Deep learning-model van Microsoft Cognitive Toolkit gebruiken met Azure HDInsight Spark-cluster
In dit artikel voert u de volgende stappen uit.
Voer een aangepast script uit om Microsoft Cognitive Toolkit te installeren op een Azure HDInsight Spark-cluster.
Upload een Jupyter Notebook naar het Apache Spark-cluster om te zien hoe u een getraind Deep Learning-model van Microsoft Cognitive Toolkit toepast op bestanden in een Azure Blob Storage-account met behulp van de Spark Python-API (PySpark)
Vereisten
Een Apache Spark-cluster in HDInsight. Zie Een Apache Spark-cluster maken.
Weten hoe u Jupyter Notebooks gebruikt met Apache Spark on HDInsight. Zie Zelfstudie: Gegevens laden en query's uitvoeren in een Apache Spark-cluster in Azure HDInsight voor meer informatie.
Hoe verloopt deze oplossing?
Deze oplossing is verdeeld over dit artikel en een Jupyter Notebook die u uploadt als onderdeel van dit artikel. In dit artikel voert u de volgende stappen uit:
- Voer een scriptactie uit op een HDInsight Spark-cluster om Microsoft Cognitive Toolkit en Python-pakketten te installeren.
- Upload de Jupyter Notebook waarmee de oplossing wordt uitgevoerd naar het HDInsight Spark-cluster.
De volgende resterende stappen worden behandeld in het Jupyter Notebook.
- Laad voorbeeldafbeeldingen in een Spark Resilient Distributed Dataset of RDD.
- Laad modules en definieer vooraf ingestelde instellingen.
- Download de gegevensset lokaal in het Spark-cluster.
- Converteer de gegevensset naar een RDD.
- Score de afbeeldingen met behulp van een getraind Cognitive Toolkit-model.
- Download het getrainde Cognitive Toolkit-model naar het Spark-cluster.
- Definieer functies die moeten worden gebruikt door werkknooppunten.
- Score de afbeeldingen op werkknooppunten.
- De nauwkeurigheid van het model evalueren.
Microsoft Cognitive Toolkit installeren
U kunt Microsoft Cognitive Toolkit installeren op een Spark-cluster met behulp van scriptactie. Scriptactie maakt gebruik van aangepaste scripts om onderdelen op het cluster te installeren die niet standaard beschikbaar zijn. U kunt het aangepaste script gebruiken vanuit Azure Portal, met behulp van HDInsight .NET SDK of met behulp van Azure PowerShell. U kunt het script ook gebruiken om de toolkit te installeren als onderdeel van het maken van het cluster of nadat het cluster actief is.
In dit artikel gebruiken we de portal om de toolkit te installeren nadat het cluster is gemaakt. Zie HDInsight-clusters aanpassen met scriptactie voor andere manieren om het aangepaste script uit te voeren.
Met behulp van Azure Portal
Zie HDInsight-clusters aanpassen met scriptactie voor instructies over het gebruik van Azure Portal om scriptacties uit te voeren. Zorg ervoor dat u de volgende invoer opgeeft om Microsoft Cognitive Toolkit te installeren. Gebruik de volgende waarden voor uw scriptactie:
| Eigenschappen | Weergegeven als |
|---|---|
| Scripttype | - Aangepast |
| Naam | MCT installeren |
| Bash-script-URI | https://raw.githubusercontent.com/Azure-Samples/hdinsight-pyspark-cntk-integration/master/cntk-install.sh |
| Type knooppunt: | Hoofd, werkrol |
| Parameters | Geen |
Jupyter Notebook uploaden naar Azure HDInsight Spark-cluster
Als u de Microsoft Cognitive Toolkit wilt gebruiken met het Azure HDInsight Spark-cluster, moet u de Jupyter Notebook CNTK_model_scoring_on_Spark_walkthrough.ipynb laden naar het Azure HDInsight Spark-cluster. Dit notebook is beschikbaar op GitHub op https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
Downloaden en uitpakken https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
Navigeer in een webbrowser naar
https://CLUSTERNAME.azurehdinsight.net/jupyter, waarbijCLUSTERNAMEde naam van uw cluster is.Selecteer Uploaden in de Jupyter Notebook in de rechterbovenhoek en navigeer naar het download- en selecteer bestand
CNTK_model_scoring_on_Spark_walkthrough.ipynb.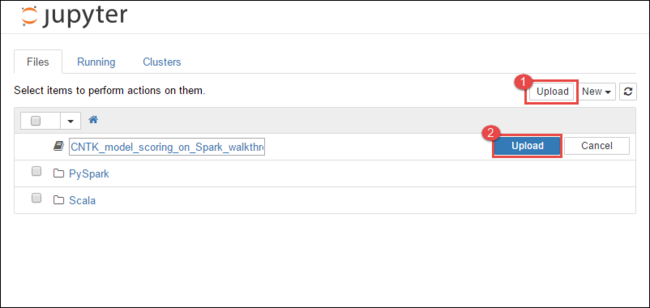
Selecteer Opnieuw uploaden .
Nadat het notitieblok is geüpload, klikt u op de naam van het notitieblok en volgt u de instructies in het notitieblok zelf over het laden van de gegevensset en het uitvoeren van het artikel.
Zie ook
Scenario's
- Apache Spark met BI: Interactieve gegevensanalyse uitvoeren met Spark in HDInsight met BI-hulpprogramma's
- Apache Spark met Machine Learning: Spark in HDInsight gebruiken voor het analyseren van de gebouwtemperatuur met behulp van HVAC-gegevens
- Apache Spark met Machine Learning: Spark in HDInsight gebruiken om resultaten van voedselinspectie te voorspellen
- Analyse van websitelogboeken met Apache Spark in HDInsight
- Application Insight-telemetriegegevensanalyse met Apache Spark in HDInsight
Toepassingen maken en uitvoeren
- Een zelfstandige toepassing maken met behulp van Scala
- Apache Livy gebruiken om taken op afstand uit te voeren in een Apache Spark-cluster
Tools en uitbreidingen
- De invoegtoepassing HDInsight Tools for IntelliJ IDEA gebruiken om Spark Scala-toepassingen te maken en in te dienen
- De invoegtoepassing HDInsight Tools voor IntelliJ IDEA gebruiken om op afstand fouten in Apache Spark-toepassingen op te sporen
- Apache Zeppelin-notebooks gebruiken met een Apache Spark-cluster in HDInsight
- Kernels beschikbaar voor Jupyter Notebook in Apache Spark-cluster voor HDInsight
- Externe pakketten gebruiken met Jupyter Notebooks
- Jupyter op uw computer installeren en verbinding maken met een HDInsight Spark-cluster