Fakturerings- og utnyttelsesrapportering for Apache Spark i Microsoft Fabric
Gjelder for:✅ Dataingeniør ing og datavitenskap i Microsoft Fabric
Denne artikkelen forklarer databehandlingsutnyttelsen og rapporteringen for ApacheSpark som driver Fabric Dataingeniør ing and Science-arbeidsbelastningene i Microsoft Fabric. Databehandlingsutnyttelsen inkluderer lakehouse-operasjoner som forhåndsversjon av tabeller, belastning til delta, notatblokkkjøringer fra grensesnittet, planlagte kjøringer, kjøringer utløst av notatblokktrinn i datasamlebånd og Apache Spark-jobbdefinisjonskjøringer.
I likhet med andre opplevelser i Microsoft Fabric bruker Dataingeniør ing også kapasiteten som er knyttet til et arbeidsområde, til å kjøre denne jobben, og de totale kapasitetskostnadene vises i Azure-portalen under Microsoft Cost Management-abonnementet. Hvis du vil ha mer informasjon om fakturering av stoff, kan du se Forstå Azure-fakturaen på en Stoff-kapasitet.
Stoffkapasitet
Du som bruker kan kjøpe en Fabric-kapasitet fra Azure ved å angi ved hjelp av et Azure-abonnement. Størrelsen på kapasiteten bestemmer mengden databehandlingskraft som er tilgjengelig. For Apache Spark for Fabric oversettes hver CU kjøpt til 2 Apache Spark VCores. Hvis du for eksempel kjøper en Fabric-kapasitet F128, oversettes dette til 256 SparkVCores. En Fabric-kapasitet deles på tvers av alle arbeidsområdene som er lagt til, og der den totale Apache Spark-databehandlingen som tillates, deles på tvers av alle jobbene som sendes inn fra alle arbeidsområdene som er knyttet til en kapasitet. Hvis du vil forstå om de ulike SKU-ene, kjernetildeling og begrensning på Spark, kan du se Samtidighetsgrenser og kø i Apache Spark for Microsoft Fabric.
Spark-databehandlingskonfigurasjon og kjøpt kapasitet
Apache Spark compute for Fabric tilbyr to alternativer når det gjelder beregningskonfigurasjon.
Startutvalg: Disse standardutvalgene er raske og enkle måter å bruke Spark på Microsoft Fabric-plattformen på i løpet av sekunder. Du kan bruke Spark-økter umiddelbart, i stedet for å vente på at Spark skal konfigurere nodene for deg, noe som hjelper deg med å gjøre mer med data og få innsikt raskere. Når det gjelder fakturering og kapasitetsforbruk, belastes du når du begynner å utføre notatblokken eller Spark-jobbdefinisjonen eller lakehouse-operasjonen. Du belastes ikke for tiden klyngene er inaktive i utvalget.
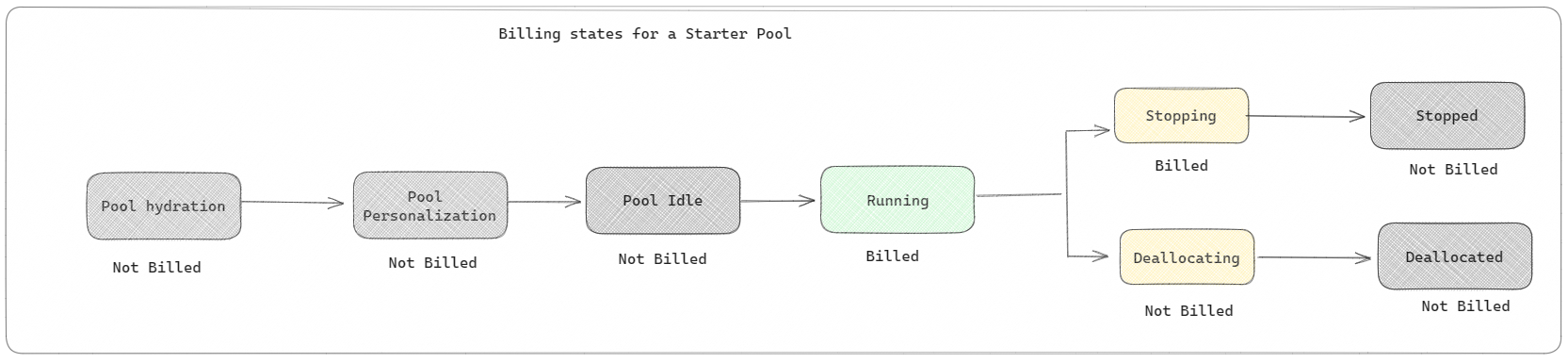
Hvis du for eksempel sender en notatblokkjobb til et startutvalg, faktureres du bare for tidsperioden der notatblokkøkten er aktiv. Den fakturerte tiden inkluderer ikke inaktiv tid eller tiden det tar å tilpasse økten med Spark-konteksten. Hvis du vil forstå mer om hvordan du konfigurerer starterutvalg basert på den kjøpte SKU-en for stoffkapasitet, kan du gå til Konfigurer starterutvalg basert på stoffkapasitet
Spark-utvalg: Dette er egendefinerte utvalg, der du får tilpasse størrelsen på ressursene du trenger for dataanalyseoppgavene. Du kan gi Spark-utvalget et navn, og velge hvor mange og hvor store nodene (maskinene som gjør arbeidet) er. Du kan også fortelle Spark hvordan du justerer antall noder avhengig av hvor mye arbeid du har. Det er gratis å opprette et Spark-basseng. du betaler bare når du kjører en Spark-jobb på bassenget, og deretter setter Spark opp nodene for deg.
- Størrelsen og antall noder du kan ha i det egendefinerte Spark-utvalget, avhenger av Microsoft Fabric-kapasiteten. Du kan bruke disse Spark VCores til å opprette noder av forskjellige størrelser for det egendefinerte Spark-utvalget, så lenge det totale antallet Spark VCores ikke overskrider 128.
- Spark-bassenger faktureres som startbassenger; du betaler ikke for de egendefinerte Spark-bassengene du har opprettet, med mindre du har opprettet en aktiv Spark-økt for å kjøre en notatblokk eller spark-jobbdefinisjon. Du faktureres bare for varigheten av jobbkjøringene. Du faktureres ikke for faser som oppretting av klynge og avtaleplassering etter at jobben er fullført.
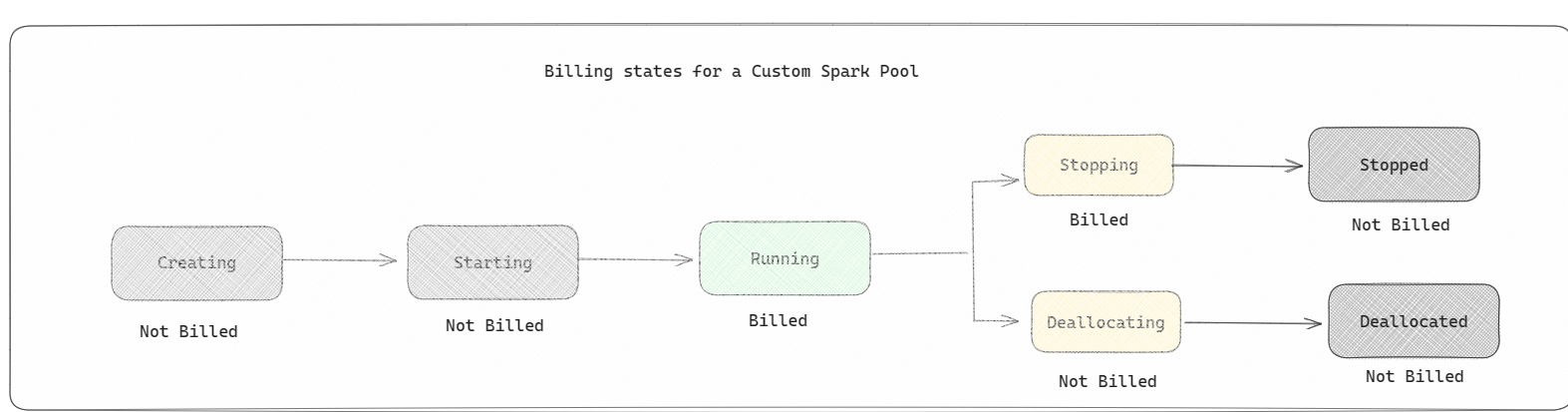
Hvis du for eksempel sender inn en notatblokkjobb til et egendefinert Spark-utvalg, blir du bare belastet for tidsperioden når økten er aktiv. Faktureringen for notatblokkøkten stopper når Spark-økten er stoppet eller utløpt. Du belastes ikke for tiden det tar å skaffe klyngeforekomster fra skyen, eller for tiden det tar å initialisere Spark-konteksten. Hvis du vil forstå mer om hvordan du konfigurerer Spark-bassenger basert på den kjøpte SKU-en for stoffkapasitet, kan du gå til Konfigurering av bassenger basert på stoffkapasitet


Merk
Standard utløpsperiode for økt for Startutvalg og Spark Pools som du oppretter, er satt til 20 minutter. Hvis du ikke bruker Spark-bassenget på 2 minutter etter at økten utløper, blir Spark-bassenget deallocated. Hvis du vil stoppe økten og faktureringen etter at du har fullført kjøringen av notatblokken før utløpsperioden for økten, kan du enten klikke stoppøktknappen fra hjemmesidemenyen for notatblokkene eller gå til siden for overvåkingshuben og stoppe økten der.
Rapportering av bruk av spark-databehandling
Microsoft Fabric Capacity Metrics-appen gir synlighet i kapasitetsbruk for alle fabric-arbeidsbelastninger på ett sted. Den brukes av kapasitetsadministratorer til å overvåke ytelsen til arbeidsbelastninger og bruken, sammenlignet med kjøpt kapasitet.
Når du har installert appen, velger du elementtypen Notatblokk, Lakehouse, Spark Job Definition fra rullegardinlisten Velg element: Diagrammet med flere metriske bånd kan nå justeres til en ønsket tidsramme for å forstå bruken fra alle disse valgte elementene.
Alle Spark-relaterte operasjoner klassifiseres som bakgrunnsoperasjoner. Kapasitetsforbruk fra Spark vises under en notatblokk, en Spark-jobbdefinisjon eller et lakehouse, og aggregeres etter operasjonsnavn og element. Hvis du for eksempel kjører en notatblokkjobb, kan du se notatblokken kjøre, CUs som brukes av notatblokken (Totalt Spark VCores/2 som 1 CU gir 2 Spark VCores), varighet jobben har tatt i rapporten.
 Hvis du vil forstå mer om bruksrapportering for Spark-kapasitet, kan du se Overvåke apache Spark-kapasitetsforbruk
Hvis du vil forstå mer om bruksrapportering for Spark-kapasitet, kan du se Overvåke apache Spark-kapasitetsforbruk
Eksempel på fakturering
Tenk deg følgende scenario:
Det er en kapasitet C1 som er vert for et Fabric Workspace W1, og dette arbeidsområdet inneholder Lakehouse LH1 og Notebook NB1.
- Alle Spark-operasjoner som notatblokken (NB1) eller lakehouse(LH1) utfører, rapporteres mot kapasitet C1.
Utvide dette eksemplet til et scenario der det finnes en annen kapasitet C2 som er vert for et Fabric Workspace W2, og lar oss si at dette arbeidsområdet inneholder en Spark-jobbdefinisjon (SJD1) og Lakehouse (LH2).
- Hvis Spark Job Definition (SDJ2) fra Workspace (W2) leser data fra lakehouse (LH1), rapporteres bruken mot kapasitet C2 som er knyttet til arbeidsområdet (W2) som er vert for elementet.
- Hvis notatblokken (NB1) utfører en leseoperasjon fra Lakehouse(LH2), rapporteres kapasitetsforbruket mot kapasitet C1 som driver arbeidsområdet W1 som er vert for notatblokkelementet.