Opprett og administrer Jobbdefinisjoner for Apache Spark i Visual Studio Code
Visual Studio (VS)-kodeutvidelsen for Synapse støtter curd (opprette, oppdatere, lese og slette) Spark-jobbdefinisjonsoperasjoner i Fabric. Når du har opprettet en Spark-jobbdefinisjon, kan du laste opp flere refererte biblioteker, sende inn en forespørsel om å kjøre Spark-jobbdefinisjonen og kontrollere kjøreloggen.
Opprett en Spark-jobbdefinisjon
Slik oppretter du en ny Spark-jobbdefinisjon:
Velg alternativet Opprett Spark-jobbdefinisjon i VS Code Explorer.

Skriv inn de opprinnelige nødvendige feltene: navn, referert lakehouse og standard lakehouse.
Forespørselsprosessene og navnet på den nyopprettede Spark-jobbdefinisjonen vises under rotnoden Spark Job Definition i VS Code Explorer. Under navnenoden sparkjobbdefinisjon ser du tre undernoder:
- Filer: Liste over hoveddefinisjonsfilen og andre refererte biblioteker. Du kan laste opp nye filer fra denne listen.
- Lakehouse: Liste over alle lakehouses referert av denne Spark jobb definisjon. Standard lakehouse er merket i listen, og du kan få tilgang til den via den relative banen
Files/…, Tables/…. - Kjør: Liste over kjøreloggen for denne Spark-jobbdefinisjonen og jobbstatusen for hver kjøring.
Laste opp en hoveddefinisjonsfil til et referert bibliotek
Hvis du vil laste opp eller overskrive hoveddefinisjonsfilen, velger du alternativet Legg til hovedfil .
Hvis du vil laste opp bibliotekfilen som hoveddefinisjonsfilen refererer til, velger du alternativet Legg til Lib-fil .
Når du har lastet opp en fil, kan du overstyre den ved å klikke oppdater fil-alternativet og laste opp en ny fil, eller du kan slette filen via alternativet Slett .
Send inn en kjøreforespørsel
Slik sender du inn en forespørsel om å kjøre Spark-jobbdefinisjonen fra VS Code:
Velg alternativet Kjør Spark-jobb fra alternativene til høyre for navnet på Spark-jobbdefinisjonen du vil kjøre.

Når du har sendt forespørselen, vises et nytt Apache Spark-program i Kjører-noden i Explorer-listen. Du kan avbryte kjørejobben ved å velge alternativet Avbryt Spark-jobb .
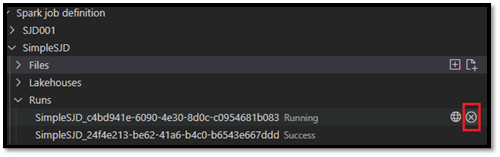
Åpne en Spark-jobbdefinisjon i Fabric-portalen
Du kan åpne redigeringssiden for Spark-jobbdefinisjon i Stoff-portalen ved å velge alternativet Åpne i nettleser .
Du kan også velge Åpne i nettleser ved siden av en fullført kjøring for å se detaljskjermsiden for kjøringen.

Feilsøk spark jobbdefinisjonskildekode (Python)
Hvis Spark-jobbdefinisjonen er opprettet med PySpark (Python), kan du laste ned .py skriptet til hoveddefinisjonsfilen og den refererte filen, og feilsøke kildeskriptet i VS Code.
Hvis du vil laste ned kildekoden, velger du alternativet Debug Spark Job Definition til høyre for Spark-jobbdefinisjonen.

Når nedlastingen er fullført, åpnes mappen for kildekoden automatisk.
Velg alternativet Klarer forfatterne når du blir bedt om det. (Dette alternativet vises bare første gang du åpner mappen. Hvis du ikke velger dette alternativet, kan du ikke feilsøke eller kjøre kildeskriptet. Hvis du vil ha mer informasjon, kan du se Sikkerhet for klarering av Visual Studio Code Workspace.)
Hvis du har lastet ned kildekoden før, blir du bedt om å bekrefte at du vil overskrive den lokale versjonen med den nye nedlastingen.
Merk
I rotmappen for kildeskriptet oppretter systemet en undermappe med navnet conf. I denne mappen inneholder en fil med navnet lighter-config.json noen systemmetadata som kreves for ekstern kjøring. Ikke gjør endringer i den.
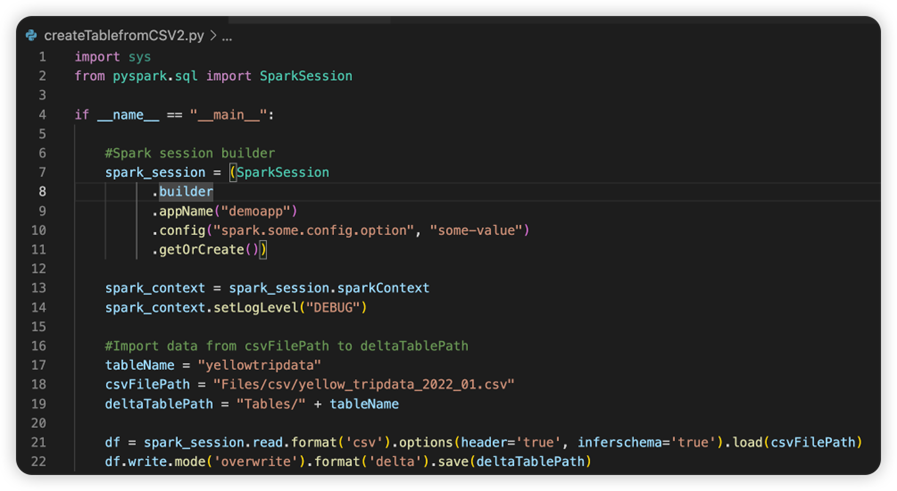
Filen med navnet sparkconf.py inneholder en kodesnutt som du må legge til for å konfigurere SparkConf-objektet . Hvis du vil aktivere den eksterne feilsøkingen , må du kontrollere at SparkConf-objektet er riktig konfigurert. Bildet nedenfor viser den opprinnelige versjonen av kildekoden.
Det neste bildet er den oppdaterte kildekoden etter at du har kopiert og limt inn snutten.
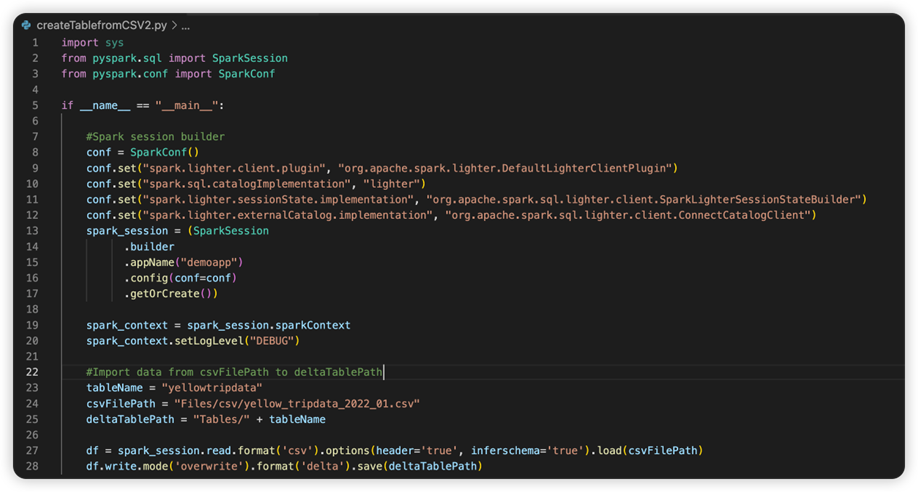
Når du har oppdatert kildekoden med den nødvendige konfigurasjonen, må du velge riktig Python-tolk. Pass på at du velger den som er installert fra synapse-spark-kernel conda-miljøet.
Rediger egenskaper for Spark-jobbdefinisjon
Du kan redigere detaljegenskapene for Spark-jobbdefinisjoner, for eksempel kommandolinjeargumenter.
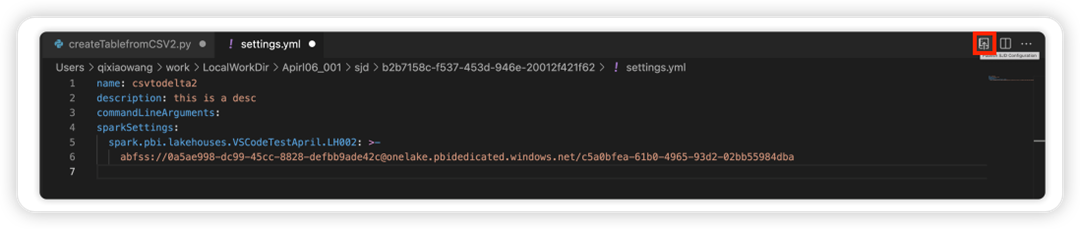
Velg alternativet Oppdater SJD-konfigurasjon for å åpne en settings.yml fil. De eksisterende egenskapene fyller ut innholdet i denne filen.
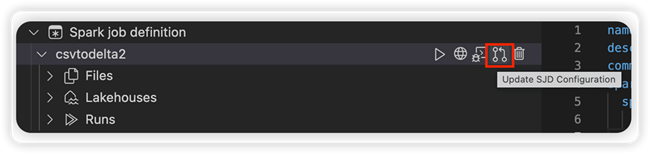
Oppdater og lagre .yml filen.
Velg alternativet Publiser SJD-egenskap øverst til høyre for å synkronisere endringen tilbake til det eksterne arbeidsområdet.