Opplæring: Opprette, evaluere og score en frafallsprognosemodell
Denne opplæringen presenterer et ende-til-ende-eksempel på en Synapse Data Science-arbeidsflyt i Microsoft Fabric. Scenarioet bygger en modell for å forutsi om bankkunder frafaller eller ikke. Frafallsrenten, eller attrisjonssatsen, innebærer hvor raskt bankkunder avslutter sin virksomhet med banken.
Denne opplæringen dekker disse trinnene:
- Installere egendefinerte biblioteker
- Laste inn dataene
- Forstå og behandle dataene gjennom utforskende dataanalyse, og vis bruken av Fabric Data Wrangler-funksjonen
- Bruk scikit-learn og LightGBM til å lære opp maskinlæringsmodeller, og spor eksperimenter med MLflow- og Fabric Autologging-funksjonene
- Evaluer og lagre den endelige maskinlæringsmodellen
- Vis modellytelsen med Power BI-visualiseringer
Forutsetninger
Få et Microsoft Fabric-abonnement. Eller registrer deg for en gratis Prøveversjon av Microsoft Fabric.
Logg på Microsoft Fabric.
Bruk opplevelsesbryteren nederst til venstre på hjemmesiden for å bytte til Fabric.

- Opprett om nødvendig et Microsoft Fabric lakehouse som beskrevet i Opprett et lakehouse i Microsoft Fabric.
Følg med i en notatblokk
Du kan velge ett av disse alternativene for å følge med i en notatblokk:
- Åpne og kjør den innebygde notatblokken.
- Last opp notatblokken fra GitHub.
Åpne den innebygde notatblokken
Eksemplet Kundefrafall notatblokk følger med denne opplæringen.
Hvis du vil åpne eksempelnotatblokken for denne opplæringen, følger du instruksjonene i Klargjør systemet for.
Pass på å feste et lakehouse til notatblokken før du begynner å kjøre kode.
Importere notatblokken fra GitHub
Den AIsample - Bank Customer Churn.ipynb notatblokken følger med denne opplæringen.
Hvis du vil åpne den medfølgende notatblokken for denne opplæringen, følger du instruksjonene i Klargjøre systemet for opplæringer om datavitenskap importere notatblokken til arbeidsområdet.
Hvis du heller vil kopiere og lime inn koden fra denne siden, kan du opprette en ny notatblokk.
Pass på å feste et lakehouse til notatblokken før du begynner å kjøre kode.
Trinn 1: Installere egendefinerte biblioteker
For utvikling av maskinlæringsmodeller eller ad hoc-dataanalyse, må du kanskje raskt installere et egendefinert bibliotek for Apache Spark-økten. Du har to alternativer for å installere biblioteker.
- Bruk de innebygde installasjonsfunksjonene (
%pipeller%conda) i notatblokken til å installere et bibliotek, bare i gjeldende notatblokk. - Alternativt kan du opprette et stoffmiljø, installere biblioteker fra offentlige kilder eller laste opp egendefinerte biblioteker til det, og deretter kan administratoren for arbeidsområdet legge ved miljøet som standard for arbeidsområdet. Alle bibliotekene i miljøet blir da tilgjengelige for bruk i alle notatblokker og Spark-jobbdefinisjoner i arbeidsområdet. Hvis du vil ha mer informasjon om miljøer, kan du se opprette, konfigurere og bruke et miljø i Microsoft Fabric.
For denne opplæringen kan du bruke %pip install til å installere imblearn biblioteket i notatblokken.
Notat
PySpark-kjernen starter på nytt etter at %pip install kjører. Installer de nødvendige bibliotekene før du kjører andre celler.
# Use pip to install libraries
%pip install imblearn
Trinn 2: Laste inn dataene
Datasettet i churn.csv inneholder frafallsstatusen til 10 000 kunder, sammen med 14 attributter som inkluderer:
- Kredittpoengsum
- Geografisk plassering (Tyskland, Frankrike, Spania)
- Kjønn (mann, kvinne)
- Alder
- Tenure (antall år personen var en kunde i denne banken)
- Kontosaldo
- Beregnet lønn
- Antall produkter som en kunde har kjøpt gjennom banken
- Kredittkortstatus (om en kunde har et kredittkort eller ikke)
- Aktiv medlemsstatus (om personen er en aktiv bankkunde eller ikke)
Datasettet inneholder også radnummer, kunde-ID og kundenavnkolonner. Verdier i disse kolonnene bør ikke påvirke kundens beslutning om å forlate banken.
En avslutningshendelse for kundebankkonto definerer frafall for kunden. Datasettet Exited kolonnen refererer til kundens oppgivelse. Siden vi har lite kontekst om disse attributtene, trenger vi ikke bakgrunnsinformasjon om datasettet. Vi ønsker å forstå hvordan disse attributtene bidrar til statusen Exited.
Av disse 10 000 kundene forlot bare 2037 kunder (omtrent 20%) banken. På grunn av klasseubalanseforholdet anbefaler vi generering av syntetiske data. Forvirringsmatrisenøyaktighet har kanskje ikke relevans for ubalansert klassifisering. Vi vil kanskje måle nøyaktigheten ved hjelp av området under Precision-Recall kurve (AUPRC).
- Denne tabellen viser en forhåndsvisning av
churn.csvdata:
| Kunde-ID | Etternavn | CreditScore | Geografi | Kjønn | Alder | Tid | Balanse | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | Avsluttet |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Hargrave | 619 | Frankrike | Kvinnelig | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Ås | 608 | Spania | Kvinnelig | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
Last ned datasettet og last opp til lakehouse
Definer disse parameterne, slik at du kan bruke denne notatblokken med forskjellige datasett:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Denne koden laster ned en offentlig tilgjengelig versjon av datasettet, og lagrer deretter datasettet i et Fabric Lakehouse:
Viktig
Legg til et lakehouse- i notatblokken før du kjører den. Hvis du ikke gjør dette, vil det føre til en feil.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Start innspillingen av tiden det tar å kjøre notatblokken:
# Record the notebook running time
import time
ts = time.time()
Les rådata fra lakehouse
Denne koden leser rådata fra Files-delen av lakehouse, og legger til flere kolonner for ulike datodeler. Oppretting av den partisjonerte deltatabellen bruker denne informasjonen.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Opprette en pandas DataFrame fra datasettet
Denne koden konverterer Spark DataFrame til en pandas DataFrame, for enklere behandling og visualisering:
df = df.toPandas()
Trinn 3: Utfør utforskende dataanalyse
Vis rådata
Utforsk rådataene med display, beregn grunnleggende statistikk og vis diagramvisninger. Du må først importere de nødvendige bibliotekene for datavisualisering – for eksempel sjøfødte. Seaborn er et python-datavisualiseringsbibliotek, og gir et grensesnitt på høyt nivå for å bygge visualobjekter på datarammer og matriser.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Bruk Data Wrangler til å utføre første datarengjøring
Start Data Wrangler direkte fra notatblokken for å utforske og transformere pandas-datarammer. Velg rullegardinlisten Data Wrangler fra den vannrette verktøylinjen for å bla gjennom de aktiverte pandas DataFrames som er tilgjengelige for redigering. Velg datarammen du vil åpne i Data Wrangler.
Notat
Data-Wrangler kan ikke åpnes mens notatblokkkjernen er opptatt. Cellekjøringen må fullføres før du starter Data Wrangler. Finn ut mer om Data Wrangler.

Når Data Wrangler starter, genereres en beskrivende oversikt over datapanelet, som vist i følgende bilder. Oversikten inneholder informasjon om dimensjonen til DataFrame, eventuelle manglende verdier osv. Du kan bruke Data Wrangler til å generere skriptet for å slippe radene med manglende verdier, de dupliserte radene og kolonnene med bestemte navn. Deretter kan du kopiere skriptet til en celle. Den neste cellen viser det kopierte skriptet.


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Bestemme attributter
Denne koden bestemmer de kategoriske, numeriske attributtene og målattributtene:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Vis sammendraget med fem tall
Bruk bokstegninger til å vise sammendraget med fem tall
- minimumspoengsummen
- første kvartil
- Median
- tredje kvartil
- maksimal poengsum
for de numeriske attributtene.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
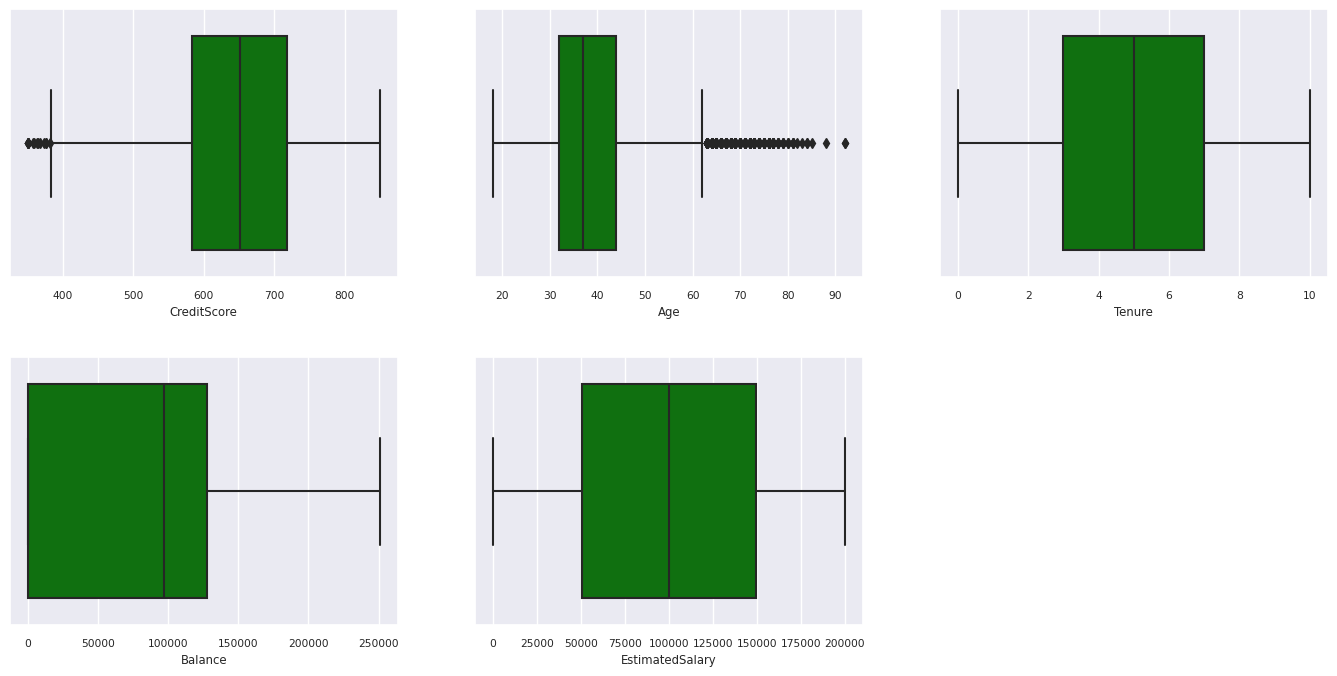
Vis distribusjonen av avsluttede og ikke-utgåtte kunder
Vis fordelingen av avsluttede kontra kunder som ikke er avsluttet, på tvers av de kategoriske attributtene:
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
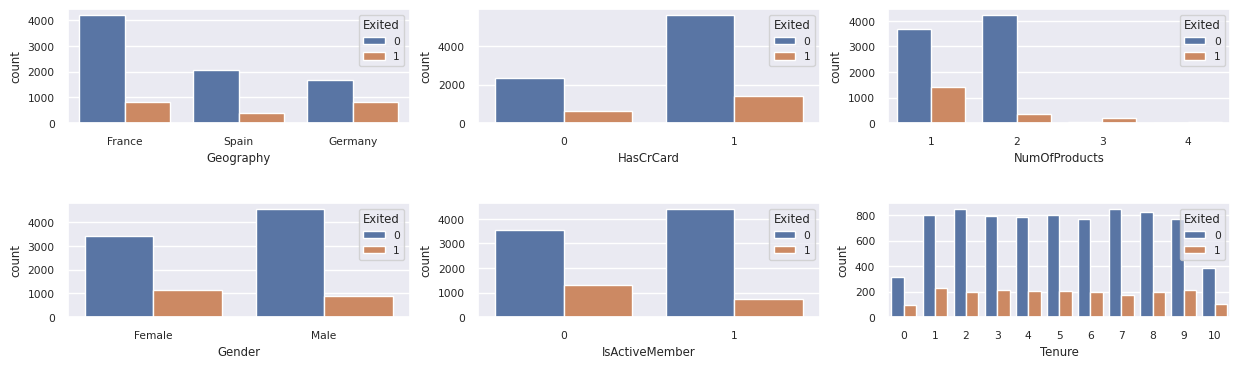
Vis fordelingen av numeriske attributter
Bruk et histogram til å vise hyppighetsfordelingen av numeriske attributter:
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
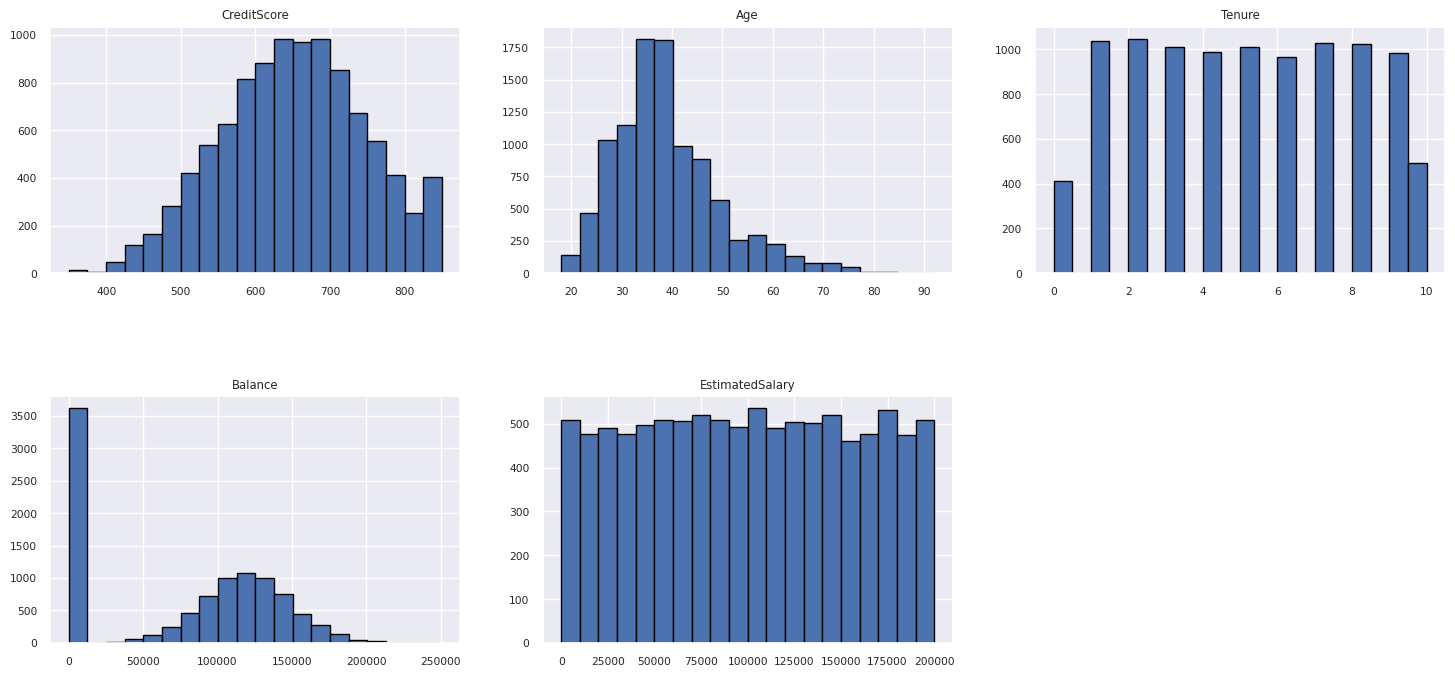
Utfør funksjonsteknikk
Denne funksjonsteknikken genererer nye attributter basert på gjeldende attributter:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Bruk Data Wrangler til å utføre en varm koding
Med de samme trinnene for å starte Data Wrangler, som beskrevet tidligere, bruker du Data Wrangler til å utføre en varm koding. Denne cellen viser det kopierte genererte skriptet for en-hot koding:


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Opprette en deltatabell for å generere Power BI-rapporten
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Sammendrag av observasjoner fra den utforskende dataanalysen
- De fleste av kundene er fra Frankrike. Spania har den laveste churn rate, sammenlignet med Frankrike og Tyskland.
- De fleste kunder har kredittkort
- Noen kunder er begge over 60 år og har kredittscore under 400. De kan imidlertid ikke betraktes som ytterpunkter
- Svært få kunder har mer enn to bankprodukter
- Inaktive kunder har en høyere frafallsrate
- Kjønns- og ansettelsesår har liten innvirkning på kundens beslutning om å stenge en bankkonto
Trinn 4: Utfør modellopplæring og -sporing
Når dataene er på plass, kan du nå definere modellen. Bruk tilfeldige skogs- og LightGBM-modeller i denne notatblokken.
Bruk scikit-learn- og LightGBM-bibliotekene til å implementere modellene, med noen få linjer med kode. I tillegg kan du bruke MLfLow og Fabric Autologging til å spore eksperimentene.
Denne kodeeksemplet laster deltatabellen fra lakehouse. Du kan bruke andre deltabord som selv bruker lakehouse som kilde.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Generer et eksperiment for sporing og logging av modellene ved hjelp av MLflow
Denne delen viser hvordan du genererer et eksperiment, og den angir modell- og opplæringsparameterne og måledataene for poengsum. I tillegg viser den hvordan du lærer opp modellene, logger dem og lagrer de opplærte modellene for senere bruk.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
Automatisk tillogging registrerer automatisk både inndataparameterverdiene og utdatadata for en maskinlæringsmodell, ettersom denne modellen er opplært. Denne informasjonen logges deretter på arbeidsområdet, der MLflow-API-ene eller det tilsvarende eksperimentet i arbeidsområdet kan få tilgang til og visualisere det.
Når du er ferdig, ligner eksperimentet på dette bildet:

Alle eksperimentene med de respektive navnene logges, og du kan spore parameterne og ytelsesmåledataene. Hvis du vil ha mer informasjon om autologging, kan du se Autologging i Microsoft Fabric.
Angi spesifikasjoner for eksperiment og autologging
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
Importer scikit-learn og LightGBM
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Klargjøre opplærings- og testdatasett
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
Bruk SMOTE på opplæringsdataene
Ubalansert klassifisering har et problem, fordi den har for få eksempler på minoritetsklassen for en modell for effektivt å lære beslutningsgrensen. For å håndtere dette er Synthetic Minority Oversampling Technique (SMOTE) den mest brukte teknikken for å syntetisere nye prøver for minoritetsklassen. Få tilgang til SMOTE med imblearn biblioteket du installerte i trinn 1.
Bruk SMOTE bare på opplæringsdatasettet. Du må la testdatasettet stå i den opprinnelige ubalanserte fordelingen for å få en gyldig tilnærming til modellytelsen på de opprinnelige dataene. Dette eksperimentet representerer situasjonen i produksjonen.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Hvis du vil ha mer informasjon, kan du se SMOTE og Fra tilfeldig over-sampling til SMOTE og ADASYN. Det ubalanserte nettstedet er vert for disse ressursene.
Kalibrer modellen
Bruk Random Forest til å lære opp modellen, med en maksimal dybde på fire, og med fire funksjoner:
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Bruk Random Forest til å lære opp modellen, med en maksimal dybde på åtte, og med seks funksjoner:
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Kalibrer modellen med LightGBM:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Vise eksperimentartefakten for å spore modellytelse
Eksperimentkjøringene lagres automatisk i eksperimentartefakten. Du finner artefakten i arbeidsområdet. Et artefaktnavn er basert på navnet som brukes til å angi eksperimentet. Alle de opplærte modellene, kjøringene, ytelsesmåledataene og modellparameterne logges på eksperimentsiden.
Slik viser du eksperimentene dine:
- Velg arbeidsområdet i venstre panel.
- Finn og velg eksperimentnavnet, i dette tilfellet, eksempel-bank-churn-eksperiment.
Trinn 5: Evaluere og lagre den endelige maskinlæringsmodellen
Åpne det lagrede eksperimentet fra arbeidsområdet for å velge og lagre den beste modellen:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
Vurder ytelsen til de lagrede modellene på testdatasettet
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
Vis sanne/falske positiver/negativer ved hjelp av en forvirringsmatrise
Hvis du vil evaluere nøyaktigheten til klassifiseringen, bygger du et skript som tegner inn forvirringsmatrisen. Du kan også tegne inn en forvirringsmatrise ved hjelp av SynapseML-verktøy, som vist i eksempel på svindelregistrering.
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
Opprett en forvirringsmatrise for den tilfeldige skogklassifiseren, med en maksimal dybde på fire, med fire funksjoner:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
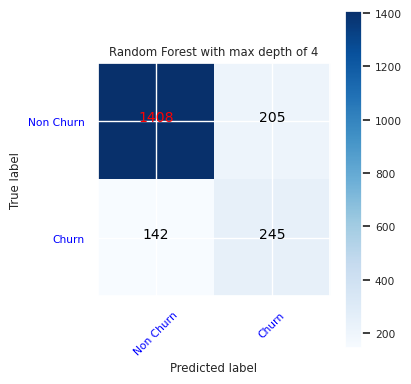
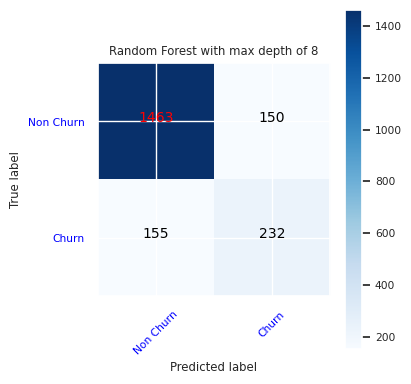
Opprett en forvirringsmatrise for den tilfeldige skogklassifiseren med maksimal dybde på åtte, med seks funksjoner:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
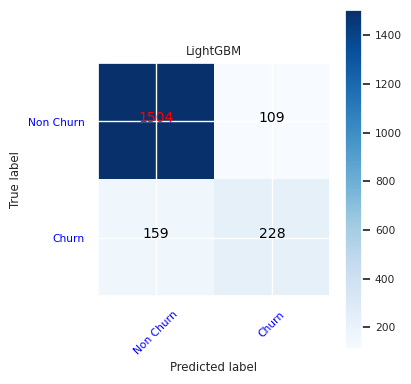
Opprett en forvirringsmatrise for LightGBM:
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Lagre resultater for Power BI
Lagre deltarammen i lakehouse for å flytte prognoseresultatene for modellen til en Power BI-visualisering.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Trinn 6: Få tilgang til visualiseringer i Power BI
Få tilgang til den lagrede tabellen i Power BI:
- Velg OneLaketil venstre.
- Velg lakehouse som du har lagt til i denne notatblokken.
- Velg Åpneunder Åpne dette Lakehouse- .
- Velg ny semantisk modellpå båndet. Velg
df_pred_results, og velg deretter Bekreft for å opprette en ny semantisk Power BI-modell som er koblet til prognosene. - Åpne ny semantisk modell. Du finner den i OneLake.
- Velg Opprett ny rapport under fil fra verktøyene øverst på semantiske modeller-siden for å åpne redigeringssiden for Power BI-rapporten.
Skjermbildet nedenfor viser noen eksempelvisualiseringer. Datapanelet viser deltatabellene og kolonnene du vil velge fra en tabell. Når du har valgt riktig kategoriakse (x) og verdiakse (y), kan du velge filtre og funksjoner – for eksempel sum eller gjennomsnitt for tabellkolonnen.
Notat
I dette skjermbildet beskriver det illustrerte eksemplet analysen av de lagrede prognoseresultatene i Power BI:

For et reelt brukstilfelle for kunder kan brukeren imidlertid trenge et grundigere sett med krav til visualiseringene for å opprette, basert på fagekspertise og hva firmaet og forretningsanalyseteamet og firmaet har standardisert som måledata.
Power BI-rapporten viser at kunder som bruker mer enn to av bankproduktene, har en høyere frafallsrate. Men få kunder hadde mer enn to produkter. (Se tegnefeltet nederst til venstre.) Banken bør samle inn mer data, men bør også undersøke andre funksjoner som korrelerer med flere produkter.
Bankkunder i Tyskland har en høyere frafallsrate sammenlignet med kunder i Frankrike og Spania. (Se tegnetegningen nederst til høyre). Basert på rapportresultatene kan en undersøkelse av faktorene som oppfordret kundene til å forlate, hjelpe.
Det finnes flere middelaldrende kunder (mellom 25 og 45). Kunder mellom 45 og 60 har en tendens til å avslutte flere.
Til slutt vil kunder med lavere kredittscore mest sannsynlig forlate banken for andre finansinstitusjoner. Banken bør utforske måter å oppmuntre kunder med lavere kredittscore og kontosaldoer til å holde seg hos banken.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")