Administrere Apache Spark-biblioteker i Microsoft Fabric
Et bibliotek er en samling forhåndsskrevne koder som utviklere kan importere for å gi funksjonalitet. Ved hjelp av biblioteker kan du spare tid og krefter ved å ikke måtte skrive kode fra grunnen av for å utføre vanlige oppgaver. Importer i stedet biblioteket og bruk funksjonene og klassene for å oppnå ønsket funksjonalitet. Microsoft Fabric tilbyr flere mekanismer for å hjelpe deg med å administrere og bruke biblioteker.
- Innebygde biblioteker: Hvert Fabric Spark runtime gir et rikt sett med populære forhåndsinstallerte biblioteker. Du finner den fullstendige innebygde biblioteklisten i Fabric Spark Runtime.
- Offentlige biblioteker: Folkebiblioteker er hentet fra repositorier som PyPI og Conda, som for øyeblikket støttes.
- Egendefinerte biblioteker: Egendefinerte biblioteker refererer til kode som du eller organisasjonen bygger. Stoffet støtter dem i formatene .whl, .jar og .tar.gz . Stoffet støtter .tar.gz bare for R-språket. Bruk .whl-formatet for python-egendefinerte biblioteker.
Sammendrag av anbefalte fremgangsmåter for bibliotekbehandling
Følgende scenarier beskriver anbefalte fremgangsmåter når du bruker biblioteker i Microsoft Fabric.
Scenario 1: Administrator angir standardbiblioteker for arbeidsområdet
Hvis du vil angi standardbiblioteker, må du være administrator for arbeidsområdet. Som administrator kan du utføre disse oppgavene:
- Opprett et nytt miljø
- Installere de nødvendige bibliotekene i miljøet
- Legg ved dette miljøet som standard for arbeidsområdet
Når notatblokker og Spark-jobbdefinisjoner er knyttet til innstillingene for arbeidsområdet, starter de økter med bibliotekene som er installert i arbeidsområdets standardmiljø.
Scenario 2: Behold bibliotekspesifikasjoner for ett eller flere kodeelementer
Hvis du har vanlige biblioteker for ulike kodeelementer og ikke krever hyppig oppdatering, kan du installere bibliotekene i et miljø og knytte det til kodeelementene .
Det vil ta litt tid å få bibliotekene i miljøer til å bli effektive når de publiserer. Det tar vanligvis 5–15 minutter, avhengig av kompleksiteten i bibliotekene. I løpet av denne prosessen vil systemet bidra til å løse potensielle konflikter og laste ned nødvendige avhengigheter.
En fordel med denne fremgangsmåten er at de installerte bibliotekene garantert er tilgjengelige når Spark-økten startes med miljøvedlagt. Det sparer arbeidet med å vedlikeholde felles biblioteker for prosjektene dine.
Det anbefales på det sterkeste for datasamlebåndscenarioer med stabiliteten.
Scenario 3: Innebygd installasjon i interaktiv kjøring
Hvis du bruker notatblokkene til å skrive kode interaktivt, kan du bruke innebygd installasjon til å legge til ekstra nye PyPI/conda-biblioteker eller validere egendefinerte biblioteker for engangsbruk. Innebygde kommandoer i Fabric lar deg ha biblioteket effektivt i gjeldende spark-økt for notatblokken. Den tillater hurtiginstallasjon, men det installerte biblioteket vedvarer ikke på tvers av ulike økter.
Siden %pip install generering av ulike avhengighetstrær fra tid til annen, noe som kan føre til bibliotekkonflikter, deaktiveres innebygde kommandoer som standard i datasamlebåndkjøringene, og ANBEFALES IKKE å brukes i datasamlebåndet.
Sammendrag av støttede bibliotektyper
| Bibliotektype | Administrasjon av miljøbibliotek | Innebygd installasjon |
|---|---|---|
| Python Public (PyPI &Conda) | Støttes | Støttes |
| Python Custom (.whl) | Støttes | Støttes |
| Offentlig R (CRAN) | Støttes ikke | Støttes |
| R-egendefinert (.tar.gz) | Støttes som egendefinert bibliotek | Støttes |
| Krukke | Støttes som egendefinert bibliotek | Støttes |
Innebygd installasjon
Innebygde kommandoer støtter administrasjon av biblioteker i hver notatblokkøkt.
Python-innebygd installasjon
Systemet starter Python-tolken på nytt for å bruke endringen av biblioteker. Alle variabler som er definert før du kjører kommandocellen, går tapt. Vi anbefaler på det sterkeste at du legger til alle kommandoene for å legge til, slette eller oppdatere Python-pakker i begynnelsen av notatblokken.
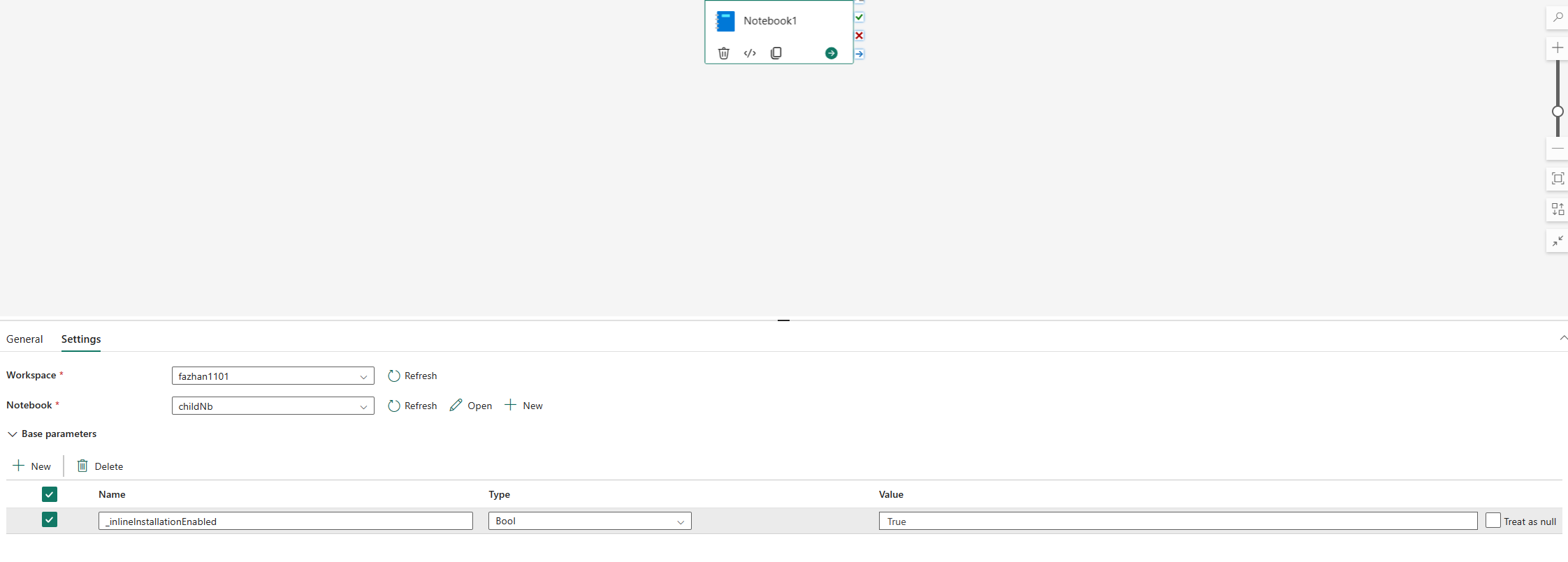
De innebygde kommandoene for administrasjon av Python-biblioteker er deaktivert i pipeline for notatblokker som kjøres som standard. Hvis du vil aktivere %pip install for datasamlebånd, legger du til «_inlineInstallationEnabled» som boolsk parameter er lik Sann i aktivitetsparameterne for notatblokken.
Merk
Det %pip install kan føre til inkonsekvente resultater fra tid til annen. Det anbefales å installere biblioteket i et miljø og bruke det i datasamlebåndet.
Innebygde kommandoer for behandling av Python-biblioteker støttes ikke i notatblokkreferansekjøringer. For å sikre riktig kjøring anbefales det å fjerne disse innebygde kommandoene fra notatblokken det refereres til.
Vi anbefaler %pip i stedet !pipfor .
!pip er en innebygd IPython-grensesnittkommando, som har følgende begrensninger:
-
!pipinstallerer bare en pakke på drivernoden, ikke eksekutornoder. - Pakker som installeres gjennom
!pip, påvirker ikke konflikter med innebygde pakker eller om pakker allerede er importert i en notatblokk.
Håndterer imidlertid %pip disse scenariene. Biblioteker som er installert gjennom %pip , er tilgjengelige på både driver- og eksekutornoder og er fremdeles effektive selv om biblioteket allerede er importert.
Tips
Kommandoen %conda install tar vanligvis lengre tid enn %pip install kommandoen for å installere nye Python-biblioteker. Den kontrollerer de fullstendige avhengighetene og løser konflikter.
Det kan være lurt å bruke %conda install for mer pålitelighet og stabilitet. Du kan bruke %pip install hvis du er sikker på at biblioteket du vil installere, ikke er i konflikt med de forhåndsinstallerte bibliotekene i kjøretidsmiljøet.
Hvis du vil ha alle tilgjengelige python-innebygde kommandoer og avklaringer, kan du se %pip-kommandoer og %conda-kommandoer.
Administrer Python-biblioteker gjennom innebygd installasjon
I dette eksemplet kan du se hvordan du bruker innebygde kommandoer til å behandle biblioteker. La oss si at du vil bruke altair, et kraftig visualiseringsbibliotek for Python, for en engangsdatautforskning. La oss si at biblioteket ikke er installert i arbeidsområdet. Følgende eksempel bruker conda-kommandoer til å illustrere trinnene.
Du kan bruke innebygde kommandoer til å aktivere altair på notatblokkøkten uten å påvirke andre økter i notatblokken eller andre elementer.
Kjør følgende kommandoer i en notatblokkkodecelle. Den første kommandoen installerer altair-biblioteket . Installer også vega_datasets, som inneholder en semantisk modell du kan bruke til å visualisere.
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda commandUtdataene i cellen angir resultatet av installasjonen.
Importer pakken og semantisk modell ved å kjøre følgende kode i en annen notatblokkcelle.
import altair as alt from vega_datasets import dataNå kan du leke deg med altair-biblioteket med øktomfang.
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
Behandle egendefinerte Python-biblioteker gjennom innebygd installasjon
Du kan laste opp de egendefinerte Python-bibliotekene til ressursmappen i notatblokken eller det vedlagte miljøet. Ressursmappene er det innebygde filsystemet som leveres av hver notatblokk og miljøer. Se notatblokkressurser for mer informasjon. Etter opplastingen kan du dra og slippe det egendefinerte biblioteket til en kodecelle, den innebygde kommandoen for å installere biblioteket genereres automatisk. Du kan også bruke følgende kommando til å installere.
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
Innebygd R-installasjon
For å administrere R-biblioteker støtter install.packages()Fabric kommandoene , remove.packages()og devtools:: . Hvis du vil ha alle tilgjengelige innebygde R-kommandoer og -avklaringer, kan du se kommandoen install.packages og remove.package.
Administrer R-biblioteker gjennom innebygd installasjon
Følg dette eksemplet for å gå gjennom trinnene for å installere et offentlig R-bibliotek.
Slik installerer du et R-feedbibliotek:
Bytt arbeidsspråket til SparkR (R) på notatblokkbåndet.
Installer cæsarbiblioteket ved å kjøre følgende kommando i en notatblokkcelle.
install.packages("caesar")Nå kan du leke deg med cæsarbiblioteket med øktomfang med en Spark-jobb.
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
Behandle Jar-biblioteker gjennom innebygd installasjon
De .jar filene støttes på notatblokkøkter med følgende kommando.
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
Kodecellen bruker Lakehouses lagringsplass som eksempel. I notatblokkutforskeren kan du kopiere den fullstendige fil-ABFS-banen og erstatte i koden.
