Een N-tier-toepassing uitvoeren in meerdere Azure Stack Hub-regio's voor hoge beschikbaarheid
Deze referentiearchitectuur toont een set bewezen procedures voor het uitvoeren in een N-tier-toepassing in meerdere Azure Stack Hub-regio's om beschikbaarheid en een robuuste infrastructuur voor herstel na noodgevallen te realiseren. In dit document wordt Traffic Manager gebruikt om hoge beschikbaarheid te bereiken. Als Traffic Manager echter geen voorkeurskeuze is in uw omgeving, kan een paar maximaal beschikbare load balancers ook worden vervangen door.
Notitie
Houd er rekening mee dat de Traffic Manager die in de onderstaande architectuur wordt gebruikt, moet worden geconfigureerd in Azure en dat de eindpunten die worden gebruikt voor het configureren van het Traffic Manager-profiel openbaar routeerbare IP-adressen moeten zijn.
Architectuur
Deze architectuur bouwt voort op de architectuur die wordt weergegeven in een N-tier-toepassing met SQL Server.
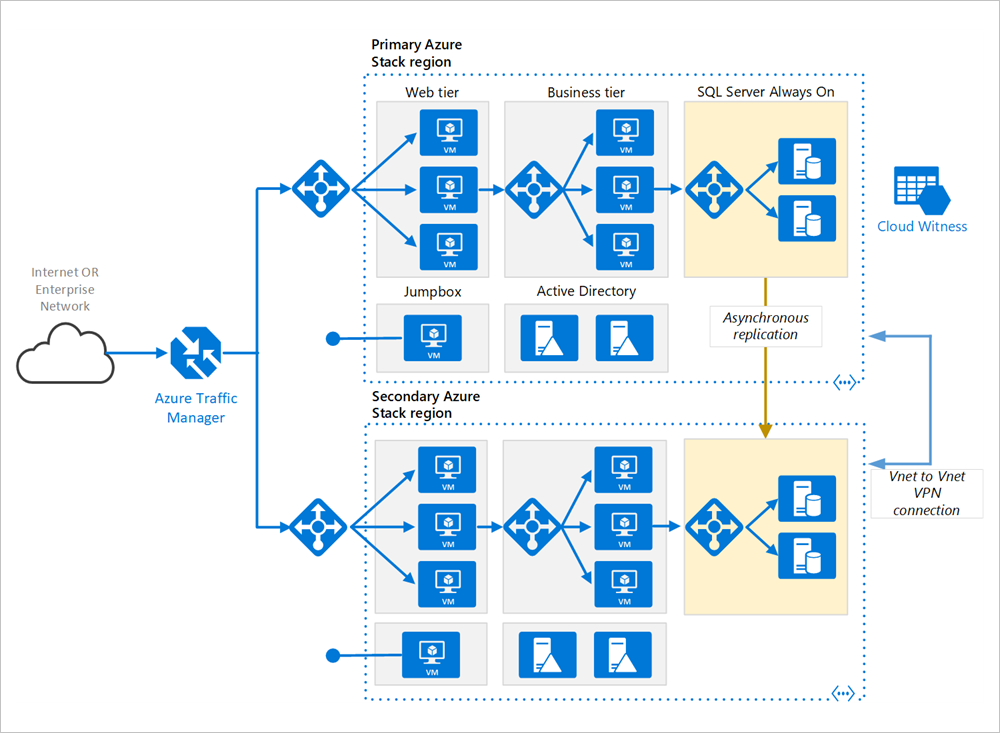
Primaire en secundaire regio. Gebruik twee regio's voor hogere beschikbaarheid. De ene regio is de primaire regio. De andere regio is voor failover.
Azure Traffic Manager. Met Traffic Manager worden binnenkomende aanvragen gerouteerd naar een van de regio's. Normaliter worden aanvragen gerouteerd naar de primaire regio. Als de primaire regio niet beschikbaar is, wordt in Traffic Manager een Failover-schakeling naar de secundaire regio uitgevoerd. Zie de sectie Configuratie van Traffic Manager voor meer informatie.
Resourcegroepen. Maak afzonderlijke resourcegroepen voor de primaire regio, de secundaire regio. Dit biedt u de flexibiliteit om elke regio te beheren als één verzameling resources. U kunt bijvoorbeeld één regio opnieuw implementeren zonder de andere regio offline te nemen. Koppel de resourcegroepen, zodat u een query voor het weergeven van alle resources voor de toepassing kunt uitvoeren.
Virtuele netwerken. Maak een afzonderlijk virtueel netwerk voor elke regio. Zorg ervoor dat de adresruimten elkaar niet overlappen.
SQL Server AlwaysOn-beschikbaarheidsgroep. Voor hoge beschikbaarheid van de SQL-server, raden we SQL AlwaysOn-beschikbaarheidsgroepen aan. Maak één beschikbaarheidsgroep met de SQL Server-exemplaren in beide regio's.
VPN-verbinding tussen VNET en VNET. Omdat VNET-peering nog niet beschikbaar is in Azure Stack Hub, gebruikt u een VNET-naar-VNET-VPN-verbinding om de twee VNET's te verbinden. Zie VNET naar VNET in Azure Stack Hub voor meer informatie.
Aanbevelingen
Een architectuur met meerdere regio's kan zorgen voor een hogere beschikbaarheid dan een implementatie in één regio. Als een regionale storing van invloed is op de primaire regio, kunt u met Traffic Manager een Failover-schakeling naar de secundaire regio uitvoeren. Deze architectuur kan ook helpen als een afzonderlijk subsysteem van de toepassing uitvalt.
Er zijn verschillende algemene methoden voor het bereiken van maximale beschikbaarheid in regio's:
Actief/passief met hot stand-by. Het verkeer wordt gerouteerd naar één regio, terwijl de andere regio wacht in hot stand-by. Hot stand-by betekent dat de virtuele machines in de secundaire regio zijn toegewezen en te allen tijde worden uitgevoerd.
Actief/passief met koude stand-by. Het verkeer wordt gerouteerd naar de ene regio, terwijl de andere regio wacht in koude stand-by. Koude stand-by betekent dat de virtuele machines in de secundaire regio pas worden toegewezen wanneer dat nodig is voor failover. Deze methode is goedkoper qua uitvoering, maar het duurt langer om het systeem weer online te brengen na uitval.
Actief/actief. Beide regio's zijn actief en aanvragen worden gelijkmatig verdeeld tussen beide regio's. Als een regio niet beschikbaar is, wordt deze uit de roulatie gehaald.
Deze referentiearchitectuur is gericht op actief/passief met hot stand-by, en Traffic Manager voor failover. U kunt een klein aantal VM's implementeren voor dynamische stand-by en vervolgens naar behoefte uitschalen.
Configuratie van Traffic Manager
Houd rekening met de volgende punten bij het configureren van Traffic Manager:
Routering. Traffic Manager biedt ondersteuning voor diverse routeringsalgoritmen. Voor het scenario dat in dit artikel wordt beschreven, gebruikt u routering voor prioriteit (voorheen routering voor failover). Bij deze instelling worden alle aanvragen door Traffic Manager verzonden naar de primaire regio, tenzij de primaire regio onbereikbaar wordt. Op dat moment wordt automatisch een Failover-schakeling naar de secundaire regio uitgevoerd. Zie Methode voor failover-routering configureren.
Statustest. Traffic Manager maakt gebruik van een HTTP- (of HTTPS-)test om de beschikbaarheid van elke regio te controleren. Met de test wordt gecontroleerd op een HTTP 200-respons van een opgegeven URL-pad. Maak, als een best practice, een eindpunt waarmee de algemene status van de toepassing wordt gerapporteerd en gebruik dit eindpunt voor de statustest. Anders wordt mogelijk een gezond eindpunt (testresultaat Geslaagd) gerapporteerd, terwijl essentiële onderdelen van de toepassing in werkelijkheid niet correct functioneren. Zie Health Endpoint Monitoring pattern (Patroon statuseindpuntbewaking) voor meer informatie.
Tijdens het uitvoeren van deze Failover-overschakeling door Traffic Manager is de toepassing tijdelijk niet bereikbaar voor clients. Hoe lang dit duurt, is afhankelijk van de volgende factoren:
Met de statustest moet worden gedetecteerd dat de primaire regio onbereikbaar is geworden.
DNS-servers moeten de DNS-records voor het IP-adres in de cache bijwerken. Hoe lang dit duurt, is afhankelijk van de DNS TTL (Time To Live). Standaard is de TTL-waarde 300 seconden (5 minuten), maar u kunt deze waarde configureren wanneer u het Traffic Manager-profiel maakt.
Zie Traffic Manager-controle voor meer informatie.
Bij een failover van Traffic Manager raden wij u aan een handmatige failback uit te voeren in plaats van een automatische failback te implementeren. Anders ontstaat er een situatie waarin de toepassing steeds van de ene naar de andere regio wordt overgeschakeld. Voer een statuscontrole van alle subsystemen voor de toepassing uit voordat u een failback uitvoert.
Houd er rekening mee dat voor Traffic Manager failback automatisch wordt uitgevoerd. Om dit te voorkomen, verlaagt u handmatig de prioriteit van de primaire regio na een failover-gebeurtenis. Stel, de primaire regio heeft prioriteit 1 en de secundaire regio heeft prioriteit 2. Na een failover stelt u de primaire regio in op prioriteit 3, zodat er niet automatisch een failback wordt uitgevoerd. Wanneer u klaar bent om terug te schakelen, werkt u de prioriteit bij naar 1.
U wijzigt de prioriteit met de volgende Azure CLI-opdracht:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --priority 3
Een andere methode is het eindpunt tijdelijk uit te schakelen totdat u klaar bent voor het uitvoeren van een failback:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --endpoint-status Disabled
Afhankelijk van de oorzaak van een failover, moet u de resources in een regio mogelijk opnieuw implementeren. Voordat u een failback uitvoert, moet u een operationele gereedheidstest uitvoeren. Tijdens de test moet onder meer het volgende worden gecontroleerd:
Virtuele machines zijn juist geconfigureerd. (Alle vereiste software is geïnstalleerd, IIS is actief, enzovoort.)
Subsystemen van de toepassing zijn in orde.
Functionele testen. (Bijvoorbeeld: de databaselaag is bereikbaar vanaf de weblaag.)
AlwaysOn-beschikbaarheidsgroepen in SQL Server configureren
Vóór Windows Server 2016 vereisten AlwaysOn-beschikbaarheidsgroepen in SQL Server een domeincontroller en moesten alle knooppunten in de beschikbaarheidsgroep zich in hetzelfde AD-domein (Active Directory) bevinden.
De beschikbaarheidsgroep configureren:
Plaats ten minste twee domeincontrollers in elke regio.
Geef elke domeincontroller een statisch IP-adres.
Vpn maken om communicatie tussen twee virtuele netwerken mogelijk te maken.
Voeg voor elk virtueel netwerk de IP-adressen van de domeincontrollers (uit beide regio's) toe aan de lijst met DNS-servers. U kunt hiervoor de volgende opdracht in de opdrachtregelinterface gebruiken. Zie DNS-servers wijzigen voor meer informatie.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Maak een WSFC-cluster (Windows Server-failoverclustering) met de SQL Server-exemplaren in beide regio's.
Maak een AlwaysOn-beschikbaarheidsgroep in SQL Server met de SQL Server-exemplaren in de primaire en secundaire regio's. Zie Extending Always On Availability Group to Remote Azure Datacenter (PowerShell) (AlwaysOn-beschikbaarheidsgroep uitbreiden naar extern Azure-datacenter) voor de benodigde stappen.
Plaats de primaire replica in de primaire regio.
Plaats een of meer secundaire replica's in de primaire regio. Configureer deze voor het gebruik van synchrone doorvoer met automatische failover.
Plaats een of meer secundaire replica's in de secundaire regio. Configureer deze voor het gebruik van asynchrone doorvoer, voor betere prestaties. (Anders moeten alle T-SQL-transacties wachten op een retour via het netwerk naar de secundaire regio.)
Notitie
Asynchrone doorvoerreplica's bieden geen ondersteuning voor automatische failover.
Beschikbaarheidsoverwegingen
Bij een complexe app met n-aantal lagen hoeft u wellicht niet hele toepassing in de secundaire regio te repliceren. In plaats daarvan kunt u ook alleen een kritiek subsysteem repliceren dat vereist is voor de bedrijfscontinuïteit.
Traffic Manager is een mogelijk punt van mislukken in het systeem. Als de Traffic Manager-service uitvalt, hebben clients geen toegang tot uw toepassing tijdens de downtime. Controleer de SLA voor Traffic Manager en bepaal of het gebruik van alleen Traffic Manager voldoet aan uw zakelijke vereisten voor hoge beschikbaarheid. Als dat niet het geval is, overweeg dan een andere oplossing voor het beheer van verkeer toe te voegen als failback. Als de service Azure Traffic Manager uitvalt, wijzigt u de CNAME-records in DNS zodanig dat ze verwijzen naar de andere service voor verkeerbeheer. (Deze stap moet handmatig worden uitgevoerd en uw toepassing pas weer beschikbaar als de DNS-wijzigingen zijn doorgegeven.)
Voor de SQL Server-cluster moet u rekening houden met twee failoverscenario's:
Alle SQL Server-databasereplica's in de primaire regio mislukken. Dit kan bijvoorbeeld gebeuren tijdens een regionale storing. In dat geval moet u handmatig een Failover-schakeling van de beschikbaarheidsgroep uitvoeren, ook al wordt automatisch een Failover-schakeling van Traffic Manager uitgevoerd op de front-end. Volg de stappen in Perform a Forced Manual Failover of a SQL Server Availability Group (Engelstalig) uit. Hierin wordt beschreven hoe u een geforceerde failover kunt uitvoeren met SQL Server Management Studio, Transact-SQL of PowerShell in SQL Server 2016.
Waarschuwing
Bij een geforceerde failover loopt u het risico dat er gegevens verloren gaan. Zodra de primaire regio weer online is, maakt u een momentopname van de database en gebruikt u tablediff om de verschillen te zoeken.
Er wordt een Failover-schakeling van Traffic Manager naar de secundaire regio uitgevoerd, maar de primaire replica van de SQL Server-database is nog steeds beschikbaar. De front-endlaag kan bijvoorbeeld mislukken, zonder de virtuele SQL Server-machines te beïnvloeden. In dat geval wordt het internetverkeer omgeleid naar de secundaire regio, en die regio kan nog steeds verbinding maken met de primaire replica. De latentie zal echter toenemen, vanwege de SQL Server-verbindingen tussen de verschillende regio's. In dit geval moet u als volgt een handmatige failover uitvoeren:
Schakel een replica van de SQL Server-database in de secundaire regio tijdelijk over naar synchrone doorvoer. Dit zorgt ervoor dat er geen gegevens verloren gaan tijdens de failover.
Voer een Failover-overschakeling naar die replica uit.
Als u een failback naar de primaire regio uitvoert, herstelt u de instelling voor asynchrone doorvoer.
Beheerbaarheidsoverwegingen
Werk, als u de implementatie wilt bijwerken, slechts één regio tegelijk bij om de kans op algehele uitval wegens een onjuiste configuratie of een fout in de toepassing te verkleinen.
Test de fouttolerantie van het systeem. Hier volgen enkele veelvoorkomende foutscenario's die u kunt testen:
VM-exemplaren afsluiten.
CPU- en geheugenresources zwaar belasten.
Netwerkverbinding verbreken/vertragen.
Processen laten vastlopen.
Certificaten laten verlopen.
Hardwarefouten simuleren.
De DNS-service op de domeincontrollers afsluiten.
Meet de hersteltijden en controleer of deze voldoen aan de vereisten van uw bedrijf. Test ook combinaties van foutmodi.
Volgende stappen
- Zie Cloudontwerppatronen voor meer informatie over Azure-cloudpatronen.