Maskinlæringseksperimenter i Microsoft Fabric
En maskinlæring eksperimentere er den primære enheten i organisasjonen og kontroll for alle relaterte maskinlæringskjøringer. En kjøre tilsvarer en enkelt kjøring av modellkode. I MLflow-er sporing basert på eksperimenter og kjøringer.
Maskinlæringseksperimenter gjør det mulig for dataforskere å logge parametere, kodeversjoner, måledata og utdatafiler når de kjører maskinlæringskoden. Eksperimenter lar deg også visualisere, søke etter og sammenligne kjøringer, samt laste ned kjøre filer og metadata for analyse i andre verktøy.
I denne artikkelen lærer du mer om hvordan dataforskere kan samhandle med og bruke maskinlæringseksperimenter til å organisere utviklingsprosessen og spore flere kjøringer.
Forutsetninger
- Et Power BI Premium-abonnement. Hvis du ikke har en, kan du se Slik kjøper du Power BI Premium-.
- Et Power BI-arbeidsområde med tilordnet Premium-kapasitet.
Opprette et eksperiment
Du kan opprette et maskinlæringseksperiment direkte fra stoffbrukergrensesnittet eller ved å skrive kode som bruker MLflow-API-en.
Opprette et eksperiment ved hjelp av brukergrensesnittet
Slik oppretter du et maskinlæringseksperiment fra brukergrensesnittet:
- Opprett et nytt arbeidsområde, eller velg et eksisterende arbeidsområde.
- Du kan opprette et nytt element via arbeidsområdet eller ved hjelp av Opprett.
- Arbeidsområde:
- Velg arbeidsområdet.
- Velg Nytt element.
- Velg Eksperimenter under Analyser og lær opp data.
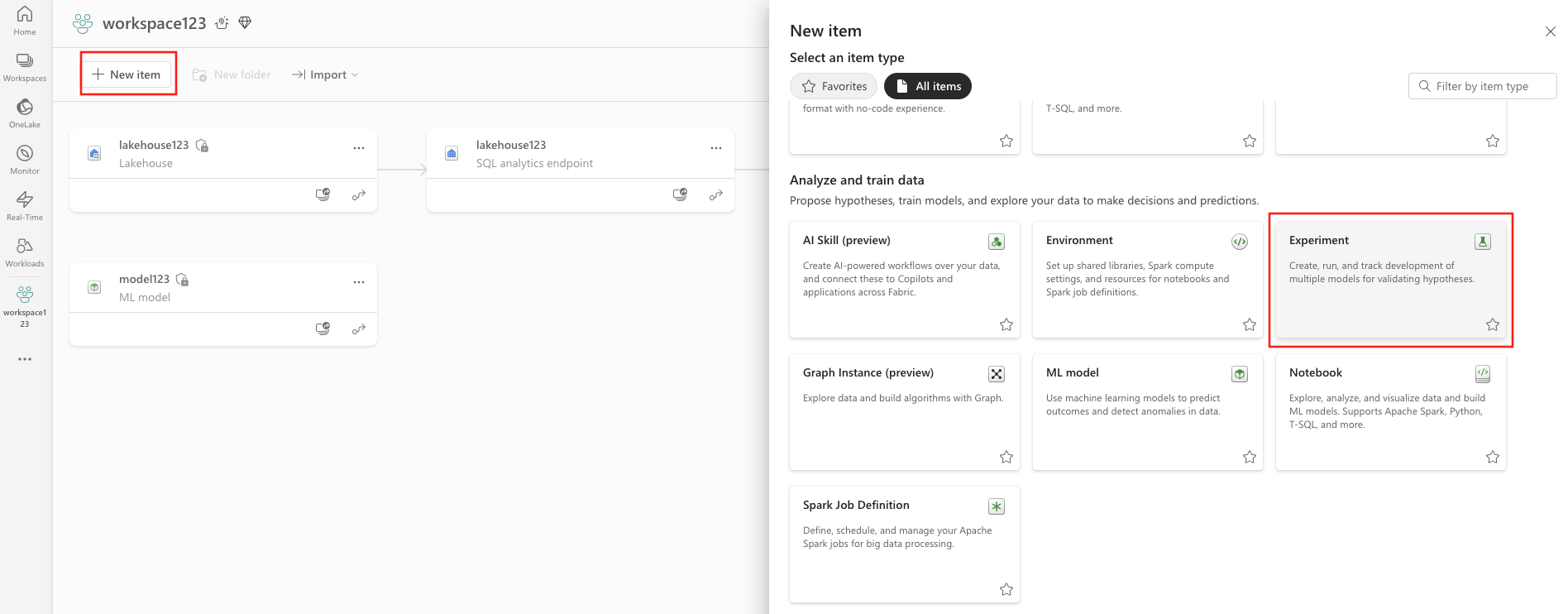
- Opprett-knapp:
- Velg Opprett, som du finner i ... fra den loddrette menyen.
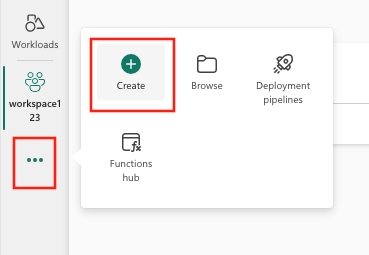
- Velg Eksperimenter under Data Science.
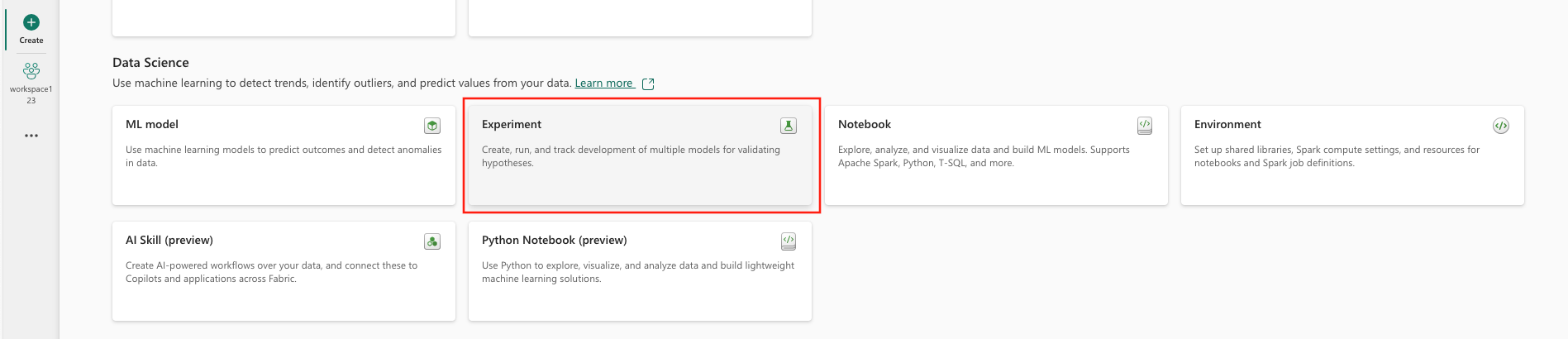
- Velg Opprett, som du finner i ... fra den loddrette menyen.
- Arbeidsområde:
- Angi et eksperimentnavn, og velg Opprett. Denne handlingen oppretter et tomt eksperiment i arbeidsområdet.



Når du har opprettet eksperimentet, kan du begynne å legge til kjøringer for å spore kjøremetrikk og parametere.
Opprette et eksperiment ved hjelp av API-en for MLflow
Du kan også opprette et maskinlæringseksperiment direkte fra redigeringsopplevelsen ved hjelp av mlflow.create_experiment() eller mlflow.set_experiment() API-er. I følgende kode erstatter du <EXPERIMENT_NAME> med eksperimentets navn.
import mlflow
# This will create a new experiment with the provided name.
mlflow.create_experiment("<EXPERIMENT_NAME>")
# This will set the given experiment as the active experiment.
# If an experiment with this name does not exist, a new experiment with this name is created.
mlflow.set_experiment("<EXPERIMENT_NAME>")
Administrere kjøringer i et eksperiment
Et maskinlæringseksperiment inneholder en samling kjøringer for forenklet sporing og sammenligning. I et eksperiment kan en dataforsker navigere på tvers av ulike kjøringer og utforske de underliggende parameterne og måledataene. Dataforskere kan også sammenligne kjøringer i et maskinlæringseksperiment for å identifisere hvilket delsett av parametere som gir en ønsket modellytelse.
Spor kjøringer
En maskinlæringskjøring tilsvarer én kjøring av modellkode.

Hver kjøring inneholder følgende informasjon:
- Kilde: Navnet på notatblokken som opprettet kjøringen.
- registrert versjon: Angir om kjøringen ble lagret som en maskinlæringsmodell.
- Startdato: Starttidspunkt for kjøringen.
- Status: Fremdrift for kjøringen.
- Hyperparametere: Hyperparametere lagret som nøkkelverdipar. Både nøkler og verdier er strenger.
- måledata: Kjør måledata som er lagret som nøkkelverdipar. Verdien er numerisk.
- Utdatafiler: Utdatafiler i alle formater. Du kan for eksempel ta opp bilder, miljø, modeller og datafiler.
- Merker: Metadata som nøkkelverdipar som skal kjøres.
Vis nylige kjøringer
Du kan også vise nylige kjøringer for et eksperiment ved å velge Kjør liste. Med denne visningen kan du holde oversikt over nylig aktivitet, raskt hoppe til det relaterte Spark-programmet og bruke filtre basert på kjørestatusen.

Sammenligne og filtrere kjøringer
Hvis du vil sammenligne og evaluere kvaliteten på maskinlæringskjøringene, kan du sammenligne parametere, måledata og metadata mellom valgte kjøringer i et eksperiment.
Bruke merker på kjøringer
MLflow-merking for eksperimentkjøringer gjør det mulig for brukere å legge til egendefinerte metadata i form av nøkkelverdipar i kjøringene. Disse kodene bidrar til å kategorisere, filtrere og søke etter kjøringer basert på bestemte attributter, noe som gjør det enklere å administrere og analysere eksperimenter i MLflow-plattformen. Brukere kan bruke koder til å merke kjøringer med informasjon som modelltyper, parametere eller relevante identifikatorer, noe som forbedrer den generelle organisasjonen og sporbarheten til eksperimenter.
Denne kodesnutten starter en MLflow-kjøring, logger noen parametere og måledata, og legger til koder for å kategorisere og gi ekstra kontekst for kjøringen.
import mlflow
import mlflow.sklearn
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.datasets import fetch_california_housing
# Autologging
mlflow.autolog()
# Load the California housing dataset
data = fetch_california_housing(as_frame=True)
X = data.data
y = data.target
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Start an MLflow run
with mlflow.start_run() as run:
# Train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Predict and evaluate
y_pred = model.predict(X_test)
# Add tags
mlflow.set_tag("model_type", "Linear Regression")
mlflow.set_tag("dataset", "California Housing")
mlflow.set_tag("developer", "Bob")
Når kodene er brukt, kan du deretter vise resultatene direkte fra det innebygde MLflow-kontrollprogrammet eller fra siden for kjøredetaljer.

Advarsel
Advarsel: Begrensninger for bruk av merker på MLflow Experiment Runs i Fabric
- koder som ikke er tomme: Kodenavn eller verdier kan ikke være tomme. Hvis du prøver å bruke en kode med et tomt navn eller en tom verdi, vil operasjonen mislykkes.
- Merkenavn: Kodenavn kan inneholde opptil 250 tegn.
- kodeverdier: Kodeverdier kan inneholde opptil 5000 tegn.
-
Begrensede kodenavn: Kodenavn som begynner med visse prefikser, støttes ikke. Kodenavn som begynner med
synapseml,mlflowellertrident, er begrenset og godtas ikke.
Sammenligne kjøringer visuelt
Du kan visuelt sammenligne og filtrere kjøringer i et eksisterende eksperiment. Med visualobjektsammenligning kan du enkelt navigere mellom flere kjøringer og sortere på tvers av dem.

Slik sammenligner du kjøringer:
- Velg et eksisterende maskinlæringseksperiment som inneholder flere kjøringer.
- Velg Vis-fanen, og gå deretter til Kjør-listen visning. Alternativt kan du velge alternativet for å Vis kjøreliste direkte fra Kjør detaljer visning.
- Tilpass kolonnene i tabellen ved å utvide Tilpass kolonner-ruten. Her kan du velge egenskaper, måledata, koder og hyperparametere som du vil se.
- Utvid Filtrer-ruten for å begrense resultatene basert på bestemte valgte vilkår.
- Velg flere kjøringer for å sammenligne resultatene i sammenligningsruten for måledata. Fra denne ruten kan du tilpasse diagrammene ved å endre diagramtittelen, visualiseringstypen, X-aksen, Y-aksen med mer.
Sammenligne kjøringer ved hjelp av API-en for MLflow
Dataforskere kan også bruke MLflow til å spørre og søke blant kjøringer i et eksperiment. Du kan utforske flere MLflow-API-er for søk, filtrering og sammenligning av kjøringer ved å gå til MLflow-dokumentasjon.
Få alle kjøringer
Du kan bruke MLflow-søke-API-en mlflow.search_runs() for å få alle kjøringer i et eksperiment ved å erstatte <EXPERIMENT_NAME> med eksperimentnavnet eller <EXPERIMENT_ID> med eksperiment-ID-en i følgende kode:
import mlflow
# Get runs by experiment name:
mlflow.search_runs(experiment_names=["<EXPERIMENT_NAME>"])
# Get runs by experiment ID:
mlflow.search_runs(experiment_ids=["<EXPERIMENT_ID>"])
Tips
Du kan søke på tvers av flere eksperimenter ved å gi en liste over eksperiment-ID-er til experiment_ids-parameteren. På samme måte vil det å gi en liste over eksperimentnavn til experiment_names-parameteren tillate MLflow å søke på tvers av flere eksperimenter. Dette kan være nyttig hvis du vil sammenligne på tvers av kjøringer i ulike eksperimenter.
Bestillings- og grensekjøringer
Bruk max_results-parameteren fra search_runs til å begrense antall returnerte kjøringer. Med order_by-parameteren kan du liste opp kolonnene du vil ordne etter, og kan inneholde en valgfri DESC- eller ASC-verdi. Eksemplet nedenfor returnerer for eksempel den siste kjøringen av et eksperiment.
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["start_time DESC"])
Sammenligne kjøringer i en Fabric-notatblokk
Du kan bruke kontrollprogrammet for MLFlow-redigering i Fabric-notatblokker til å spore MLflow-kjøringer som genereres i hver notatblokkcelle. Kontrollprogrammet lar deg spore kjøringer, tilknyttede måledata, parametere og egenskaper helt ned til det individuelle cellenivået.
Hvis du vil ha en visuell sammenligning, kan du også bytte til Kjør sammenligning visning. Denne visningen presenterer dataene grafisk, noe som bidrar til rask identifisering av mønstre eller avvik på tvers av ulike kjøringer.

Lagre kjøring som maskinlæringsmodell
Når en kjøring gir ønsket resultat, kan du lagre kjøringen som en modell for forbedret modellsporing og for modelldistribusjon ved å velge Lagre som en ML-modell.

Overvåk ML-eksperimenter (forhåndsversjon)
ML-eksperimenter integreres direkte i Monitor. Denne funksjonaliteten er utformet for å gi mer innsikt i Spark-programmene og ML-eksperimentene de genererer, noe som gjør det enklere å administrere og feilsøke disse prosessene.
Spor kjøringer fra skjermen
Brukere kan spore eksperimentkjøringer direkte fra skjermen, noe som gir en enhetlig visning av alle aktivitetene deres. Denne integreringen omfatter filtreringsalternativer, slik at brukere kan fokusere på eksperimenter eller kjøringer som er opprettet i løpet av de siste 30 dagene eller andre angitte perioder.

Spor relaterte ML Experiment-kjøringer fra Spark-programmet
ML Experiment integreres direkte i Monitor, der du kan velge et bestemt Spark-program og få tilgang til øyeblikksbilder av elementer. Her finner du en liste over alle eksperimentene og kjøringene som genereres av programmet.