Opplæring del 3: Lære opp og registrere en maskinlæringsmodell
I denne opplæringen lærer du å lære opp flere maskinlæringsmodeller for å velge den beste for å forutsi hvilke bankkunder som sannsynligvis vil forlate.
I denne opplæringen gjør du følgende:
- Kalibrer Random Forest- og LightGBM-modeller.
- Bruk Microsoft Fabrics opprinnelige integrasjon med MLflow-rammeverket til å logge de opplærte maskinlæringsmodellene, de brukte hyperaparameterne og evalueringsmåledataene.
- Registrer den opplærte maskinlæringsmodellen.
- Vurder resultatene til de opplærte maskinlæringsmodellene på valideringsdatasettet.
MLflow er en åpen kilde plattform for administrasjon av maskinlæringslivssyklusen med funksjoner som Sporing, Modeller og Modellregister. MLflow er integrert med Fabric Data Science-opplevelsen.
Forutsetning
Få et Microsoft Fabric-abonnement. Eller registrer deg for en gratis prøveversjon av Microsoft Fabric.
Logg på Microsoft Fabric.
Bruk opplevelsesbryteren til venstre på hjemmesiden for å bytte til Synapse Data Science-opplevelsen.

Dette er del 3 av 5 i opplæringsserien. Hvis du vil fullføre denne opplæringen, må du først fullføre:
- Del 1: Innta data i et Microsoft Fabric lakehouse ved hjelp av Apache Spark.
- Del 2: Utforske og visualisere data ved hjelp av Microsoft Fabric-notatblokker for å lære mer om dataene.
Følg med i notatblokken
3-train-evaluate.ipynb er notatblokken som følger med denne opplæringen.
Hvis du vil åpne den medfølgende notatblokken for denne opplæringen, følger du instruksjonene i Klargjør systemet for opplæring for datavitenskap, for å importere notatblokken til arbeidsområdet.
Hvis du heller vil kopiere og lime inn koden fra denne siden, kan du opprette en ny notatblokk.
Pass på at du fester et lakehouse til notatblokken før du begynner å kjøre kode.
Viktig
Fest det samme lakehouse du brukte i del 1 og del 2.
Installere egendefinerte biblioteker
For denne notatblokken installerer du ubalansert lære (importert som imblearn) ved hjelp av %pip install. Ubalansert lære er et bibliotek for Synthetic Minority Oversampling Technique (SMOTE) som brukes når du arbeider med ubalanserte datasett. PySpark-kjernen startes på nytt etter %pip install, så du må installere biblioteket før du kjører andre celler.
Du får tilgang til SMOTE ved hjelp av imblearn biblioteket. Installer den nå ved hjelp av de innebygde installasjonsfunksjonene (for eksempel %pip, ). %conda
# Install imblearn for SMOTE using pip
%pip install imblearn
Viktig
Kjør denne installasjonen hver gang du starter notatblokken på nytt.
Når du installerer et bibliotek i en notatblokk, er det bare tilgjengelig i løpet av notatblokkøkten og ikke i arbeidsområdet. Hvis du starter notatblokken på nytt, må du installere biblioteket på nytt.
Hvis du har et bibliotek du ofte bruker, og du vil gjøre det tilgjengelig for alle notatblokker i arbeidsområdet, kan du bruke et stoffmiljø til dette formålet. Du kan opprette et miljø, installere biblioteket i det, og deretter kan administratoren for arbeidsområdet knytte miljøet til arbeidsområdet som standardmiljø. Hvis du vil ha mer informasjon om hvordan du angir et miljø som standard for arbeidsområdet, kan du se Administrator angir standardbiblioteker for arbeidsområdet.
Hvis du vil ha informasjon om overføring av eksisterende arbeidsområdebiblioteker og Spark-egenskaper til et miljø, kan du se Overføre arbeidsområdebiblioteker og Spark-egenskaper til et standardmiljø.
Laste inn dataene
Før du lærer opp en maskinlæringsmodell, må du laste deltatabellen fra lakehouse for å kunne lese de rengjorte dataene du opprettet i den forrige notatblokken.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Generer eksperiment for sporing og logging av modellen ved hjelp av MLflow
Denne delen viser hvordan du genererer et eksperiment, angir maskinlæringsmodellen og opplæringsparameterne samt måledata for poengsummer, lærer opp maskinlæringsmodellene, logger dem og lagrer de opplærte modellene for senere bruk.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment" # MLflow experiment name
Hvis du utvider egenskapene for automatisk tillogging av MLflow, fungerer autologging ved automatisk å registrere verdiene for inndataparametere og utdatadata for en maskinlæringsmodell etter hvert som den blir opplært. Denne informasjonen logges deretter på arbeidsområdet, der den kan åpnes og visualiseres ved hjelp av MLflow-API-ene eller det tilsvarende eksperimentet i arbeidsområdet.
Alle eksperimentene med de respektive navnene logges, og du kan spore parameterne og ytelsesmåledataene. Hvis du vil lære mer om autologging, kan du se Autologging i Microsoft Fabric.
Angi spesifikasjoner for eksperiment og autologging
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Importer scikit-learn og LightGBM
Med dataene på plass kan du nå definere maskinlæringsmodellene. Du bruker Random Forest- og LightGBM-modeller i denne notatblokken. Bruk scikit-learn og lightgbm til å implementere modellene innenfor noen få linjer med kode.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Klargjøre opplærings-, validerings- og testdatasett
train_test_split Bruk funksjonen fra scikit-learn til å dele dataene inn i opplærings-, validerings- og testsett.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Lagre testdata i en deltatabell
Lagre testdataene i deltatabellen for bruk i neste notatblokk.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
Bruk SMOTE på opplæringsdataene for å syntetisere nye eksempler for minoritetsklassen
Datautforskningen i del 2 viste at av de 10 000 datapunktene som tilsvarer 10 000 kunder, har bare 2037 kunder (rundt 20 %) forlatt banken. Dette indikerer at datasettet er svært ubalansert. Problemet med ubalansert klassifisering er at det er for få eksempler på minoritetsklassen for en modell å effektivt lære beslutningsgrensen. SMOTE er den mest brukte tilnærmingen til å syntetisere nye eksempler for minoritetsklassen. Mer informasjon om SMOTE her og her.
Tips
Vær oppmerksom på at SMOTE bare skal brukes på opplæringsdatasettet. Du må la testdatasettet stå i den opprinnelige ubalanserte fordelingen for å få en gyldig tilnærming til hvordan maskinlæringsmodellen skal fungere på de opprinnelige dataene, som representerer situasjonen i produksjonen.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Tips
Du kan trygt ignorere MLflow-advarselen som vises når du kjører denne cellen.
Hvis du ser en ModuleNotFoundError-melding , gikk du glipp av å kjøre den første cellen i denne notatblokken, som installerer imblearn biblioteket. Du må installere dette biblioteket hver gang du starter notatblokken på nytt. Gå tilbake og kjør alle cellene på nytt fra og med den første cellen i denne notatblokken.
Modellopplæring
- Kalibrer modellen ved hjelp av Random Forest med maksimal dybde på 4 og 4 funksjoner
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Kalibrer modellen ved hjelp av Random Forest med maksimal dybde på 8 og 6 funksjoner
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- Kalibrer modellen ved hjelp av LightGBM
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
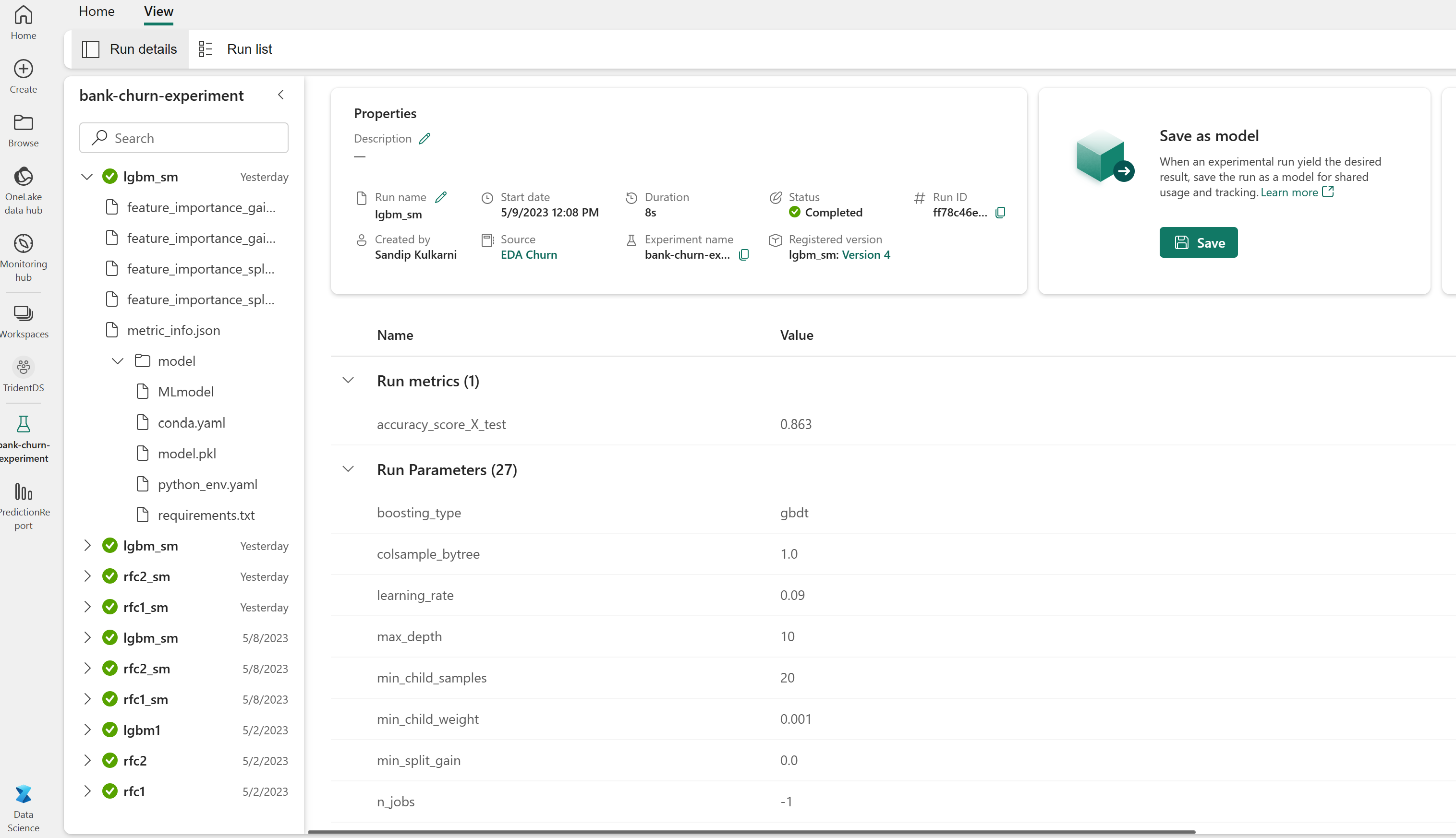
Eksperimenter artefakt for sporing av modellytelse
Eksperimentkjøringene lagres automatisk i eksperimentartefakten som finnes fra arbeidsområdet. De er navngitt basert på navnet som brukes til å angi eksperimentet. Alle de opplærte maskinlæringsmodellene, kjøringene, ytelsesmåledataene og modellparameterne logges.
Slik viser du eksperimentene dine:
Velg arbeidsområdet i venstre panel.
Filtrer for å vise bare eksperimenter øverst til høyre for å gjøre det enklere å finne eksperimentet du leter etter.
Finn og velg eksperimentnavnet, i dette tilfellet bank-churn-eksperiment. Hvis du ikke ser eksperimentet i arbeidsområdet, kan du oppdatere nettleseren.


Vurder resultatene av de opplærte modellene på valideringsdatasettet
Når du er ferdig med opplæring i maskinlæringsmodellen, kan du vurdere ytelsen til opplærte modeller på to måter.
Åpne det lagrede eksperimentet fra arbeidsområdet, last inn maskinlæringsmodellene, og vurder deretter ytelsen til de innlastede modellene på valideringsdatasettet.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMVurder ytelsen til de opplærte maskinlæringsmodellene direkte på valideringsdatasettet.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
Avhengig av hva du foretrekker, er begge tilnærmingene fine og bør tilby identiske forestillinger. I denne notatblokken velger du den første fremgangsmåten for bedre å demonstrere autologgingsfunksjonene for MLflow i Microsoft Fabric.
Vis sanne/falske positiver/negativer ved hjelp av forvirringsmatrisen
Deretter utvikler du et skript for å tegne inn forvirringsmatrisen for å evaluere nøyaktigheten av klassifiseringen ved hjelp av valideringsdatasettet. Forvirringsmatrisen kan også tegnes inn ved hjelp av SynapseML-verktøy, som vises i eksemplet på svindelgjenkjenning som er tilgjengelig her.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
- Forvirringsmatrise for Random Forest Classifier med maksimal dybde på 4 og 4 funksjoner
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
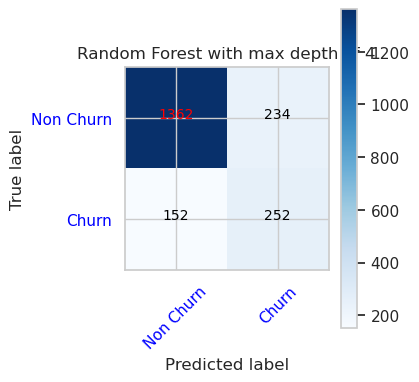
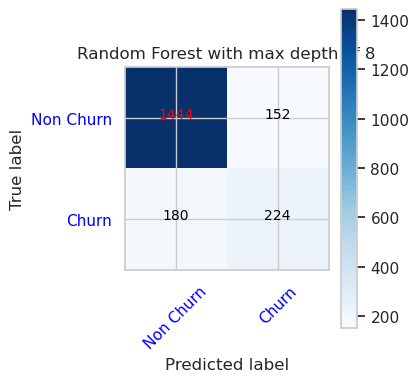
- Forvirringsmatrise for Random Forest Classifier med maksimal dybde på 8 og 6 funksjoner
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
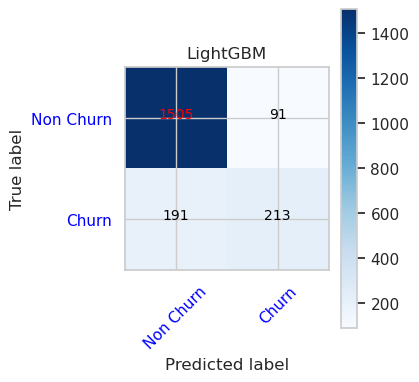
- Forvirringsmatrise for LightGBM
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()