Overføring: Azure Synapse Analytics dedikerte SQL-bassenger til Fabric
Gjelder for:✅ Lager i Microsoft Fabric
Denne artikkelen beskriver strategien, vurderingene og metodene for overføring av datalagre i Azure Synapse Analytics dedikerte SQL-bassenger til Microsoft Fabric Warehouse.
Innføring i overføring
Da Microsoft introduserte Microsoft Fabric, en alt-i-ett-analyseløsning for bedrifter som tilbyr en omfattende tjenesteserie, inkludert Data Factory, Dataingeniør ing, Data Warehousing, Data Science, Real-Time Intelligence og Power BI.
Denne artikkelen fokuserer på alternativer for skjemaoverføring (DDL), databasekodeoverføring (DML) og dataoverføring. Microsoft tilbyr flere alternativer, og her diskuterer vi hvert alternativ i detalj og gir veiledning om hvilke av disse alternativene du bør vurdere for scenarioet ditt. Denne artikkelen bruker TPC-DS-bransjereferansen for illustrasjons- og ytelsestesting. Det faktiske resultatet kan variere avhengig av mange faktorer, inkludert datatype, datatyper, bredde på tabeller, ventetid for datakilde osv.
Klargjør for overføring
Planlegg overføringsprosjektet nøye før du kommer i gang, og sørg for at skjemaet, koden og dataene er kompatible med Fabric Warehouse. Det er noen begrensninger du må vurdere. Kvantifiser refaktoreringsarbeidet for de inkompatible elementene, samt eventuelle andre ressurser som kreves før overføringsleveringen.
Et annet viktig mål med planleggingen er å justere utformingen for å sikre at løsningen drar full nytte av den høye spørringsytelsen som Fabric Warehouse er utformet for å gi. Utforming av datalagre for skala introduserer unike utformingsmønstre, slik at tradisjonelle tilnærminger ikke alltid er best. Se gjennom ytelsesretningslinjene for Fabric Warehouse, fordi selv om noen utformingsjusteringer kan gjøres etter overføring, vil det spare tid og krefter å gjøre endringer tidligere i prosessen. Overføring fra ett teknologi/miljø til et annet er alltid en stor innsats.
Diagrammet nedenfor viser overføringens livssyklus som viser hovedsøylene som består av vurdere og evaluere, planlegge og utforme, overføre, overvåke og styre, optimalisere og modernisere søyler med de tilknyttede oppgavene i hver søyle for å planlegge og forberede seg på jevn overføring.

Runbook for overføring
Vurder følgende aktiviteter som en planleggingskjøringsbok for overføringen fra Synapse dedikerte SQL-bassenger til Fabric Warehouse.
-
Vurder og evaluer
- Identifiser mål og motivasjoner. Etablere klare ønskede resultater.
- Oppdag, vurder og grunnlinje den eksisterende arkitekturen.
- Identifiser sentrale interessenter og sponsorer.
- Definer omfanget av hva som skal overføres.
- Start små og enkle, klargjør for flere små overføringer.
- Begynn å overvåke og dokumentere alle faser av prosessen.
- Bygg beholdning av data og prosesser for overføring.
- Definer datamodellendringer (hvis noen).
- Konfigurer Fabric Workspace.
- Hva er kompetansen/preferansen din?
- Automatiser der det er mulig.
- Bruk innebygde Azure-verktøy og -funksjoner for å redusere overføringsarbeidet.
- Tren ansatte tidlig på den nye plattformen.
- Identifiser behov og opplæringsressurser, inkludert Microsoft Learn.
-
Planlegg og utforming
- Definer ønsket arkitektur.
-
Velg metoden/verktøyene for overføringen for å utføre følgende oppgaver:
- Datauthenting fra kilden.
- Skjemakonvertering (DDL), inkludert metadata for tabeller og visninger
- Datainntak, inkludert historiske data.
- Om nødvendig kan du utvikle datamodellen på nytt ved hjelp av ny plattformytelse og skalerbarhet.
- Overføring av databasekode (DML).
- Overføre eller refaktorere lagrede prosedyrer og forretningsprosesser.
- Lager og trekk ut sikkerhetsfunksjoner og objekttillatelser fra kilden.
- Utform og planlegg å erstatte/endre eksisterende ETL/ELT-prosesser for trinnvis innlasting.
- Opprett parallelle ETL/ELT-prosesser til det nye miljøet.
- Klargjøre en detaljert overføringsplan.
- Tilordne gjeldende tilstand til ny ønsket tilstand.
-
Trekke
- Utfør skjema, data, kodeoverføring.
- Datauthenting fra kilden.
- Skjemakonvertering (DDL)
- Datainntak
- Overføring av databasekode (DML).
- Hvis det er nødvendig, skalerer du de dedikerte SQL-utvalgsressursene midlertidig for å hjelpe overføringshastigheten.
- Bruk sikkerhet og tillatelser.
- Overfør eksisterende ETL/ELT-prosesser for trinnvis innlasting.
- Overfør eller refaktorer ETL/ELT trinnvise innlastingsprosesser.
- Test og sammenlign parallelle innlastingsprosesser.
- Tilpass detaljoverføringsplan etter behov.
- Utfør skjema, data, kodeoverføring.
-
Overvåk og styre
- Kjør parallelt, sammenlign med kildemiljøet.
- Test programmer, forretningsintelligensplattformer og spørringsverktøy.
- Benchmark og optimaliser spørringsytelse.
- Overvåk og administrer kostnader, sikkerhet og ytelse.
- Styringsreferanse og vurdering.
- Kjør parallelt, sammenlign med kildemiljøet.
-
Optimaliser og moderniser
- Når virksomheten er komfortabel, overgangsprogrammer og primære rapporteringsplattformer til Fabric.
- Skaler ressurser opp/ned etter hvert som arbeidsbelastningen skifter fra Azure Synapse Analytics til Microsoft Fabric.
- Bygg en repeterbar mal fra opplevelsen som er oppnådd for fremtidige overføringer. Gå.
- Identifisere muligheter for kostnadsoptimalisering, sikkerhet, skalerbarhet og driftskvalitet
- Identifiser muligheter til å modernisere dataområdet med de nyeste Fabric-funksjonene.
- Når virksomheten er komfortabel, overgangsprogrammer og primære rapporteringsplattformer til Fabric.
«Løft og skift» eller moderniser?
Generelt sett finnes det to typer overføringsscenarioer, uavhengig av formålet og omfanget av den planlagte overføringen: løft og skift som det er, eller en faset tilnærming som inkorporerer arkitektoniske og kodeendringer.
Løft og flytt
I en overføring av løft og skift overføres en eksisterende datamodell med mindre endringer i det nye Fabric Warehouse. Denne tilnærmingen minimerer risiko- og overføringstiden ved å redusere det nye arbeidet som trengs for å realisere fordelene ved overføring.
Overføring av løft og skift passer godt til disse scenarioene:
- Du har et eksisterende miljø med et lite antall datamarter som skal overføres.
- Du har et eksisterende miljø med data som allerede er i et godt utformet stjerne- eller snøfnuggskjema.
- Du er under tid og koster press for å flytte til Fabric Warehouse.
Sammendraget fungerer denne tilnærmingen bra for arbeidsbelastningene som er optimalisert med det gjeldende dedikerte SQL-utvalgsmiljøet i Synapse, og krever derfor ikke store endringer i Fabric.
Modernisere i en faset tilnærming med arkitektoniske endringer
Hvis et eldre datalager har utviklet seg over en lang periode, må du kanskje utvikle det på nytt for å opprettholde de nødvendige ytelsesnivåene.
Det kan også være lurt å redesigne arkitekturen for å dra nytte av de nye motorene og funksjonene som er tilgjengelige i Fabric Workspace.
Utformingsforskjeller: Synapse dedikerte SQL-bassenger og Fabric Warehouse
Vurder følgende azure Synapse- og Microsoft Fabric-datalagringsforskjeller, og sammenligne dedikerte SQL-bassenger med Fabric Warehouse.
Tabellhensyn
Når du overfører tabeller mellom ulike miljøer, overføres vanligvis bare rådataene og metadataene fysisk. Andre databaseelementer fra kildesystemet, for eksempel indekser, overføres vanligvis ikke fordi de kan være unødvendige eller implementert annerledes i det nye miljøet.
Ytelsesoptimaliseringer i kildemiljøet, for eksempel indekser, angir hvor du kan legge til ytelsesoptimalisering i et nytt miljø, men nå tar Fabric seg av dette automatisk for deg.
T-SQL-vurderinger
Det finnes flere syntaksforskjeller for datamanipuleringsspråk (DML) å være oppmerksom på. Se T-SQL-overflateareal i Microsoft Fabric. Vurder også en kodevurdering når du velger metode(r) for overføring for databasekoden (DML).
Avhengig av paritetsforskjellene på tidspunktet for overføringen, må du kanskje skrive om deler av T-SQL DML-koden.
Forskjeller i datatypetilordning
Det finnes flere datatypeforskjeller i Fabric Warehouse. Hvis du vil ha mer informasjon, kan du se Datatyper i Microsoft Fabric.
Tabellen nedenfor inneholder tilordningen av støttede datatyper fra Synapse dedikerte SQL-utvalg til Fabric Warehouse.
| Synapse dedikerte SQL-utvalg | Fabric Warehouse |
|---|---|
| penger | desimal(19,4) |
| småpenger | desimal(10,4) |
| smalldatetime | datetime2 |
| datetime | datetime2 |
| nchar | Char |
| nvarchar | varchar |
| tinyint | smallint |
| binær | varbinary |
| datetimeoffset* | datetime2 |
* Datetime2 lagrer ikke den ekstra tidssoneforskyvningsinformasjonen som er lagret i. Siden datatypen datetimeoffset for øyeblikket ikke støttes i Fabric Warehouse, må forskyvningsdataene for tidssone trekkes ut i en egen kolonne.
Skjema-, kode- og dataoverføringsmetoder
Se gjennom og identifiser hvilke av disse alternativene som passer til scenarioet ditt, kompetansesett for ansatte og egenskapene til dataene. De valgte alternativene avhenger av erfaring, preferanse og fordelene ved hvert av verktøyene. Målet vårt er å fortsette å utvikle overføringsverktøy som reduserer friksjon og manuell inngripen for å gjøre overføringsopplevelsen sømløs.
Denne tabellen oppsummerer informasjon om dataskjema (DDL), databasekode (DML) og dataoverføringsmetoder. Vi utvider ytterligere på hvert scenario senere i denne artikkelen, koblet i Tilvalg-kolonnen .
| Alternativnummer | Alternativ | Hva det gjør | Kompetanse/preferanse | Scenario |
|---|---|---|---|---|
| 1 | Data Factory | Skjemakonvertering (DDL) Datauttrekking Datainntak |
ADF/pipeline | Forenklet alt i ett skjema (DDL) og dataoverføring. Anbefales for dimensjonstabeller. |
| 2 | Data Factory med partisjon | Skjemakonvertering (DDL) Datauttrekking Datainntak |
ADF/pipeline | Bruk av partisjoneringsalternativer for å øke lese-/skrive-parallellismen som gir 10x gjennomstrømming kontra alternativ 1, anbefalt for faktatabeller. |
| 3 | Data Factory med akselerert kode | Skjemakonvertering (DDL) | ADF/pipeline | Konverter og overfør skjemaet (DDL) først, og bruk deretter CETAS til å trekke ut og KOPIERE/Data Factory til å innta data for optimal generell inntaksytelse. |
| 4 | Akselerert kode for lagrede prosedyrer | Skjemakonvertering (DDL) Datauttrekking Kodevurdering |
T-SQL | SQL-bruker som bruker IDE med mer detaljert kontroll over hvilke oppgaver de vil arbeide med. Bruk COPY/Data Factory til å innta data. |
| 5 | SQL Database Project-utvidelse for Azure Data Studio | Skjemakonvertering (DDL) Datauttrekking Kodevurdering |
SQL Project | SQL Database Project for distribusjon med integrering av alternativ 4. Bruk COPY eller Data Factory til å innta data. |
| 6 | OPPRETT EKSTERN TABELL SOM VELG (CETAS) | Datauttrekking | T-SQL | Kostnadseffektive data og data med høy ytelse trekkes ut i Azure Data Lake Storage (ADLS) Gen2. Bruk COPY/Data Factory til å innta data. |
| 7 | Overføre ved hjelp av dbt | Skjemakonvertering (DDL) databasekodekonvertering (DML) |
dbt | Eksisterende dbt-brukere kan bruke dbt Fabric-adapteren til å konvertere DDL og DML. Deretter må du overføre data ved hjelp av andre alternativer i denne tabellen. |
Velg en arbeidsbelastning for den første overføringen
Når du bestemmer deg for hvor du skal begynne på det dedikerte SQL-utvalget synapse til Fabric Warehouse-overføringsprosjektet, velger du et arbeidsbelastningsområde der du kan:
- Bevise levedyktigheten ved å overføre til Fabric Warehouse ved raskt å levere fordelene med det nye miljøet. Start små og enkle, klargjør for flere små overføringer.
- Gi de interne tekniske ansatte tid til å få relevant erfaring med prosessene og verktøyene de bruker når de overfører til andre områder.
- Opprett en mal for videre overføringer som er spesifikke for synapsemiljøet for kilden, og verktøyene og prosessene som er på plass for å hjelpe.
Tips
Opprett en beholdning av objekter som må overføres, og dokumenter overføringsprosessen fra start til slutt, slik at den kan gjentas for andre dedikerte SQL-utvalg eller arbeidsbelastninger.
Volumet av overførte data i en innledende overføring bør være stort nok til å demonstrere egenskapene og fordelene ved Fabric Warehouse-miljøet, men ikke for stort til raskt å demonstrere verdi. En størrelse i området 1-10 terabyte er typisk.
Overføring med Fabric Data Factory
I denne delen diskuterer vi alternativene ved hjelp av Data Factory for lavkode-/no-code-personen som er kjent med Azure Data Factory og Synapse Pipeline. Dette alternativet dra og slipp brukergrensesnittet gir et enkelt trinn for å konvertere DDL og overføre dataene.
Fabric Data Factory kan utføre følgende oppgaver:
- Konverter skjemaet (DDL) til Fabric Warehouse-syntaks.
- Opprett skjemaet (DDL) på Fabric Warehouse.
- Overføre dataene til Fabric Warehouse.
Alternativ 1. Skjema-/dataoverføring – Kopier veiviser og Foreach-kopieringsaktivitet
Denne metoden bruker Data Factory Copy assistant til å koble til det dedikerte SQL-utvalget for kilde, konvertere den dedikerte SQL Pool DDL-syntaksen til Fabric og kopiere data til Fabric Warehouse. Du kan velge 1 eller flere måltabeller (for TPC-DS-datasett er det 22 tabeller). Den genererer ForEach for å gå gjennom listen over tabeller som er valgt i brukergrensesnittet, og gyte 22 parallelle kopier aktivitetstråder.
- 22 SELECT-spørringer (én for hver valgte tabell) ble generert og utført i det dedikerte SQL-utvalget.
- Kontroller at du har riktig DWU- og ressursklasse slik at spørringene som genereres, kan utføres. I dette tilfellet trenger du minimum DWU1000 med
staticrc10for å tillate maksimalt 32 spørringer å håndtere 22 spørringer som er sendt inn. - Data Factory direkte kopiering av data fra det dedikerte SQL-utvalget til Fabric Warehouse krever oppsamling. Inntaksprosessen besto av to faser.
- Den første fasen består av å trekke ut dataene fra det dedikerte SQL-utvalget i ADLS og kalles oppsamling.
- Den andre fasen består av inntak av data fra oppsamling i Fabric Warehouse. Mesteparten av tidsberegningen for datainntak er i oppsamlingsfasen. Oppsummert har iscenesettelse en stor innvirkning på inntaksytelsen.
Anbefalt bruk
Hvis du bruker kopieringsveiviseren til å generere en ForEach, kan du konvertere DDL og innta de valgte tabellene fra det dedikerte SQL-utvalget til Fabric Warehouse i ett trinn.
Det er imidlertid ikke optimalt med den generelle gjennomstrømmingen. Kravet om å bruke oppsamling, behovet for å parallellisere lese og skrive for trinnet «Kilde til fase» er de viktigste faktorene for ytelsesventetid. Det anbefales å bare bruke dette alternativet for dimensjonstabeller.
Alternativ 2. DDL/Dataoverføring – datasamlebånd ved hjelp av partisjonsalternativ
Hvis du vil forbedre gjennomstrømmingen for å laste inn større faktatabeller ved hjelp av datasamlebånd for stoff, anbefales det å bruke Kopier aktivitet for hver faktatabell med partisjonsalternativ. Dette gir best ytelse med Kopier aktivitet.
Du har muligheten til å bruke den fysiske partisjoneringen av kildetabellen, hvis tilgjengelig. Hvis tabellen ikke har fysisk partisjonering, må du angi partisjonskolonnen og angi min/maks-verdier for å bruke dynamisk partisjonering. I skjermbildet nedenfor angir alternativene for datakilde for datasamlebånd et dynamisk område med partisjoner basert på ws_sold_date_sk kolonnen.
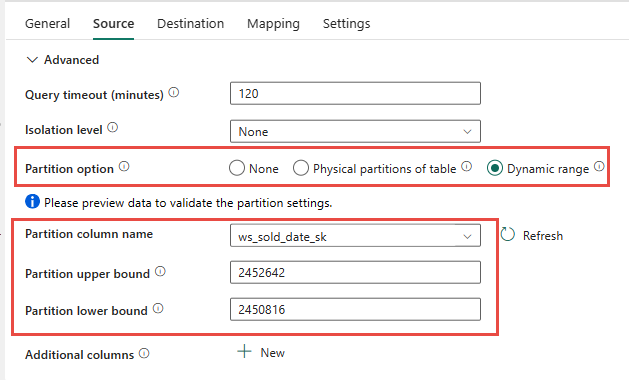
Selv om bruk av partisjon kan øke gjennomstrømmingen med oppsamlingsfasen, er det hensyn til å foreta de riktige justeringene:
- Avhengig av partisjonsområdet, kan det potensielt bruke alle samtidighetssporene, da det kan generere over 128 spørringer i det dedikerte SQL-utvalget.
- Du må skalere til minimum DWU6000 slik at alle spørringer kan utføres.
- For TPC-DS-tabellen
web_salesble for eksempel 163 spørringer sendt til det dedikerte SQL-utvalget. Ved DWU6000 ble 128 spørringer utført mens 35 spørringer ble satt i kø. - Dynamisk partisjon velger automatisk områdepartisjonen. I dette tilfellet er det et 11-dagers område for hver SELECT-spørring som sendes til det dedikerte SQL-utvalget. Eksempel:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
Anbefalt bruk
For faktatabeller anbefalte vi å bruke Data Factory med partisjoneringsalternativ for å øke gjennomstrømmingen.
De økte parallelliserte lesingene krever imidlertid dedikert SQL-utvalg for å skalere til høyere DWU for å tillate at uttrekkingsspørringene utføres. Hvis du bruker partisjonering, forbedres satsen 10x uten partisjonsalternativ. Du kan øke DWU-en for å få ekstra gjennomstrømming via databehandlingsressurser, men det dedikerte SQL-utvalget har maksimalt 128 aktive spørringer.
Merk
Hvis du vil ha mer informasjon om Synapse DWU til Fabric-tilordning, kan du se Blogg: Tilordne Azure Synapse dedikerte SQL-utvalg til datalagerdatabehandling for Fabric.
Alternativ 3. DDL-overføring – Kopier kopieringsaktivitet for veiviseren
De to foregående alternativene er gode alternativer for dataoverføring for mindre databaser. Men hvis du trenger høyere gjennomstrømming, anbefaler vi et alternativ:
- Trekk ut dataene fra det dedikerte SQL-utvalget til ADLS, og reduserer derfor ytelsesoversikten for fasen.
- Bruk enten Data Factory eller COPY-kommandoen til å innta dataene i Fabric Warehouse.
Anbefalt bruk
Du kan fortsette å bruke Data Factory til å konvertere skjemaet (DDL). Ved hjelp av kopieringsveiviseren kan du velge den bestemte tabellen eller Alle tabeller. Utforming overfører dette skjemaet og dataene i ett trinn, og trekker ut skjemaet uten rader, ved hjelp av den falske betingelsen, TOP 0 i spørringssetningen.
Følgende kodeeksempel dekker skjemaoverføring (DDL) med Data Factory.
Kodeeksempel: Skjemaoverføring (DDL) med Data Factory
Du kan bruke Fabric Data Pipelines til enkelt å overføre over DDL (skjemaer) for tabellobjekter fra en hvilken som helst kilde i Azure SQL Database eller dedikert SQL-utvalg. Dette datasamlebåndet overføres over skjemaet (DDL) for de dedikerte SQL-biljardtabellene til Fabric Warehouse.
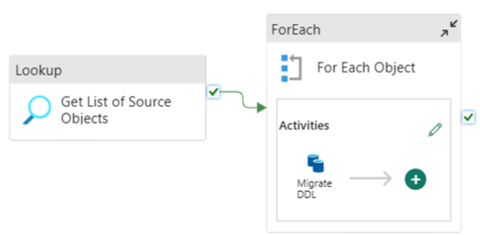
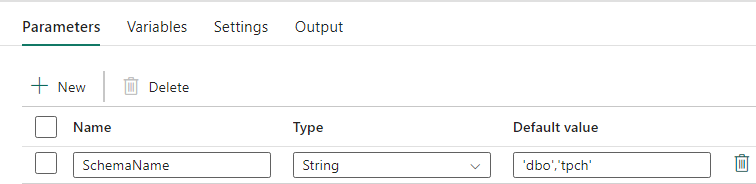
Utforming av datasamlebånd: parametere
Dette datasamlebåndet godtar en parameter SchemaName, som lar deg angi hvilke skjemaer som skal overføres. Skjemaet dbo er standard.
Angi en kommadelt liste over tabellskjema som angir hvilke skjemaer som skal overføres, i standardverdifeltet: 'dbo','tpch' for å angi to skjemaer og dbotpch.
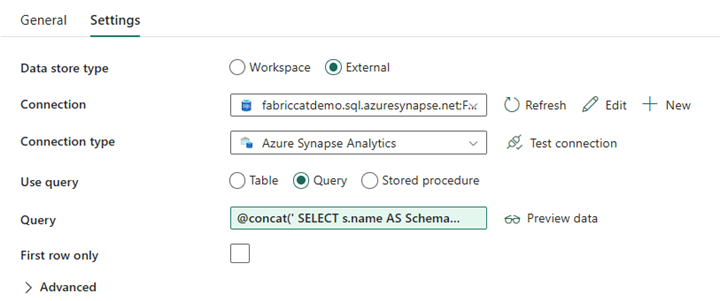
Utforming av datasamlebånd: Oppslagsaktivitet
Opprett en oppslagsaktivitet, og angi tilkoblingen til å peke til kildedatabasen.
I Innstillinger-fanen:
Angi datalagertype til Ekstern.
Tilkoblingen er azure Synapse-dedikert SQL-utvalg. Tilkoblingstypen er Azure Synapse Analytics.
Bruksspørring er satt til Spørring.
Spørringsfeltet må bygges ved hjelp av et dynamisk uttrykk, slik at parameteren SchemaName kan brukes i en spørring som returnerer en liste over målkildetabeller. Velg Spørring , og velg deretter Legg til dynamisk innhold.
Dette uttrykket i oppslagsaktiviteten genererer en SQL-setning for å spørre systemvisningene for å hente en liste over skjemaer og tabeller. Refererer til SchemaName-parameteren for å tillate filtrering på SQL-skjemaer. Utdataene for dette er en matrise med SQL-skjema og tabeller som skal brukes som inndata i ForEach-aktiviteten.
Bruk følgende kode til å returnere en liste over alle brukertabeller med skjemanavnet.
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
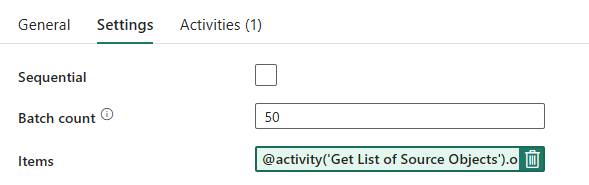
Rørledningsutforming: Forgrunnsløkke
Konfigurer følgende alternativer i Innstillinger-fanen for Foreach-løkken:
- Deaktiver sekvensiell for å tillate at flere gjentakelser kjøres samtidig.
- Angi partiantall til
50, og begrens maksimalt antall samtidige gjentakelser. - Elementer-feltet må bruke dynamisk innhold til å referere til utdataene for oppslagsaktiviteten. Bruk følgende kodesnutt:
@activity('Get List of Source Objects').output.value
Utforming av datasamlebånd: Kopier aktivitet i Foreach-løkken
Legg til en kopiaktivitet i Foreach-aktiviteten. Denne metoden bruker dynamisk uttrykksspråk i datasamlebånd til å bygge en SELECT TOP 0 * FROM <TABLE> for å overføre bare skjemaet uten data til et Fabric Warehouse.
I Kilde-fanen:
- Angi datalagertype til Ekstern.
- Tilkoblingen er azure Synapse-dedikert SQL-utvalg. Tilkoblingstypen er Azure Synapse Analytics.
- Angi bruksspørring til spørring.
-
Lim inn i den dynamiske innholdsspørringen i Spørring-feltet, og bruk dette uttrykket som returnerer null rader, bare tabellskjemaet:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

På Mål-fanen:
- Angi datalagertype til arbeidsområde.
- Datalagertypen arbeidsområde er Data Warehouse, og datalageret er satt til Fabric Warehouse.
- Skjema- og tabellnavnet for måltabellen defineres ved hjelp av dynamisk innhold.
- Skjema refererer til gjeldende gjentakelsesfelt, SchemaName med kodesnutten:
@item().SchemaName - Tabellen refererer til TableName med snutten:
@item().TableName
- Skjema refererer til gjeldende gjentakelsesfelt, SchemaName med kodesnutten:

Rørledningsutforming: Vask
Pek på lageret for Sink, og referer til kildeskjemaet og tabellnavnet.
Når du har kjørt dette datasamlebåndet, vil du se datalageret fylt ut med hver tabell i kilden, med riktig skjema.
Overføring ved hjelp av lagrede prosedyrer i synapse dedikert SQL-utvalg
Dette alternativet bruker lagrede prosedyrer til å utføre stoffoverføringen.
Du kan få kodeeksempler på microsoft/fabric-migration på GitHub.com. Denne koden deles som åpen kilde, så du kan gjerne bidra til å samarbeide og hjelpe fellesskapet.
Hvilke lagrede prosedyrer for overføring kan gjøre:
- Konverter skjemaet (DDL) til Fabric Warehouse-syntaks.
- Opprett skjemaet (DDL) på Fabric Warehouse.
- Trekk ut data fra synapse dedikert SQL-utvalg til ADLS.
- Flagg stoffsyntaks for T-SQL-koder som ikke støttes (lagrede prosedyrer, funksjoner, visninger).
Anbefalt bruk
Dette er et flott alternativ for de som:
- Er kjent med T-SQL.
- Vil bruke et integrert utviklingsmiljø, for eksempel SQL Server Management Studio (SSMS).
- Vil ha mer detaljert kontroll over hvilke oppgaver de vil arbeide med.
Du kan utføre den spesifikke lagrede prosedyren for skjemakonvertering, datauttrekking eller T-SQL-kodevurdering.
For dataoverføringen må du bruke ENTEN COPY INTO eller Data Factory til å innta dataene til Fabric Warehouse.
Overføre ved hjelp av SQL-databaseprosjekter
Microsoft Fabric Data Warehouse støttes i SQL Database Projects-utvidelsen som er tilgjengelig i Azure Data Studio og Visual Studio Code.
Denne utvidelsen er tilgjengelig i Azure Data Studio og Visual Studio Code. Denne funksjonen aktiverer funksjoner for kildekontroll, databasetesting og skjemavalidering.
Hvis du vil ha mer informasjon om kildekontroll for lagre i Microsoft Fabric, inkludert Git-integrering og distribusjonssamlebånd, kan du se Kildekontroll med Lager.
Anbefalt bruk
Dette er et flott alternativ for de som foretrekker å bruke SQL Database Project for distribusjonen. Dette alternativet integrerte i hovedsak de lagrede prosedyrene for stoffoverføring i SQL Database Project for å gi en sømløs overføringsopplevelse.
Et SQL Database Project kan:
- Konverter skjemaet (DDL) til Fabric Warehouse-syntaks.
- Opprett skjemaet (DDL) på Fabric Warehouse.
- Trekk ut data fra synapse dedikert SQL-utvalg til ADLS.
- Flagg ikke-støttet syntaks for T-SQL-koder (lagrede prosedyrer, funksjoner, visninger).
Når det gjelder dataoverføringen, bruker du enten COPY INTO eller Data Factory til å innta dataene til Fabric Warehouse.
Microsoft Fabric CAT-teamet legger til Azure Data Studio-støtte for Microsoft Fabric, og har levert et sett med PowerShell-skript for å håndtere uttrekking, oppretting og distribusjon av skjema (DDL) og databasekode (DML) via et SQL Database Project. Hvis du vil ha en gjennomgang av hvordan du bruker SQL Database-prosjektet med våre nyttige PowerShell-skript, kan du se microsoft/fabric-migration på GitHub.com.
Hvis du vil ha mer informasjon om SQL Database Projects, kan du se Komme i gang med SQL Database Projects-utvidelsen og bygge og publisere et prosjekt.
Overføring av data med CETAS
KOMMANDOEN T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) gir den mest kostnadseffektive og optimale metoden for å trekke ut data fra Synapse-dedikerte SQL-utvalg til Azure Data Lake Storage (ADLS) Gen2.
Hva CETAS kan gjøre:
- Pakk ut data i ADLS.
- Dette alternativet krever at brukere oppretter skjemaet (DDL) på Fabric Warehouse før de inntar dataene. Vurder alternativene i denne artikkelen for å overføre skjema (DDL).
Fordelene med dette alternativet er:
- Bare én enkelt spørring per tabell sendes inn mot det dedikerte SQL-utvalget for kildesynapse. Dette vil ikke bruke opp alle samtidighetssporene, og vil derfor ikke blokkere samtidige kundeproduksjons-ETL/spørringer.
- Skalering til DWU6000 er ikke nødvendig, da bare ett enkelt samtidighetsspor brukes for hver tabell, slik at kunder kan bruke lavere DWUer.
- Ekstraktet kjøres parallelt på tvers av alle databehandlingsnodene, og dette er nøkkelen til forbedring av ytelsen.
Anbefalt bruk
Bruk CETAS til å trekke ut dataene til ADLS som parkettfiler. Parquet files provide the advantage of efficient data storage with columnar compression that will take less bandwidth to move across the network. I tillegg, siden Fabric lagret dataene som Delta-parkettformat, vil datainntaket være 2,5x raskere sammenlignet med tekstfilformatet, siden det ikke er noen konvertering til Delta-formatet overhead under inntak.
Slik øker du CETAS-gjennomstrømmingen:
- Legg til parallelle CETAS-operasjoner, noe som øker bruken av samtidighetsspor, men tillater mer gjennomstrømming.
- Skaler DWU på synapse dedikert SQL-utvalg.
Overføring via dbt
I denne delen diskuterer vi dbt-alternativet for de kundene som allerede bruker dbt i det gjeldende dedikerte SQL-utvalgsmiljøet for Synapse.
Hva dbt kan gjøre:
- Konverter skjemaet (DDL) til Fabric Warehouse-syntaks.
- Opprett skjemaet (DDL) på Fabric Warehouse.
- Konverter databasekode (DML) til stoffsyntaks.
DBT-rammeverket genererer DDL og DML (SQL-skript) på farten med hver kjøring. Med modellfiler uttrykt i SELECT-setninger, kan DDL/DML oversettes umiddelbart til en hvilken som helst målplattform ved å endre profilen (tilkoblingsstreng) og adaptertypen.
Anbefalt bruk
DBT-rammeverket er kode-første tilnærming. Dataene må overføres ved hjelp av alternativer som er oppført i dette dokumentet, for eksempel CETAS eller COPY/Data Factory.
DBT-adapteren for Microsoft Fabric Data Warehouse gjør at eksisterende dbt-prosjekter som var rettet mot forskjellige plattformer som Synapse-dedikerte SQL-bassenger, Snowflake, Databricks, Google Big Query eller Amazon Redshift, kan overføres til et Fabric Warehouse med en enkel konfigurasjonsendring.
Hvis du vil komme i gang med et dbt-prosjekt rettet mot Fabric Warehouse, kan du se Opplæring: Konfigurere dbt for Fabric Data Warehouse. Dette dokumentet viser også et alternativ for å flytte mellom ulike lagre/plattformer.
Datainntak i Fabric Warehouse
For inntak i Fabric Warehouse, bruk COPY INTO eller Fabric Data Factory, avhengig av hva du foretrekker. Begge metodene er de anbefalte og beste alternativene, da de har tilsvarende ytelsesgjennomstrømming, gitt forutsetningen om at filene allerede er pakket ut til Azure Data Lake Storage (ADLS) Gen2.
Flere faktorer å merke seg, slik at du kan utforme prosessen for maksimal ytelse:
- Med Fabric er det ingen ressursstrid når du laster inn flere tabeller fra ADLS til Fabric Warehouse samtidig. Derfor er det ingen ytelsesnedbrytning ved innlasting av parallelle tråder. Maksimal gjennomstrømming av inntak begrenses bare av databehandlingskraften til stoffkapasiteten.
- Administrasjon av stoffarbeidsbelastning gir fordeling av ressurser som er tildelt for innlasting og spørring. Det er ingen ressurskonflikt mens spørringer og datainnlasting utføres samtidig.