Hurtigstart: Opprett din første dataflyt for å hente og transformere data
Dataflyter er en selvbetjent, skybasert dataforberedelsesteknologi. I denne artikkelen oppretter du den første dataflyten, henter data for dataflyten, transformerer dataene og publiserer dataflyten.
Forutsetning
Følgende forutsetninger kreves før du starter:
- En Microsoft Fabric-leierkonto med et aktivt abonnement. Opprett en gratis konto.
- Kontroller at du har et Microsoft Fabric-aktivert arbeidsområde: Opprett et arbeidsområde.
Opprette en dataflyt
I denne delen oppretter du den første dataflyten.
Bytt til datafabrikkopplevelsen .
Gå til Microsoft Fabric-arbeidsområdet.
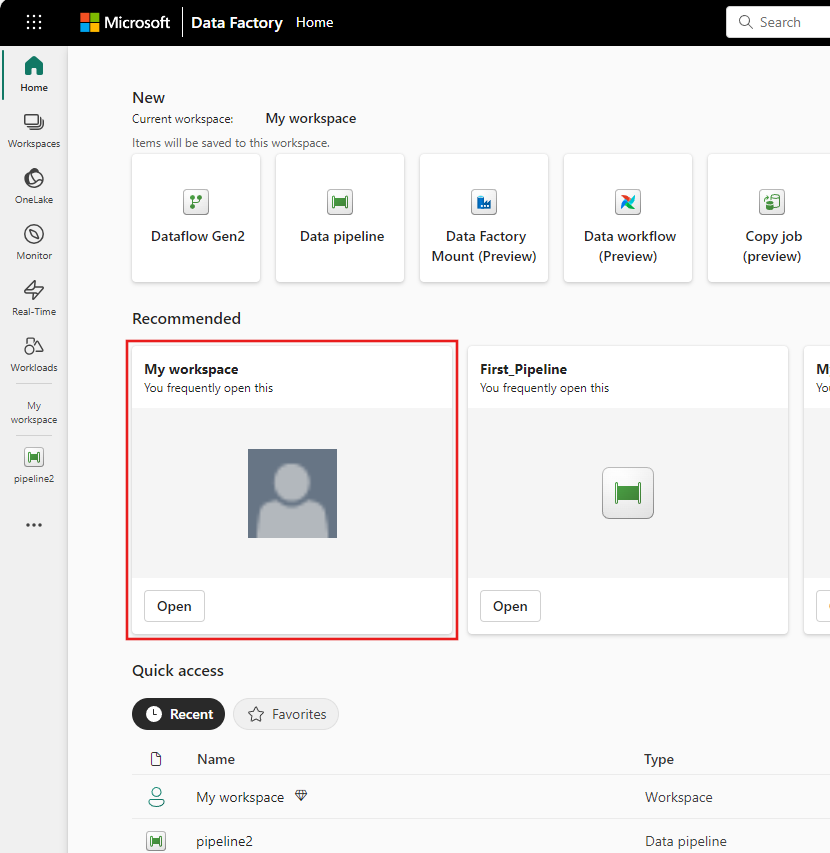
Velg Ny, og velg deretter Dataflyt gen2.
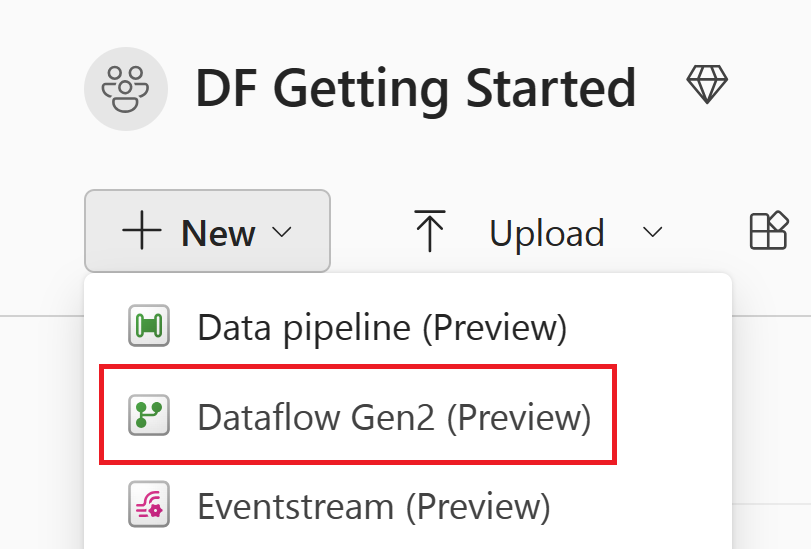

Hent data
La oss få noen data! I dette eksemplet får du data fra en OData-tjeneste. Bruk følgende fremgangsmåte for å hente data i dataflyten.
Velg Hent data i redigeringsprogrammet for dataflyt, og velg deretter Mer.
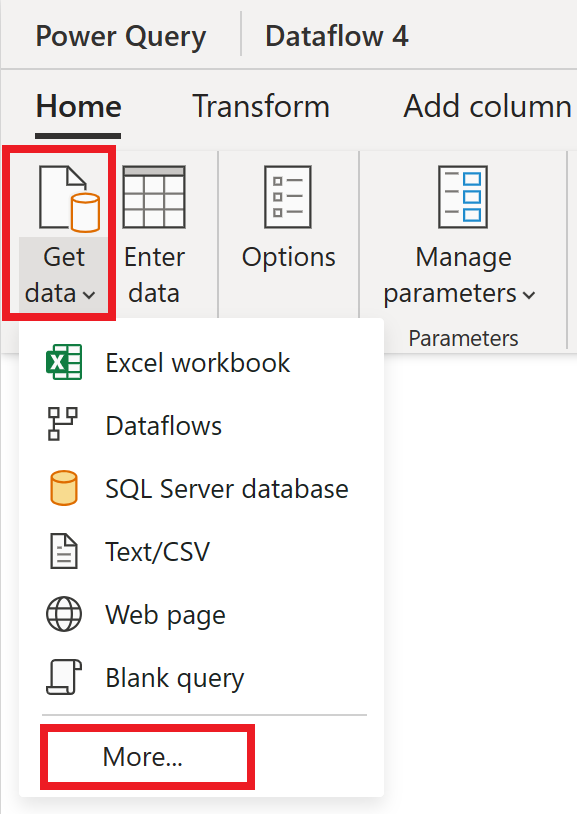
Velg Vis mer i Velg datakilde.
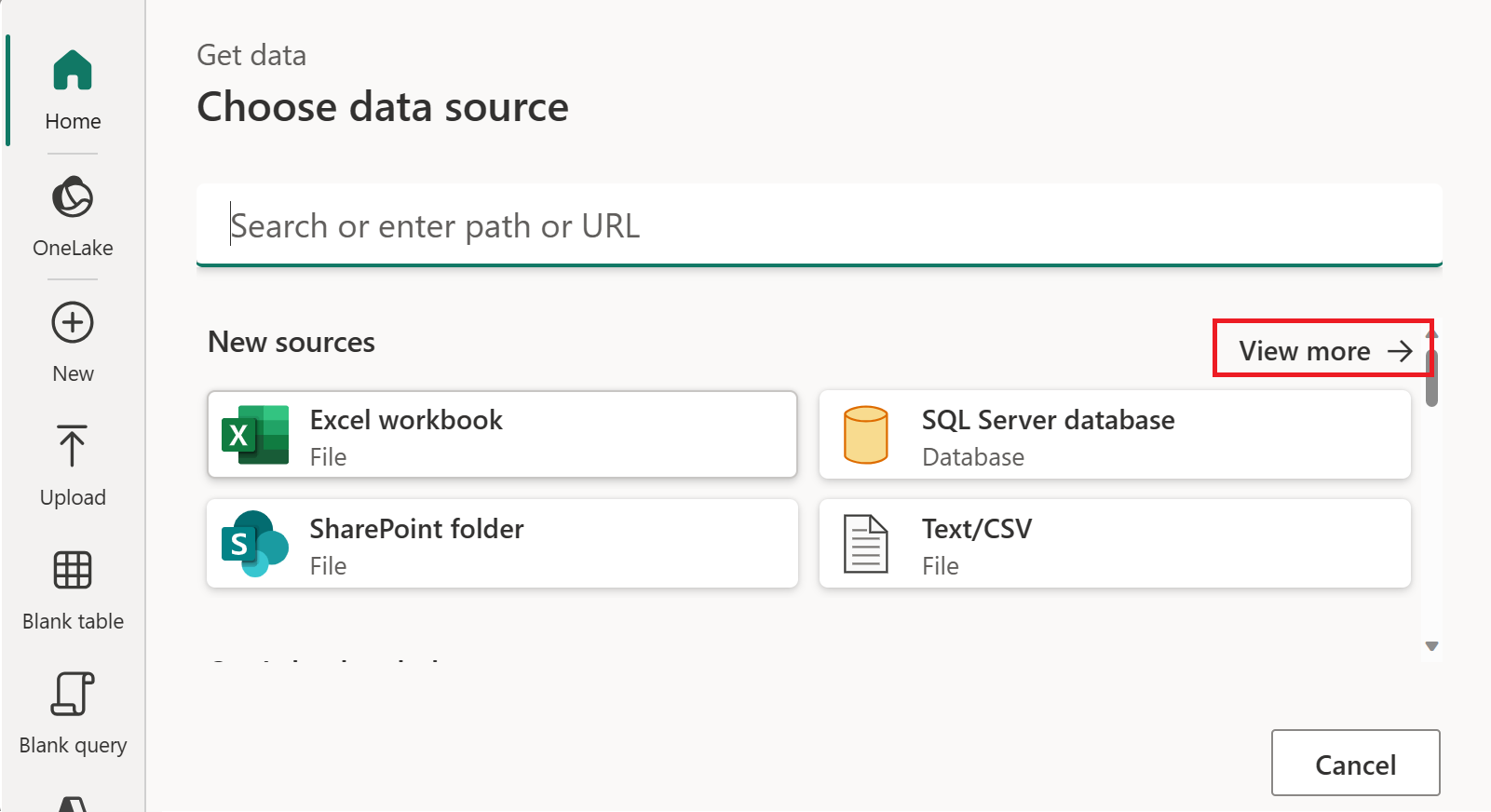
Velg som datakilde i Ny kilde.

Skriv inn URL-adressen
https://services.odata.org/v4/northwind/northwind.svc/, og velg deretter Neste.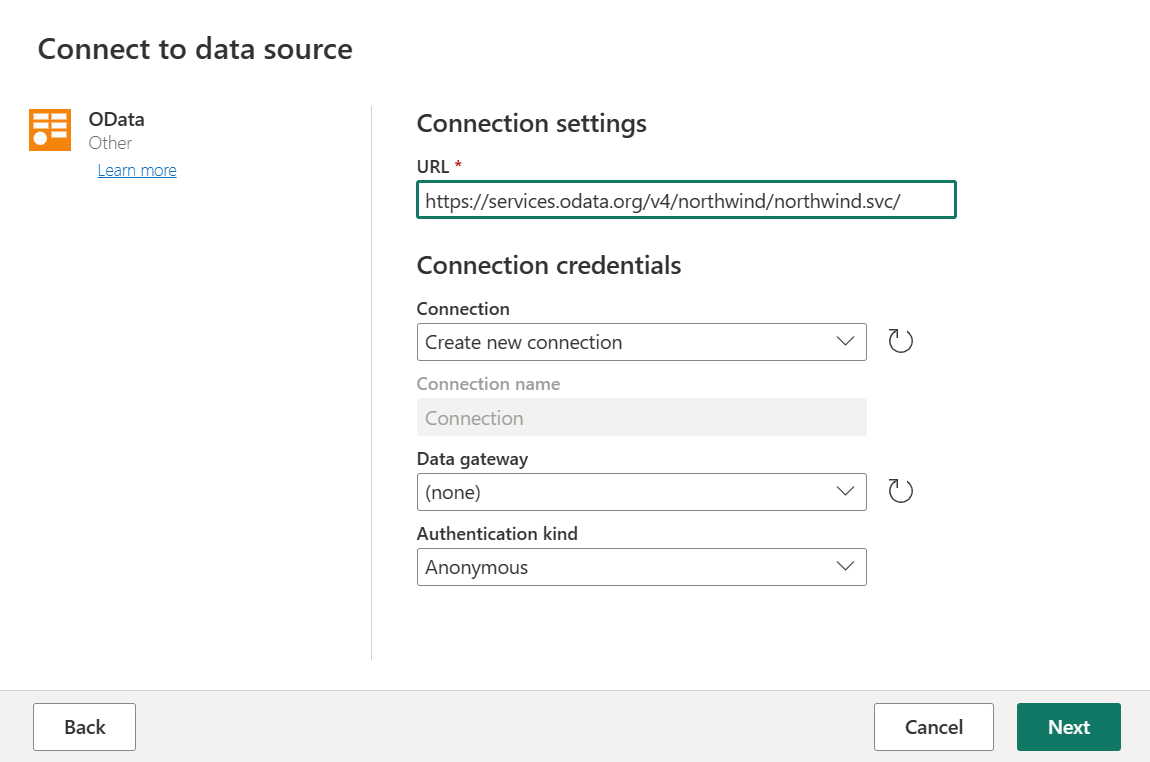
Velg ordre - og kundetabellene , og velg deretter Opprett.
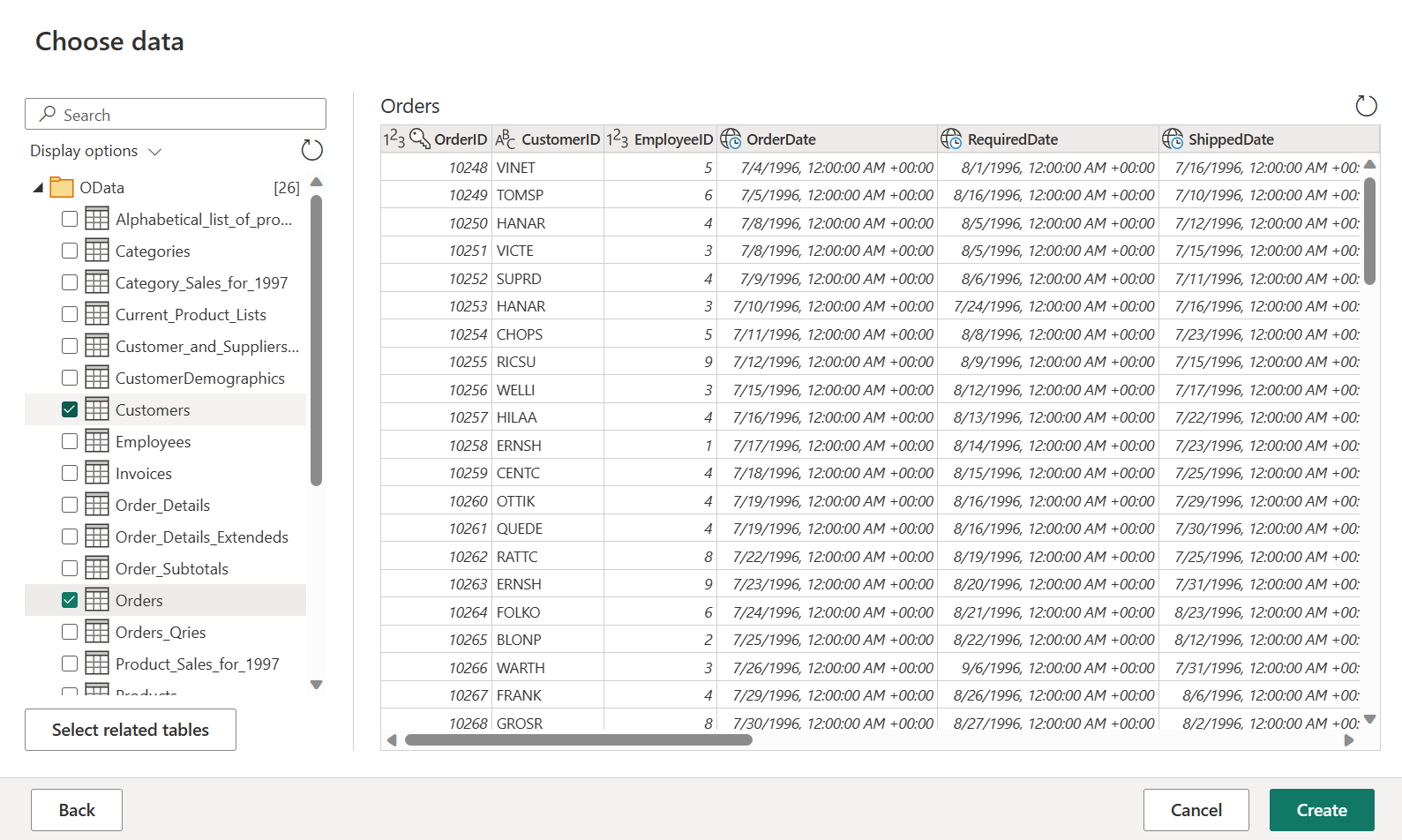



Du kan lære mer om hent dataopplevelsen og funksjonaliteten ved å få oversikt over data.
Bruke transformasjoner og publisere
Du har lastet inn dataene i den første dataflyten nå. Gratulerer! Nå er det på tide å bruke et par transformasjoner for å få disse dataene inn i ønsket figur.
Du gjør denne oppgaven fra redigeringsprogrammet for Power Query. Du finner en detaljert oversikt over power query-redigeringsprogrammet i Brukergrensesnittet i Power Query.
Følg disse trinnene for å bruke transformasjoner og publisere:
Kontroller at dataprofileringsverktøyene er aktivert ved å navigere til .
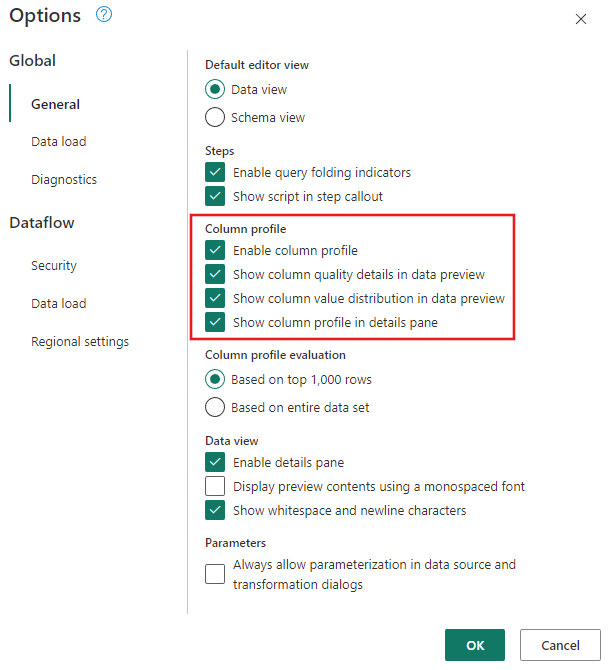
Kontroller også at du aktiverer diagramvisning ved hjelp av alternativene under fanen Vis på båndet i redigeringsprogrammet for Power Query, eller ved å velge diagramvisningsikonet nederst til høyre i Power Query-vinduet.
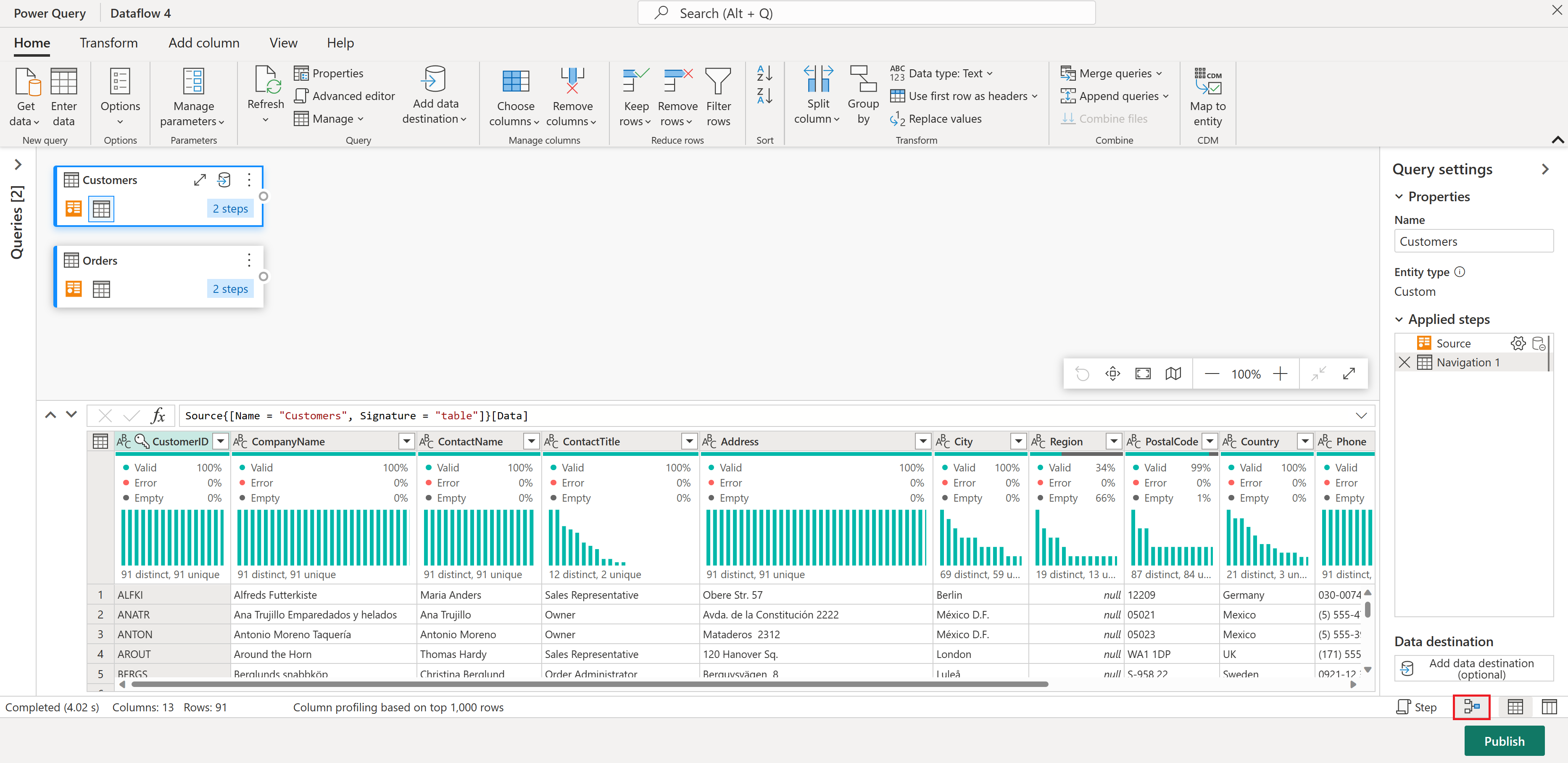
I Ordrer-tabellen beregner du det totale antallet ordrer per kunde. Hvis du vil oppnå dette målet, velger du CustomerID-kolonnen i forhåndsvisningen av data, og deretter velger du Grupper etter under Transformer-fanen på båndet.
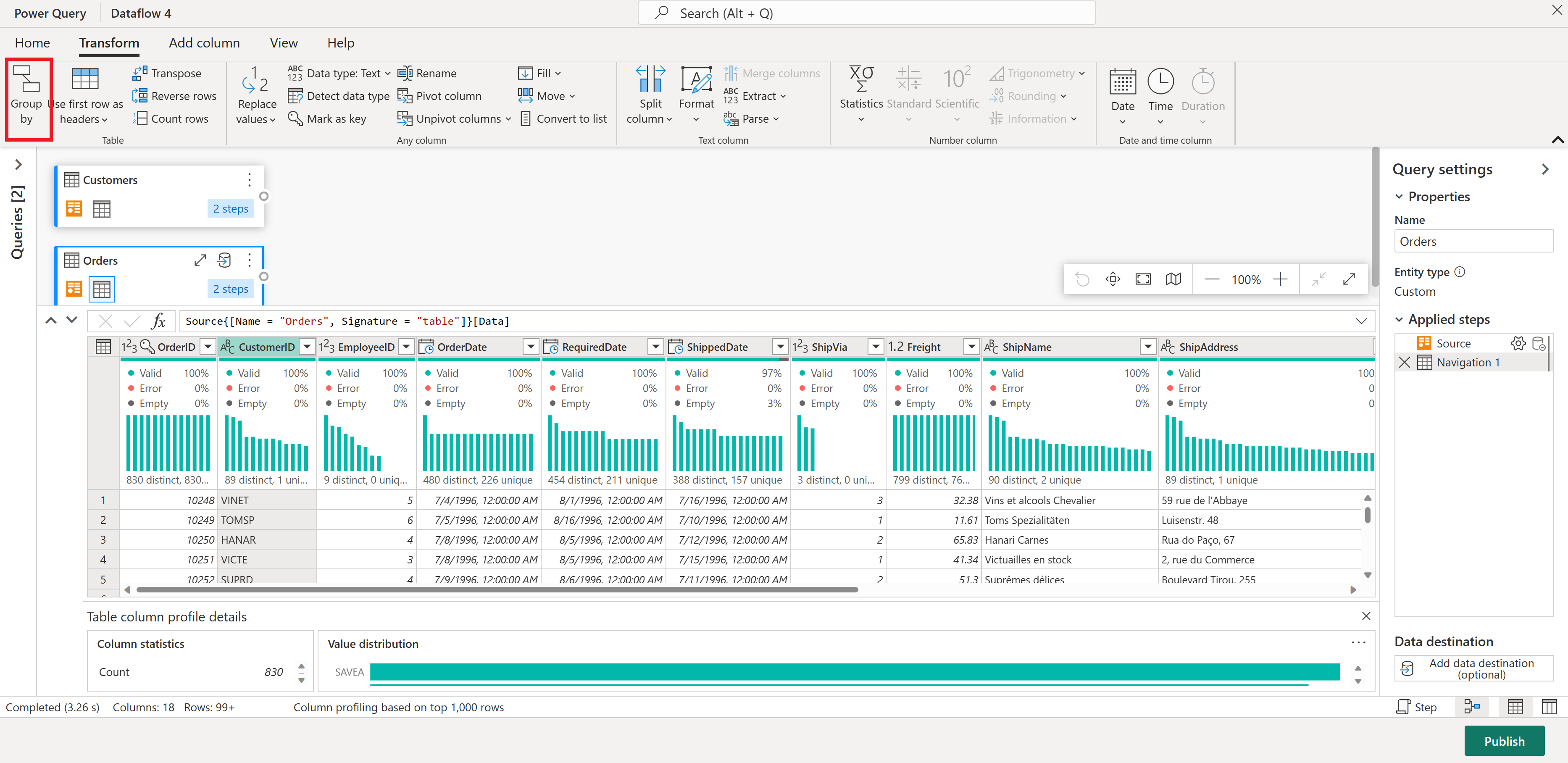
Du utfører et antall rader som aggregasjon i Grupper etter. Du kan lære mer om Group By-funksjoner ved gruppering eller oppsummering av rader.
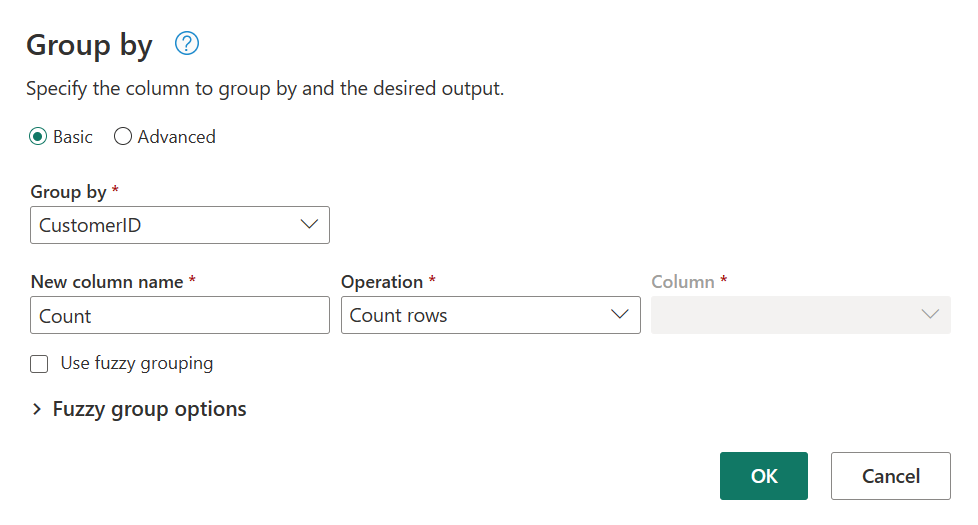
Når du har gruppert data i Ordrer-tabellen, får vi en tabell med to kolonner med CustomerID og Count som kolonner.
Deretter vil du kombinere data fra Kunder-tabellen med antall ordrer per kunde. Hvis du vil kombinere data, velger du Kunder-spørringen i diagramvisningen og bruker menyen «⋮» til å få tilgang til flettespørringene som ny transformasjon.
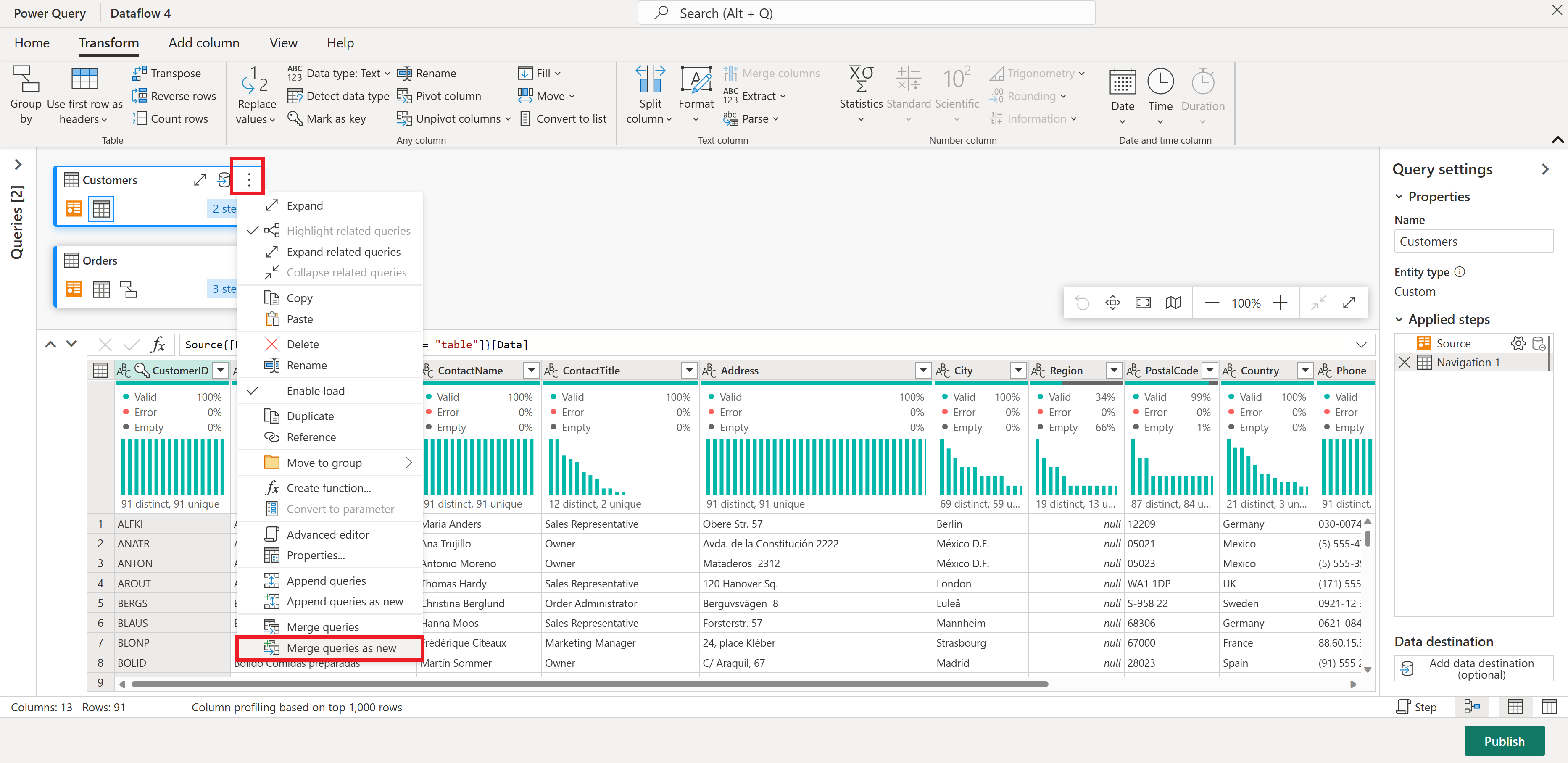
Konfigurer sammenslåingsoperasjonen som vist i skjermbildet nedenfor ved å velge CustomerID som samsvarende kolonne i begge tabellene. Deretter velger du Ok.
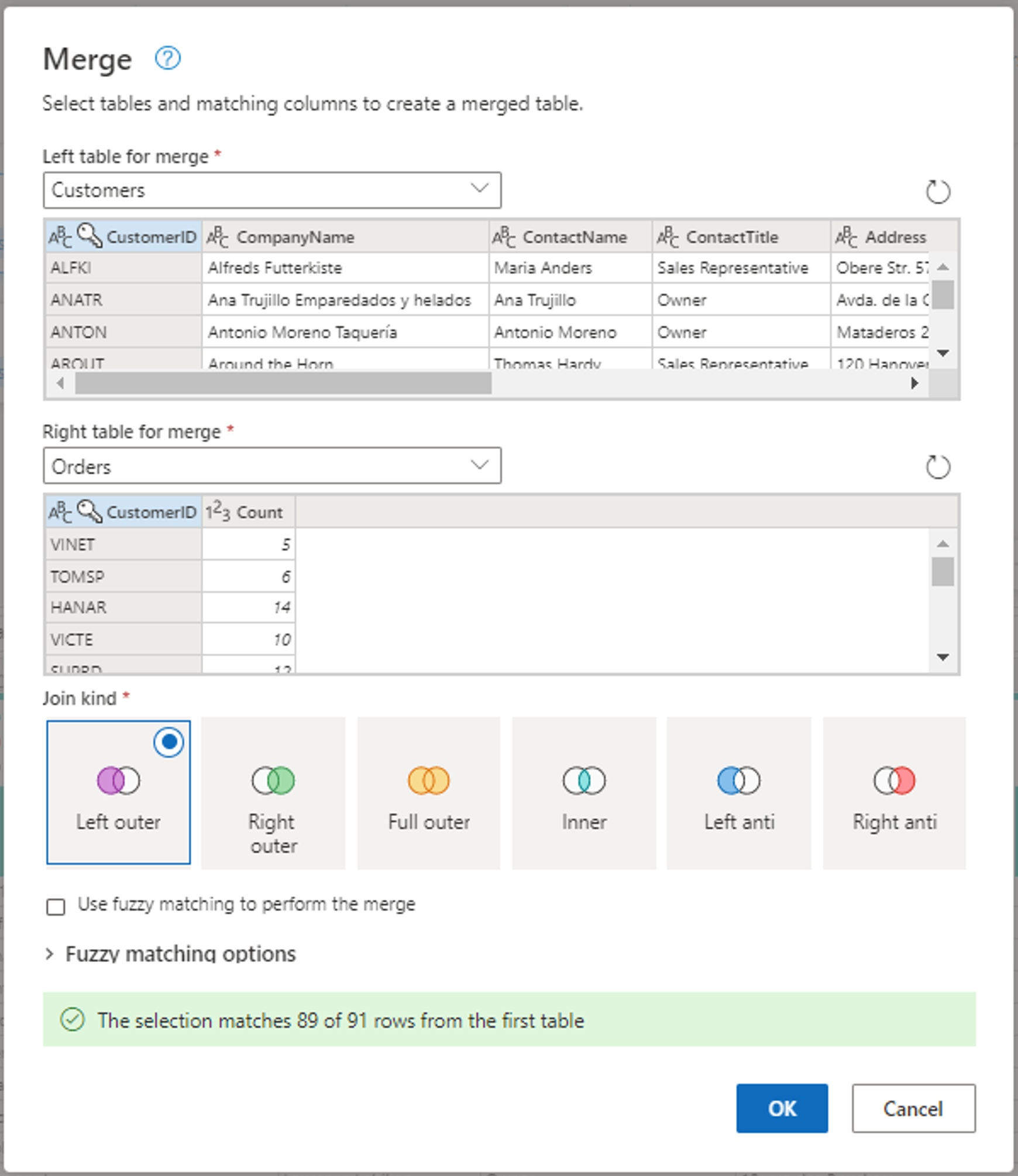
Skjermbilde av Flett-vinduet, med Venstre-tabellen for fletting satt til Kunder-tabellen og Høyre-tabellen for fletting satt til Ordrer-tabellen. CustomerID-kolonnen er valgt for både Kunder- og Ordrer-tabellene. Sammenføyningstype er også satt til Venstre ytre. Alle andre valg er satt til standardverdien.
Når du utfører flettespørringene som ny operasjon, får du en ny spørring med alle kolonner fra Kunder-tabellen og én kolonne med nestede data fra Ordrer-tabellen.
I dette eksemplet er du bare interessert i et delsett med kolonner i Kunder-tabellen. Du velger disse kolonnene ved hjelp av skjemavisningen. Aktiver skjemavisningen i veksleknappen nederst til høyre i redigeringsprogrammet for dataflyter.
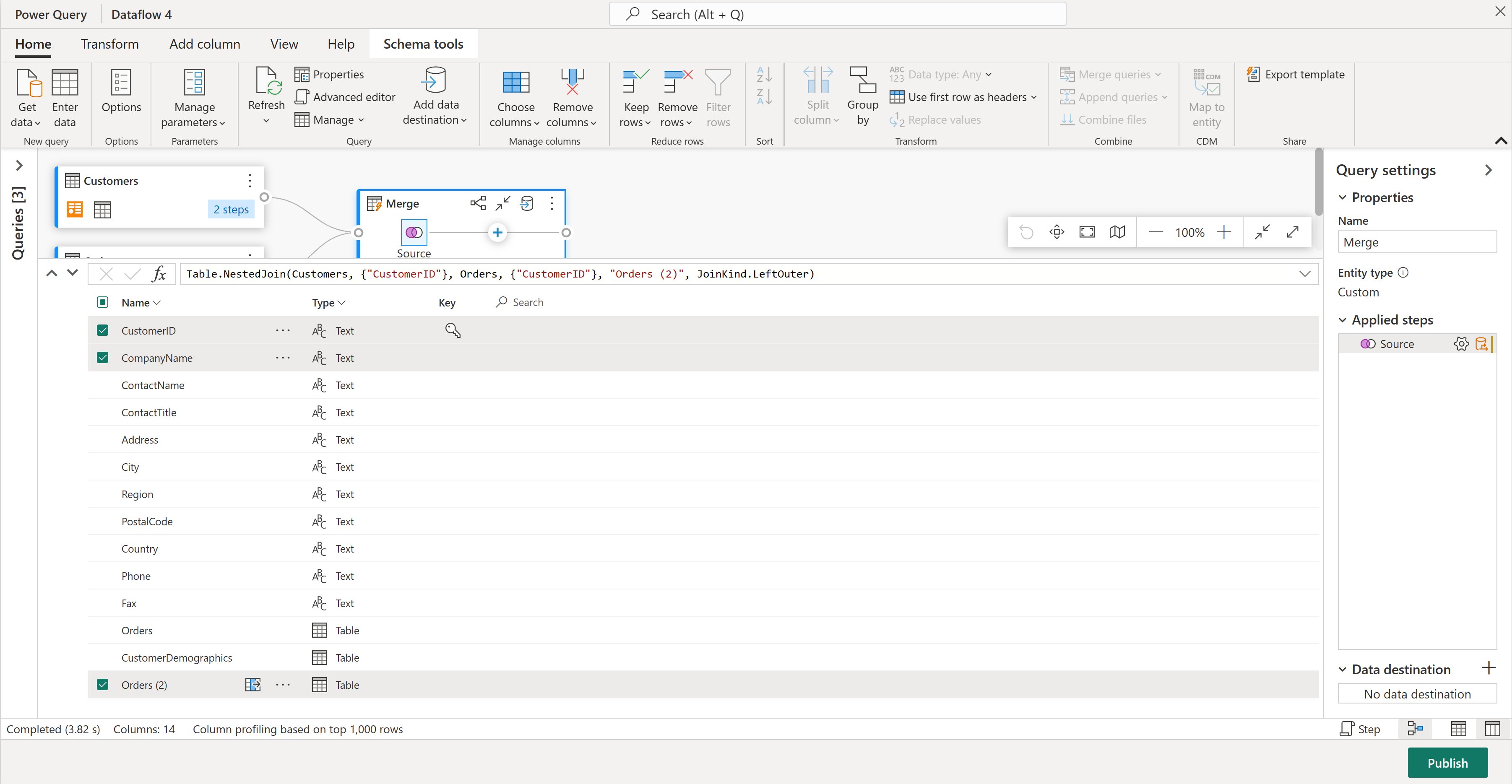
Skjemavisningen gir en fokusert visning i skjemainformasjonen for en tabell, inkludert kolonnenavn og datatyper. Skjemavisning har et sett med skjemaverktøy tilgjengelig via en kontekstavhengig båndfane. I dette scenarioet velger du kolonnene CustomerID, CompanyName og Orders (2), deretter velger du Fjern kolonner-knappen , og deretter velger du Fjern andre kolonner i kategorien Skjemaverktøy .
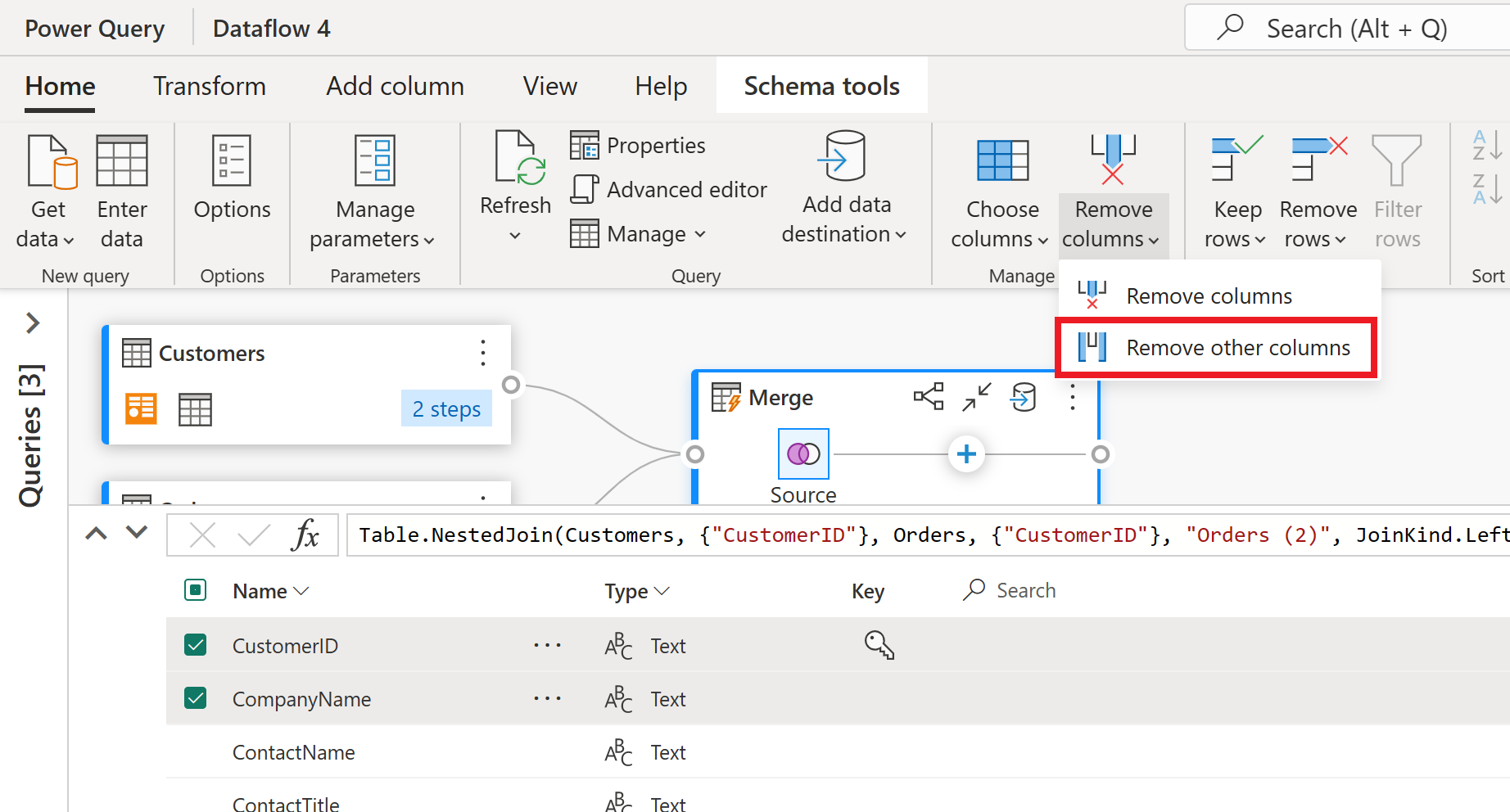
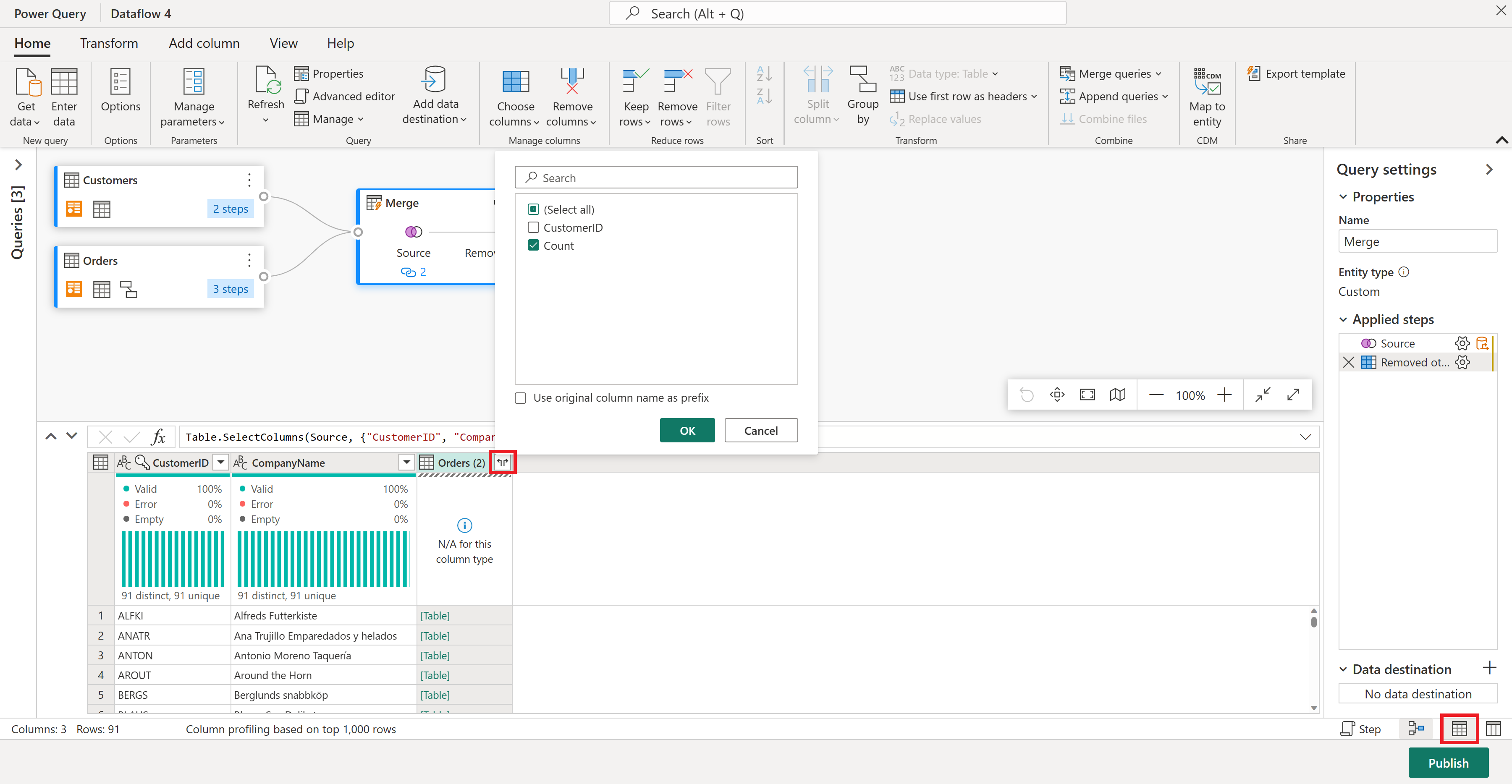
Ordrer (2)-kolonnen inneholder nestet informasjon som følge av fletteoperasjonen du utførte for noen få trinn siden. Bytt tilbake til datavisningen ved å velge Vis datavisning-knappen ved siden av Vis skjemavisning-knappen nederst til høyre i brukergrensesnittet. Bruk deretter utvid kolonnetransformasjonen i kolonneoverskriften Ordrer (2) til å velge Antall-kolonnen.
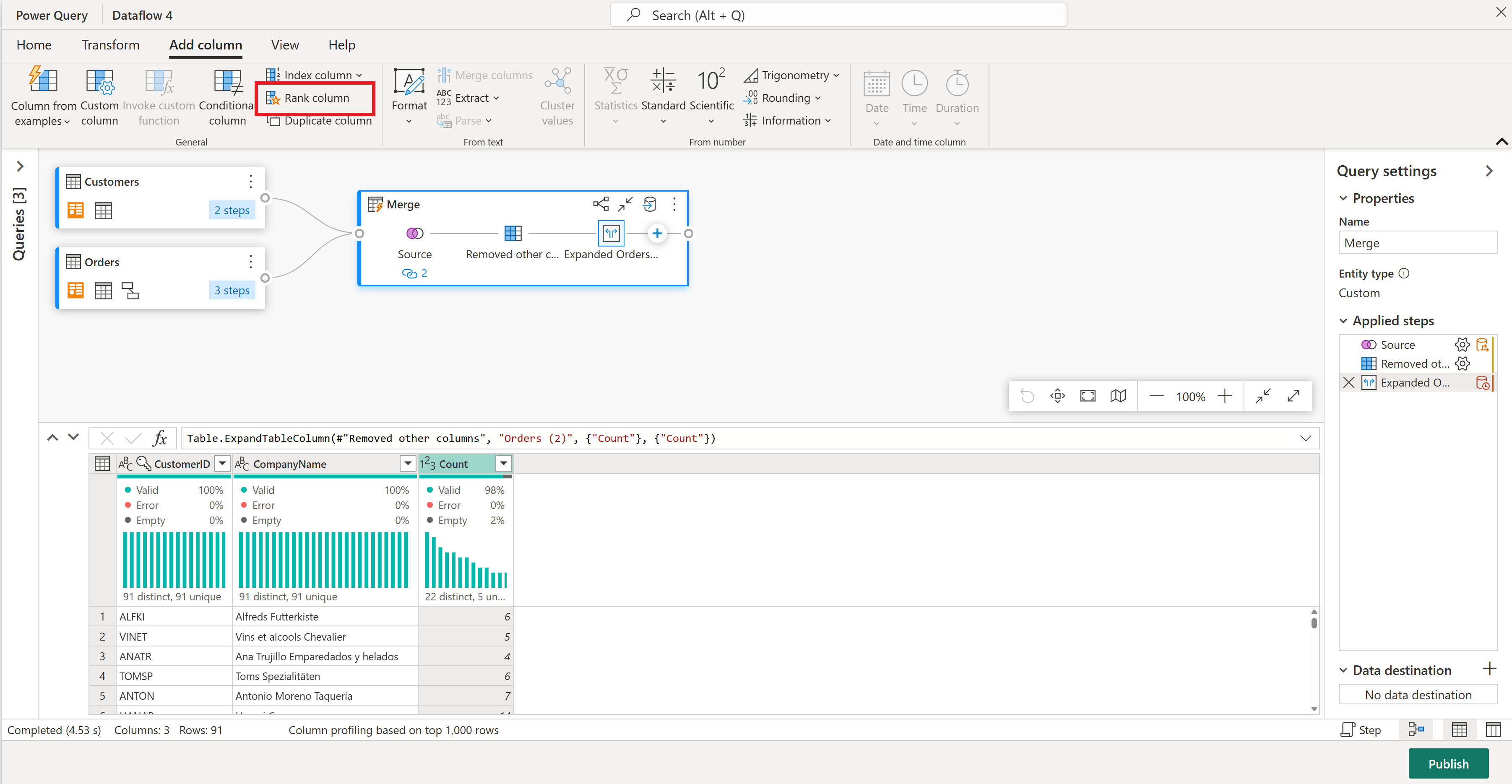
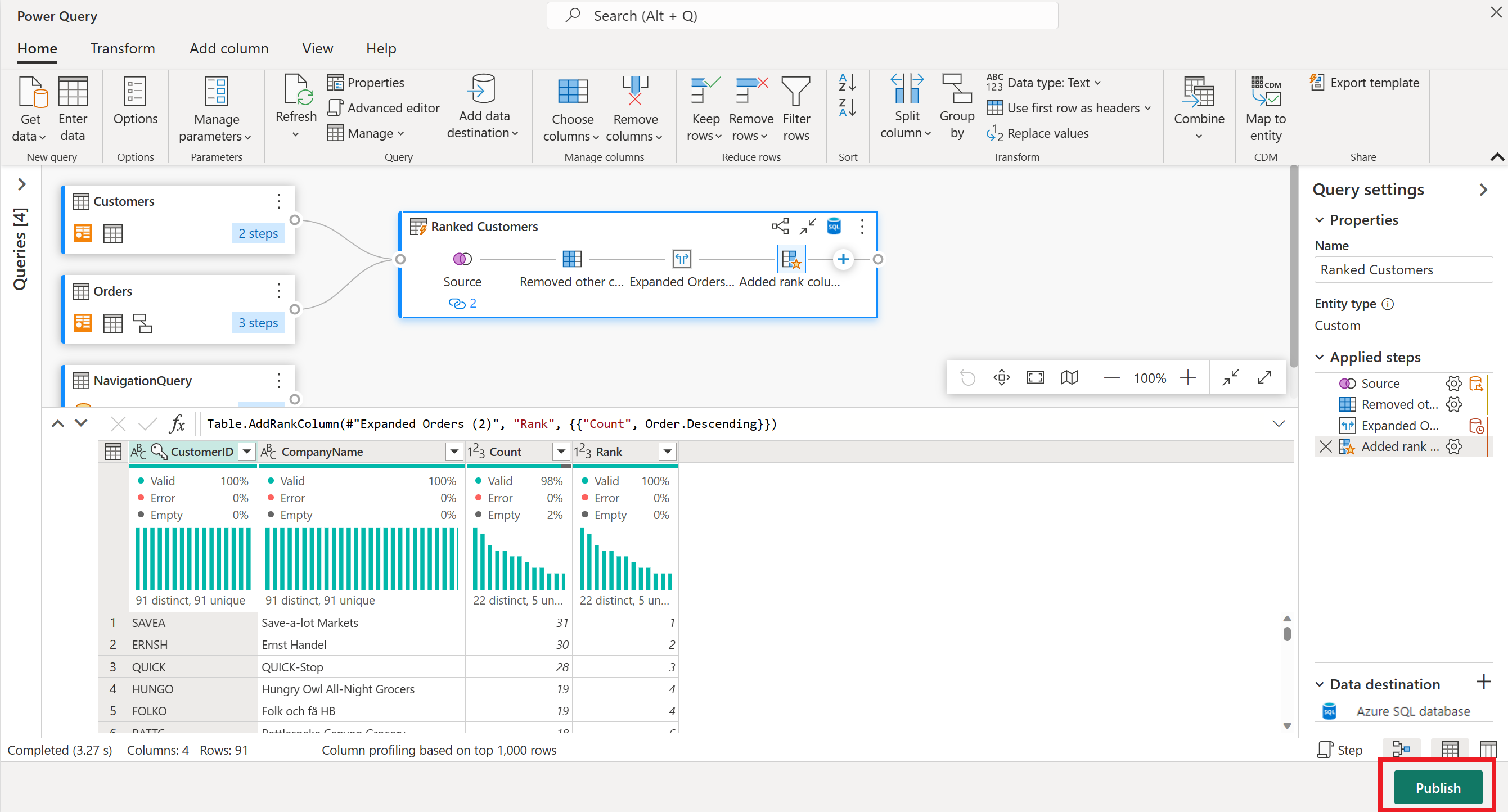
Som den endelige operasjonen vil du rangere kundene basert på antall bestillinger. Velg Antall-kolonnen, og velg deretter Rangering-kolonneknappen under Legg til kolonne-fanen på båndet.
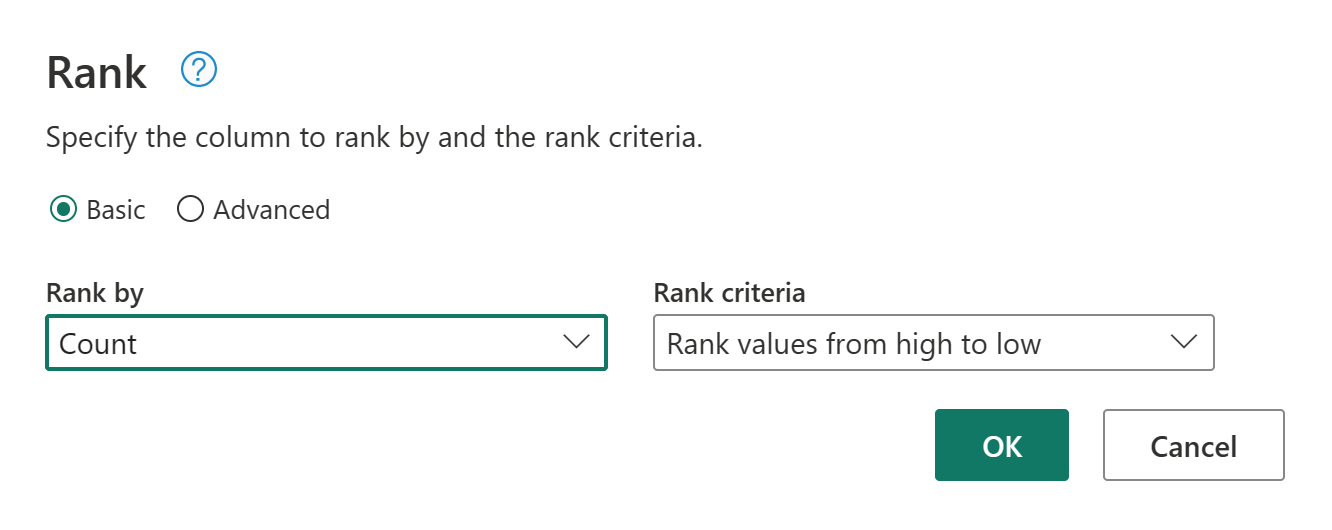
Behold standardinnstillingene i Rangeringskolonne. Velg deretter OK for å bruke denne transformasjonen.
Gi den resulterende spørringen nytt navn som rangerte kunder ved hjelp av ruten for spørringsinnstillinger på høyre side av skjermen.
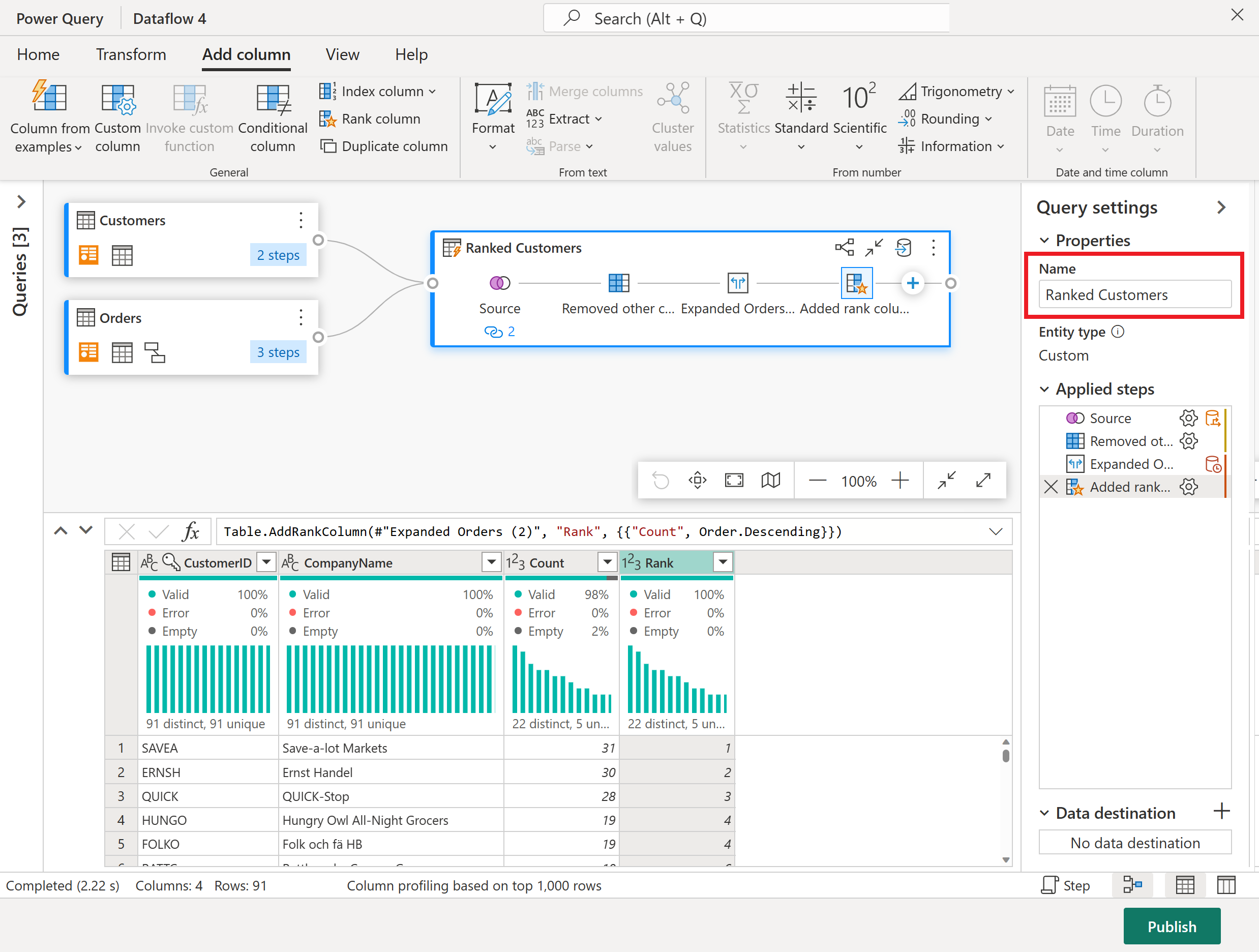
Nå som du er ferdig med å transformere og kombinere dataene, kan du konfigurere innstillingene for utdatamål. Velg Velg datamål nederst i ruten for spørringsinnstillinger .
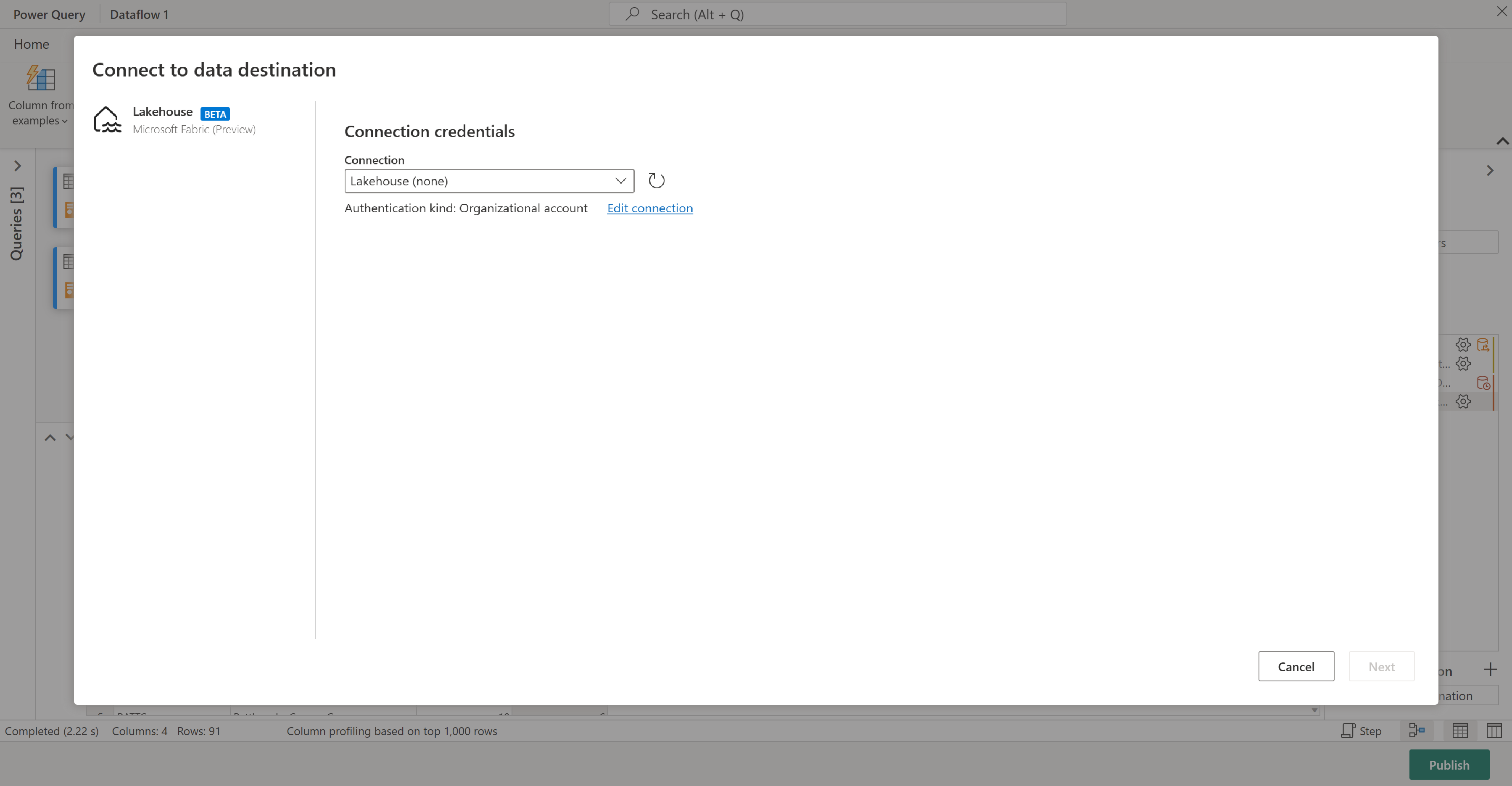
For dette trinnet kan du konfigurere en utdata til lakehouse hvis du har en tilgjengelig, eller hoppe over dette trinnet hvis du ikke gjør det. I denne opplevelsen kan du konfigurere målsjøen og tabellen for spørringsresultatene, i tillegg til oppdateringsmetoden (Tilføy eller erstatt).
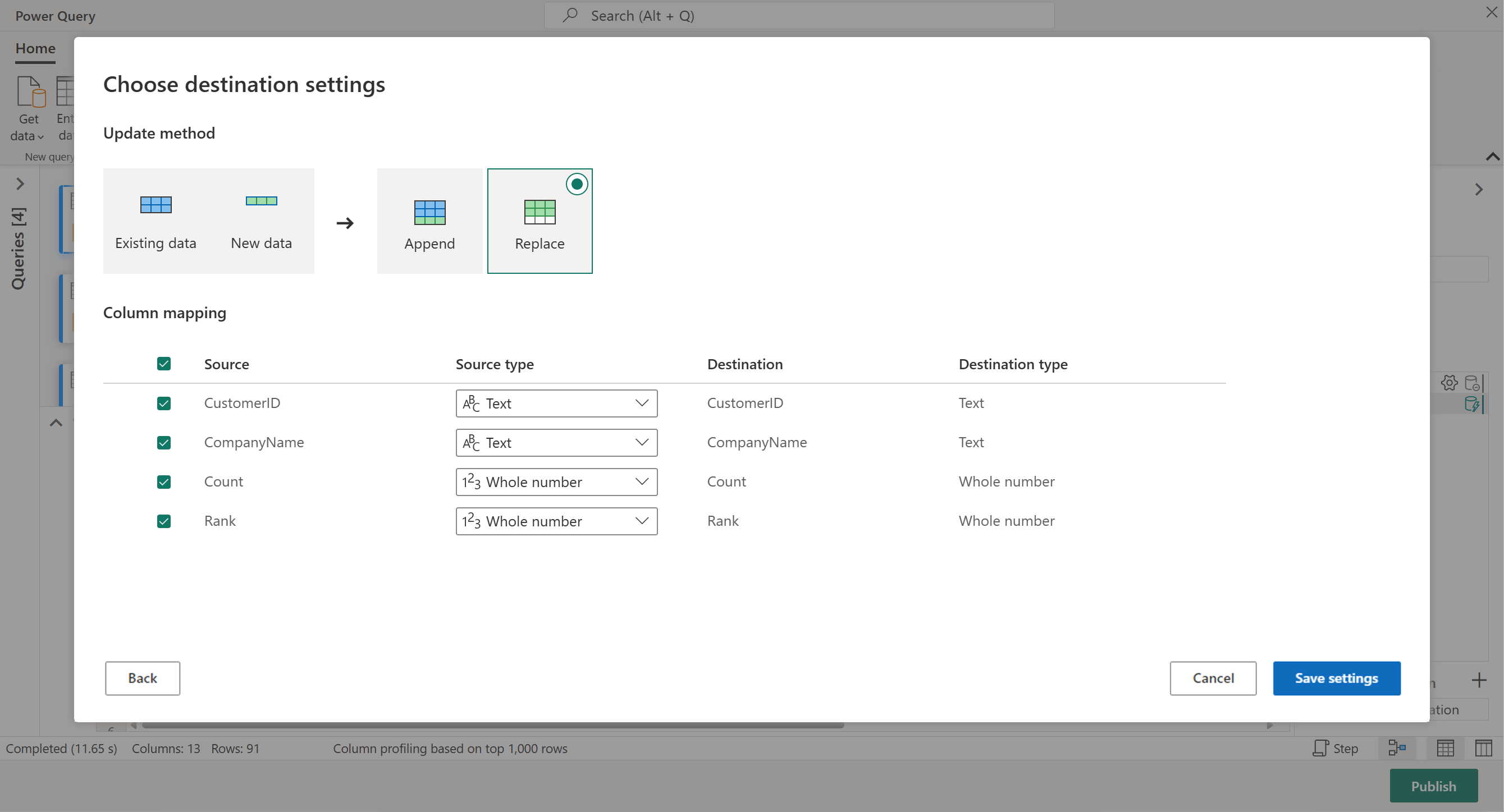
Dataflyten er nå klar til å publiseres. Se gjennom spørringene i diagramvisningen, og velg deretter Publiser.
Du er nå returnert til arbeidsområdet. Et spinnerikon ved siden av dataflytnavnet indikerer at publisering pågår. Når publiseringen er fullført, er dataflyten klar til oppdatering!
Viktig
Når den første dataflyten Gen2 opprettes i et arbeidsområde, klargjøres Lakehouse- og Warehouse-elementer sammen med relaterte SQL Analytics-endepunkt og semantiske modeller. Disse elementene deles av alle dataflyter i arbeidsområdet og kreves for at Dataflyt gen2 skal fungere, bør ikke slettes, og er ikke ment å brukes direkte av brukere. Elementene er en implementeringsdetalj for Dataflyt gen2. Elementene er ikke synlige i arbeidsområdet, men kan være tilgjengelige i andre opplevelser, for eksempel notatblokken, SQL Analytics-endepunktet, Lakehouse- og Warehouse-opplevelsene. Du kan gjenkjenne elementene ved hjelp av prefikset i navnet. Prefikset for elementene er Dataflytsstaging.
Velg Ikonet Planlegg oppdatering i arbeidsområdet.

Aktiver den planlagte oppdateringen, velg Legg til et nytt tidspunkt, og konfigurer oppdateringen som vist i skjermbildet nedenfor.
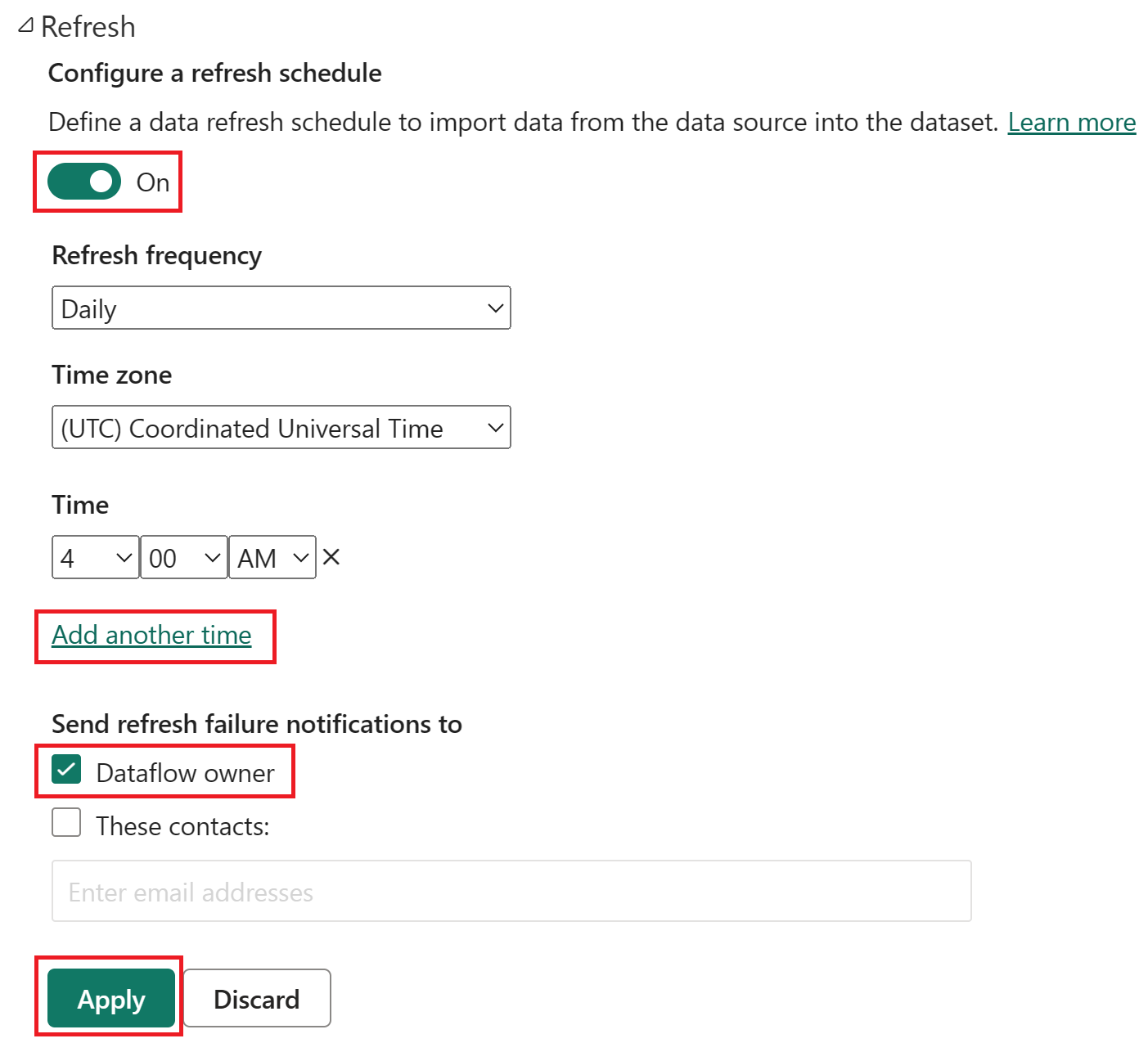
Skjermbilde av de planlagte oppdateringsalternativene, med planlagt oppdatering aktivert, oppdateringshyppigheten satt til Daglig, Tidssone satt til koordinert universell tid og klokkeslettet satt til 04:00. På-knappen, legg til et annet tidsvalg, eieren av dataflyten og bruk-knappen fremheves.













Fjerning av ressurser
Hvis du ikke skal fortsette å bruke denne dataflyten, sletter du dataflyten ved hjelp av følgende fremgangsmåte:
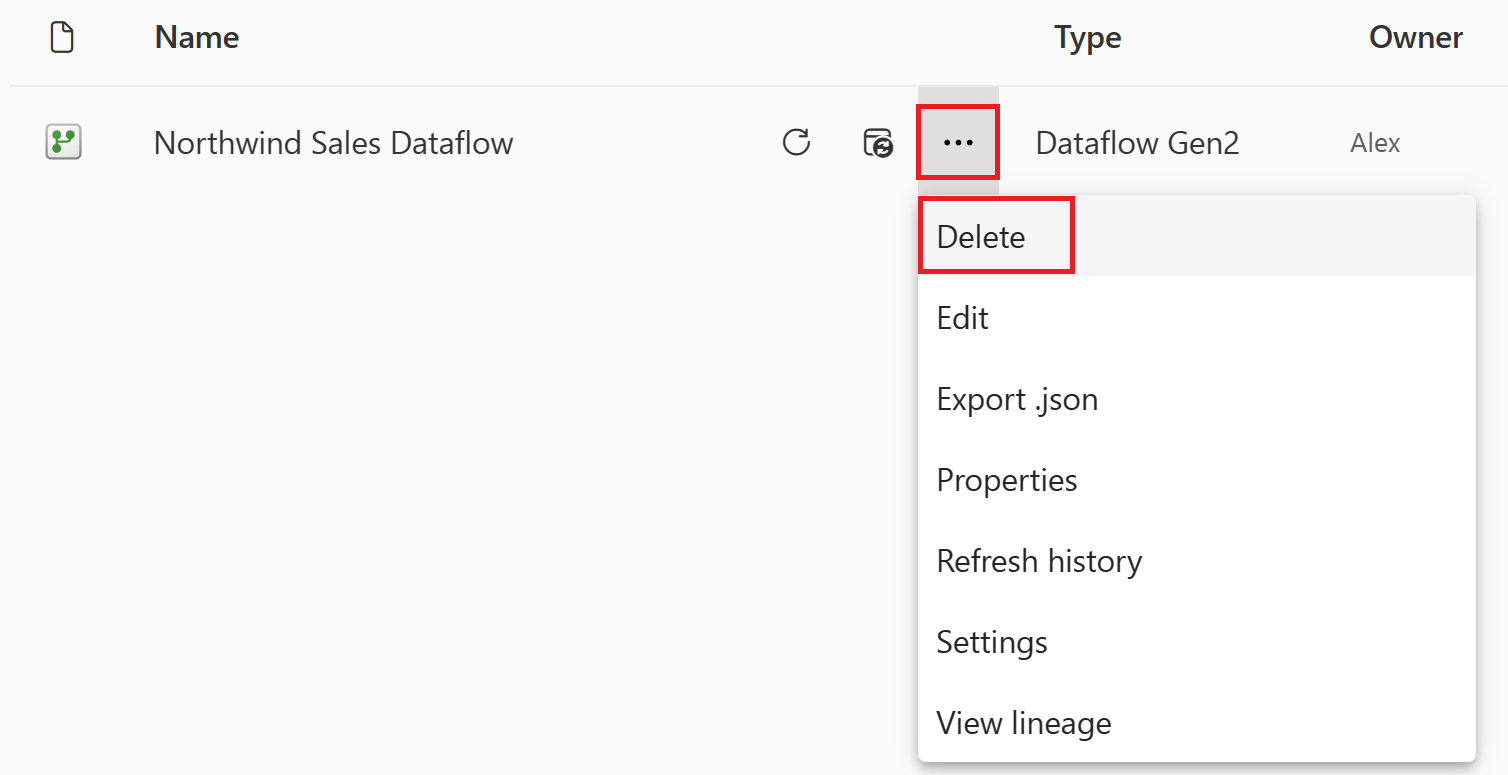
Gå til Microsoft Fabric-arbeidsområdet.
Velg den loddrette ellipsen ved siden av navnet på dataflyten, og velg deretter Slett.
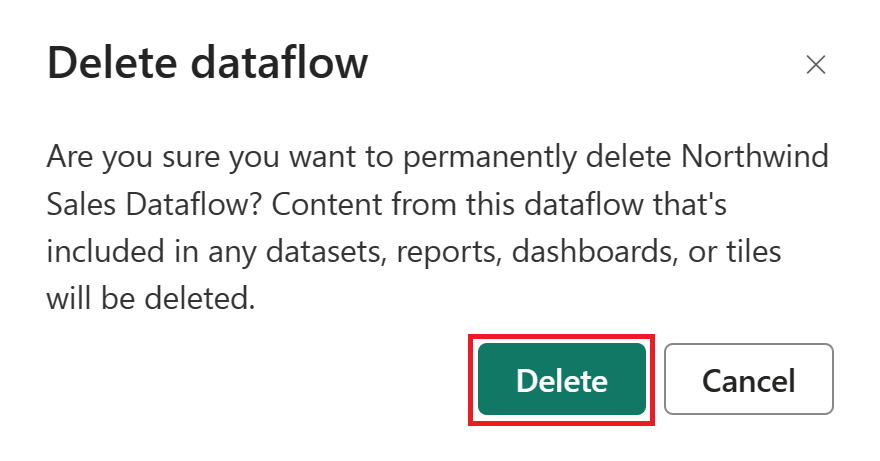
Velg Slett for å bekrefte slettingen av dataflyten.
Relatert innhold
Dataflyten i dette eksemplet viser deg hvordan du laster inn og transformerer data i Dataflyt gen2. Du lærte hvordan du:
- Opprett en dataflyt-gen2.
- Transformer data.
- Konfigurer målinnstillinger for transformerte data.
- Kjør og planlegg datasamlebåndet.
Gå videre til neste artikkel for å lære hvordan du oppretter det første datasamlebåndet.