Hva er lakehouse-skjemaer (forhåndsvisning)?
Lakehouse støtter oppretting av egendefinerte skjemaer. Med skjemaer kan du gruppere tabellene sammen for bedre dataoppdagelse, tilgangskontroll og mer.
Opprette et lakehouse-skjema
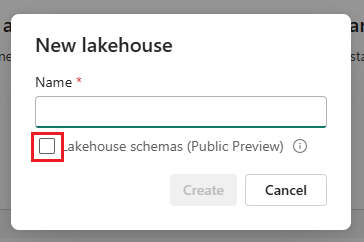
Hvis du vil aktivere skjemastøtte for lakehouse, merker du av i boksen ved siden av Lakehouse-skjemaer (offentlig forhåndsvisning) når du oppretter det.
Viktig
Arbeidsområdenavn må bare inneholde alfanumeriske tegn på grunn av forhåndsversjonsbegrensninger. Hvis spesialtegn brukes i arbeidsområdenavn, fungerer ikke noen av Lakehouse-funksjonene.
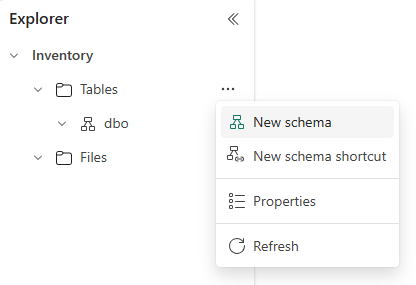
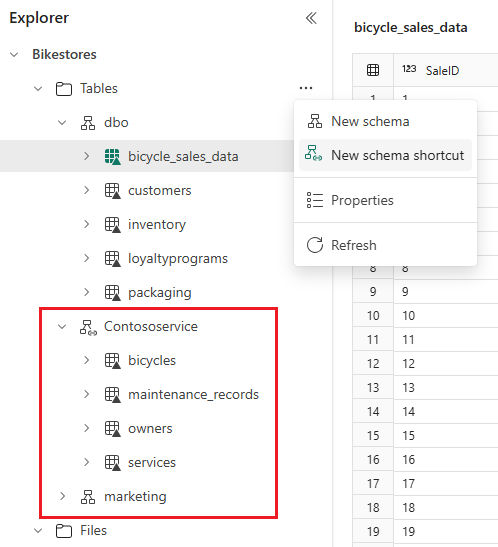
Når du har opprettet lakehouse, kan du finne et standardskjema kalt dbo under Tabeller. Dette skjemaet er alltid der og kan ikke endres eller fjernes. Hvis du vil opprette et nytt skjema, holder du pekeren over Tabeller, velger ...og velger Nytt skjema. Skriv inn skjemanavnet, og velg Opprett. Skjemaet vises under Tabeller i alfabetisk rekkefølge.
Lagre tabeller i lakehouse-skjemaer
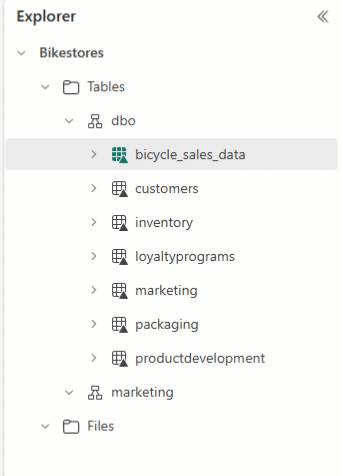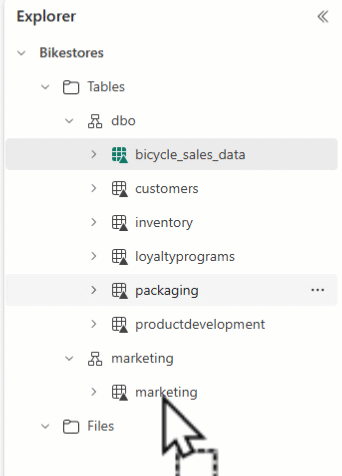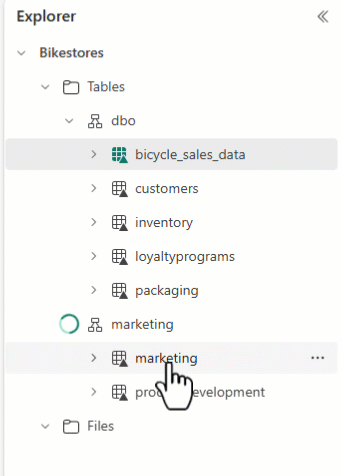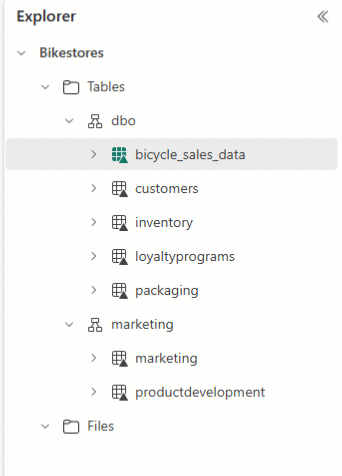
Du trenger et skjemanavn for å lagre en tabell i et skjema. Ellers går det til standard dbo-skjema .
df.write.mode("Overwrite").saveAsTable("contoso.sales")
Du kan bruke Lakehouse Explorer til å ordne tabellene og dra og slippe tabellnavn til forskjellige skjemaer.
Forsiktig!
Hvis du endrer tabellen, må du også oppdatere relaterte elementer som notatblokkkode eller dataflyter for å sikre at de er justert med riktig skjema.
Ta med flere tabeller med skjemasnarvei
Hvis du vil referere til flere Delta-tabeller fra andre Fabric Lakehouse eller ekstern lagring, kan du bruke skjemasnarvei som viser alle tabeller under det valgte skjemaet eller mappen. Eventuelle endringer i tabellene på kildeplasseringen vises også i skjemaet. Hvis du vil opprette en skjemasnarvei, holder du pekeren over tabeller, velger ...og velger Ny skjemasnarvei. Velg deretter et skjema på et annet lakehouse eller en mappe med Delta-tabeller på den eksterne lagringsplassen, for eksempel Azure Data Lake Storage (ADLS) Gen2. Dette oppretter et nytt skjema med de refererte tabellene.
Access Lakehouse-skjemaer for Power BI-rapportering
Hvis du vil lage den semantiske modellen, velger du bare tabellene du vil bruke. Tabeller kan være i forskjellige skjemaer. Hvis tabeller fra forskjellige skjemaer har samme navn, ser du tall ved siden av tabellnavn når du er i modellvisningen.
Lakehouse-skjemaer i notatblokk
Når du ser på et skjemaaktivert lakehouse i objektutforskeren for notatblokken, ser du at tabeller er i skjemaer. Du kan dra og slippe tabeller i en kodecelle og få en kodesnutt som refererer til skjemaet der tabellen er plassert. Bruk dette navneområdet til å referere til tabeller i koden: "workspace.lakehouse.schema.table". Hvis du utelater noen av elementene, bruker eksekutoren standardinnstillingen. Hvis du for eksempel bare gir tabellnavn, bruker det standardskjema (dbo) fra standard lakehouse for notatblokken.
Viktig
Hvis du vil bruke skjemaer i koden, må du kontrollere at standard lakehouse for notatblokken er skjemaaktivert.
Spark SQL-spørringer på tvers av arbeidsområder
Bruk navneområdet "workspace.lakehouse.schema.table" til å referere til tabeller i koden. På denne måten kan du koble sammen tabeller fra forskjellige arbeidsområder hvis brukeren som kjører koden, har tillatelse til å få tilgang til tabellene.
SELECT *
FROM operations.hr.hrm.employees as employees
INNER JOIN global.corporate.company.departments as departments
ON employees.deptno = departments.deptno;
Viktig
Kontroller at du bare kobler sammen tabeller fra lakehouses som har skjemaer aktivert. Sammenføyning av tabeller fra lakehouses som ikke har skjemaer aktivert, fungerer ikke.
Begrensninger for offentlig forhåndsvisning
Nedenfor oppførte funksjoner/funksjoner som ikke støttes, gjelder gjeldende utgivelse av offentlig forhåndsvisning. De vil bli løst i de kommende utgivelsene før generell tilgjengelighet.
| Funksjoner som ikke støttes/ funksjonalitet | Notater |
|---|---|
| Delt lakehouse | Bruk av arbeidsområdet i navneområdet for delte lakehouses vil ikke fungere, for eksempel wokrkspace.sharedlakehouse.schema.table. Brukeren må ha arbeidsområderolle for å kunne bruke arbeidsområdet i namaspace. |
| Skjema for ikke-delta, administrert tabell | Det støttes ikke å hente skjema for administrerte tabeller som ikke er deltaformaterte tabeller (for eksempel CSV). Hvis du utvider disse tabellene i lakehouse Explorer, vises ingen skjemainformasjon i UX. |
| Eksterne Spark-tabeller | Eksterne Spark-tabelloperasjoner (for eksempel oppdagelse, henting av skjema osv.) støttes ikke. Disse tabellene er ikke identifisert i UX. |
| Offentlig API | Offentlige API-er (listetabeller, lasttabell, eksponering av standardschema-utvidet egenskap osv.) støttes ikke for skjemaaktivert Lakehouse. Eksisterende offentlige API-er kalt på et skjemaaktivert Lakehouse resulterer i en feil. |
| Tabellvedlikehold | Støttes ikke. |
| Oppdater tabellegenskaper | Støttes ikke. |
| Arbeidsområdenavn som inneholder spesialtegn | Arbeidsområde med spesialtegn (for eksempel mellomrom, skråstreker) støttes ikke. Det vises en brukerfeil. |
| Spark-visninger | Støttes ikke. |
| Bikubespesifikke funksjoner | Støttes ikke. |
| Spark.catalog API | Støttes ikke. Bruk Spark SQL i stedet. |
USE <schemaName> |
Fungerer ikke på tvers av arbeidsområder, men støttes i samme arbeidsområde. |
| Migrering | Overføring av eksisterende ikke-skjema Lakehouses til skjemabaserte Lakehouses støttes ikke. |