Resources beheren voor Apache Spark-cluster in Azure HDInsight
Leer hoe u toegang krijgt tot de interfaces zoals de Gebruikersinterface van Apache Ambari , de Apache Hadoop YARN-gebruikersinterface en de Spark History Server die is gekoppeld aan uw Apache Spark-cluster en hoe u de clusterconfiguratie kunt afstemmen voor optimale prestaties.
De Spark History Server openen
Spark History Server is de webgebruikersinterface voor voltooide en actieve Spark-toepassingen. Het is een uitbreiding van de webgebruikersinterface van Spark. Zie Spark History Server voor volledige informatie.
De Yarn-gebruikersinterface openen
U kunt de YARN-gebruikersinterface gebruiken om toepassingen te bewaken die momenteel worden uitgevoerd op het Spark-cluster.
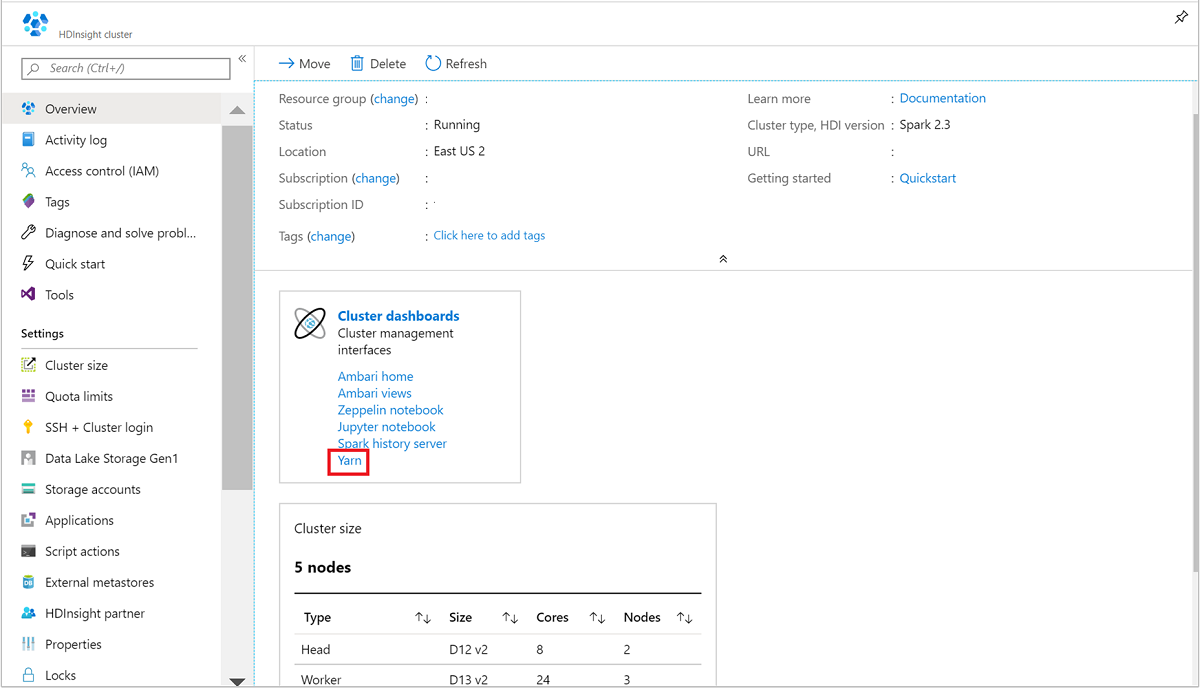
Open het Spark-cluster vanuit Azure Portal. Zie Lijst en clusters weergeven voor meer informatie.
Selecteer Yarn in clusterdashboards. Wanneer u hierom wordt gevraagd, voert u de beheerdersreferenties voor het Spark-cluster in.
Tip
U kunt ook de YARN-gebruikersinterface starten vanuit de Ambari-gebruikersinterface. Navigeer vanuit de Ambari-gebruikersinterface naar de gebruikersinterface van YARN>Quick Links>Active>Resource Manager.
Clusters optimaliseren voor Spark-toepassingen
De drie belangrijkste parameters die kunnen worden gebruikt voor Spark-configuratie, afhankelijk van de toepassingsvereisten, zijn spark.executor.instances, spark.executor.coresen spark.executor.memory. Een executor is een proces dat wordt gestart voor een Spark-toepassing. Het wordt uitgevoerd op het werkknooppunt en is verantwoordelijk voor het uitvoeren van de taken voor de toepassing. Het standaardaantal uitvoerders en de uitvoerdersgrootten voor elk cluster wordt berekend op basis van het aantal werkknooppunten en de grootte van het werkknooppunt. Deze informatie wordt opgeslagen op spark-defaults.conf de hoofdknooppunten van het cluster.
De drie configuratieparameters kunnen worden geconfigureerd op clusterniveau (voor alle toepassingen die op het cluster worden uitgevoerd) of kunnen ook worden opgegeven voor elke afzonderlijke toepassing.
De parameters wijzigen met behulp van de Ambari-gebruikersinterface
Navigeer vanuit de Ambari-gebruikersinterface naar de aangepaste spark2-standaardinstellingen van Spark 2>>.
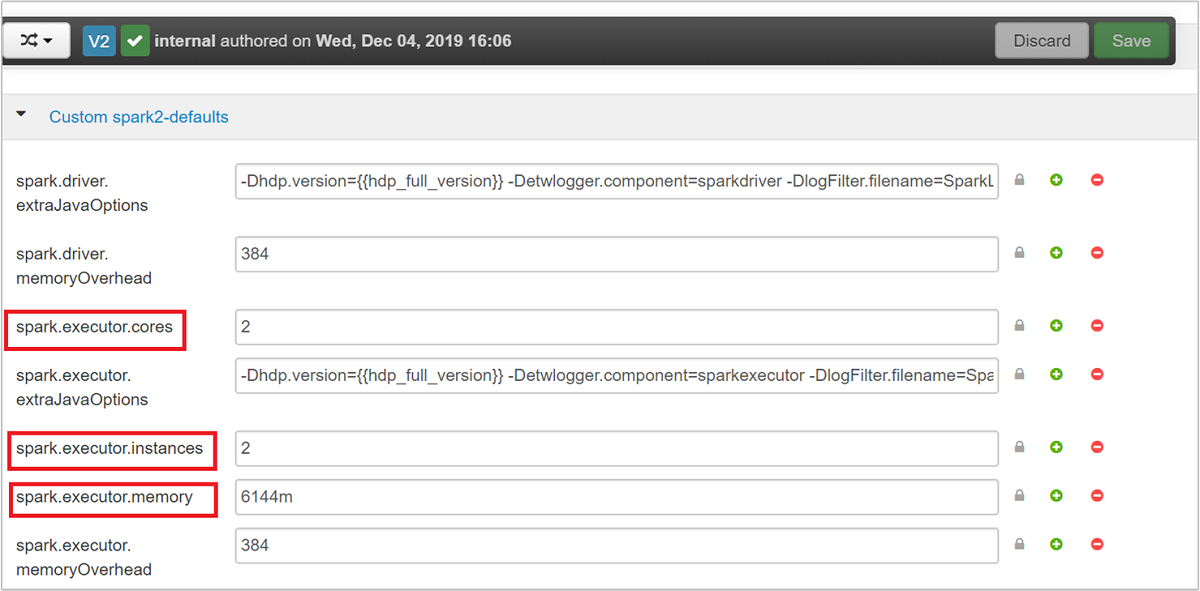
De standaardwaarden zijn handig om vier Spark-toepassingen gelijktijdig op het cluster uit te voeren. U kunt deze waarden wijzigen vanuit de gebruikersinterface, zoals wordt weergegeven in de volgende schermopname:
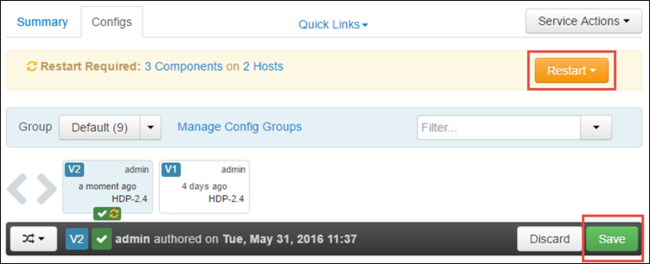
Selecteer Opslaan om de configuratiewijzigingen op te slaan. Boven aan de pagina wordt u gevraagd om alle betrokken services opnieuw op te starten. Selecteer Opnieuw starten.
De parameters wijzigen voor een toepassing die wordt uitgevoerd in Jupyter Notebook
Voor toepassingen die worden uitgevoerd in Jupyter Notebook, kunt u de %%configure magie gebruiken om de configuratiewijzigingen aan te brengen. In het ideale stadium moet u dergelijke wijzigingen aanbrengen aan het begin van de toepassing voordat u uw eerste codecel uitvoert. Dit zorgt ervoor dat de configuratie wordt toegepast op de Livy-sessie wanneer deze wordt gemaakt. Als u de configuratie in een later stadium in de toepassing wilt wijzigen, moet u de -f parameter gebruiken. Hierdoor gaat echter alle voortgang in de toepassing verloren.
Het volgende codefragment laat zien hoe u de configuratie voor een toepassing die wordt uitgevoerd in Jupyter wijzigt.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Configuratieparameters moeten worden doorgegeven als een JSON-tekenreeks en moeten zich op de volgende regel na de magie bevinden, zoals wordt weergegeven in de voorbeeldkolom.
De parameters voor een toepassing wijzigen die is verzonden met spark-submit
De volgende opdracht is een voorbeeld van het wijzigen van de configuratieparameters voor een batchtoepassing die wordt verzonden met behulp van spark-submit.
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
De parameters voor een toepassing wijzigen die is verzonden met behulp van cURL
De volgende opdracht is een voorbeeld van het wijzigen van de configuratieparameters voor een batchtoepassing die wordt verzonden met behulp van cURL.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
Notitie
Kopieer het JAR-bestand naar uw clusteropslagaccount. Kopieer het JAR-bestand niet rechtstreeks naar het hoofdknooppunt.
Deze parameters wijzigen op een Spark Thrift-server
Spark Thrift Server biedt JDBC/ODBC-toegang tot een Spark-cluster en wordt gebruikt voor het uitvoeren van Spark SQL-query's. Hulpprogramma's zoals Power BI, Tableau, enzovoort, gebruiken het ODBC-protocol om te communiceren met Spark Thrift Server om Spark SQL-query's uit te voeren als spark-toepassing. Wanneer een Spark-cluster wordt gemaakt, worden twee exemplaren van de Spark Thrift Server gestart, één op elk hoofdknooppunt. Elke Spark Thrift-server is zichtbaar als een Spark-toepassing in de YARN-gebruikersinterface.
Spark Thrift Server maakt gebruik van dynamische toewijzing van Spark-uitvoerders en wordt daarom spark.executor.instances niet gebruikt. In plaats daarvan gebruikt spark.dynamicAllocation.maxExecutors Spark Thrift Server het aantal uitvoerders en spark.dynamicAllocation.minExecutors geeft u het aantal uitvoerders op. De configuratieparameters spark.executor.coresen spark.executor.memory worden gebruikt om de grootte van de uitvoerder te wijzigen. U kunt deze parameters wijzigen, zoals wordt weergegeven in de volgende stappen:
Vouw de categorie Advanced spark2-thrift-sparkconf uit om de parameters
spark.dynamicAllocation.maxExecutorsbij te werken, enspark.dynamicAllocation.minExecutors.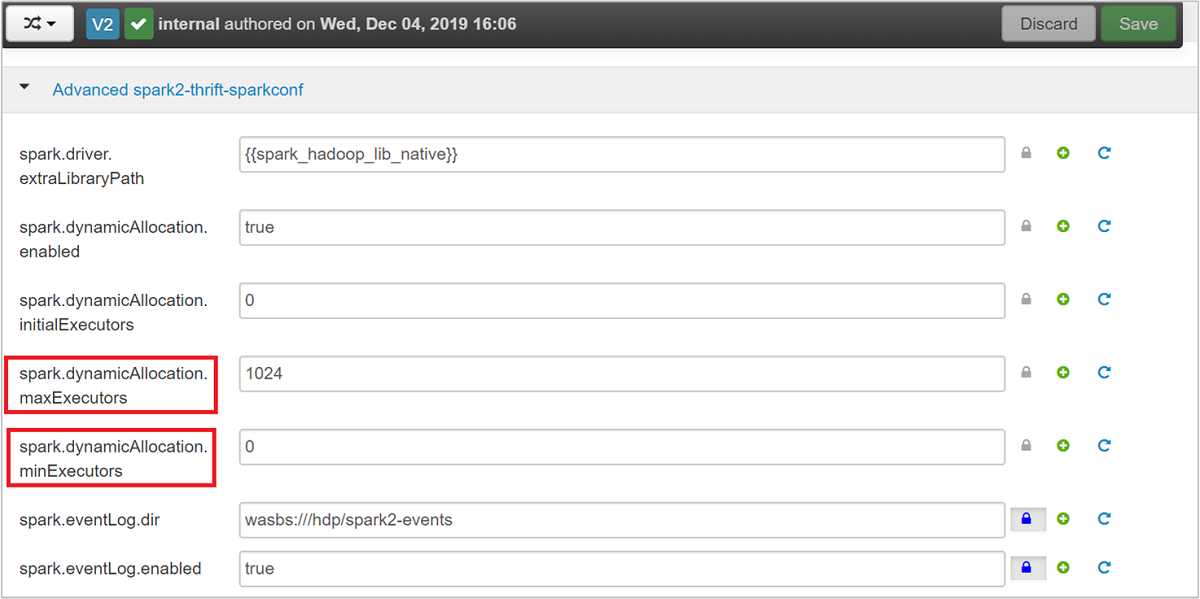
Vouw de categorie Custom spark2-thrift-sparkconf uit om de parameters
spark.executor.coresbij te werken, enspark.executor.memory.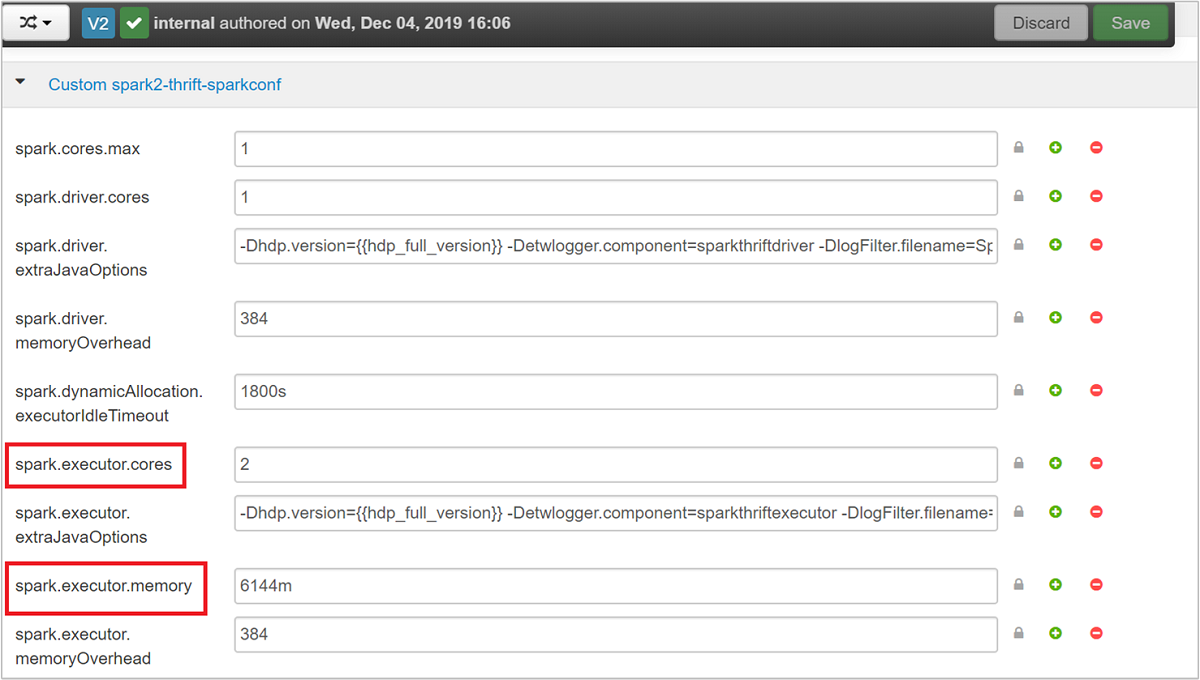
Het stuurprogrammageheugen van de Spark Thrift-server wijzigen
Spark Thrift Server-stuurprogrammageheugen is geconfigureerd op 25% van de RAM-grootte van het hoofdknooppunt, mits de totale RAM-grootte van het hoofdknooppunt groter is dan 14 GB. U kunt de Ambari-gebruikersinterface gebruiken om de geheugenconfiguratie van het stuurprogramma te wijzigen, zoals wordt weergegeven in de volgende schermopname:
Navigeer vanuit de Ambari-gebruikersinterface naar Spark2>Configs>Advanced spark2-env. Geef vervolgens de waarde op voor spark_thrift_cmd_opts.
Spark-clusterbronnen vrijmaken
Vanwege dynamische spark-toewijzing zijn de enige resources die door de thriftserver worden gebruikt, de resources voor de twee toepassingsmodellen. Als u deze resources wilt vrijmaken, moet u de Thrift Server-services die op het cluster worden uitgevoerd, stoppen.
Selecteer Spark2 in het linkerdeelvenster van de Ambari-gebruikersinterface.
Selecteer op de volgende pagina Spark 2 Thrift-servers.
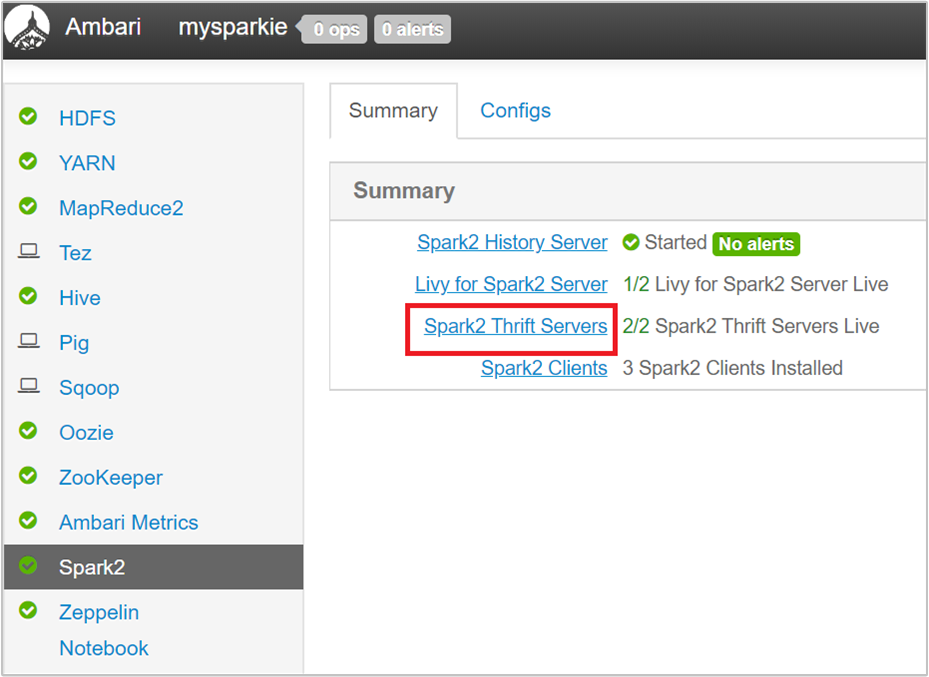
U ziet nu de twee hoofdknooppunten waarop de Spark 2 Thrift-server wordt uitgevoerd. Selecteer een van de hoofdknooppunten.
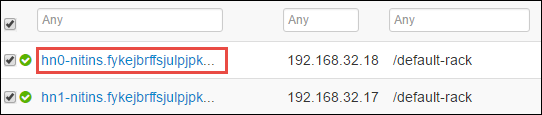
Op de volgende pagina ziet u alle services die op dat hoofdknooppunt worden uitgevoerd. Selecteer in de lijst de vervolgkeuzelijst naast Spark 2 Thrift Server en selecteer vervolgens Stoppen.
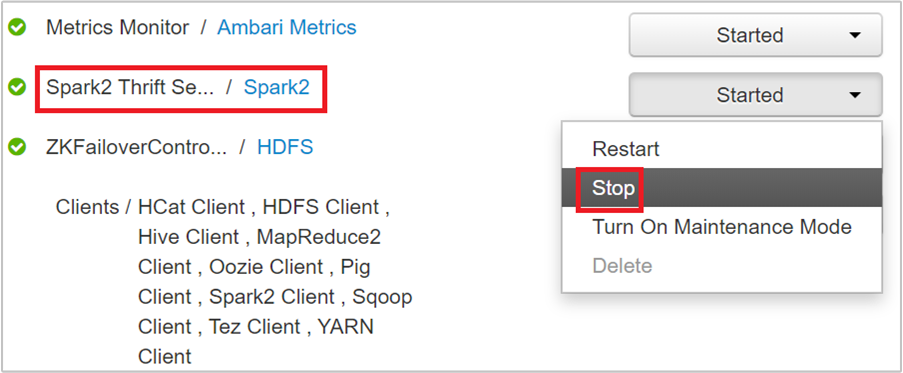
Herhaal deze stappen ook op het andere hoofdknooppunt.
De Jupyter-service opnieuw starten
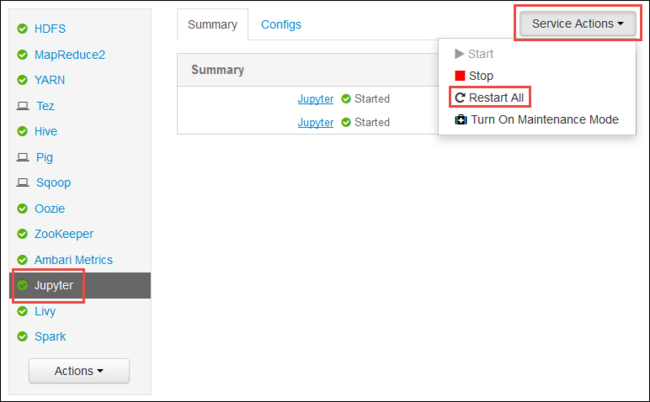
Start de Ambari-webgebruikersinterface, zoals wordt weergegeven in het begin van het artikel. Selecteer in het linkernavigatiedeelvenster Jupyter, selecteer Serviceacties en selecteer Vervolgens Alles opnieuw opstarten. Hiermee start u de Jupyter-service op alle hoofdknooppunten.
Resources bewaken
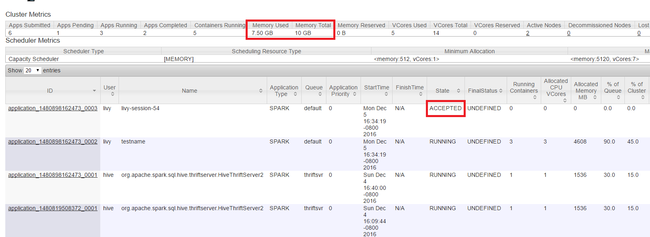
Start de Yarn-gebruikersinterface, zoals wordt weergegeven in het begin van het artikel. Controleer in de tabel Metrische gegevens van het cluster boven aan het scherm de waarden van de kolommen Geheugen gebruikt en Totaal geheugen . Als de twee waarden dicht zijn, zijn er mogelijk onvoldoende resources om de volgende toepassing te starten. Hetzelfde geldt voor de kolommen VCores Used en VCores Total . Als er in de hoofdweergave een toepassing in de status GEACCEPTEERD blijft en niet overgaat naar de status ACTIEF of MISLUKT, kan dit ook een indicatie zijn dat er onvoldoende resources zijn om te beginnen.
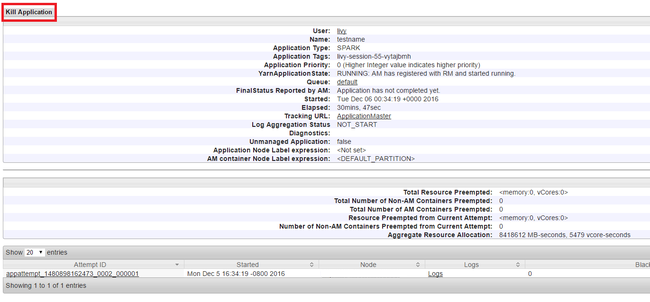
Actieve toepassingen beëindigen
Selecteer Uitvoeren in de Yarn-gebruikersinterface in het linkerdeelvenster. Bepaal in de lijst met actieve toepassingen de toepassing die moet worden gedood en selecteer de id.
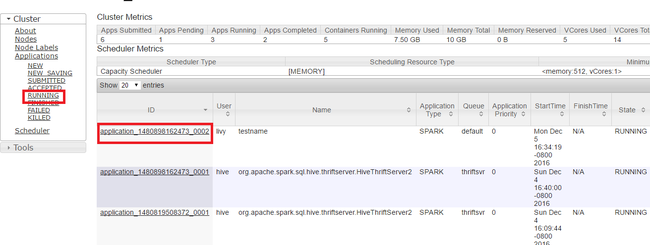
Selecteer Toepassing beëindigen in de rechterbovenhoek en selecteer VERVOLGENS OK.
Zie ook
Voor gegevensanalisten
- Apache Spark met Machine Learning: Spark in HDInsight gebruiken voor het analyseren van de gebouwtemperatuur met behulp van HVAC-gegevens
- Apache Spark met Machine Learning: Spark in HDInsight gebruiken om resultaten van voedselinspectie te voorspellen
- Analyse van websitelogboeken met Apache Spark in HDInsight
- Application Insight-telemetriegegevensanalyse met Apache Spark in HDInsight
Voor Apache Spark-ontwikkelaars
- Een zelfstandige toepassing maken met behulp van Scala
- Apache Livy gebruiken om taken op afstand uit te voeren in een Apache Spark-cluster
- De invoegtoepassing HDInsight Tools for IntelliJ IDEA gebruiken om Spark Scala-toepassingen te maken en in te dienen
- De invoegtoepassing HDInsight Tools voor IntelliJ IDEA gebruiken om op afstand fouten in Apache Spark-toepassingen op te sporen
- Apache Zeppelin-notebooks gebruiken met een Apache Spark-cluster in HDInsight
- Kernels beschikbaar voor Jupyter Notebook in Apache Spark-cluster voor HDInsight
- Externe pakketten gebruiken met Jupyter Notebooks
- Jupyter op uw computer installeren en verbinding maken met een HDInsight Spark-cluster