Anbefalte fremgangsmåter for datasamling
Når du definerer regler for å samle dataene i en kundeprofil, kan du vurdere disse anbefalte fremgangsmåtene:
Balanser tiden til å samle kontra oppnå fullstendig samsvar. Hvis du prøver å få med alle mulige treff, fører dette til mange regler og at samlingen tar lang tid.
Legg til regler fortløpende, og spor resultatene. Fjern regler som ikke forbedrer samsvarsresultatet.
Dedupliser hver tabell slik at hver kunde representeres i én rad.
Bruk normalisering til å standardisere variasjoner i hvordan data ble registrert, for eksempel Street kontra St kontra St. kontra st.
Bruk tilnærmet samsvar strategisk til å rette skrivefeil og feil som bob@contoso.com og bob@contoso.cm. Tilnærmet samsvar tar lengre tid å kjøre enn nøyaktige treff. Test alltid for å se om den ekstra tiden brukt på tilnærmet samsvar er verdt den ekstra samsvarsraten.
Begrens omfanget av treff med nøyaktig treff. Sørg for at alle regler med tilnærmede betingelser har minst én betingelse for nøyaktig treff.
Ikke samsvar kolonner som inneholder data som gjentas ofte. Kontroller at kolonner med tilnærmet samsvar ikke har verdier som gjentas ofte, for eksempel standardverdien «Fornavn» i et skjema.
Samlingsytelse
Det tar tid å kjøre hver regel. Mønstre, for eksempel sammenligning av hver tabell med alle andre tabeller eller forsøk på å få med alle mulige oppføringstreff, kan føre til lang behandlingstid ved samling. De returnerer også få treff i forhold til en plan som sammenligner hver tabell med en basistabell.
Den beste tilnærmingen er å begynne med et grunnleggende sett med regler du vet er nødvendig, for eksempel sammenligning av hver tabell med primærtabellen. Primærtabellen skal være tabellen med de mest fullstendige og nøyaktige dataene. Denne tabellen skal sorteres øverst i samlingstrinnet Samsvarsregler.
Legg til flere regler fortløpende, og se hvor lang tid det tar å kjøre endringene, og om resultatene forbedres. Gå til Innstillinger>System>Status, og velg Samsvar for å se hvor lang tid deduplisering og samsvar tok for hver samlingskjøring.
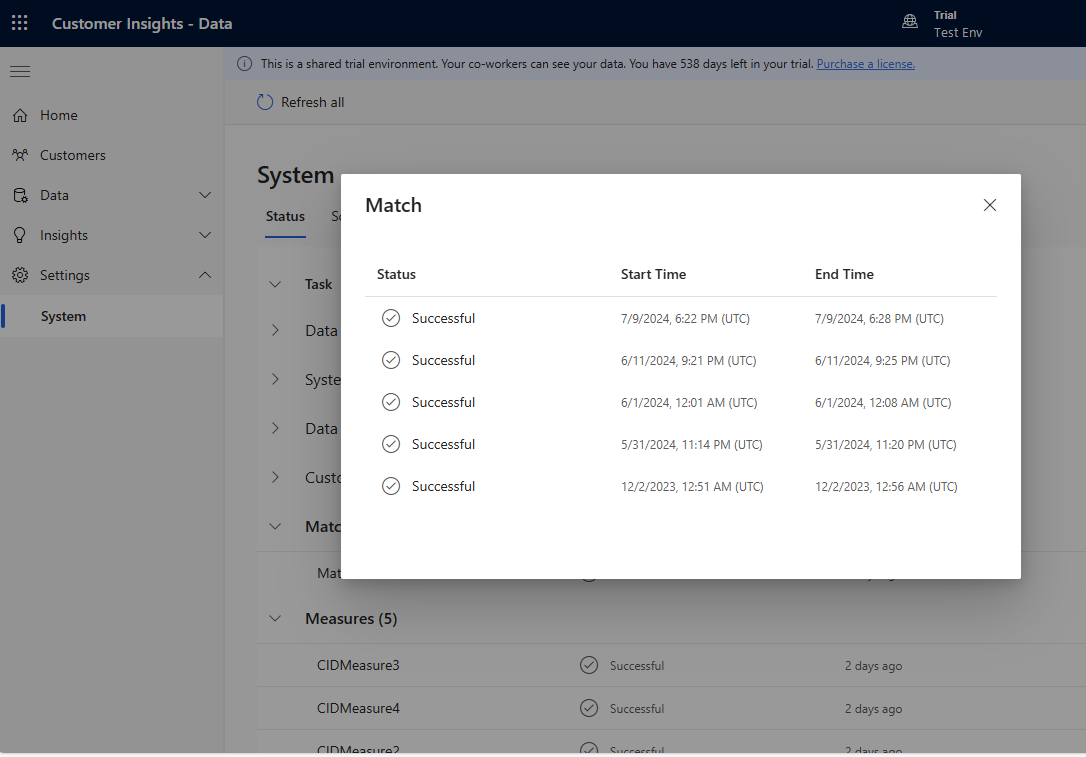
Vis regelstatistikken på sidene Dedupliseringsregler og Samsvarsregler for å se om antallet Unike oppføringer endres. Hvis en ny regel samsvarer enkelte oppføringer og det unike oppføringsantallet ikke endres, identifiserer en tidligere regel disse samsvarene.
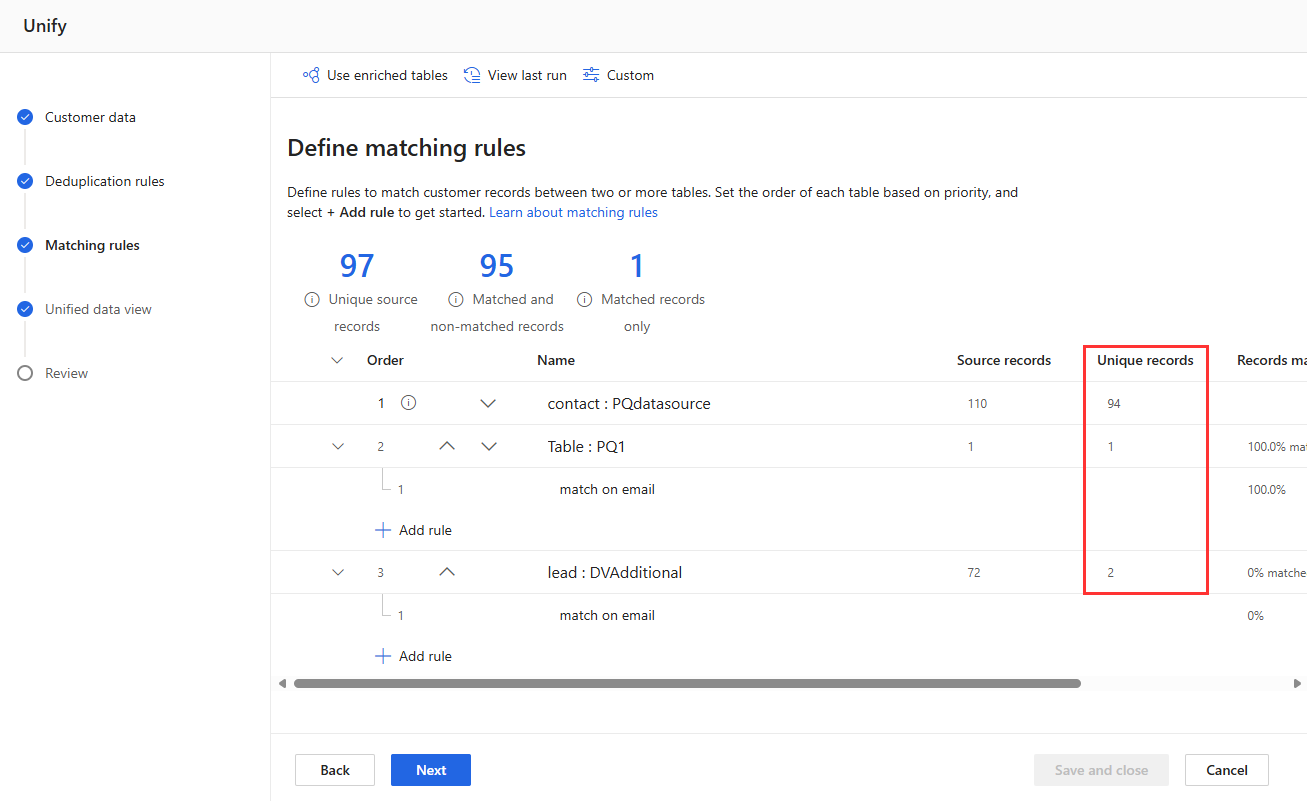
Kundedata
I Kundedata-trinnet:
Utelat kolonner som ikke er nødvendige for samsvarende regler, eller som du ikke vil ha med i den endelige kundeprofilen.
Se gjennom kolonnebeskrivelser valgt av intelligent tilordning.
Ikke alle kolonner trenger å være tilordnet. Ved å tilordne vanlige kolonner, for eksempel e-post- og adressefelter, kan Customer Insights gjøre nedstrømsprosesser enklere, men kolonner med en unik ID eller et unikt formål for virksomheten kan forbli utilordnet.
Deduplisering
Bruk dedupliseringsregler til å fjerne dupliserte kundeoppføringer i en tabell, slik at én rad i hver tabell representerer hver kunde. En god regel identifiserer en unik kunde.
I dette enkle eksemplet deler oppføring 1, 2 og 3 enten en e-postadresse eller et telefonnummer og representerer samme person.
| ID | Navn | Telefonnummer | E-postadresse |
|---|---|---|---|
| 1 | Person 1 | (425) 555-1111 | AAA@A.com |
| 2 | Person 1 | (425) 555-1111 | BBB@B.com |
| 3 | Person 1 | (425) 555-2222 | BBB@B.com |
| 4 | Person 2 | (206) 555-9999 | Person2@contoso.com |
Vi ønsker ikke å samsvare med bare navn, siden det samsvarer med forskjellige personer med samme navn.
Opprett regel 1 ved hjelp av Navn og Telefonnummer, som samsvarer med oppføring 1 og 2.
Opprett regel 2 ved hjelp av Navn og E-postadresse, som samsvarer med oppføring 2 og 3.
Kombinasjonen av Regel 1 og Regel 2 oppretter én enkelt samsvarsgruppe fordi de deler oppføring 2.
Du bestemmer antall regler og betingelser som unikt identifiserer kundene. De nøyaktige reglene avhenger av dataene du har tilgjengelige for samsvar, kvaliteten på dataene og hvor omfattende du vil at dedupliseringsprosessen skal være.
Normalisering
Bruk normalisering til å standardisere data for å oppnå bedre samsvar. Normalisering fungerer bra ved store datasett.
De normaliserte dataene brukes bare til sammenligningsformål for å samsvare kunderegistre mer effektivt. Dataene endres ikke i de endelige utdataene for den enhetlige kundeprofilen.
Nøyaktig treff
Bruk presisjon til å fastsette hvor nær to strenger skal være for å betraktes som et treff. Innstillingen for standard presisjon krever et nøyaktig samsvar. Alle andre verdier muliggjør tilnærmet samsvar for denne betingelsen.
Presisjon kan settes til lav (30 % samsvar), middels (60 % samsvar) og høy (80 % samsvar). Eller du kan tilpasse og angi presisjonen i trinn på 1 %.
Betingelser for nøyaktig samsvar
Betingelsene for nøyaktig samsvar kjøres først for å hente et mindre sett med verdier for tilnærmet samsvar. For å være effektive bør de nøyaktige samsvarsbetingelsene ha en rimelig grad av unikhet. Hvis alle kundene dine bor i samme land/område, hjelper det ikke å begrense omfanget ved å ha et nøyaktig treff på land/område.
Kolonner som fullt navn, e-postadresse, telefonnummer eller adressefelter har god egenart og er gode kolonner å bruke til nøyaktig samsvar.
Kontroller at kolonnen du bruker til en betingelse for nøyaktig samsvar, ikke har noen verdier som gjentas ofte, for eksempel standardverdien «Fornavn» som registreres av et skjema. Customer Insights kan profilere datakolonner for å gi innsikt i gjentakende verdier. Du kan aktivere dataprofilering for Azure Data Lake-tilkoblinger (ved hjelp av Common Data Model eller Delta-format) og Synapse. Dataprofilen kjøres neste gang datakilden oppdateres. Hvis du vil ha mer informasjon, kan du gå til Dataprofilering.
Tilnærmet samsvar
Bruk tilnærmet samsvar til å samsvare strenger som er nesten like, men ikke helt like, på grunn av skrivefeil eller andre små variasjoner. Bruk tilnærmet samsvar strategisk, siden det er tregere enn nøyaktig treff. Sørg for minst én betingelse for nøyaktig treff i enhver regel som har tilnærmede betingelser.
Tilnærmet samsvar er ikke ment å få med navnevarianter som Suzzie og Suzanne. Disse variantene registreres bedre med normaliseringsmønsteret Type: Navn eller det egendefinerte aliassamsvaret, der kunder kan angi listen over navnevarianter de vil betrakte som treff.
Du kan legge til betingelser i en regel, for eksempel samsvare FirstName og Telefon. Betingelser innenfor en gitt regel er OG-betingelser. Alle betingelser må samsvare for at radene skal samsvare. Separate regler er ELLER-betingelser. Hvis regel 1 ikke samsvarer med radene, sammenlignes radene med regel 2.
Notat
Bare strengdatatypekolonner kan bruke tilnærmingssøk. Når det gjelder kolonner med andre datatyper, for eksempel heltall, dobbel eller datetime, er presisjonsfeltet skrivebeskyttet og satt til nøyaktig samsvar.
Beregninger for tilnærmingssøk
Tilnærmede samsvar fastsettes ved å beregne poengsummen for redigeringsavstand mellom to strenger. Hvis poengsummen når eller overskrider presisjonsterskelen, betraktes strengene som et treff.
Redigeringsavstanden er antall redigeringer som kreves for å gjøre én streng om til en annen, ved å legge til, slette eller endre et tegn.
For eksempel har strengene "robert2020@hotmail.com" og "robrt2020@hotmail.cm" en redigeringsavstand på to når vi fjerner e- og o-tegnene. For å kunne beregne poengsummen for redigeringsavstand bruker du denne formelen: (lengde på basisstreng – redigeringsavstand) / lengde på basisstreng.
| Grunnstreng | Sammenligningsstreng | Poengsum |
|---|---|---|
| robert2020@hotmail.com | robrt2020@hotmail.cm | (20 - 2)/20 = 0,9 |