Transformere data ved å kjøre en Azure HDInsight-aktivitet
Azure HDInsight-aktiviteten i Data Factory for Microsoft Fabric lar deg organisere følgende azure HDInsight-jobbtyper:
- Utfør Hive-spørringer
- Aktiver et MapReduce-program
- Utføre grisspørringer
- Utfør et Spark-program
- Kjøre et Hadoop Stream-program
Denne artikkelen inneholder en trinnvis gjennomgang som beskriver hvordan du oppretter en Azure HDInsight-aktivitet ved hjelp av Data Factory-grensesnittet.
Forutsetning
Du må fullføre følgende forutsetninger for å komme i gang:
- En leierkonto med et aktivt abonnement. Opprett en konto gratis.
- Det opprettes et arbeidsområde.
Legg til en Azure HDInsight-aktivitet (HDI) i et datasamlebånd med brukergrensesnittet
Opprett et nytt datasamlebånd i arbeidsområdet.
Søk etter Azure HDInsight fra startskjermkortet, og velg den eller velg aktiviteten fra aktivitetslinjen for å legge den til på datasamlebåndlerretet.
Opprette aktiviteten fra startskjermkortet:

Oppretter aktiviteten fra aktivitetslinjen:
Velg den nye Azure HDInsight-aktiviteten på lerretet for datasamlebåndredigering hvis den ikke allerede er valgt.
Se veiledningen for generelle innstillinger for å konfigurere alternativene som finnes i kategorien Generelle innstillinger .

Konfigurer HDI-klyngen
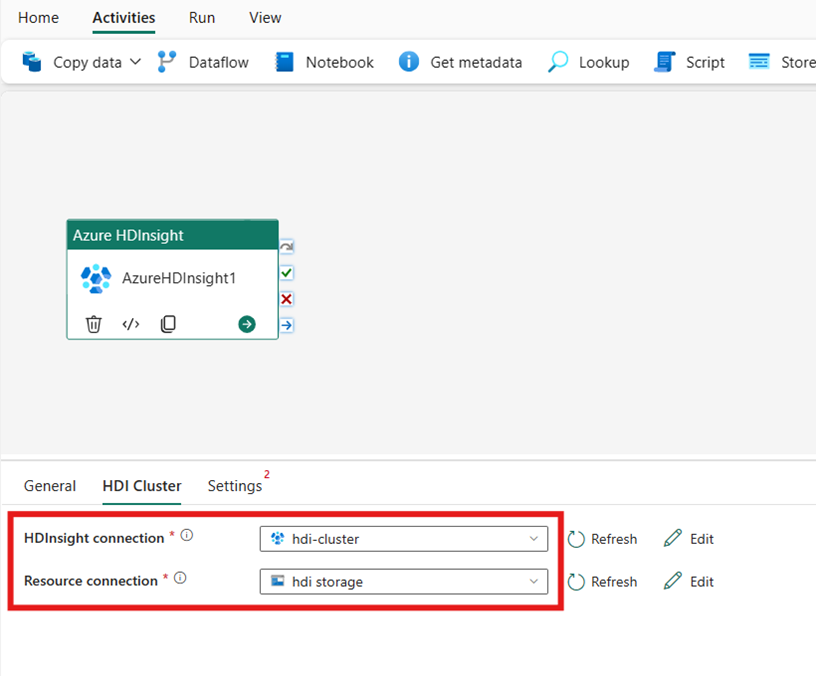
Velg fanen HDI-klynge . Deretter kan du velge en eksisterende eller opprette en ny HDInsight-tilkobling.
Velg Azure Blob Storage som refererer til Azure HDInsight-klyngen for ressurstilkoblingen. Du kan velge et eksisterende Blob-lager eller opprette et nytt.
Konfigurer innstillinger
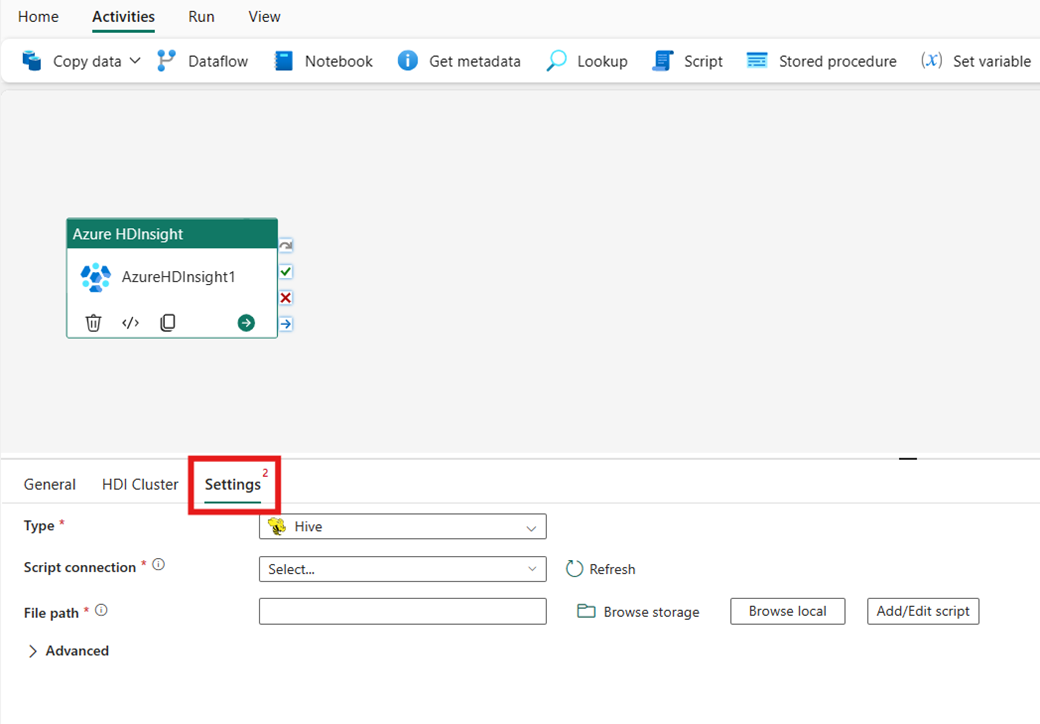
Velg Innstillinger-fanen for å se de avanserte innstillingene for aktiviteten.
Alle avanserte klyngeegenskaper og dynamiske uttrykk som støttes i Azure Data Factory og Synapse Analytics HDInsight-koblede tjenester, støttes nå også i Azure HDInsight-aktiviteten for Data Factory i Microsoft Fabric, under Avansert-delen i brukergrensesnittet. Disse egenskapene støtter alle egendefinerte parameteruttrykk som er enkle å bruke, med dynamisk innhold.
Klyngetype
Hvis du vil konfigurere innstillinger for HDInsight-klyngen, må du først velge type fra de tilgjengelige alternativene, inkludert Hive, Map Reduce, Pig, Spark og Streaming.
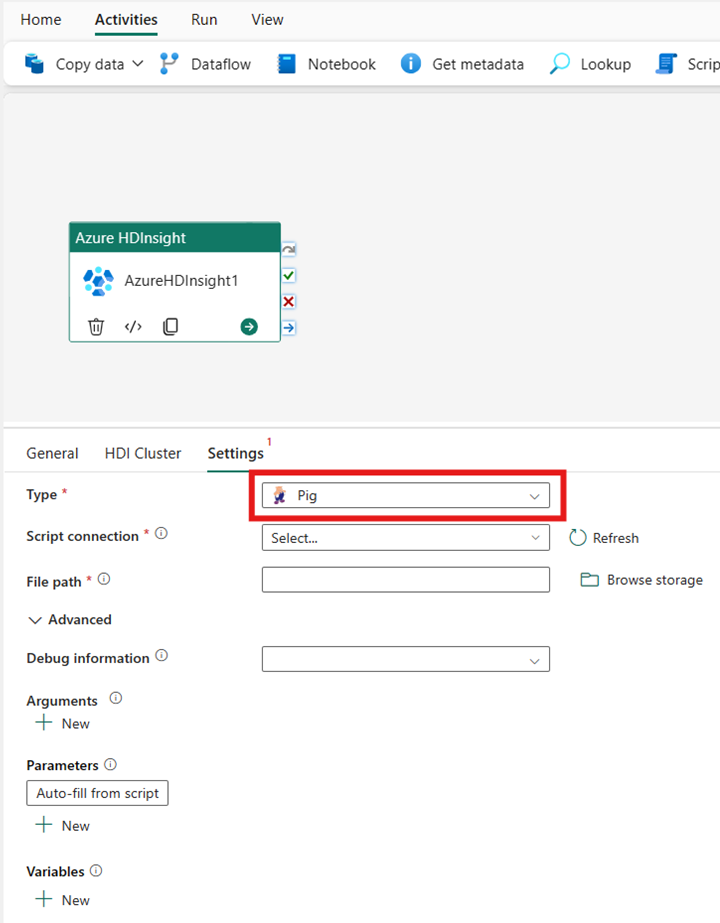
Struktur
Hvis du velger Hive for Type, utfører aktiviteten en Hive-spørring. Du kan eventuelt angi skripttilkoblingen som refererer til en lagringskonto som inneholder Hive-typen. Som standard brukes lagringstilkoblingen du angav i kategorien HDI-klynge . Du må angi filbanen som skal kjøres på Azure HDInsight. Du kan eventuelt angi flere konfigurasjoner i Avansert-delen , Feilsøkingsinformasjon, Tidsavbrudd for spørring, Argumenter, Parametere og Variabler.
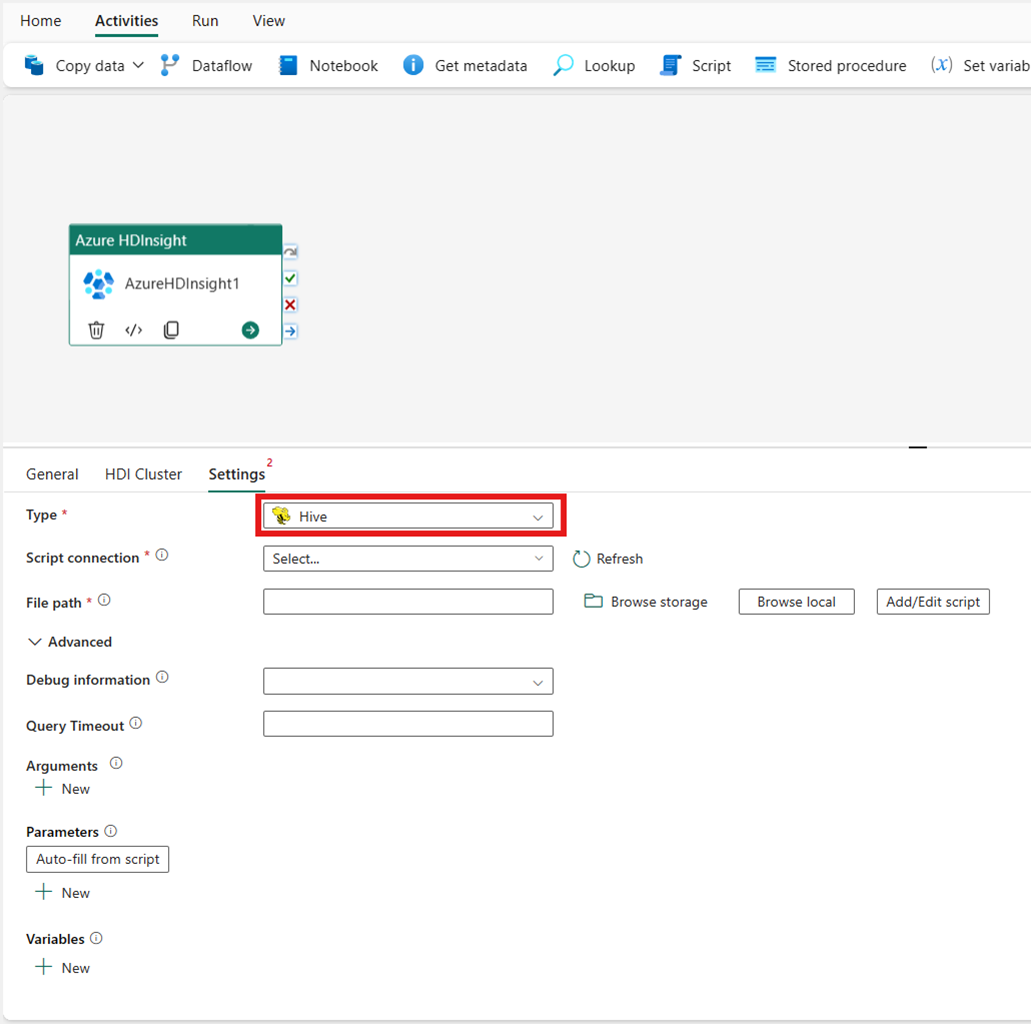
Kart reduser
Hvis du velger Tilordning reduser for type, aktiverer aktiviteten et Map Reduce-program. Du kan eventuelt angi i Jar-tilkoblingen som refererer til en lagringskonto som inneholder map Reduce-typen. Som standard brukes lagringstilkoblingen du angav i kategorien HDI-klynge. Du må angi klassenavnet og filbanen som skal kjøres på Azure HDInsight. Du kan også angi flere konfigurasjonsdetaljer, for eksempel import av Jar-biblioteker, feilsøkingsinformasjon, argumenter og parametere under Avansert-delen.
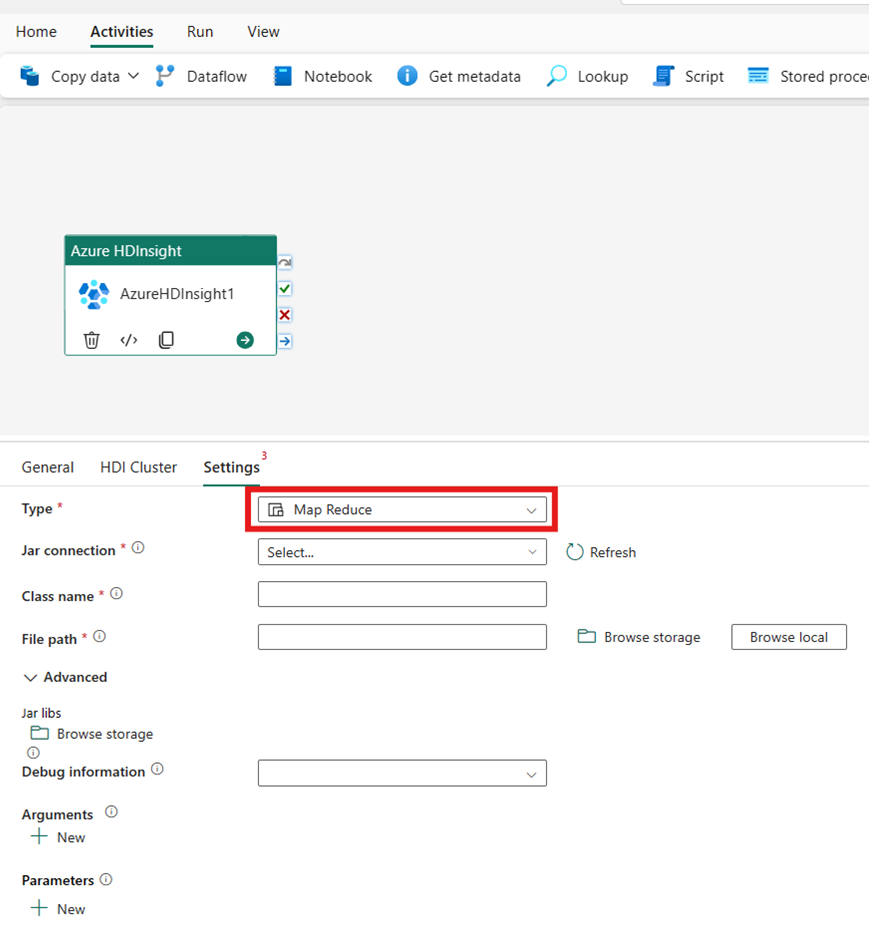
Pig
Hvis du velger Gris for type, aktiverer aktiviteten en grisespørring. Du kan eventuelt angi innstillingen for skripttilkobling som refererer til lagringskontoen som inneholder grisetypen. Som standard brukes lagringstilkoblingen du angav i kategorien HDI-klynge. Du må angi filbanen som skal kjøres på Azure HDInsight. Du kan også angi flere konfigurasjoner, for eksempel feilsøkingsinformasjon, argumenter, parametere og variabler under Avansert-delen.
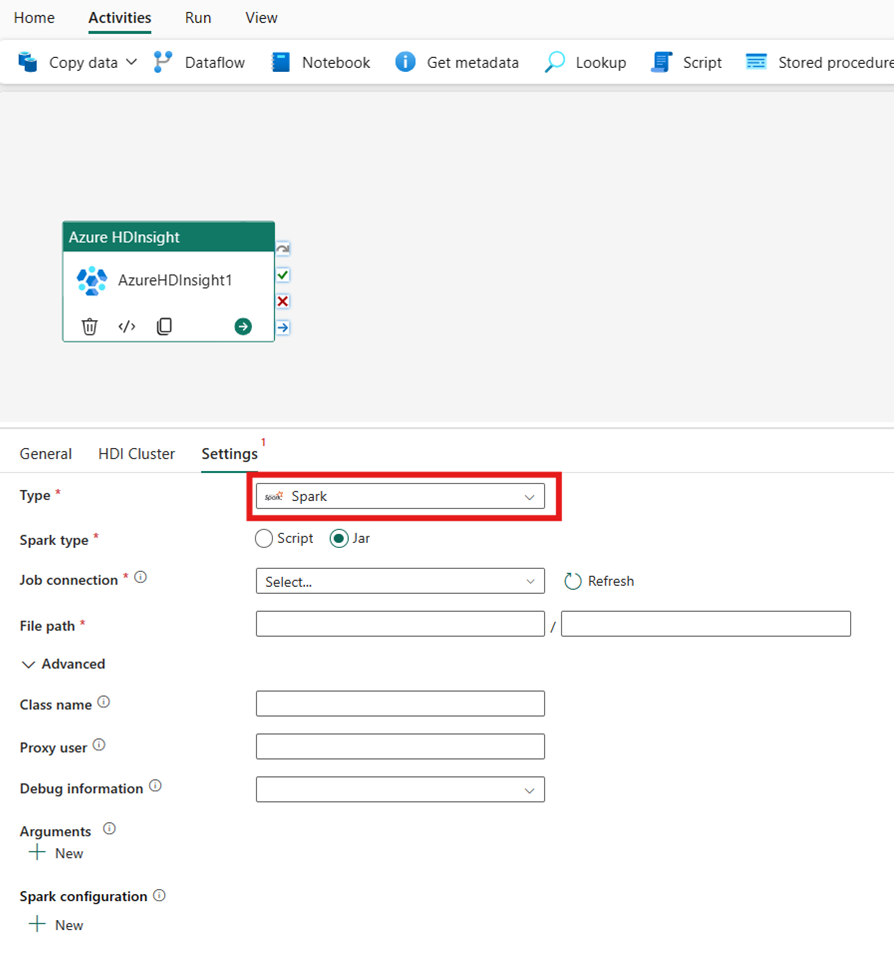
Spark
Hvis du velger Spark for Type, aktiverer aktiviteten et Spark-program. Velg enten Skript eller Krukke for Spark-typen. Du kan eventuelt angi jobbtilkoblingen som refererer til lagringskontoen som inneholder Spark-typen. Som standard brukes lagringstilkoblingen du angav i kategorien HDI-klynge. Du må angi filbanen som skal kjøres på Azure HDInsight. Du kan også angi flere konfigurasjoner, for eksempel klassenavn, proxy-bruker, feilsøkingsinformasjon, argumenter og spark-konfigurasjon under Avansert-delen.
Strømming
Hvis du velger Strømming for type, aktiverer aktiviteten et strømmingsprogram. Angi tilordnings- og reduseringsnavnene, og du kan eventuelt angi Fil-tilkoblingen som refererer til lagringskontoen som inneholder strømmetypen. Som standard brukes lagringstilkoblingen du angav i kategorien HDI-klynge. Du må angi filbanen for Mapper - og Fil-banen for redusering som skal kjøres på Azure HDInsight. Inkluder inndata- og utdataalternativene også for WASB-banen. Du kan også angi flere konfigurasjoner, for eksempel feilsøkingsinformasjon, argumenter og parametere under Avansert-delen.
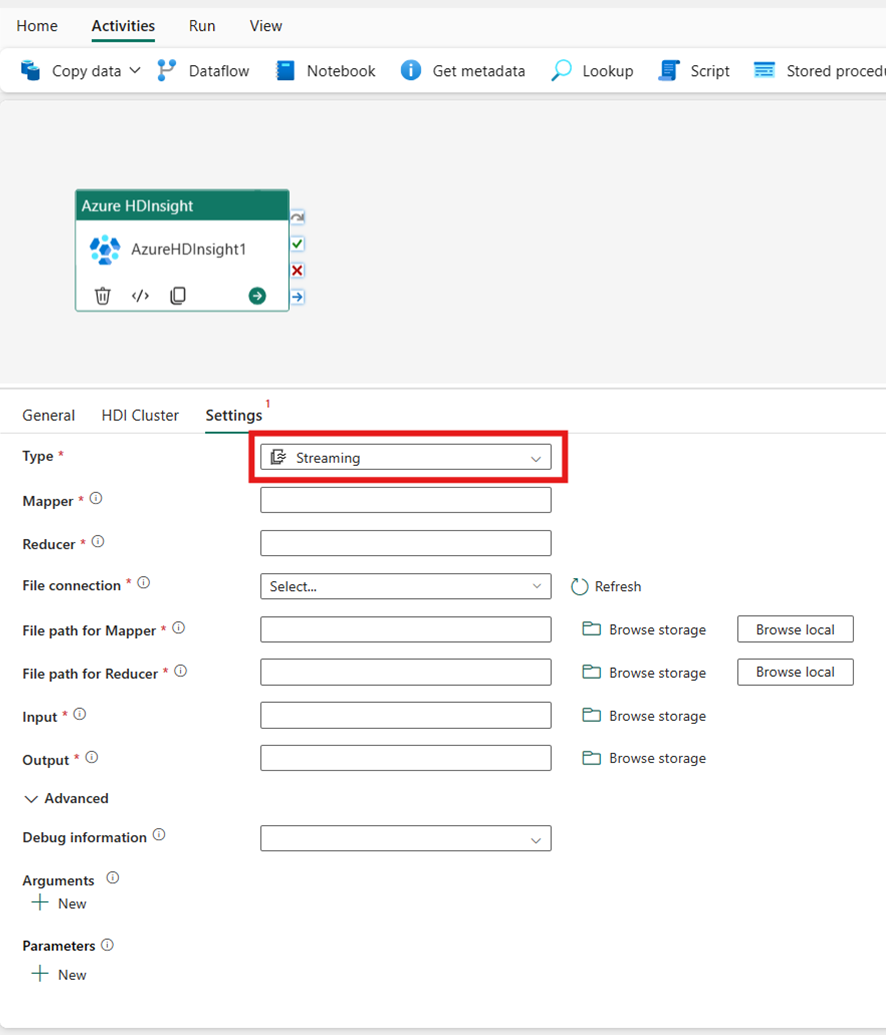
Egenskapsreferanse
| Egenskap | Beskrivelse | Kreves |
|---|---|---|
| type | For Hadoop Streaming Activity er aktivitetstypen HDInsightStreaming | Ja |
| mapper | Angir navnet på den kjørbare tilordningen | Ja |
| Redusering | Angir navnet på kjørbar redusering | Ja |
| kombinering | Angir navnet på den kjørbare kombinereren | No |
| filtilkobling | Referanse til en Azure Storage Linked Service som brukes til å lagre Mapper-, Combiner- og Reducer-programmene som skal kjøres. | No |
| Bare Azure Blob Storage- og ADLS Gen2-tilkoblinger støttes her. Hvis du ikke angir denne tilkoblingen, brukes lagringstilkoblingen som er definert i HDInsight-tilkoblingen. | ||
| filePath | Angi en matrise med bane til mapper-, kombiner- og reduseringsprogrammene som er lagret i Azure Storage som filtilkoblingen henviser til. | Ja |
| input | Angir WASB-banen til inndatafilen for Tilordning. | Ja |
| output | Angir WASB-banen til utdatafilen for Reducer. | Ja |
| getDebugInfo | Angir når loggfilene kopieres til Azure Storage som brukes av HDInsight-klyngen (eller) angitt av scriptLinkedService. | No |
| Tillatte verdier: Ingen, Alltid eller Feil. Standardverdi: Ingen. | ||
| Argumenter | Angir en matrise med argumenter for en Hadoop-jobb. Argumentene sendes som kommandolinjeargumenter til hver aktivitet. | No |
| Definerer | Angi parametere som nøkkel-/verdipar for referanse i Hive-skriptet. | No |
Lagre og kjøre eller planlegge datasamlebåndet
Når du har konfigurert andre aktiviteter som kreves for datasamlebåndet, bytter du til Hjem-fanen øverst i redigeringsprogrammet for datasamlebåndet, og velger lagre-knappen for å lagre datasamlebåndet. Velg Kjør for å kjøre den direkte, eller Planlegg for å planlegge den. Du kan også vise kjøreloggen her eller konfigurere andre innstillinger.
