Transformere data ved å kjøre en Azure Databricks-aktivitet
Azure Databricks-aktiviteten i Data Factory for Microsoft Fabric lar deg organisere følgende Azure Databricks-jobber:
- Notatblokk
- Krukke
- Python
Denne artikkelen inneholder en trinnvis gjennomgang som beskriver hvordan du oppretter en Azure Databricks-aktivitet ved hjelp av Data Factory-grensesnittet.
Forutsetning
Du må fullføre følgende forutsetninger for å komme i gang:
- En leierkonto med et aktivt abonnement. Opprett en konto gratis.
- Det opprettes et arbeidsområde.
Konfigurere en Azure Databricks-aktivitet
Hvis du vil bruke en Azure Databricks-aktivitet i et datasamlebånd, gjør du følgende:
Konfigurere tilkobling
Opprett et nytt datasamlebånd i arbeidsområdet.
Klikk på legg til en datasamlebåndaktivitet, og søk etter Azure Databricks.
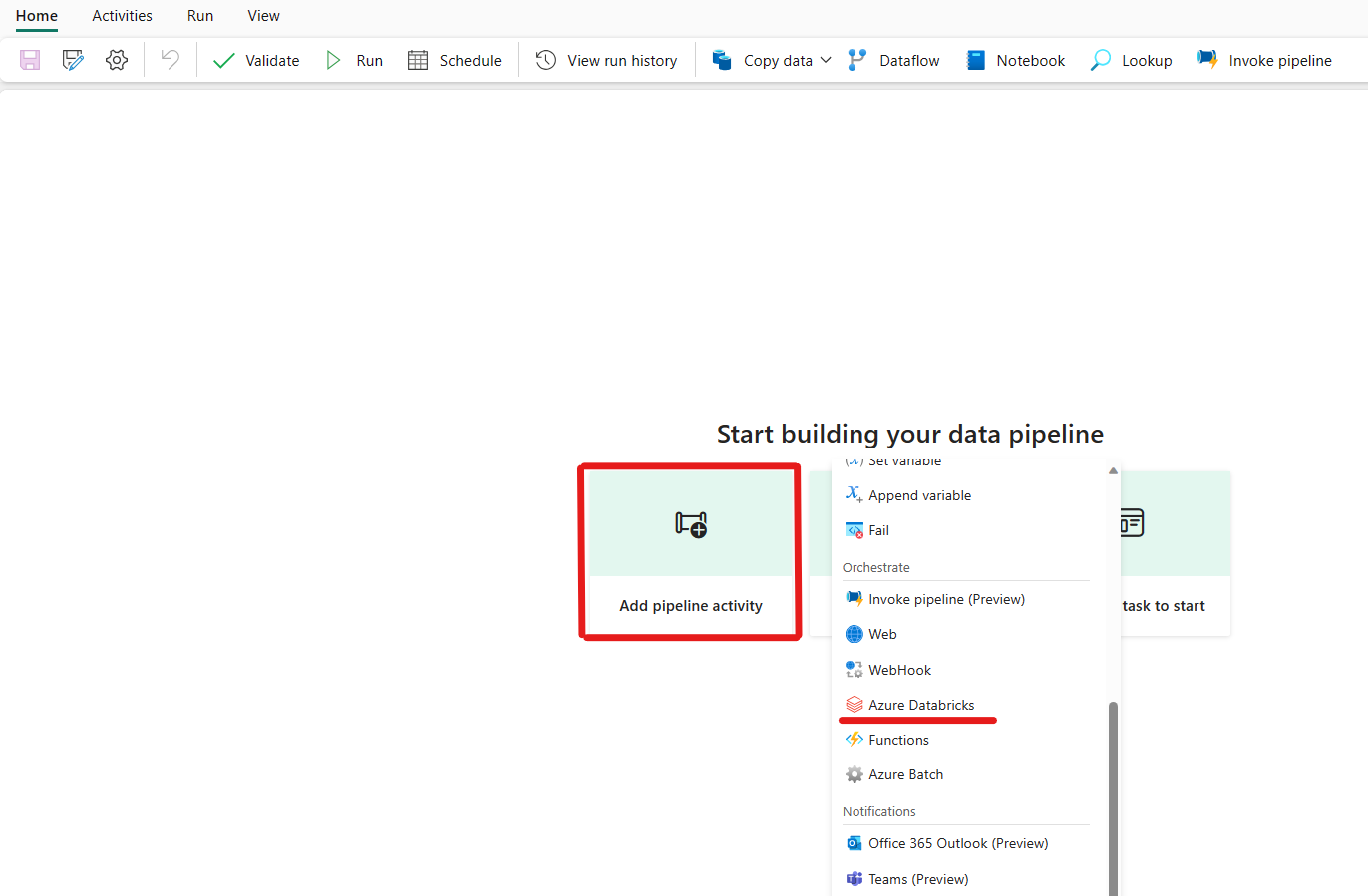
Alternativt kan du søke etter Azure Databricks i ruten for datasamlebåndaktiviteter, og velge den for å legge den til på datasamlebåndlerretet.
Velg den nye Azure Databricks-aktiviteten på lerretet hvis den ikke allerede er valgt.
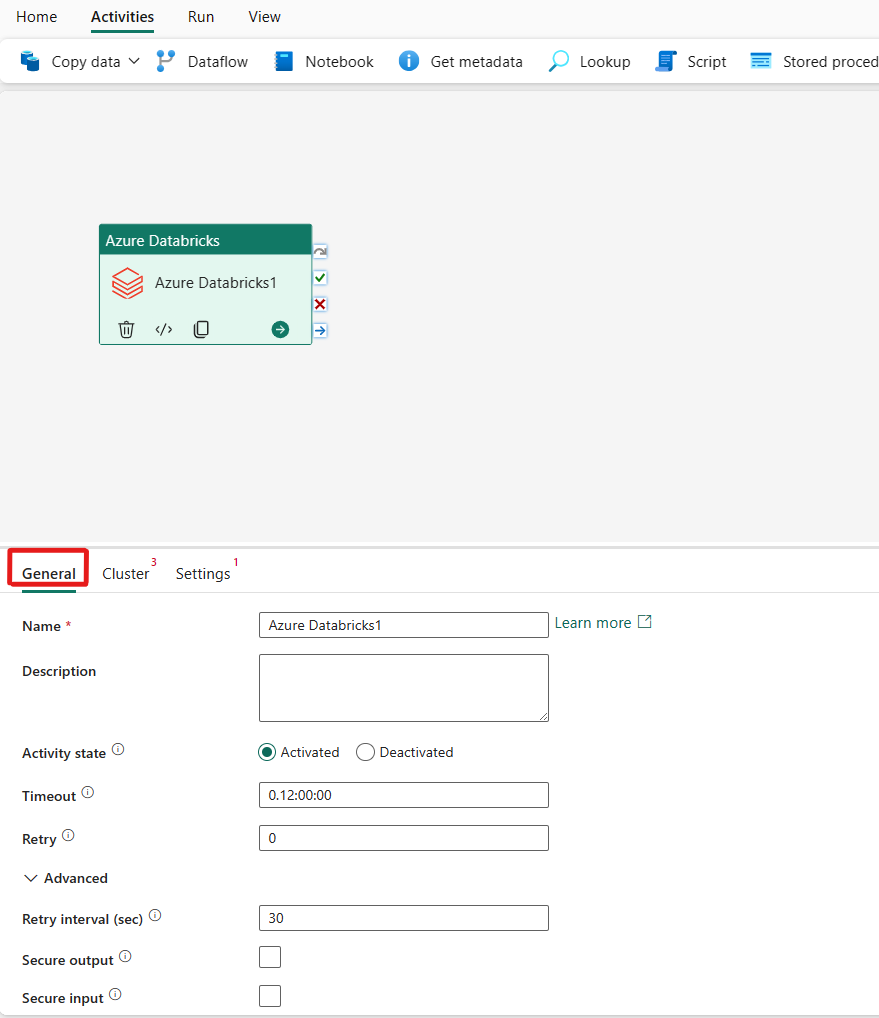
Se veiledningen for generelle innstillinger for å konfigurere fanen Generelle innstillinger.
Konfigurere klynger
Velg Klynge-fanen. Deretter kan du velge en eksisterende eller opprette en ny Azure Databricks-tilkobling, og deretter velge en ny jobbklynge, en eksisterende interaktiv klynge eller et eksisterende forekomstutvalg.
Avhengig av hva du velger for klyngen, fyller du ut de tilsvarende feltene slik de presenteres.
- Under ny jobbklynge og eksisterende forekomstutvalg har du også muligheten til å konfigurere antall arbeidere og aktivere spotforekomster.
Du kan også angi flere klyngeinnstillinger, for eksempel klyngepolicy, Spark-konfigurasjon, Spark-miljøvariabler og egendefinerte koder, etter behov for klyngen du kobler til. Databricks init-skript og målbane for klyngelogg kan også legges til under de ekstra klyngeinnstillingene.
Merk
Alle avanserte klyngeegenskaper og dynamiske uttrykk som støttes i Azure Data Factory Azure Databricks-koblede tjenesten, støttes nå også i Azure Databricks-aktiviteten i Microsoft Fabric under delen «Ekstra klyngekonfigurasjon» i brukergrensesnittet. Ettersom disse egenskapene nå er inkludert i aktivitetsgrensesnittet. De kan enkelt brukes med et uttrykk (dynamisk innhold) uten behov for avansert JSON-spesifikasjon i den koblede tjenesten Azure Databricks for Azure Databricks.
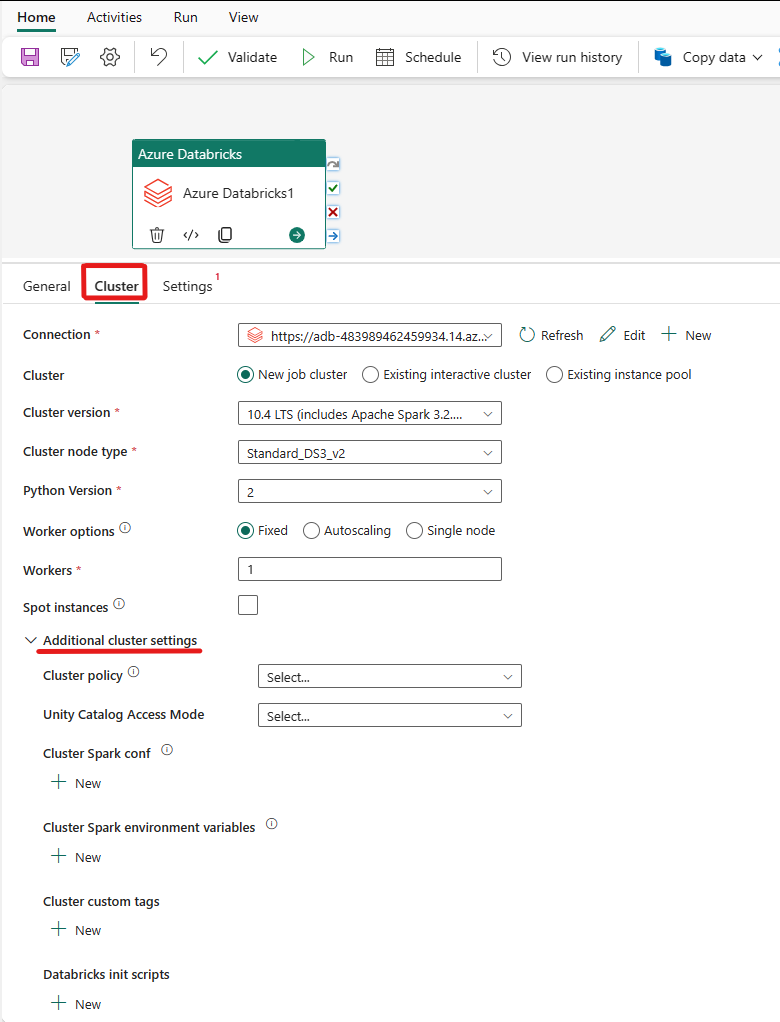
Azure Databricks-aktiviteten støtter nå også støtte for klyngepolicy og enhetskatalog.
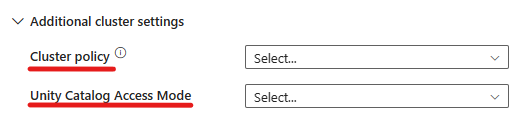
- Under avanserte innstillinger har du muligheten til å velge klyngepolicyen, slik at du kan angi hvilke klyngekonfigurasjoner som er tillatt.
- Under avanserte innstillinger har du også muligheten til å konfigurere enhetskatalogtilgangsmodus for ekstra sikkerhet. De tilgjengelige tilgangsmodustypene er:
- Tilgangsmodus for enkeltbrukere Denne modusen er utformet for scenarioer der hver klynge brukes av én enkelt bruker. Den sikrer at datatilgangen i klyngen bare er begrenset til denne brukeren. Denne modusen er nyttig for oppgaver som krever isolasjon og individuell databehandling.
- Delt tilgangsmodus I denne modusen har flere brukere tilgang til den samme klyngen. Den kombinerer Unity Catalogs datastyring med de eldre listene for tabelltilgangskontroll (ACLer). Denne modusen gir samarbeidsbasert datatilgang samtidig som styring og sikkerhetsprotokoller opprettholdes. Den har imidlertid visse begrensninger, for eksempel ikke støtte for Databricks Runtime ML, Spark-submit-jobber og bestemte Spark-API-er og UDF-er.
- Ingen tilgangsmodus Denne modusen deaktiverer samhandling med Unity-katalogen, noe som betyr at klynger ikke har tilgang til data som administreres av Unity Catalog. Denne modusen er nyttig for arbeidsbelastninger som ikke krever enhetskatalogens styringsfunksjoner.
Konfigurere innstillinger
Når du velger Innstillinger-fanen , kan du velge mellom tre alternativer som azure Databricks-typen du vil orkestrere.
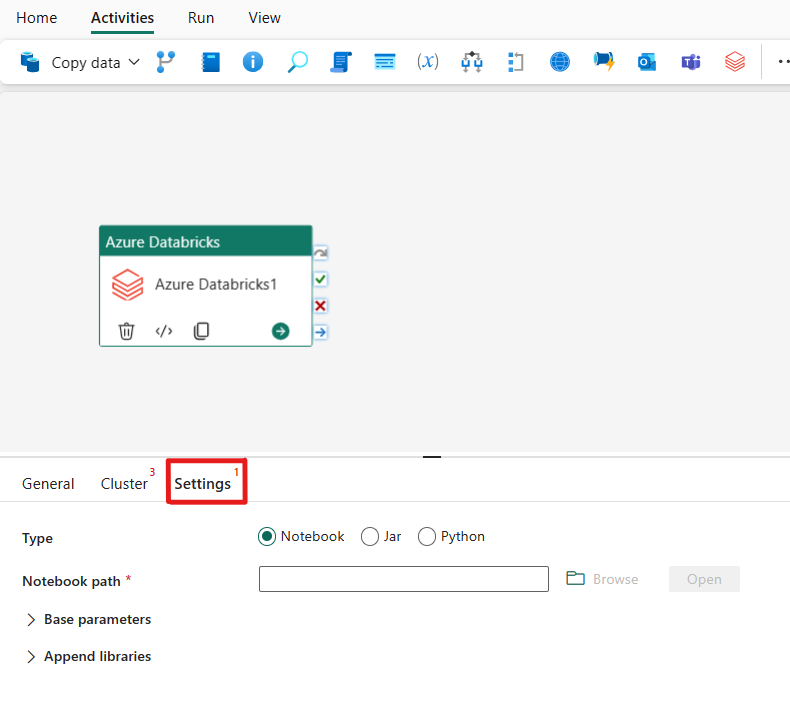
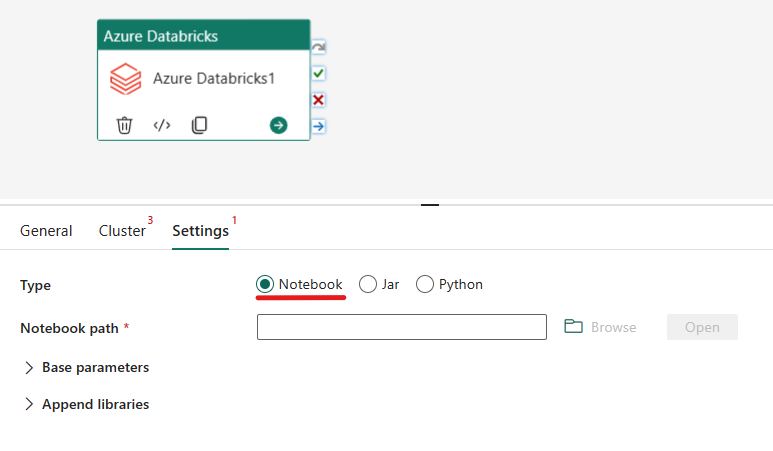
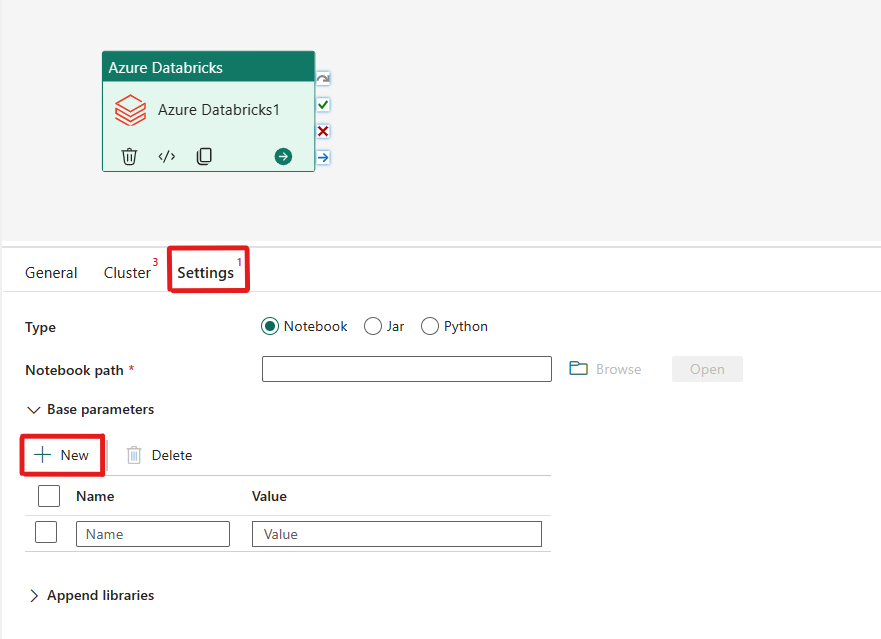
Orkestrer notatblokktypen i Azure Databricks-aktivitet:
Under Innstillinger-fanen kan du velge alternativknappen notatblokk for å kjøre en notatblokk. Du må angi notatblokkbanen som skal kjøres på Azure Databricks, valgfrie basisparametere som skal sendes til notatblokken, og eventuelle ekstra biblioteker som skal installeres på klyngen for å utføre jobben.
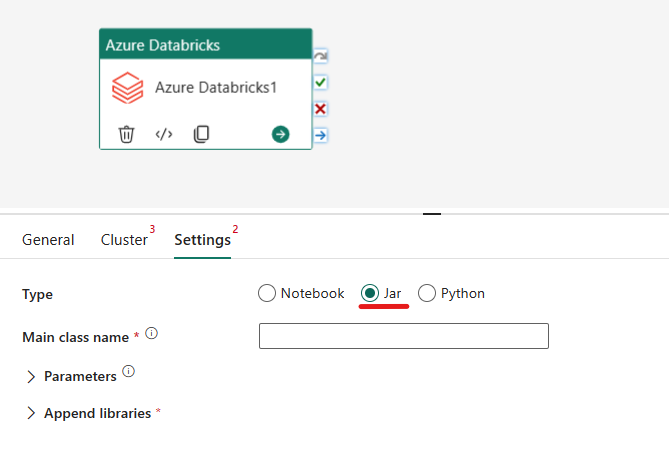
Orkestrering av Jar-typen i Azure Databricks-aktivitet:
Under Innstillinger-fanen kan du velge alternativknappen Jar for å kjøre en krukke. Du må angi klassenavnet som skal kjøres på Azure Databricks, valgfrie basisparametere som skal sendes til Jar, og eventuelle ekstra biblioteker som skal installeres på klyngen for å utføre jobben.
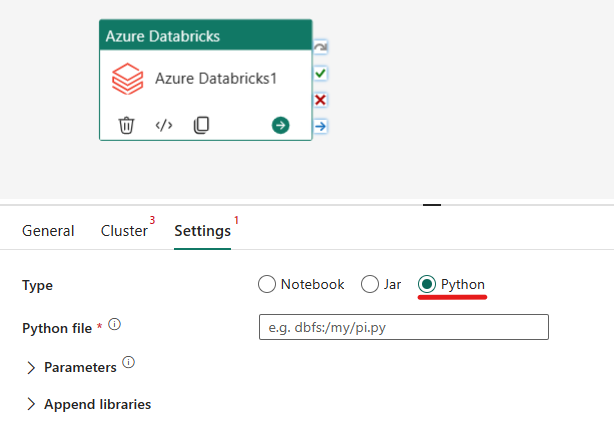
Orkestrer python-typen i Azure Databricks-aktivitet:
Under Innstillinger-fanen kan du velge Python-alternativknappen for å kjøre en Python-fil. Du må angi banen i Azure Databricks til en Python-fil som skal kjøres, valgfrie basisparametere som skal sendes, og eventuelle ekstra biblioteker som skal installeres på klyngen for å utføre jobben.
Støttede biblioteker for Azure Databricks-aktiviteten
I aktivitetsdefinisjonen over Databricks kan du angi disse bibliotektypene: jar, egg, whl, maven, pypi, cran.
Hvis du vil ha mer informasjon, kan du se dokumentasjonen for Databricks for bibliotektyper.
Sende parametere mellom Azure Databricks-aktivitet og -datasamlebånd
Du kan sende parametere til notatblokker ved hjelp av baseParameters-egenskapen i databricks-aktivitet.
I enkelte tilfeller må du kanskje sende tilbake bestemte verdier fra notatblokk tilbake til tjenesten, som kan brukes til kontrollflyt (betingede kontroller) i tjenesten eller brukes av nedstrømsaktiviteter (størrelsesgrensen er 2 MB).
I notatblokken, for eksempel, kan du kalle dbutils.notebook.exit("returnValue") og tilsvarende "returnValue" vil bli returnert til tjenesten.
Du kan bruke utdataene i tjenesten ved hjelp av uttrykk, for eksempel
@{activity('databricks activity name').output.runOutput}.
Lagre og kjøre eller planlegge datasamlebåndet
Når du har konfigurert andre aktiviteter som kreves for datasamlebåndet, bytter du til Hjem-fanen øverst i redigeringsprogrammet for datasamlebåndet, og velger lagre-knappen for å lagre datasamlebåndet. Velg Kjør for å kjøre den direkte, eller Planlegg for å planlegge den. Du kan også vise kjøreloggen her eller konfigurere andre innstillinger.
