat u een beheerde identiteit hebt ingeschakeld, wijst u de rol Cognitive Services User toe aan uw Azure OpenAI-resource met behulp van de beheerde identiteit van uw taalresource.
- Meld u aan bij Azure Portal en navigeer naar uw Azure OpenAI-resource.
- Selecteer het tabblad Toegangsbeheer (IAM) aan de linkerkant.
- Selecteer Roltoewijzing toevoegen.>
- Selecteer Functierollen voor taken en klik op Volgende.
- Selecteer
Cognitive Services Userin de lijst met rollen en klik op Volgende. - Selecteer Toegang toewijzen tot 'Beheerde identiteit' en selecteer Leden selecteren.
- Selecteer Onder Beheerde identiteit de optie Taal.
- Zoek uw resource en selecteer deze. Selecteer vervolgens de knop Selecteren hieronder en voltooi het proces.
- Controleer de details en selecteer Beoordelen en toewijzen.

Vernieuw de Language Studio na enkele minuten en u kunt verbinding maken met Azure OpenAI.