Fjerne duplikater i hver tabell for dataforening
Deduplisering finner og fjerner like poster for en kunde fra en kildetabell, slik at hver kunde representeres av én enkelt rad i hver tabell. Hver tabell dedupliseres separat ved hjelp av regler for å identifisere oppføringene for en gitt kunde.
Hver dedupliseringsregel kjøres mot hver rad. Hvis den første regelen samsvarer med rad 1 og 2, og regel 2 samsvarer med rad 2 og 3, er rad 1, 2 og 3 samsvarende. Når samsvarende rader blir funnet, velges en vinnerrad som skal representere kunden basert på innstillingene for sammenslåing (Mest fylte, Nyeste eller Minst nylig). Bruk Avansert-alternativet til å opprette en vinnerrad ved å velge felter fra de ulike samsvarende radene, for eksempel den nyeste e-postmeldingen, men den mest utfylte adressen.
Customer Insights - Data utfører automatisk følgende handlinger:
- Dedupliser poster med samme primærnøkkelverdi, og velg den første raden i datasettet som vinneren.
- Dedupliser poster ved hjelp av samsvarsreglene som er definert for tabellen når rader mellom tabeller samsvares.
Definer dedupliseringsregler
En god regel identifiserer en unik kunde. Vurder dataene dine. Det kan være nok til å identifisere kunder basert på et felt, for eksempel e-post. Hvis du vil skille mellom kunder som deler en e-post, kan du imidlertid velge å ha en regel med to betingelser som samsvarer med Email + FirstName. Hvis du vil ha mer informasjon, kan du se Anbefalte fremgangsmåter for deduplisering.
Velg en tabell på siden Dedupliseringsregler, og velg Legg til regel for å definere dedupliseringsreglene.
Tips
Hvis du supplerte tabeller på datakildenivå for å forbedre foreningsresultatene, velger du Bruk supplerte tabeller på toppen av siden. Hvis du vil ha mer informasjon, kan du se Supplering for datakilder.
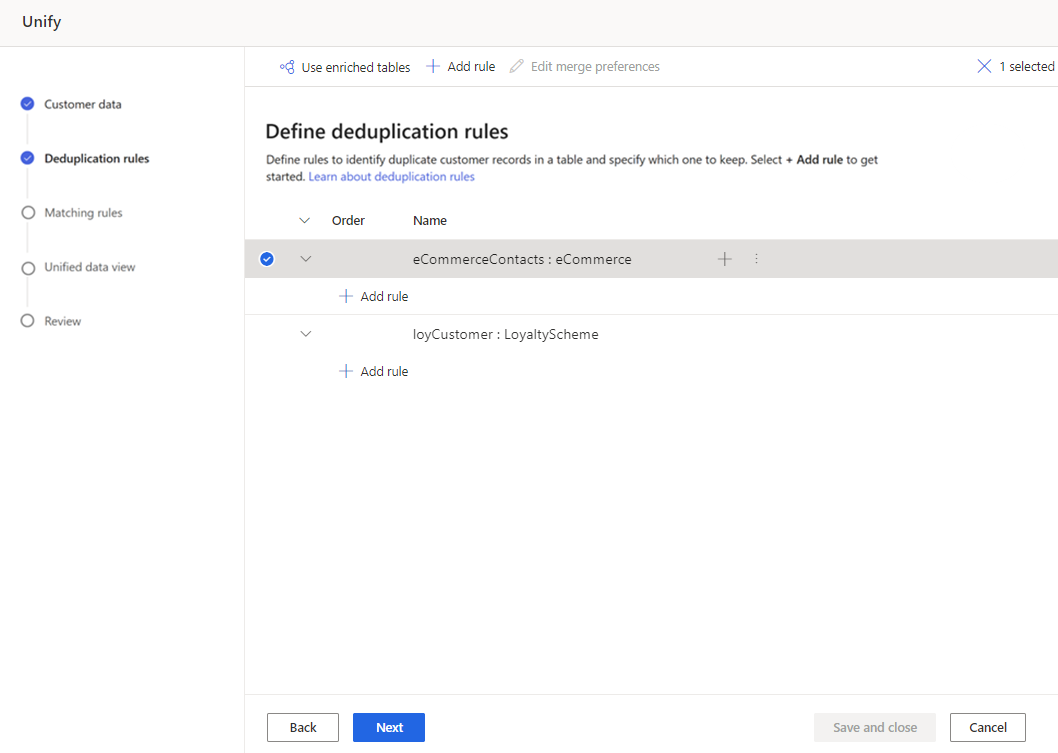
Angi følgende informasjon i ruten Legg til regel:
Velg felt: Velg fra listen over tilgjengelige felter fra tabellen du vil søke etter duplikater for. Velg felter som sannsynligvis er unike for hver enkelt kunde. For eksempel en e-postadresse eller en kombinasjon av navn, poststed og telefonnummer.
Normaliser: Velg normaliseringsalternativer for kolonnen. Normalisering påvirker bare det samsvarstrinnet og endrer ikke dataene.
Normalisering Eksempler Tall Konverterer mange Unicode-symboler som representerer tall, til enkle tall.
Eksempler: ❽ og Ⅷ blir begge normalisert til tallet 8.
Obs! Symbolene må være kodet i Unicode Point Format.Symboler Fjerner symboler og spesialtegn.
Eksempler: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ]Tekst til små bokstaver Konverterer store bokstaver til små bokstaver.
Eksempel: «DETTE Er eT EKSempeL» konverteres til «dette er et eksempel»Type – Telefon Konverterer telefoner i ulike formater til sifre og tar hensyn til variasjoner i hvordan landskoder og utvidelser presenteres. Symboler og mellomrom ignoreres. Innledende 0-sifre i landskoder ignoreres, og +1 og +01 samsvarer. Utvidelser betegnet med et prefiks med bokstaver ignoreres (X 123). Den normaliserte landskoden er signifikant, så en telefon med landskode samsvarer ikke med en telefon uten landskode.
Eksempel: +01 425.555.1212 samsvarer med 1 (425) 555-1212
+01 425.555.1212 samsvarer ikke med (425) 555-1212Type – Navn Konverterer over 500 vanlige navnevarianter og titler.
Eksempler: debby -> deborah prof og professor -> Prof.Type – Adresse Konverterer vanlige deler av adresser
Eksempler: street -> st og northwest -> nwType – Organisasjon Fjerner rundt 50 «støyord» fra firmanavn, for eksempel «co», «corp», «corporation» og «ltd». Unicode til ASCII Konverterer Unicode-tegn til tilsvarende ASCII-bokstavtegn
Eksempel: Tegnene à, á, â, À, Á, Â, Ã, Ä, Ⓐ, og A konverteres alle til a.Mellomrom Fjerner alle mellomrom Aliastilordning Lar deg laste opp en egendefinert liste over strengpar som deretter kan brukes til å indikere strenger som alltid bør betraktes som et eksakt samsvar.
Bruk aliastildeling når du har spesifikke dataeksempler du mener bør samsvare, og ikke blir samsvart ved hjelp av et av de andre normaliseringsmønstrene.
Eksempel: Scott og Scooter eller MSFT og Microsoft.Egendefinert utelatelse Lar deg laste opp en egendefinert liste over strenger som deretter kan brukes til å indikere strenger som aldri skal samsvares.
Egendefinert utelatelse er nyttig når du har data med vanlige verdier som skal ignoreres, for eksempel et eksempeltelefonnummer eller en eksempel-e-postadresse.
Eksempel: Samsvar aldri telefonen 555-1212, eller test@contoso.com
Presisjon: Angir presisjonsnivået. Presisjon brukes for nøyaktig treff og tilnærmet samsvar og fastsetter hvor nær to strenger må være for å bli betraktet som et treff.
- Grunnleggende: Velg mellom Lav (30 %), Middels (60 %), Høy (80 %) og Nøyaktig (100 %). Velg Eksakt for å samsvare bare med oppføringer som samsvarer med 100 prosent.
- Egendefinert: Angi en prosentandel som oppføringer må samsvare med. Systemet samsvarer bare med oppføringer som passerer denne terskelen.
Navn: Navn for regelen.
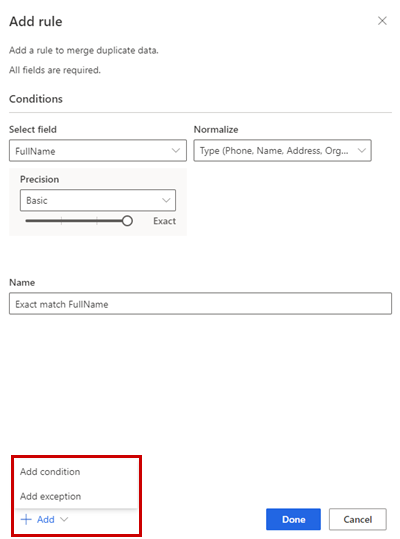
Du kan eventuelt velge Legg til>Legg til betingelse for å legge til flere betingelser i regelen. Betingelser er koblet til en logisk OG-operator og kjøres derfor bare hvis alle betingelser er oppfylt.
Legg til>Legg til unntak for å legge til unntak i regelen. Unntak brukes til å løse sjeldne tilfeller av falske positive og falske negativer.
Velg Ferdig for å opprette regelen.
Du kan eventuelt legge til flere regler.

Velg innstillinger for sammenslåing
Når regler kjøres og dupliserte oppføringer identifiseres for en kunde, velges en "vinnerrad" basert på retningslinjene for sammenslåing. Vinnerraden representerer kunden i det neste samlingstrinnet som samsvarer med oppføringer mellom tabeller. Data i radene som ikke er vinnere ("alternative rader") brukes i samlingstrinnet Samsvarsregler for å samsvare oppføringer fra andre tabeller med vinnerraden. Denne fremgangsmåten forbedrer samsvarende resultater ved å la informasjon som tidligere telefonnumre bidra til å identifisere samsvarende oppføringer. Vinnerraden kan konfigureres til å være den mest utfylte, nyeste eller minst nylige av de dupliserte postene som blir funnet.
Velg en tabell og deretter Rediger fletteinnstillinger. Ruten Innstillinger for sammenslåing vises.
Velg et av tre alternativer for å bestemme hvilken oppføring som skal beholdes hvis det blir funnet et duplikat:
- Mest fylte: Identifiserer oppføringen med de mest utfylte kolonnene som vinneroppføringen. Dette er standardalternativet for sammenslåing.
- Nyeste: Identifiserer vinneroppføringen, basert på den nyeste oppføringen. Krever en dato eller et numerisk felt for å definere den nyeste.
- Minst nylig: Identifiserer vinneroppføringen, basert på den minst nye oppføringen. Krever en dato eller et numerisk felt for å definere den nyeste.
Ved uavgjort er vinneroppføringen den med MAX(PK) eller den største primærnøkkelverdien.
Hvis du eventuelt vil definere fletteinnstillinger for individuelle kolonner for en tabell, velger du Avansert nederst i ruten. Du kan for eksempel velge å beholde den nyeste e-postadressen OG den mest fullstendige adressen fra forskjellige oppføringer. Utvid tabellen for å vise alle kolonnene, og definer hvilket alternativ som skal brukes for enkeltkolonner. Hvis du velger et besøksbasert alternativ, må du også angi et dato-/klokkeslettfelt som definerer ventetiden.
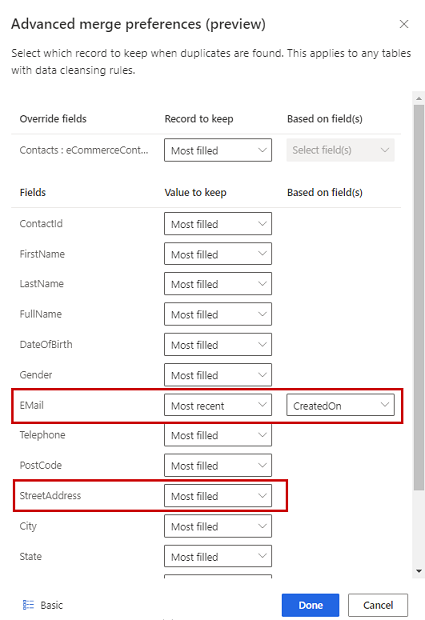
Velg Ferdig for å ta i bruk fletteinnstillingene.
Når du har definert dedupliseringsreglene og fletteinnstillingene, velger du Neste.