Chatvoltooien genereren met azure AI-modeldeductie
Belangrijk
Items die in dit artikel zijn gemarkeerd (preview) zijn momenteel beschikbaar als openbare preview. Deze preview wordt aangeboden zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
In dit artikel wordt uitgelegd hoe u de API voor chatvoltooiing gebruikt met modellen die zijn geïmplementeerd in Azure AI-modeldeductie in Azure AI-services.
Vereisten
Als u chatvoltooiingsmodellen in uw toepassing wilt gebruiken, hebt u het volgende nodig:
Een Azure-abonnement. Als u GitHub-modellen gebruikt, kunt u uw ervaring upgraden en een Azure-abonnement maken in het proces. Lees Upgrade van GitHub-modellen naar Azure AI-modeldeductie als dat uw geval is.
Een Azure AI-servicesresource. Zie Een Azure AI Services-resource maken voor meer informatie.
De eindpunt-URL en -sleutel.
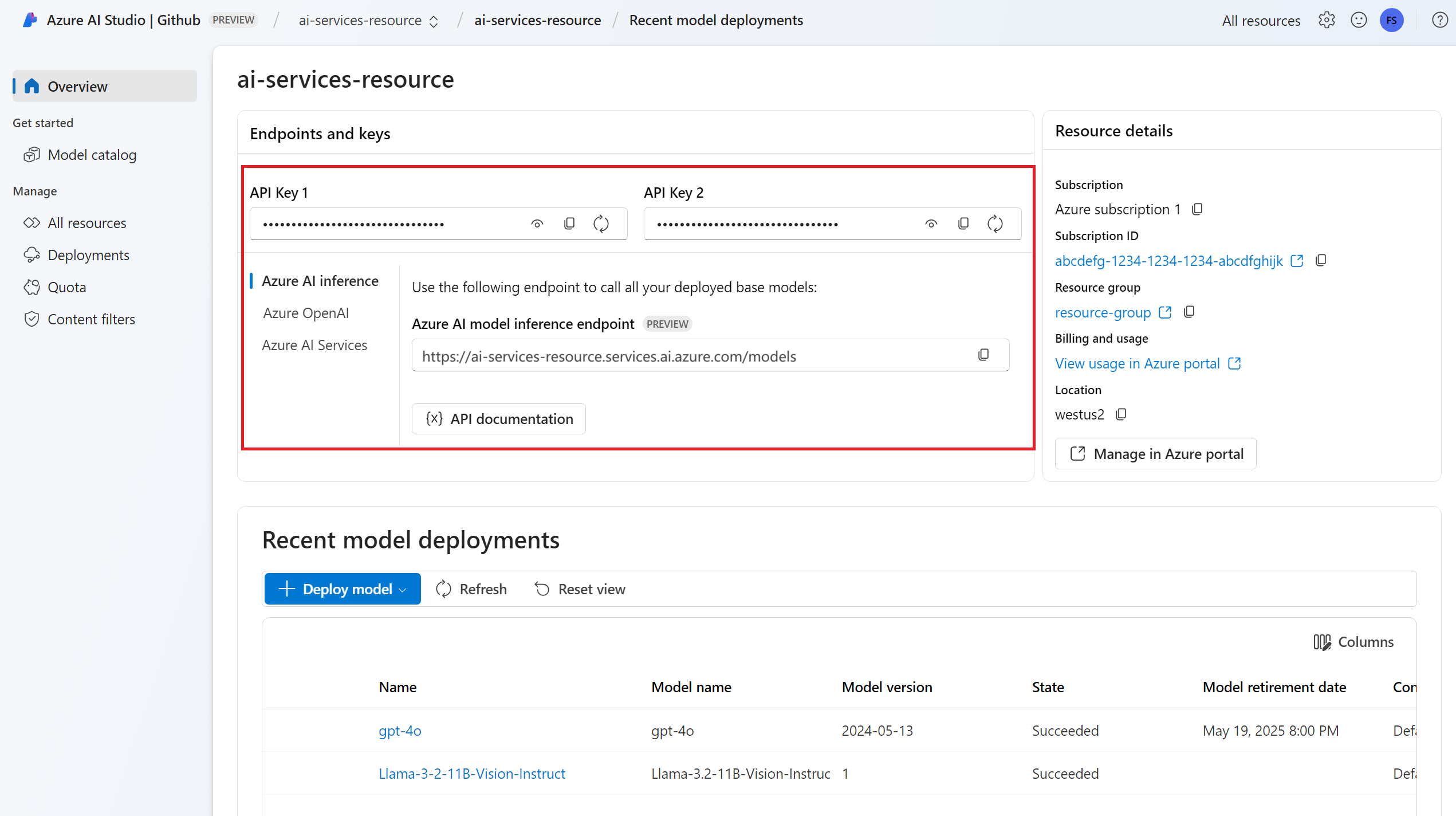

Een implementatie van een chat-voltooiingsmodel. Als u nog geen gelezen model voor toevoegen en configureren voor Azure AI-services hebt om een model voor chatvoltooiing toe te voegen aan uw resource.
Installeer het Azure AI-deductiepakket met de volgende opdracht:
pip install -U azure-ai-inferenceTip
Lees meer over het Azure AI-deductiepakket en de naslaginformatie.
Chatvoltooiingen gebruiken
Maak eerst de client om het model te gebruiken. De volgende code maakt gebruik van een eindpunt-URL en -sleutel die zijn opgeslagen in omgevingsvariabelen.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="mistral-large-2407"
)
Als u de resource hebt geconfigureerd voor ondersteuning voor Microsoft Entra ID , kunt u het volgende codefragment gebruiken om een client te maken.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="mistral-large-2407"
)
Een aanvraag voor het voltooien van een chat maken
In het volgende voorbeeld ziet u hoe u een aanvraag voor voltooiing van een eenvoudige chat kunt maken voor het model.
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
)
Notitie
Sommige modellen bieden geen ondersteuning voor systeemberichten (role="system"). Wanneer u de deductie-API van het Azure AI-model gebruikt, worden systeemberichten vertaald naar gebruikersberichten. Dit is de dichtstbijzijnde mogelijkheid die beschikbaar is. Deze vertaling wordt voor het gemak aangeboden, maar het is belangrijk dat u controleert of het model de instructies in het systeembericht met het juiste vertrouwensniveau volgt.
Het antwoord is als volgt, waar u de gebruiksstatistieken van het model kunt zien:
print("Response:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Inspecteer de usage sectie in het antwoord om het aantal tokens te zien dat wordt gebruikt voor de prompt, het totale aantal gegenereerde tokens en het aantal tokens dat wordt gebruikt voor de voltooiing.
Inhoud streamen
Standaard retourneert de voltooiings-API de volledige gegenereerde inhoud in één antwoord. Als u lange voltooiingen genereert, kan het wachten op het antwoord vele seconden duren.
U kunt de inhoud streamen om deze te verkrijgen terwijl deze wordt gegenereerd. Met streaming-inhoud kunt u beginnen met het verwerken van de voltooiing wanneer inhoud beschikbaar komt. Deze modus retourneert een object dat het antwoord terugstuurt als gebeurtenissen die alleen door de server worden verzonden. Extraheer segmenten uit het deltaveld in plaats van het berichtveld.
Als u voltooiingen wilt streamen, stelt u in stream=True wanneer u het model aanroept.
result = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
temperature=0,
top_p=1,
max_tokens=2048,
stream=True,
)
Als u de uitvoer wilt visualiseren, definieert u een helperfunctie om de stream af te drukken.
def print_stream(result):
"""
Prints the chat completion with streaming.
"""
import time
for update in result:
if update.choices:
print(update.choices[0].delta.content, end="")
U kunt visualiseren hoe streaming inhoud genereert:
print_stream(result)
Meer parameters verkennen die worden ondersteund door de deductieclient
Verken andere parameters die u kunt opgeven in de deductieclient. Zie de naslaginformatie over de Deductie-API voor Azure AI-modellen voor een volledige lijst met alle ondersteunde parameters en de bijbehorende documentatie.
from azure.ai.inference.models import ChatCompletionsResponseFormatText
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
presence_penalty=0.1,
frequency_penalty=0.8,
max_tokens=2048,
stop=["<|endoftext|>"],
temperature=0,
top_p=1,
response_format={ "type": ChatCompletionsResponseFormatText() },
)
Sommige modellen bieden geen ondersteuning voor JSON-uitvoeropmaak. U kunt het model altijd vragen om JSON-uitvoer te genereren. Dergelijke uitvoer is echter niet gegarandeerd geldige JSON.
Als u een parameter wilt doorgeven die niet in de lijst met ondersteunde parameters staat, kunt u deze doorgeven aan het onderliggende model met behulp van extra parameters. Zie Extra parameters doorgeven aan het model.
JSON-uitvoer maken
Sommige modellen kunnen JSON-uitvoer maken. Ingesteld response_format om de JSON-modus in te json_object schakelen en te garanderen dat het bericht dat het model genereert geldige JSON is. U moet ook het model instrueren om zelf JSON te produceren via een systeem- of gebruikersbericht. De inhoud van het bericht kan ook gedeeltelijk worden afgekapt als finish_reason="length", wat aangeeft dat de generatie is overschreden max_tokens of dat het gesprek de maximale contextlengte heeft overschreden.
from azure.ai.inference.models import ChatCompletionsResponseFormatJSON
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant that always generate responses in JSON format, using."
" the following format: { ""answer"": ""response"" }."),
UserMessage(content="How many languages are in the world?"),
],
response_format={ "type": ChatCompletionsResponseFormatJSON() }
)
Extra parameters doorgeven aan het model
Met de Azure AI-modeldeductie-API kunt u extra parameters doorgeven aan het model. In het volgende codevoorbeeld ziet u hoe u de extra parameter logprobs doorgeeft aan het model.
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
model_extras={
"logprobs": True
}
)
Voordat u extra parameters doorgeeft aan de deductie-API van het Azure AI-model, moet u ervoor zorgen dat uw model deze extra parameters ondersteunt. Wanneer de aanvraag wordt ingediend bij het onderliggende model, wordt de header extra-parameters met de waarde pass-throughdoorgegeven aan het model. Met deze waarde wordt aan het eindpunt doorgegeven dat de extra parameters aan het model moeten worden doorgegeven. Het gebruik van extra parameters met het model garandeert niet dat het model deze daadwerkelijk kan verwerken. Lees de documentatie van het model om te begrijpen welke extra parameters worden ondersteund.
Hulpprogramma's gebruiken
Sommige modellen ondersteunen het gebruik van hulpprogramma's, wat een buitengewone resource kan zijn wanneer u specifieke taken uit het taalmodel moet offloaden en in plaats daarvan afhankelijk bent van een meer deterministisch systeem of zelfs een ander taalmodel. Met de Azure AI-modeldeductie-API kunt u hulpprogramma's op de volgende manier definiëren.
In het volgende codevoorbeeld wordt een hulpprogrammadefinitie gemaakt die kan zoeken op basis van vluchtinformatie uit twee verschillende steden.
from azure.ai.inference.models import FunctionDefinition, ChatCompletionsFunctionToolDefinition
flight_info = ChatCompletionsFunctionToolDefinition(
function=FunctionDefinition(
name="get_flight_info",
description="Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters={
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates",
},
"destination_city": {
"type": "string",
"description": "The flight destination city",
},
},
"required": ["origin_city", "destination_city"],
},
)
)
tools = [flight_info]
In dit voorbeeld is de uitvoer van de functie dat er geen vluchten beschikbaar zijn voor de geselecteerde route, maar de gebruiker moet overwegen om een trein te nemen.
def get_flight_info(loc_origin: str, loc_destination: str):
return {
"info": f"There are no flights available from {loc_origin} to {loc_destination}. You should take a train, specially if it helps to reduce CO2 emissions."
}
Notitie
Cohere-modellen vereisen dat de antwoorden van een hulpprogramma een geldige JSON-inhoud zijn die is opgemaakt als een tekenreeks. Zorg ervoor dat het antwoord een geldige JSON-tekenreeks is bij het samenstellen van berichten van het type Tool.
Vraag het model om vluchten te boeken met behulp van deze functie:
messages = [
SystemMessage(
content="You are a helpful assistant that help users to find information about traveling, how to get"
" to places and the different transportations options. You care about the environment and you"
" always have that in mind when answering inqueries.",
),
UserMessage(
content="When is the next flight from Miami to Seattle?",
),
]
response = client.complete(
messages=messages, tools=tools, tool_choice="auto"
)
U kunt het antwoord controleren om erachter te komen of een hulpprogramma moet worden aangeroepen. Controleer de eindreden om te bepalen of het hulpprogramma moet worden aangeroepen. Houd er rekening mee dat er meerdere hulpprogrammatypen kunnen worden aangegeven. In dit voorbeeld ziet u een hulpprogramma van het type function.
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
print("Finish reason:", response.choices[0].finish_reason)
print("Tool call:", tool_calls)
Als u wilt doorgaan, voegt u dit bericht toe aan de chatgeschiedenis:
messages.append(
response_message
)
Nu is het tijd om de juiste functie aan te roepen om de aanroep van het hulpprogramma af te handelen. Het volgende codefragment herhaalt alle hulpprogramma-aanroepen die in het antwoord worden aangegeven en roept de bijbehorende functie aan met de juiste parameters. Het antwoord wordt ook toegevoegd aan de chatgeschiedenis.
import json
from azure.ai.inference.models import ToolMessage
for tool_call in tool_calls:
# Get the tool details:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments.replace("\'", "\""))
tool_call_id = tool_call.id
print(f"Calling function `{function_name}` with arguments {function_args}")
# Call the function defined above using `locals()`, which returns the list of all functions
# available in the scope as a dictionary. Notice that this is just done as a simple way to get
# the function callable from its string name. Then we can call it with the corresponding
# arguments.
callable_func = locals()[function_name]
function_response = callable_func(**function_args)
print("->", function_response)
# Once we have a response from the function and its arguments, we can append a new message to the chat
# history. Notice how we are telling to the model that this chat message came from a tool:
messages.append(
ToolMessage(
tool_call_id=tool_call_id,
content=json.dumps(function_response)
)
)
Bekijk het antwoord van het model:
response = client.complete(
messages=messages,
tools=tools,
)
Inhoudsveiligheid toepassen
De Azure AI-modeldeductie-API ondersteunt de veiligheid van Azure AI-inhoud. Wanneer u implementaties gebruikt waarbij de veiligheid van Azure AI-inhoud is ingeschakeld, passeren invoer en uitvoer een ensemble van classificatiemodellen die zijn gericht op het detecteren en voorkomen van de uitvoer van schadelijke inhoud. Het inhoudsfiltersysteem detecteert en onderneemt actie op specifieke categorieën van mogelijk schadelijke inhoud in zowel invoerprompts als uitvoervoltooiingen.
In het volgende voorbeeld ziet u hoe gebeurtenissen worden verwerkt wanneer het model schadelijke inhoud detecteert in de invoerprompt en de veiligheid van inhoud is ingeschakeld.
from azure.ai.inference.models import AssistantMessage, UserMessage, SystemMessage
try:
response = client.complete(
messages=[
SystemMessage(content="You are an AI assistant that helps people find information."),
UserMessage(content="Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."),
]
)
print(response.choices[0].message.content)
except HttpResponseError as ex:
if ex.status_code == 400:
response = ex.response.json()
if isinstance(response, dict) and "error" in response:
print(f"Your request triggered an {response['error']['code']} error:\n\t {response['error']['message']}")
else:
raise
raise
Tip
Raadpleeg de documentatie over de veiligheid van Azure AI-inhoud voor meer informatie over hoe u de beveiligingsinstellingen voor Azure AI-inhoud kunt configureren en beheren.
Chatvoltooiingen gebruiken met afbeeldingen
Sommige modellen kunnen reden hebben voor tekst en afbeeldingen en tekstvoltooiingen genereren op basis van beide soorten invoer. In deze sectie verkent u de mogelijkheden van sommige modellen voor visie op een chat:
Belangrijk
Sommige modellen ondersteunen slechts één afbeelding voor elke inlever in het chatgesprek en alleen de laatste afbeelding wordt in context bewaard. Als u meerdere afbeeldingen toevoegt, resulteert dit in een fout.
Als u deze mogelijkheid wilt zien, downloadt u een afbeelding en codeert u de informatie als base64 tekenreeks. De resulterende gegevens moeten zich in een gegevens-URL hebben:
from urllib.request import urlopen, Request
import base64
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
image_format = "jpeg"
request = Request(image_url, headers={"User-Agent": "Mozilla/5.0"})
image_data = base64.b64encode(urlopen(request).read()).decode("utf-8")
data_url = f"data:image/{image_format};base64,{image_data}"
Visualiseer de afbeelding:
import requests
import IPython.display as Disp
Disp.Image(requests.get(image_url).content)

Maak nu een aanvraag voor chatvoltooiing met de afbeelding:
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image=ImageUrl(url=data_url))
]),
],
temperature=0,
top_p=1,
max_tokens=2048,
)
Het antwoord is als volgt, waar u de gebruiksstatistieken van het model kunt zien:
print(f"{response.choices[0].message.role}:\n\t{response.choices[0].message.content}\n")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Belangrijk
Items die in dit artikel zijn gemarkeerd (preview) zijn momenteel beschikbaar als openbare preview. Deze preview wordt aangeboden zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
In dit artikel wordt uitgelegd hoe u de API voor chatvoltooiing gebruikt met modellen die zijn geïmplementeerd in Azure AI-modeldeductie in Azure AI-services.
Vereisten
Als u chatvoltooiingsmodellen in uw toepassing wilt gebruiken, hebt u het volgende nodig:
Een Azure-abonnement. Als u GitHub-modellen gebruikt, kunt u uw ervaring upgraden en een Azure-abonnement maken in het proces. Lees Upgrade van GitHub-modellen naar Azure AI-modeldeductie als dat uw geval is.
Een Azure AI-servicesresource. Zie Een Azure AI Services-resource maken voor meer informatie.
De eindpunt-URL en -sleutel.
Een implementatie van een chat-voltooiingsmodel. Als u nog geen gelezen model voor toevoegen en configureren voor Azure AI-services hebt om een model voor chatvoltooiing toe te voegen aan uw resource.
Installeer de Azure-deductiebibliotheek voor JavaScript met de volgende opdracht:
npm install @azure-rest/ai-inferenceTip
Lees meer over het Azure AI-deductiepakket en de naslaginformatie.
Chatvoltooiingen gebruiken
Maak eerst de client om het model te gebruiken. De volgende code maakt gebruik van een eindpunt-URL en -sleutel die zijn opgeslagen in omgevingsvariabelen.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
Als u de resource hebt geconfigureerd voor ondersteuning voor Microsoft Entra ID , kunt u het volgende codefragment gebruiken om een client te maken.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential()
);
Een aanvraag voor het voltooien van een chat maken
In het volgende voorbeeld ziet u hoe u een aanvraag voor voltooiing van een eenvoudige chat kunt maken voor het model.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
Notitie
Sommige modellen bieden geen ondersteuning voor systeemberichten (role="system"). Wanneer u de deductie-API van het Azure AI-model gebruikt, worden systeemberichten vertaald naar gebruikersberichten. Dit is de dichtstbijzijnde mogelijkheid die beschikbaar is. Deze vertaling wordt voor het gemak aangeboden, maar het is belangrijk dat u controleert of het model de instructies in het systeembericht met het juiste vertrouwensniveau volgt.
Het antwoord is als volgt, waar u de gebruiksstatistieken van het model kunt zien:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Inspecteer de usage sectie in het antwoord om het aantal tokens te zien dat wordt gebruikt voor de prompt, het totale aantal gegenereerde tokens en het aantal tokens dat wordt gebruikt voor de voltooiing.
Inhoud streamen
Standaard retourneert de voltooiings-API de volledige gegenereerde inhoud in één antwoord. Als u lange voltooiingen genereert, kan het wachten op het antwoord vele seconden duren.
U kunt de inhoud streamen om deze te verkrijgen terwijl deze wordt gegenereerd. Met streaming-inhoud kunt u beginnen met het verwerken van de voltooiing wanneer inhoud beschikbaar komt. Deze modus retourneert een object dat het antwoord terugstuurt als gebeurtenissen die alleen door de server worden verzonden. Extraheer segmenten uit het deltaveld in plaats van het berichtveld.
Als u voltooiingen wilt streamen, gebruikt .asNodeStream() u deze wanneer u het model aanroept.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
}).asNodeStream();
U kunt visualiseren hoe streaming inhoud genereert:
var stream = response.body;
if (!stream) {
stream.destroy();
throw new Error(`Failed to get chat completions with status: ${response.status}`);
}
if (response.status !== "200") {
throw new Error(`Failed to get chat completions: ${response.body.error}`);
}
var sses = createSseStream(stream);
for await (const event of sses) {
if (event.data === "[DONE]") {
return;
}
for (const choice of (JSON.parse(event.data)).choices) {
console.log(choice.delta?.content ?? "");
}
}
Meer parameters verkennen die worden ondersteund door de deductieclient
Verken andere parameters die u kunt opgeven in de deductieclient. Zie de naslaginformatie over de Deductie-API voor Azure AI-modellen voor een volledige lijst met alle ondersteunde parameters en de bijbehorende documentatie.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
presence_penalty: "0.1",
frequency_penalty: "0.8",
max_tokens: 2048,
stop: ["<|endoftext|>"],
temperature: 0,
top_p: 1,
response_format: { type: "text" },
}
});
Sommige modellen bieden geen ondersteuning voor JSON-uitvoeropmaak. U kunt het model altijd vragen om JSON-uitvoer te genereren. Dergelijke uitvoer is echter niet gegarandeerd geldige JSON.
Als u een parameter wilt doorgeven die niet in de lijst met ondersteunde parameters staat, kunt u deze doorgeven aan het onderliggende model met behulp van extra parameters. Zie Extra parameters doorgeven aan het model.
JSON-uitvoer maken
Sommige modellen kunnen JSON-uitvoer maken. Ingesteld response_format om de JSON-modus in te json_object schakelen en te garanderen dat het bericht dat het model genereert geldige JSON is. U moet ook het model instrueren om zelf JSON te produceren via een systeem- of gebruikersbericht. De inhoud van het bericht kan ook gedeeltelijk worden afgekapt als finish_reason="length", wat aangeeft dat de generatie is overschreden max_tokens of dat het gesprek de maximale contextlengte heeft overschreden.
var messages = [
{ role: "system", content: "You are a helpful assistant that always generate responses in JSON format, using."
+ " the following format: { \"answer\": \"response\" }." },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
response_format: { type: "json_object" }
}
});
Extra parameters doorgeven aan het model
Met de Azure AI-modeldeductie-API kunt u extra parameters doorgeven aan het model. In het volgende codevoorbeeld ziet u hoe u de extra parameter logprobs doorgeeft aan het model.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
headers: {
"extra-params": "pass-through"
},
body: {
messages: messages,
logprobs: true
}
});
Voordat u extra parameters doorgeeft aan de deductie-API van het Azure AI-model, moet u ervoor zorgen dat uw model deze extra parameters ondersteunt. Wanneer de aanvraag wordt ingediend bij het onderliggende model, wordt de header extra-parameters met de waarde pass-throughdoorgegeven aan het model. Met deze waarde wordt aan het eindpunt doorgegeven dat de extra parameters aan het model moeten worden doorgegeven. Het gebruik van extra parameters met het model garandeert niet dat het model deze daadwerkelijk kan verwerken. Lees de documentatie van het model om te begrijpen welke extra parameters worden ondersteund.
Hulpprogramma's gebruiken
Sommige modellen ondersteunen het gebruik van hulpprogramma's, wat een buitengewone resource kan zijn wanneer u specifieke taken uit het taalmodel moet offloaden en in plaats daarvan afhankelijk bent van een meer deterministisch systeem of zelfs een ander taalmodel. Met de Azure AI-modeldeductie-API kunt u hulpprogramma's op de volgende manier definiëren.
In het volgende codevoorbeeld wordt een hulpprogrammadefinitie gemaakt die kan zoeken op basis van vluchtinformatie uit twee verschillende steden.
const flight_info = {
name: "get_flight_info",
description: "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters: {
type: "object",
properties: {
origin_city: {
type: "string",
description: "The name of the city where the flight originates",
},
destination_city: {
type: "string",
description: "The flight destination city",
},
},
required: ["origin_city", "destination_city"],
},
}
const tools = [
{
type: "function",
function: flight_info,
},
];
In dit voorbeeld is de uitvoer van de functie dat er geen vluchten beschikbaar zijn voor de geselecteerde route, maar de gebruiker moet overwegen om een trein te nemen.
function get_flight_info(loc_origin, loc_destination) {
return {
info: "There are no flights available from " + loc_origin + " to " + loc_destination + ". You should take a train, specially if it helps to reduce CO2 emissions."
}
}
Notitie
Cohere-modellen vereisen dat de antwoorden van een hulpprogramma een geldige JSON-inhoud zijn die is opgemaakt als een tekenreeks. Zorg ervoor dat het antwoord een geldige JSON-tekenreeks is bij het samenstellen van berichten van het type Tool.
Vraag het model om vluchten te boeken met behulp van deze functie:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
tool_choice: "auto"
}
});
U kunt het antwoord controleren om erachter te komen of een hulpprogramma moet worden aangeroepen. Controleer de eindreden om te bepalen of het hulpprogramma moet worden aangeroepen. Houd er rekening mee dat er meerdere hulpprogrammatypen kunnen worden aangegeven. In dit voorbeeld ziet u een hulpprogramma van het type function.
const response_message = response.body.choices[0].message;
const tool_calls = response_message.tool_calls;
console.log("Finish reason: " + response.body.choices[0].finish_reason);
console.log("Tool call: " + tool_calls);
Als u wilt doorgaan, voegt u dit bericht toe aan de chatgeschiedenis:
messages.push(response_message);
Nu is het tijd om de juiste functie aan te roepen om de aanroep van het hulpprogramma af te handelen. Het volgende codefragment herhaalt alle hulpprogramma-aanroepen die in het antwoord worden aangegeven en roept de bijbehorende functie aan met de juiste parameters. Het antwoord wordt ook toegevoegd aan de chatgeschiedenis.
function applyToolCall({ function: call, id }) {
// Get the tool details:
const tool_params = JSON.parse(call.arguments);
console.log("Calling function " + call.name + " with arguments " + tool_params);
// Call the function defined above using `window`, which returns the list of all functions
// available in the scope as a dictionary. Notice that this is just done as a simple way to get
// the function callable from its string name. Then we can call it with the corresponding
// arguments.
const function_response = tool_params.map(window[call.name]);
console.log("-> " + function_response);
return function_response
}
for (const tool_call of tool_calls) {
var tool_response = tool_call.apply(applyToolCall);
messages.push(
{
role: "tool",
tool_call_id: tool_call.id,
content: tool_response
}
);
}
Bekijk het antwoord van het model:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
}
});
Inhoudsveiligheid toepassen
De Azure AI-modeldeductie-API ondersteunt de veiligheid van Azure AI-inhoud. Wanneer u implementaties gebruikt waarbij de veiligheid van Azure AI-inhoud is ingeschakeld, passeren invoer en uitvoer een ensemble van classificatiemodellen die zijn gericht op het detecteren en voorkomen van de uitvoer van schadelijke inhoud. Het inhoudsfiltersysteem detecteert en onderneemt actie op specifieke categorieën van mogelijk schadelijke inhoud in zowel invoerprompts als uitvoervoltooiingen.
In het volgende voorbeeld ziet u hoe gebeurtenissen worden verwerkt wanneer het model schadelijke inhoud detecteert in de invoerprompt en de veiligheid van inhoud is ingeschakeld.
try {
var messages = [
{ role: "system", content: "You are an AI assistant that helps people find information." },
{ role: "user", content: "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills." },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
console.log(response.body.choices[0].message.content);
}
catch (error) {
if (error.status_code == 400) {
var response = JSON.parse(error.response._content);
if (response.error) {
console.log(`Your request triggered an ${response.error.code} error:\n\t ${response.error.message}`);
}
else
{
throw error;
}
}
}
Tip
Raadpleeg de documentatie over de veiligheid van Azure AI-inhoud voor meer informatie over hoe u de beveiligingsinstellingen voor Azure AI-inhoud kunt configureren en beheren.
Chatvoltooiingen gebruiken met afbeeldingen
Sommige modellen kunnen reden hebben voor tekst en afbeeldingen en tekstvoltooiingen genereren op basis van beide soorten invoer. In deze sectie verkent u de mogelijkheden van sommige modellen voor visie op een chat:
Belangrijk
Sommige modellen ondersteunen slechts één afbeelding voor elke inlever in het chatgesprek en alleen de laatste afbeelding wordt in context bewaard. Als u meerdere afbeeldingen toevoegt, resulteert dit in een fout.
Als u deze mogelijkheid wilt zien, downloadt u een afbeelding en codeert u de informatie als base64 tekenreeks. De resulterende gegevens moeten zich in een gegevens-URL hebben:
const image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
const image_format = "jpeg";
const response = await fetch(image_url, { headers: { "User-Agent": "Mozilla/5.0" } });
const image_data = await response.arrayBuffer();
const image_data_base64 = Buffer.from(image_data).toString("base64");
const data_url = `data:image/${image_format};base64,${image_data_base64}`;
Visualiseer de afbeelding:
const img = document.createElement("img");
img.src = data_url;
document.body.appendChild(img);
Maak nu een aanvraag voor chatvoltooiing met de afbeelding:
var messages = [
{ role: "system", content: "You are a helpful assistant that can generate responses based on images." },
{ role: "user", content:
[
{ type: "text", text: "Which conclusion can be extracted from the following chart?" },
{ type: "image_url", image:
{
url: data_url
}
}
]
}
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
temperature: 0,
top_p: 1,
max_tokens: 2048,
}
});
Het antwoord is als volgt, waar u de gebruiksstatistieken van het model kunt zien:
console.log(response.body.choices[0].message.role + ": " + response.body.choices[0].message.content);
console.log("Model:", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Belangrijk
Items die in dit artikel zijn gemarkeerd (preview) zijn momenteel beschikbaar als openbare preview. Deze preview wordt aangeboden zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
In dit artikel wordt uitgelegd hoe u de API voor chatvoltooiing gebruikt met modellen die zijn geïmplementeerd in Azure AI-modeldeductie in Azure AI-services.
Vereisten
Als u chatvoltooiingsmodellen in uw toepassing wilt gebruiken, hebt u het volgende nodig:
Een Azure-abonnement. Als u GitHub-modellen gebruikt, kunt u uw ervaring upgraden en een Azure-abonnement maken in het proces. Lees Upgrade van GitHub-modellen naar Azure AI-modeldeductie als dat uw geval is.
Een Azure AI-servicesresource. Zie Een Azure AI Services-resource maken voor meer informatie.
De eindpunt-URL en -sleutel.
Een implementatie van een chat-voltooiingsmodel. Als u nog geen gelezen model voor toevoegen en configureren voor Azure AI-services hebt om een model voor chatvoltooiing toe te voegen aan uw resource.
Voeg het Azure AI-deductiepakket toe aan uw project:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>Tip
Lees meer over het Azure AI-deductiepakket en de naslaginformatie.
Als u Entra-id gebruikt, hebt u ook het volgende pakket nodig:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>Importeer de volgende naamruimte:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Chatvoltooiingen gebruiken
Maak eerst de client om het model te gebruiken. De volgende code maakt gebruik van een eindpunt-URL en -sleutel die zijn opgeslagen in omgevingsvariabelen.
Als u de resource hebt geconfigureerd voor ondersteuning voor Microsoft Entra ID , kunt u het volgende codefragment gebruiken om een client te maken.
Een aanvraag voor het voltooien van een chat maken
In het volgende voorbeeld ziet u hoe u een aanvraag voor voltooiing van een eenvoudige chat kunt maken voor het model.
Notitie
Sommige modellen bieden geen ondersteuning voor systeemberichten (role="system"). Wanneer u de deductie-API van het Azure AI-model gebruikt, worden systeemberichten vertaald naar gebruikersberichten. Dit is de dichtstbijzijnde mogelijkheid die beschikbaar is. Deze vertaling wordt voor het gemak aangeboden, maar het is belangrijk dat u controleert of het model de instructies in het systeembericht met het juiste vertrouwensniveau volgt.
Het antwoord is als volgt, waar u de gebruiksstatistieken van het model kunt zien:
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Inspecteer de usage sectie in het antwoord om het aantal tokens te zien dat wordt gebruikt voor de prompt, het totale aantal gegenereerde tokens en het aantal tokens dat wordt gebruikt voor de voltooiing.
Inhoud streamen
Standaard retourneert de voltooiings-API de volledige gegenereerde inhoud in één antwoord. Als u lange voltooiingen genereert, kan het wachten op het antwoord vele seconden duren.
U kunt de inhoud streamen om deze te verkrijgen terwijl deze wordt gegenereerd. Met streaming-inhoud kunt u beginnen met het verwerken van de voltooiing wanneer inhoud beschikbaar komt. Deze modus retourneert een object dat het antwoord terugstuurt als gebeurtenissen die alleen door de server worden verzonden. Extraheer segmenten uit het deltaveld in plaats van het berichtveld.
U kunt visualiseren hoe streaming inhoud genereert:
Meer parameters verkennen die worden ondersteund door de deductieclient
Verken andere parameters die u kunt opgeven in de deductieclient. Zie de naslaginformatie over de Deductie-API voor Azure AI-modellen voor een volledige lijst met alle ondersteunde parameters en de bijbehorende documentatie. Sommige modellen bieden geen ondersteuning voor JSON-uitvoeropmaak. U kunt het model altijd vragen om JSON-uitvoer te genereren. Dergelijke uitvoer is echter niet gegarandeerd geldige JSON.
Als u een parameter wilt doorgeven die niet in de lijst met ondersteunde parameters staat, kunt u deze doorgeven aan het onderliggende model met behulp van extra parameters. Zie Extra parameters doorgeven aan het model.
JSON-uitvoer maken
Sommige modellen kunnen JSON-uitvoer maken. Ingesteld response_format om de JSON-modus in te json_object schakelen en te garanderen dat het bericht dat het model genereert geldige JSON is. U moet ook het model instrueren om zelf JSON te produceren via een systeem- of gebruikersbericht. De inhoud van het bericht kan ook gedeeltelijk worden afgekapt als finish_reason="length", wat aangeeft dat de generatie is overschreden max_tokens of dat het gesprek de maximale contextlengte heeft overschreden.
Extra parameters doorgeven aan het model
Met de Azure AI-modeldeductie-API kunt u extra parameters doorgeven aan het model. In het volgende codevoorbeeld ziet u hoe u de extra parameter logprobs doorgeeft aan het model.
Voordat u extra parameters doorgeeft aan de deductie-API van het Azure AI-model, moet u ervoor zorgen dat uw model deze extra parameters ondersteunt. Wanneer de aanvraag wordt ingediend bij het onderliggende model, wordt de header extra-parameters met de waarde pass-throughdoorgegeven aan het model. Met deze waarde wordt aan het eindpunt doorgegeven dat de extra parameters aan het model moeten worden doorgegeven. Het gebruik van extra parameters met het model garandeert niet dat het model deze daadwerkelijk kan verwerken. Lees de documentatie van het model om te begrijpen welke extra parameters worden ondersteund.
Hulpprogramma's gebruiken
Sommige modellen ondersteunen het gebruik van hulpprogramma's, wat een buitengewone resource kan zijn wanneer u specifieke taken uit het taalmodel moet offloaden en in plaats daarvan afhankelijk bent van een meer deterministisch systeem of zelfs een ander taalmodel. Met de Azure AI-modeldeductie-API kunt u hulpprogramma's op de volgende manier definiëren.
In het volgende codevoorbeeld wordt een hulpprogrammadefinitie gemaakt die kan zoeken op basis van vluchtinformatie uit twee verschillende steden.
In dit voorbeeld is de uitvoer van de functie dat er geen vluchten beschikbaar zijn voor de geselecteerde route, maar de gebruiker moet overwegen om een trein te nemen.
Notitie
Cohere-modellen vereisen dat de antwoorden van een hulpprogramma een geldige JSON-inhoud zijn die is opgemaakt als een tekenreeks. Zorg ervoor dat het antwoord een geldige JSON-tekenreeks is bij het samenstellen van berichten van het type Tool.
Vraag het model om vluchten te boeken met behulp van deze functie:
U kunt het antwoord controleren om erachter te komen of een hulpprogramma moet worden aangeroepen. Controleer de eindreden om te bepalen of het hulpprogramma moet worden aangeroepen. Houd er rekening mee dat er meerdere hulpprogrammatypen kunnen worden aangegeven. In dit voorbeeld ziet u een hulpprogramma van het type function.
Als u wilt doorgaan, voegt u dit bericht toe aan de chatgeschiedenis:
Nu is het tijd om de juiste functie aan te roepen om de aanroep van het hulpprogramma af te handelen. Het volgende codefragment herhaalt alle hulpprogramma-aanroepen die in het antwoord worden aangegeven en roept de bijbehorende functie aan met de juiste parameters. Het antwoord wordt ook toegevoegd aan de chatgeschiedenis.
Bekijk het antwoord van het model:
Inhoudsveiligheid toepassen
De Azure AI-modeldeductie-API ondersteunt de veiligheid van Azure AI-inhoud. Wanneer u implementaties gebruikt waarbij de veiligheid van Azure AI-inhoud is ingeschakeld, passeren invoer en uitvoer een ensemble van classificatiemodellen die zijn gericht op het detecteren en voorkomen van de uitvoer van schadelijke inhoud. Het inhoudsfiltersysteem detecteert en onderneemt actie op specifieke categorieën van mogelijk schadelijke inhoud in zowel invoerprompts als uitvoervoltooiingen.
In het volgende voorbeeld ziet u hoe gebeurtenissen worden verwerkt wanneer het model schadelijke inhoud detecteert in de invoerprompt en de veiligheid van inhoud is ingeschakeld.
Tip
Raadpleeg de documentatie over de veiligheid van Azure AI-inhoud voor meer informatie over hoe u de beveiligingsinstellingen voor Azure AI-inhoud kunt configureren en beheren.
Chatvoltooiingen gebruiken met afbeeldingen
Sommige modellen kunnen reden hebben voor tekst en afbeeldingen en tekstvoltooiingen genereren op basis van beide soorten invoer. In deze sectie verkent u de mogelijkheden van sommige modellen voor visie op een chat:
Belangrijk
Sommige modellen ondersteunen slechts één afbeelding voor elke inlever in het chatgesprek en alleen de laatste afbeelding wordt in context bewaard. Als u meerdere afbeeldingen toevoegt, resulteert dit in een fout.
Als u deze mogelijkheid wilt zien, downloadt u een afbeelding en codeert u de informatie als base64 tekenreeks. De resulterende gegevens moeten zich in een gegevens-URL hebben:
Visualiseer de afbeelding:
Maak nu een aanvraag voor chatvoltooiing met de afbeelding:
Het antwoord is als volgt, waar u de gebruiksstatistieken van het model kunt zien:
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Belangrijk
Items die in dit artikel zijn gemarkeerd (preview) zijn momenteel beschikbaar als openbare preview. Deze preview wordt aangeboden zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
In dit artikel wordt uitgelegd hoe u de API voor chatvoltooiing gebruikt met modellen die zijn geïmplementeerd in Azure AI-modeldeductie in Azure AI-services.
Vereisten
Als u chatvoltooiingsmodellen in uw toepassing wilt gebruiken, hebt u het volgende nodig:
Een Azure-abonnement. Als u GitHub-modellen gebruikt, kunt u uw ervaring upgraden en een Azure-abonnement maken in het proces. Lees Upgrade van GitHub-modellen naar Azure AI-modeldeductie als dat uw geval is.
Een Azure AI-servicesresource. Zie Een Azure AI Services-resource maken voor meer informatie.
De eindpunt-URL en -sleutel.
Een implementatie van een chat-voltooiingsmodel. Als u nog geen gelezen model voor toevoegen en configureren voor Azure AI-services hebt om een model voor chatvoltooiing toe te voegen aan uw resource.
Installeer het Azure AI-deductiepakket met de volgende opdracht:
dotnet add package Azure.AI.Inference --prereleaseTip
Lees meer over het Azure AI-deductiepakket en de naslaginformatie.
Als u Entra-id gebruikt, hebt u ook het volgende pakket nodig:
dotnet add package Azure.Identity
Chatvoltooiingen gebruiken
Maak eerst de client om het model te gebruiken. De volgende code maakt gebruik van een eindpunt-URL en -sleutel die zijn opgeslagen in omgevingsvariabelen.
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
"mistral-large-2407"
);
Als u de resource hebt geconfigureerd voor ondersteuning voor Microsoft Entra ID , kunt u het volgende codefragment gebruiken om een client te maken.
client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(includeInteractiveCredentials: true),
"mistral-large-2407"
);
Een aanvraag voor het voltooien van een chat maken
In het volgende voorbeeld ziet u hoe u een aanvraag voor voltooiing van een eenvoudige chat kunt maken voor het model.
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
Notitie
Sommige modellen bieden geen ondersteuning voor systeemberichten (role="system"). Wanneer u de deductie-API van het Azure AI-model gebruikt, worden systeemberichten vertaald naar gebruikersberichten. Dit is de dichtstbijzijnde mogelijkheid die beschikbaar is. Deze vertaling wordt voor het gemak aangeboden, maar het is belangrijk dat u controleert of het model de instructies in het systeembericht met het juiste vertrouwensniveau volgt.
Het antwoord is als volgt, waar u de gebruiksstatistieken van het model kunt zien:
Console.WriteLine($"Response: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Inspecteer de usage sectie in het antwoord om het aantal tokens te zien dat wordt gebruikt voor de prompt, het totale aantal gegenereerde tokens en het aantal tokens dat wordt gebruikt voor de voltooiing.
Inhoud streamen
Standaard retourneert de voltooiings-API de volledige gegenereerde inhoud in één antwoord. Als u lange voltooiingen genereert, kan het wachten op het antwoord vele seconden duren.
U kunt de inhoud streamen om deze te verkrijgen terwijl deze wordt gegenereerd. Met streaming-inhoud kunt u beginnen met het verwerken van de voltooiing wanneer inhoud beschikbaar komt. Deze modus retourneert een object dat het antwoord terugstuurt als gebeurtenissen die alleen door de server worden verzonden. Extraheer segmenten uit het deltaveld in plaats van het berichtveld.
Als u voltooiingen wilt streamen, gebruikt CompleteStreamingAsync u de methode wanneer u het model aanroept. In dit voorbeeld wordt de aanroep verpakt in een asynchrone methode.
static async Task StreamMessageAsync(ChatCompletionsClient client)
{
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world? Write an essay about it.")
},
MaxTokens=4096
};
StreamingResponse<StreamingChatCompletionsUpdate> streamResponse = await client.CompleteStreamingAsync(requestOptions);
await PrintStream(streamResponse);
}
Als u de uitvoer wilt visualiseren, definieert u een asynchrone methode om de stream in de console af te drukken.
static async Task PrintStream(StreamingResponse<StreamingChatCompletionsUpdate> response)
{
await foreach (StreamingChatCompletionsUpdate chatUpdate in response)
{
if (chatUpdate.Role.HasValue)
{
Console.Write($"{chatUpdate.Role.Value.ToString().ToUpperInvariant()}: ");
}
if (!string.IsNullOrEmpty(chatUpdate.ContentUpdate))
{
Console.Write(chatUpdate.ContentUpdate);
}
}
}
U kunt visualiseren hoe streaming inhoud genereert:
StreamMessageAsync(client).GetAwaiter().GetResult();
Meer parameters verkennen die worden ondersteund door de deductieclient
Verken andere parameters die u kunt opgeven in de deductieclient. Zie de naslaginformatie over de Deductie-API voor Azure AI-modellen voor een volledige lijst met alle ondersteunde parameters en de bijbehorende documentatie.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
PresencePenalty = 0.1f,
FrequencyPenalty = 0.8f,
MaxTokens = 2048,
StopSequences = { "<|endoftext|>" },
Temperature = 0,
NucleusSamplingFactor = 1,
ResponseFormat = new ChatCompletionsResponseFormatText()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Sommige modellen bieden geen ondersteuning voor JSON-uitvoeropmaak. U kunt het model altijd vragen om JSON-uitvoer te genereren. Dergelijke uitvoer is echter niet gegarandeerd geldige JSON.
Als u een parameter wilt doorgeven die niet in de lijst met ondersteunde parameters staat, kunt u deze doorgeven aan het onderliggende model met behulp van extra parameters. Zie Extra parameters doorgeven aan het model.
JSON-uitvoer maken
Sommige modellen kunnen JSON-uitvoer maken. Ingesteld response_format om de JSON-modus in te json_object schakelen en te garanderen dat het bericht dat het model genereert geldige JSON is. U moet ook het model instrueren om zelf JSON te produceren via een systeem- of gebruikersbericht. De inhoud van het bericht kan ook gedeeltelijk worden afgekapt als finish_reason="length", wat aangeeft dat de generatie is overschreden max_tokens of dat het gesprek de maximale contextlengte heeft overschreden.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage(
"You are a helpful assistant that always generate responses in JSON format, " +
"using. the following format: { \"answer\": \"response\" }."
),
new ChatRequestUserMessage(
"How many languages are in the world?"
)
},
ResponseFormat = new ChatCompletionsResponseFormatJSON()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Extra parameters doorgeven aan het model
Met de Azure AI-modeldeductie-API kunt u extra parameters doorgeven aan het model. In het volgende codevoorbeeld ziet u hoe u de extra parameter logprobs doorgeeft aan het model.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
AdditionalProperties = { { "logprobs", BinaryData.FromString("true") } },
};
response = client.Complete(requestOptions, extraParams: ExtraParameters.PassThrough);
Console.WriteLine($"Response: {response.Value.Content}");
Voordat u extra parameters doorgeeft aan de deductie-API van het Azure AI-model, moet u ervoor zorgen dat uw model deze extra parameters ondersteunt. Wanneer de aanvraag wordt ingediend bij het onderliggende model, wordt de header extra-parameters met de waarde pass-throughdoorgegeven aan het model. Met deze waarde wordt aan het eindpunt doorgegeven dat de extra parameters aan het model moeten worden doorgegeven. Het gebruik van extra parameters met het model garandeert niet dat het model deze daadwerkelijk kan verwerken. Lees de documentatie van het model om te begrijpen welke extra parameters worden ondersteund.
Hulpprogramma's gebruiken
Sommige modellen ondersteunen het gebruik van hulpprogramma's, wat een buitengewone resource kan zijn wanneer u specifieke taken uit het taalmodel moet offloaden en in plaats daarvan afhankelijk bent van een meer deterministisch systeem of zelfs een ander taalmodel. Met de Azure AI-modeldeductie-API kunt u hulpprogramma's op de volgende manier definiëren.
In het volgende codevoorbeeld wordt een hulpprogrammadefinitie gemaakt die kan zoeken op basis van vluchtinformatie uit twee verschillende steden.
FunctionDefinition flightInfoFunction = new FunctionDefinition("getFlightInfo")
{
Description = "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
Parameters = BinaryData.FromObjectAsJson(new
{
Type = "object",
Properties = new
{
origin_city = new
{
Type = "string",
Description = "The name of the city where the flight originates"
},
destination_city = new
{
Type = "string",
Description = "The flight destination city"
}
}
},
new JsonSerializerOptions() { PropertyNamingPolicy = JsonNamingPolicy.CamelCase }
)
};
ChatCompletionsFunctionToolDefinition getFlightTool = new ChatCompletionsFunctionToolDefinition(flightInfoFunction);
In dit voorbeeld is de uitvoer van de functie dat er geen vluchten beschikbaar zijn voor de geselecteerde route, maar de gebruiker moet overwegen om een trein te nemen.
static string getFlightInfo(string loc_origin, string loc_destination)
{
return JsonSerializer.Serialize(new
{
info = $"There are no flights available from {loc_origin} to {loc_destination}. You " +
"should take a train, specially if it helps to reduce CO2 emissions."
});
}
Notitie
Cohere-modellen vereisen dat de antwoorden van een hulpprogramma een geldige JSON-inhoud zijn die is opgemaakt als een tekenreeks. Zorg ervoor dat het antwoord een geldige JSON-tekenreeks is bij het samenstellen van berichten van het type Tool.
Vraag het model om vluchten te boeken met behulp van deze functie:
var chatHistory = new List<ChatRequestMessage>(){
new ChatRequestSystemMessage(
"You are a helpful assistant that help users to find information about traveling, " +
"how to get to places and the different transportations options. You care about the" +
"environment and you always have that in mind when answering inqueries."
),
new ChatRequestUserMessage("When is the next flight from Miami to Seattle?")
};
requestOptions = new ChatCompletionsOptions(chatHistory);
requestOptions.Tools.Add(getFlightTool);
requestOptions.ToolChoice = ChatCompletionsToolChoice.Auto;
response = client.Complete(requestOptions);
U kunt het antwoord controleren om erachter te komen of een hulpprogramma moet worden aangeroepen. Controleer de eindreden om te bepalen of het hulpprogramma moet worden aangeroepen. Houd er rekening mee dat er meerdere hulpprogrammatypen kunnen worden aangegeven. In dit voorbeeld ziet u een hulpprogramma van het type function.
var responseMessage = response.Value;
var toolsCall = responseMessage.ToolCalls;
Console.WriteLine($"Finish reason: {response.Value.Choices[0].FinishReason}");
Console.WriteLine($"Tool call: {toolsCall[0].Id}");
Als u wilt doorgaan, voegt u dit bericht toe aan de chatgeschiedenis:
requestOptions.Messages.Add(new ChatRequestAssistantMessage(response.Value));
Nu is het tijd om de juiste functie aan te roepen om de aanroep van het hulpprogramma af te handelen. Het volgende codefragment herhaalt alle hulpprogramma-aanroepen die in het antwoord worden aangegeven en roept de bijbehorende functie aan met de juiste parameters. Het antwoord wordt ook toegevoegd aan de chatgeschiedenis.
foreach (ChatCompletionsToolCall tool in toolsCall)
{
if (tool is ChatCompletionsFunctionToolCall functionTool)
{
// Get the tool details:
string callId = functionTool.Id;
string toolName = functionTool.Name;
string toolArgumentsString = functionTool.Arguments;
Dictionary<string, object> toolArguments = JsonSerializer.Deserialize<Dictionary<string, object>>(toolArgumentsString);
// Here you have to call the function defined. In this particular example we use
// reflection to find the method we definied before in an static class called
// `ChatCompletionsExamples`. Using reflection allows us to call a function
// by string name. Notice that this is just done for demonstration purposes as a
// simple way to get the function callable from its string name. Then we can call
// it with the corresponding arguments.
var flags = BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Static;
string toolResponse = (string)typeof(ChatCompletionsExamples).GetMethod(toolName, flags).Invoke(null, toolArguments.Values.Cast<object>().ToArray());
Console.WriteLine("->", toolResponse);
requestOptions.Messages.Add(new ChatRequestToolMessage(toolResponse, callId));
}
else
throw new Exception("Unsupported tool type");
}
Bekijk het antwoord van het model:
response = client.Complete(requestOptions);
Inhoudsveiligheid toepassen
De Azure AI-modeldeductie-API ondersteunt de veiligheid van Azure AI-inhoud. Wanneer u implementaties gebruikt waarbij de veiligheid van Azure AI-inhoud is ingeschakeld, passeren invoer en uitvoer een ensemble van classificatiemodellen die zijn gericht op het detecteren en voorkomen van de uitvoer van schadelijke inhoud. Het inhoudsfiltersysteem detecteert en onderneemt actie op specifieke categorieën van mogelijk schadelijke inhoud in zowel invoerprompts als uitvoervoltooiingen.
In het volgende voorbeeld ziet u hoe gebeurtenissen worden verwerkt wanneer het model schadelijke inhoud detecteert in de invoerprompt en de veiligheid van inhoud is ingeschakeld.
try
{
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage(
"Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
),
},
};
response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
}
catch (RequestFailedException ex)
{
if (ex.ErrorCode == "content_filter")
{
Console.WriteLine($"Your query has trigger Azure Content Safety: {ex.Message}");
}
else
{
throw;
}
}
Tip
Raadpleeg de documentatie over de veiligheid van Azure AI-inhoud voor meer informatie over hoe u de beveiligingsinstellingen voor Azure AI-inhoud kunt configureren en beheren.
Chatvoltooiingen gebruiken met afbeeldingen
Sommige modellen kunnen reden hebben voor tekst en afbeeldingen en tekstvoltooiingen genereren op basis van beide soorten invoer. In deze sectie verkent u de mogelijkheden van sommige modellen voor visie op een chat:
Belangrijk
Sommige modellen ondersteunen slechts één afbeelding voor elke inlever in het chatgesprek en alleen de laatste afbeelding wordt in context bewaard. Als u meerdere afbeeldingen toevoegt, resulteert dit in een fout.
Als u deze mogelijkheid wilt zien, downloadt u een afbeelding en codeert u de informatie als base64 tekenreeks. De resulterende gegevens moeten zich in een gegevens-URL hebben:
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
Visualiseer de afbeelding:
Maak nu een aanvraag voor chatvoltooiing met de afbeelding:
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
Het antwoord is als volgt, waar u de gebruiksstatistieken van het model kunt zien:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Belangrijk
Items die in dit artikel zijn gemarkeerd (preview) zijn momenteel beschikbaar als openbare preview. Deze preview wordt aangeboden zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
In dit artikel wordt uitgelegd hoe u de API voor chatvoltooiing gebruikt met modellen die zijn geïmplementeerd in Azure AI-modeldeductie in Azure AI-services.
Vereisten
Als u chatvoltooiingsmodellen in uw toepassing wilt gebruiken, hebt u het volgende nodig:
Een Azure-abonnement. Als u GitHub-modellen gebruikt, kunt u uw ervaring upgraden en een Azure-abonnement maken in het proces. Lees Upgrade van GitHub-modellen naar Azure AI-modeldeductie als dat uw geval is.
Een Azure AI-servicesresource. Zie Een Azure AI Services-resource maken voor meer informatie.
De eindpunt-URL en -sleutel.
- Een implementatie van een chat-voltooiingsmodel. Als u nog geen gelezen model voor toevoegen en configureren voor Azure AI-services hebt om een model voor chatvoltooiing toe te voegen aan uw resource.
Chatvoltooiingen gebruiken
Als u de tekst insluitingen wilt gebruiken, gebruikt u de route /chat/completions die is toegevoegd aan de basis-URL, samen met uw referenties die zijn aangegeven in api-key.
Authorization header wordt ook ondersteund met de indeling Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Als u de resource hebt geconfigureerd met ondersteuning voor Microsoft Entra ID , geeft u het token door in de Authorization header:
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Een aanvraag voor het voltooien van een chat maken
In het volgende voorbeeld ziet u hoe u een aanvraag voor voltooiing van een eenvoudige chat kunt maken voor het model.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
]
}
Notitie
Sommige modellen bieden geen ondersteuning voor systeemberichten (role="system"). Wanneer u de deductie-API van het Azure AI-model gebruikt, worden systeemberichten vertaald naar gebruikersberichten. Dit is de dichtstbijzijnde mogelijkheid die beschikbaar is. Deze vertaling wordt voor het gemak aangeboden, maar het is belangrijk dat u controleert of het model de instructies in het systeembericht met het juiste vertrouwensniveau volgt.
Het antwoord is als volgt, waar u de gebruiksstatistieken van het model kunt zien:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Inspecteer de usage sectie in het antwoord om het aantal tokens te zien dat wordt gebruikt voor de prompt, het totale aantal gegenereerde tokens en het aantal tokens dat wordt gebruikt voor de voltooiing.
Inhoud streamen
Standaard retourneert de voltooiings-API de volledige gegenereerde inhoud in één antwoord. Als u lange voltooiingen genereert, kan het wachten op het antwoord vele seconden duren.
U kunt de inhoud streamen om deze te verkrijgen terwijl deze wordt gegenereerd. Met streaming-inhoud kunt u beginnen met het verwerken van de voltooiing wanneer inhoud beschikbaar komt. Deze modus retourneert een object dat het antwoord terugstuurt als gebeurtenissen die alleen door de server worden verzonden. Extraheer segmenten uit het deltaveld in plaats van het berichtveld.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"stream": true,
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
U kunt visualiseren hoe streaming inhoud genereert:
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null,
"logprobs": null
}
]
}
Het laatste bericht in de stream is finish_reason ingesteld, wat de reden aangeeft waarom het generatieproces moet worden gestopt.
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"content": ""
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Meer parameters verkennen die worden ondersteund door de deductieclient
Verken andere parameters die u kunt opgeven in de deductieclient. Zie de naslaginformatie over de Deductie-API voor Azure AI-modellen voor een volledige lijst met alle ondersteunde parameters en de bijbehorende documentatie.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"presence_penalty": 0.1,
"frequency_penalty": 0.8,
"max_tokens": 2048,
"stop": ["<|endoftext|>"],
"temperature" :0,
"top_p": 1,
"response_format": { "type": "text" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Sommige modellen bieden geen ondersteuning voor JSON-uitvoeropmaak. U kunt het model altijd vragen om JSON-uitvoer te genereren. Dergelijke uitvoer is echter niet gegarandeerd geldige JSON.
Als u een parameter wilt doorgeven die niet in de lijst met ondersteunde parameters staat, kunt u deze doorgeven aan het onderliggende model met behulp van extra parameters. Zie Extra parameters doorgeven aan het model.
JSON-uitvoer maken
Sommige modellen kunnen JSON-uitvoer maken. Ingesteld response_format om de JSON-modus in te json_object schakelen en te garanderen dat het bericht dat het model genereert geldige JSON is. U moet ook het model instrueren om zelf JSON te produceren via een systeem- of gebruikersbericht. De inhoud van het bericht kan ook gedeeltelijk worden afgekapt als finish_reason="length", wat aangeeft dat de generatie is overschreden max_tokens of dat het gesprek de maximale contextlengte heeft overschreden.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that always generate responses in JSON format, using the following format: { \"answer\": \"response\" }"
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"response_format": { "type": "json_object" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718727522,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{\"answer\": \"There are approximately 7,117 living languages in the world today, according to the latest estimates. However, this number can vary as some languages become extinct and others are newly discovered or classified.\"}",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 39,
"total_tokens": 87,
"completion_tokens": 48
}
}
Extra parameters doorgeven aan het model
Met de Azure AI-modeldeductie-API kunt u extra parameters doorgeven aan het model. In het volgende codevoorbeeld ziet u hoe u de extra parameter logprobs doorgeeft aan het model.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Authorization: Bearer <TOKEN>
Content-Type: application/json
extra-parameters: pass-through
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"logprobs": true
}
Voordat u extra parameters doorgeeft aan de deductie-API van het Azure AI-model, moet u ervoor zorgen dat uw model deze extra parameters ondersteunt. Wanneer de aanvraag wordt ingediend bij het onderliggende model, wordt de header extra-parameters met de waarde pass-throughdoorgegeven aan het model. Met deze waarde wordt aan het eindpunt doorgegeven dat de extra parameters aan het model moeten worden doorgegeven. Het gebruik van extra parameters met het model garandeert niet dat het model deze daadwerkelijk kan verwerken. Lees de documentatie van het model om te begrijpen welke extra parameters worden ondersteund.
Hulpprogramma's gebruiken
Sommige modellen ondersteunen het gebruik van hulpprogramma's, wat een buitengewone resource kan zijn wanneer u specifieke taken uit het taalmodel moet offloaden en in plaats daarvan afhankelijk bent van een meer deterministisch systeem of zelfs een ander taalmodel. Met de Azure AI-modeldeductie-API kunt u hulpprogramma's op de volgende manier definiëren.
In het volgende codevoorbeeld wordt een hulpprogrammadefinitie gemaakt die kan zoeken op basis van vluchtinformatie uit twee verschillende steden.
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
In dit voorbeeld is de uitvoer van de functie dat er geen vluchten beschikbaar zijn voor de geselecteerde route, maar de gebruiker moet overwegen om een trein te nemen.
Notitie
Cohere-modellen vereisen dat de antwoorden van een hulpprogramma een geldige JSON-inhoud zijn die is opgemaakt als een tekenreeks. Zorg ervoor dat het antwoord een geldige JSON-tekenreeks is bij het samenstellen van berichten van het type Tool.
Vraag het model om vluchten te boeken met behulp van deze functie:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
]
}
U kunt het antwoord controleren om erachter te komen of een hulpprogramma moet worden aangeroepen. Controleer de eindreden om te bepalen of het hulpprogramma moet worden aangeroepen. Houd er rekening mee dat er meerdere hulpprogrammatypen kunnen worden aangegeven. In dit voorbeeld ziet u een hulpprogramma van het type function.
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726007,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0dF1gh",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
"finish_reason": "tool_calls",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 190,
"total_tokens": 226,
"completion_tokens": 36
}
}
Als u wilt doorgaan, voegt u dit bericht toe aan de chatgeschiedenis:
Nu is het tijd om de juiste functie aan te roepen om de aanroep van het hulpprogramma af te handelen. Het volgende codefragment herhaalt alle hulpprogramma-aanroepen die in het antwoord worden aangegeven en roept de bijbehorende functie aan met de juiste parameters. Het antwoord wordt ook toegevoegd aan de chatgeschiedenis.
Bekijk het antwoord van het model:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0DeFgH",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
{
"role": "tool",
"content": "{ \"info\": \"There are no flights available from Miami to Seattle. You should take a train, specially if it helps to reduce CO2 emissions.\" }",
"tool_call_id": "abc0DeFgH"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters":{
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": ["origin_city", "destination_city"]
}
}
}
]
}
Inhoudsveiligheid toepassen
De Azure AI-modeldeductie-API ondersteunt de veiligheid van Azure AI-inhoud. Wanneer u implementaties gebruikt waarbij de veiligheid van Azure AI-inhoud is ingeschakeld, passeren invoer en uitvoer een ensemble van classificatiemodellen die zijn gericht op het detecteren en voorkomen van de uitvoer van schadelijke inhoud. Het inhoudsfiltersysteem detecteert en onderneemt actie op specifieke categorieën van mogelijk schadelijke inhoud in zowel invoerprompts als uitvoervoltooiingen.
In het volgende voorbeeld ziet u hoe gebeurtenissen worden verwerkt wanneer het model schadelijke inhoud detecteert in de invoerprompt en de veiligheid van inhoud is ingeschakeld.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are an AI assistant that helps people find information."
},
{
"role": "user",
"content": "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
}
]
}
{
"error": {
"message": "The response was filtered due to the prompt triggering Microsoft's content management policy. Please modify your prompt and retry.",
"type": null,
"param": "prompt",
"code": "content_filter",
"status": 400
}
}
Tip
Raadpleeg de documentatie over de veiligheid van Azure AI-inhoud voor meer informatie over hoe u de beveiligingsinstellingen voor Azure AI-inhoud kunt configureren en beheren.
Chatvoltooiingen gebruiken met afbeeldingen
Sommige modellen kunnen reden hebben voor tekst en afbeeldingen en tekstvoltooiingen genereren op basis van beide soorten invoer. In deze sectie verkent u de mogelijkheden van sommige modellen voor visie op een chat:
Belangrijk
Sommige modellen ondersteunen slechts één afbeelding voor elke inlever in het chatgesprek en alleen de laatste afbeelding wordt in context bewaard. Als u meerdere afbeeldingen toevoegt, resulteert dit in een fout.
Als u deze mogelijkheid wilt zien, downloadt u een afbeelding en codeert u de informatie als base64 tekenreeks. De resulterende gegevens moeten zich in een gegevens-URL hebben:
Tip
U moet de gegevens-URL maken met behulp van een script- of programmeertaal. In deze zelfstudie wordt deze voorbeeldafbeelding gebruikt in JPEG-indeling. Een gegevens-URL heeft als volgt een indeling: data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ....
{kind=link}
Visualiseer de afbeelding:
Maak nu een aanvraag voor chatvoltooiing met de afbeelding:
{
"model": "phi-3.5-vision-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
Het antwoord is als volgt, waar u de gebruiksstatistieken van het model kunt zien:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "phi-3.5-vision-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}