Utskalering av semantisk modell for Power BI
Semantisk modellutskalering hjelper Power BI med å levere rask ytelse mens rapporter og instrumentbord forbrukes av et stort publikum. Semantisk modellutskalering bruker Premium-kapasiteten til å være vert for én eller flere skrivebeskyttede kopier av den primære semantiske modellen. Ved å øke gjennomstrømmingen sikrer de skrivebeskyttede replikaene at ytelsen ikke avtar når flere brukere sender inn spørringer samtidig.
Når Power BI oppretter skrivebeskyttede replikaer, skiller den dem fra den primære leseskrivende semantiske modellen. De skrivebeskyttede replikaene tjener Power BI-rapport- og instrumentbordspørringer, og den lese-skrive semantiske modellen brukes når skrive- og oppdateringsoperasjoner utføres. Under skrive- og oppdateringsoperasjoner fortsetter de skrivebeskyttede replikaene å betjene rapportene og instrumentbordspørringene uten å bli forstyrret. Som standard synkroniseres de skrivebeskyttede og skrivebeskyttede semantiske modellene automatisk, slik at de skrivebeskyttede replikaene holdes oppdaterte. Du kan imidlertid deaktivere automatisk synkronisering og velge å synkronisere manuelt på kommandolinjen eller med skript.
Tabellen nedenfor viser den nødvendige synkroniseringen for hver oppdateringsmetode når semantisk utskalering av Power BI-semantisk modell er aktivert, og automatisk synkronisering er deaktivert:
| Oppdateringsmetode | Synkroniser |
|---|---|
| OnDemand UI | Synkroniserer alltid |
| Planlagt oppdatering | Synkroniserer alltid |
| Grunnleggende REST-API | Manuell synkronisering kreves 1 |
| Avansert REST-API | Manuell synkronisering kreves 1 |
| XMLA | Manuell synkronisering kreves 1 |
1 - Med autoSyncReadOnlyReplicas angitt queryScaleOutSettings til usann.
Replikabehandling
Skalering oppretter én lese-skrive semantisk modellreplika, og så mange skrivebeskyttede replikaer etter behov. Alle skriveoperasjoner sendes til replikaen for leseskriving. Dette inkluderer spørringer om økter som retter seg eksplisitt mot replikaen for leseskriving, det vil vil eksempel: Ikke bruk ?readonly i tilkoblingsstreng. Disse spørringene kan forårsake høy interaktiv CPU-bruk på replikaen for leseskriving. I slike tilfeller opprettes ikke en ny replika fordi spørringsbelastningen som er rettet mot skrivebeskyttet replika, ikke kan distribueres til skrivebeskyttede replikaer.
Antall skrivebeskyttede replikaer bestemmes basert på antall CUer som spørringene bruker. Hvis etterspørselen overskrider databehandlingsressursene som for øyeblikket er tilgjengelige på en node der modellen lastes inn, og forblir høy, kan det opprettes en ekstra skrivebeskyttet replika på en annen node for å distribuere belastningen. Totalt antall CUer som forbrukes av alle replikaer kombinert, kan imidlertid ikke overskride det maksimale antallet CUer som en enkelt modell har lov til å bruke på den angitte kapasitets-SKU-en.
En gitt semantisk modell på en F64-kapasitet vil for eksempel ha nok ressurser på én enkelt node til å bruke alle tillatte CUer på denne SKU-en. Derfor skalerer F64-kapasiteter vanligvis ikke utover én enkelt skrivebeskyttet replika. På den annen side er det mer sannsynlig at F256- og F1024+-kapasiteter oppretter en ny skrivebeskyttet replika fordi en enkeltnode kanskje ikke er tilstrekkelig til å gi alle CUer som har tillatelse til å brukes på en F256/F1024+-kapasitet.
QSO er utformet for å utnytte den tilgjengelige databehandlingskraften til en gitt kapasitets-SKU så effektivt og sømløst som mulig med minst antall skrivebeskyttede replikaer, og uten administrasjonskostnader for semantiske modelleiere.
Gjeldende belastning på en kapasitet kan imidlertid være høy nok til å forårsake begrensning hvis flere replikaer legges til. Begrensning hindrer at flere skrivebeskyttede replikaer når en vedvarende høy CPU-bruk. I slike tilfeller opprettes ikke en ny skala ut skrivebeskyttet replika.
En replika fjernes når CU-bruk for modellen reduseres tilstrekkelig og forblir konsekvent lav nok.
Forutsetning
Skalering er aktivert som standard for leieren, men den er ikke aktivert for semantiske modeller i leieren. Hvis du vil aktivere skalering for en semantisk modell, må du bruke REST-API-ene for Power BI. Før du aktiverer, må følgende forutsetninger oppfylles:
Skaleringsspørringene for store semantiske modeller for leieren er aktivert (standard).
Arbeidsområdet ligger på en Power BI Premium-kapasitet:
- Premium per bruker (PPU)
- Power BI Premium P SKU-er
- Power BI A SKU-er for Power BI Embedded (også kjent som innebygging for kundene dine).
- Fabric F SKU-er
Innstillingen for lagringsformat for den store semantiske modellen er aktivert.
Hvis du vil administrere semantiske modeller ved hjelp av REST-API-en, kan du bruke cmdleter for Power BI-administrasjon. Installer ved å åpne PowerShell i administratormodus og kjøre kommandoen:
Install-Module -Name MicrosoftPowerBIMgmtFølgende (eller høyere) app-, bibliotek- og tjenesteversjoner støtter tilkobling til skrivebeskyttede replikaer:
App, bibliotek eller tjeneste Versjon Ole DB-leverandør for Microsoft Analysis Services for Microsoft SQL Server (MSOLAP) 16.0.20.201 (mars 2022) Microsoft.AnalysisServices.AdomdClient (ADOMD.NET) 19.36.0 (mars 2022) Power BI Desktop Juni 2022 SQL Server Management Studio (SSMS) 19,0 Tabellredigering 2 2.16.6 Tabellredigering 3 3.2.3 DAX Studio 3.0.0
Konfigurere skalering for en semantisk modell
Hvis du vil lære hvordan du aktiverer eller deaktiverer skalering for en semantisk modell, eller får utskaleringsstatus ved hjelp av PowerShell og REST-API-ene, kan du se Konfigurere semantisk modellskala.
Koble til en bestemt semantisk modelltype
Når skalering er aktivert, beholdes følgende tilkoblinger:
Power BI Desktop kobler som standard til en skrivebeskyttet replika.
Live-tilkoblingsrapporter kobler til en skrivebeskyttet replika.
XMLA-klientprogrammer kobler til den leseskrivende semantiske modellen som standard.
Oppdateringer i Power Bi-tjeneste og oppdateringer ved hjelp av REST-API-en for forbedret oppdatering kobler til den leseskrivende semantiske modellen.
Du kan koble til en skrivebeskyttet replika eller lese-skrive semantisk modell ved å tilføye en av følgende strenger til nettadressen til den semantiske modellen:
- Skrivebeskyttet -
?readonly - Skrivetilgang -
?readwrite
Deaktiver semantisk modellutskalering for leieren
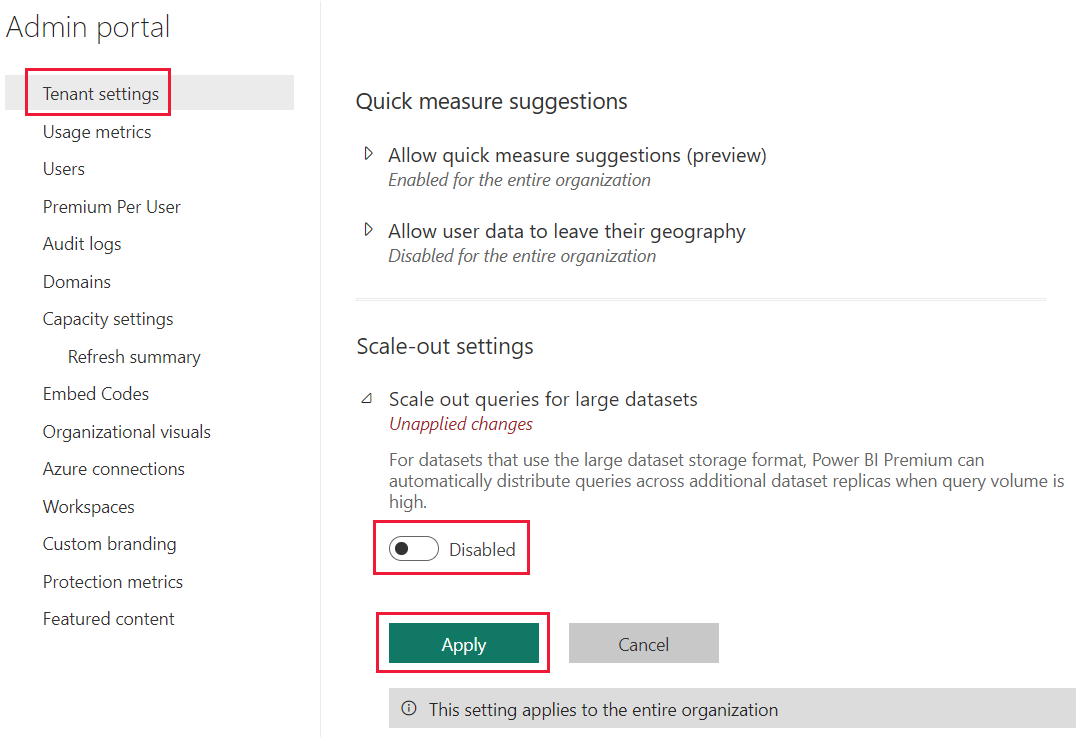
Semantisk utskalering av Power BI-semantisk modell er aktivert som standard for en leier. Power BI-leieradministratorer kan deaktivere denne innstillingen. Hvis du vil deaktivere skalering av semantisk modell for leieren, gjør du følgende:
Utvid utskaleringsspørringer for store semantiske modeller i innstillinger for utskalering.
Aktiver/deaktiver bryteren til Deaktivert.
Velg Bruk.
Hensyn og begrensninger
Klientprogrammer kan koble til en skrivebeskyttet replika gjennom XMLA-endepunktet, forutsatt at de støtter modusen som er angitt i tilkoblingsstreng. Klientprogrammer kan også koble til forekomsten av leseskriving ved hjelp av XMLA-endepunktet.
Manuelle og planlagte oppdateringer synkroniseres alltid automatisk med den nyeste versjonen av de skrivebeskyttede replikaene. REST-API-oppdateringer respekterer den automatiske synkroniseringskonfigurasjonen. Hvis automatisk synkronisering er deaktivert, må den semantiske modellen synkroniseres med skrivebeskyttede replikaer ved hjelp av rest-API-en for manuell synkronisering.
Når automatisk synkronisering er deaktivert, må XMLA-oppdateringer og oppdateringer synkroniseres med skrivebeskyttede semantiske modellkopier ved hjelp av REST-API-en for synkronisering.
Når du sletter en semantisk power BI-utskalert semantisk modell og oppretter en annen semantisk modell med samme navn, kan du la fem minutter gå før du oppretter den nye semantiske modellen. Det kan ta litt tid for Power BI å fjerne replikaene av den primære semantiske modellen.
Når semantisk utskalering av Power BI-semantisk modell er aktivert, og
autoSyncReadOnlyReplicas=falseendringer i følgende funksjoner ikke støttes:- Legge til eller slette roller
- Oppdatere settet med rollemedlemskap for enhver rolle
- Endre en datakilde
- Slette datakilder som brukes av en DirectQuery eller en dobbel tabell
- Endringer i sikkerhet på objektnivå (OLS) eller dynamiske RLS-uttrykk (row-level security)
Hvis du vil gjøre endringer i disse funksjonene, deaktiverer du utskalering og tillater noen minutter før endringen kan utføres før du prøver på nytt.
Når du oppdager rollemedlemskap ved hjelp av DMV (Dynamic Management View) TMSCHEMA_ROLE_MEMBERSHIPS radsett, returneres ingen resultater når de kjøres mot den skrivebeskyttede replikaen.
Rapporter som bruker en Live-tilkobling, kobler alltid til den skrivebeskyttede replikaen, selv om tilkoblingsstreng bruker
?readwrite. Men i Power BI Desktop kan du koble?readwritetil replikaen for leseskriving i Power BI Desktop.Radsettene DBSCHEMA_CATALOGS og DISCOVER_XML_METADATA radsettene for dynamisk administrasjonsvisning (DMV), returnerer skrivebeskyttet replikainformasjon når du bruker
?readonlyi tilkoblingsstreng.SQL Server profiler fungerer ikke med
?readonlytilkoblingsstreng.Disse operasjonene utløser automatisk synkronisering selv når automatisk synkronisering er deaktivert (
AutoSync=Off).- Overføre et arbeidsområde fra én kapasitet til en annen.
- Bytte (eller rotere) versjonen av nøkkelen som brukes for Ta med dine egne krypteringsnøkler (BYOK).
- Flytte arbeidsområdet til en semantisk modell fra en kapasitet som ikke bruker BYOK til en kapasitet som bruker BYOK.
- Flytte arbeidsområdet til en semantisk modell fra en kapasitet som bruker BYOK til en kapasitet som ikke bruker BYOK.
- Gjenopprette en semantisk modell ved hjelp av det offentlige XMLA-endepunktet.
Deaktivering av stort semantisk modelllagringsformat deaktiverer utskalering og mister all synkroniseringsinformasjon.