Batchanalyse van Document Intelligence
Met de batchanalyse-API kunt u meerdere documenten bulksgewijs verwerken met één asynchrone aanvraag. In plaats van documenten afzonderlijk in te dienen en meerdere aanvraag-id's bij te houden, kunt u een verzameling documenten analyseren, zoals facturen, een reeks leningdocumenten of een groep aangepaste documenten tegelijk. De batch-API ondersteunt het lezen van de documenten vanuit Azure Blob Storage en het schrijven van de resultaten naar blobopslag.
- Als u batchanalyse wilt gebruiken, hebt u een Azure Blob Storage-account met specifieke containers nodig voor zowel uw brondocumenten als de verwerkte uitvoer.
- Na voltooiing bevat het resultaat van de batchbewerking alle afzonderlijke documenten die zijn verwerkt met hun status, zoals
succeeded,skippedoffailed. - De Preview-versie van de Batch-API is beschikbaar via prijzen voor betalen per gebruik.
Richtlijnen voor batchanalyse
Het maximum aantal documenten dat per aanvraag voor één batchanalyse wordt verwerkt (inclusief overgeslagen documenten) is 10.000.
De resultaten van de bewerking worden 24 uur na voltooiing bewaard. De documenten en resultaten bevinden zich in het opgegeven opslagaccount, maar de bewerkingsstatus is 24 uur na voltooiing niet meer beschikbaar.
Klaar om aan de slag te gaan?
Vereisten
Een Azure-abonnement. Als u geen Azure-abonnement hebt, kunt u er gratis een maken.
Zodra u uw Azure-abonnement een Document Intelligence-exemplaar hebt in Azure Portal. U kunt de gratis prijscategorie (
F0) gebruiken om de service te proberen.Nadat uw resource is geïmplementeerd, selecteert u Ga naar de resource en haalt u uw sleutel en eindpunt op.
- U hebt de sleutel en het eindpunt van de resource nodig om uw toepassing te verbinden met de Document Intelligence-service. U plakt uw sleutel en eindpunt verderop in de code in de quickstart. U vindt deze waarden op de pagina Sleutels en eindpunten van Azure Portal.
Een Azure Blob Storage-account. U maakt containers in uw Azure Blob Storage-account voor uw bron- en resultaatbestanden:
- Broncontainer. In deze container uploadt u uw bestanden voor analyse (vereist).
- Resultaatcontainer. In deze container worden uw verwerkte bestanden opgeslagen (optioneel).
U kunt dezelfde Azure Blob Storage-container aanwijzen voor bron- en verwerkte documenten. Als u echter de potentiële kans op het per ongeluk overschrijven van gegevens wilt minimaliseren, raden we u aan afzonderlijke containers te kiezen.
Autorisatie van opslagcontainers
U kunt een van de volgende opties kiezen om toegang tot uw documentresource te autoriseren.
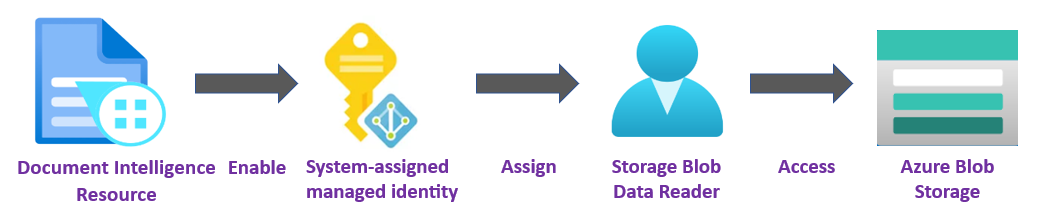
✔️ Beheerde identiteit. Een beheerde identiteit is een service-principal waarmee een Microsoft Entra-identiteit en specifieke machtigingen voor een door Azure beheerde resource worden gemaakt. Met beheerde identiteiten kunt u uw Document Intelligence-toepassing uitvoeren zonder referenties in uw code in te sluiten. Beheerde identiteiten zijn een veiligere manier om toegang te verlenen tot opslaggegevens en om de vereiste voor het opnemen van sas-tokens (Shared Access Signature) te vervangen door uw bron- en resultaat-URL's.
ZieBeheerde identiteiten voor Document Intelligence voor meer informatie.
Belangrijk
- Wanneer u beheerde identiteiten gebruikt, neemt u geen SAS-token-URL op met uw HTTP-aanvragen. Uw aanvragen mislukken. Als u beheerde identiteiten gebruikt, wordt de vereiste voor het opnemen van sas-tokens (Shared Access Signature) vervangen.
✔️ Shared Access Signature (SAS). Een handtekening voor gedeelde toegang is een URL die gedurende een opgegeven periode beperkte toegang verleent aan uw Document Intelligence-service. Als u deze methode wilt gebruiken, moet u SAS-tokens (Shared Access Signature) maken voor uw bron- en resultaatcontainers. De bron- en resultaatcontainers moeten een SAS-token (Shared Access Signature) bevatten, toegevoegd als een querytekenreeks. Het token kan worden toegewezen aan uw container of specifieke blobs.

- Uw broncontainer of blob moet lees-, schrijf-, lijst- en verwijdertoegang aanwijzen.
- Uw resultaatcontainer of blob moet schrijf-, lijst- en verwijdertoegang aanwijzen.
ZieSAS-tokens maken voor meer informatie.
De batchanalyse-API aanroepen
- Geef de URL van de Azure Blob Storage-container op voor uw brondocumentset in de
azureBlobSourceofazureBlobFileListSourceobjecten.
De invoerbestanden opgeven
De batch-API ondersteunt twee opties voor het opgeven van de bestanden die moeten worden verwerkt. Als u alle bestanden in een container of map wilt verwerken en het aantal bestanden kleiner is dan de limiet van 10000 voor één batchaanvraag, gebruikt u de azureBlobSource container.
Als u specifieke bestanden in de container of map hebt die moeten worden verwerkt of als het aantal te verwerken bestanden de maximumlimiet voor één batch overschrijdt, gebruikt u de azureBlobFileListSource. Splits de gegevensset in meerdere batches en voeg een bestand toe met de lijst met bestanden die moeten worden verwerkt in een JSONL-indeling in de hoofdmap van de container. Een voorbeeld van de bestandsindeling is.
{"file": "Adatum Corporation.pdf"}
{"file": "Best For You Organics Company.pdf"}
Geef de locatie van de resultaten op
Geef de URL van de Azure Blob Storage-container op voor uw batchanalyseresultaten met behulp van resultContainerUrl. Om onbedoeld overschrijven te voorkomen, raden we u aan afzonderlijke containers te gebruiken voor bron- en verwerkte documenten.
Stel de overwriteExisting booleaanse eigenschap in op false als u geen bestaande resultaten wilt overschrijven met dezelfde bestandsnamen. Deze instelling heeft geen invloed op de facturering en voorkomt alleen dat resultaten worden overschreven nadat het invoerbestand is verwerkt.
Stel de resultPrefix naamruimte in op de resultaten van deze uitvoering van de batch-API.
- Als u van plan bent om dezelfde container te gebruiken voor zowel invoer als uitvoer, stelt u deze in
resultContainerUrlenresultPrefixkomt u overeen met uw invoerazureBlobSource. - Wanneer u dezelfde container gebruikt, kunt u het
overwriteExistingveld opnemen om te bepalen of u bestanden met de analyseresultatenbestanden wilt overschrijven.
De POST-aanvraag bouwen en uitvoeren
Voordat u de POST-aanvraag uitvoert, vervangt u {your-source-container-SAS-URL} en {your-result-container-SAS-URL} door de waarden uit uw Azure Blob Storage-containerinstanties.
In het volgende voorbeeld ziet u hoe u de azureBlobSource eigenschap toevoegt aan de aanvraag:
Sta slechts één of azureBlobSourceazureBlobFileListSourceéén toe.
POST /documentModels/{modelId}:analyzeBatch
{
"azureBlobSource": {
"containerUrl": "https://myStorageAccount.blob.core.windows.net/myContainer?mySasToken",
"prefix": "trainingDocs/"
},
"resultContainerUrl": "https://myStorageAccount.blob.core.windows.net/myOutputContainer?mySasToken",
"resultPrefix": "layoutresult/",
"overwriteExisting": true
}
In het volgende voorbeeld ziet u hoe u de azureBlobFileListSource eigenschap toevoegt aan de aanvraag:
POST /documentModels/{modelId}:analyzeBatch
{
"azureBlobFileListSource": {
"containerUrl": "https://myStorageAccount.blob.core.windows.net/myContainer?mySasToken",
"fileList": "myFileList.jsonl"
},
"resultContainerUrl": "https://myStorageAccount.blob.core.windows.net/myOutputContainer?mySasToken",
"resultPrefix": "customresult/",
"overwriteExisting": true
}
Geslaagde reactie
202 Accepted
Operation-Location: /documentModels/{modelId}/analyzeBatchResults/{resultId}
Api-resultaten voor batchanalyse ophalen
Nadat de Batch API-bewerking is uitgevoerd, kunt u de batchanalyseresultaten ophalen met behulp van deGET bewerking. Met deze bewerking worden informatie over de bewerkingsstatus, voltooiingspercentage van de bewerking en het maken en bijwerken van datum/tijd opgehaald.
GET /documentModels/{modelId}/analyzeBatchResults/{resultId}
200 OK
{
"status": "running", // notStarted, running, completed, failed
"percentCompleted": 67, // Estimated based on the number of processed documents
"createdDateTime": "2021-09-24T13:00:46Z",
"lastUpdatedDateTime": "2021-09-24T13:00:49Z"
...
}
Statusberichten interpreteren
Voor elk document is er een status toegewezen, ofwel succeeded, failedof skipped. Voor elk document zijn er twee URL's opgegeven om de resultaten te valideren: sourceUrl, dit is de bron-blobopslagcontainer voor uw geslaagde invoerdocument, en resultUrl, dat is samengesteld door het relatieve pad voor het bronbestand te combineren resultContainerUrl enresultPrefix te maken en .ocr.json.
Status
notStartedofrunning. De batchanalysebewerking wordt niet gestart of is niet voltooid. Wacht totdat de bewerking is voltooid voor alle documenten.Status
completed. De batchanalysebewerking is voltooid.Status
failed. De batchbewerking is mislukt. Dit antwoord treedt meestal op als er algemene problemen zijn met de aanvraag. Fouten voor afzonderlijke bestanden worden geretourneerd in de reactie van het batchrapport, zelfs als alle bestanden zijn mislukt. Opslagfouten stoppen bijvoorbeeld de batchbewerking niet als geheel, zodat u gedeeltelijke resultaten kunt openen via het batchrapportantwoord.
Alleen bestanden met een succeeded status hebben de eigenschap resultUrl gegenereerd in het antwoord. Hierdoor kan modeltraining bestandsnamen detecteren die eindigen .ocr.json en identificeren als de enige bestanden die kunnen worden gebruikt voor training.
Voorbeeld van een succeeded statusantwoord:
[
"result": {
"succeededCount": 0,
"failedCount": 2,
"skippedCount": 2,
"details": [
{
"sourceUrl": "https://{your-source-container}/myContainer/trainingDocs/file2.jpg",
"status": "failed",
"error": {
"code": "InvalidArgument",
"message": "Invalid argument.",
"innererror": {
"code": "InvalidSasToken",
"message": "The shared access signature (SAS) is invalid: {details}"
}
}
}
]
}
]
...
Voorbeeld van een failed statusantwoord:
- Deze fout wordt alleen geretourneerd als er fouten zijn in de algehele batchaanvraag.
- Zodra de batchanalysebewerking is gestart, heeft de afzonderlijke documentbewerkingsstatus geen invloed op de status van de algehele batchtaak, zelfs als alle bestanden de status
failedhebben.
[
"result": {
"succeededCount": 0,
"failedCount": 2,
"skippedCount": 2,
"details": [
"sourceUrl": "https://{your-source-container}/myContainer/trainingDocs/file2.jpg",
"status": "failed",
"error": {
"code": "InvalidArgument",
"message": "Invalid argument.",
"innererror": {
"code": "InvalidSasToken",
"message": "The shared access signature (SAS) is invalid: {details}"
}
}
]
}
]
...
Voorbeeld van skipped statusantwoord:
[
"result": {
"succeededCount": 3,
"failedCount": 0,
"skippedCount": 2,
"details": [
...
"sourceUrl": "https://myStorageAccount.blob.core.windows.net/myContainer/trainingDocs/file4.jpg",
"status": "skipped",
"error": {
"code": "OutputExists",
"message": "Analysis skipped because result file {path} already exists."
}
]
}
]
...
Met de resultaten van de batchanalyse kunt u bepalen welke bestanden met succes worden geanalyseerd en gevalideerd door het bestand in het resultUrl bestand te vergelijken met het uitvoerbestand in de resultContainerUrl.
Notitie
Analyseresultaten worden pas geretourneerd voor afzonderlijke bestanden als de volledige batchanalyse van de documentenset is voltooid. Als u gedetailleerde voortgang verder percentCompletedwilt bijhouden, kunt u bestanden bewaken *.ocr.json terwijl ze in het resultContainerUrlbestand worden geschreven.