Bruk Azure Machine Learning-baserte modeller
De enhetlige dataene i Dynamics 365 Customer Insights - Data er en kilde for bygging av maskinlæringsmodeller som kan generere ytterligere forretningsinnsikt. Customer Insights - Data integreres med Azure Machine Learning slik at dine egendefinerte modeller brukes.
Forutsetning
- Tilgang til Customer Insights - Data
- Aktivt abonnement på Azure Enterprise
- Enhetlige kundeprofiler
- Tabelleksport til Azure Blob Storage konfigurert
Konfigurer Azure Machine Learning-arbeidsområde
Se Opprette et Azure Machine Learning-arbeidsområde for alternativer for å opprette arbeidsområdet. For å få best mulig ytelse bør du opprette arbeidsområdet i et Azure-område som er geografisk nærmest Customer Insights-miljøet ditt.
Få tilgang til arbeidsområdet via Azure Machine Learning Studio. Det finnes flere måter å samhandle med arbeidsområdet på.
Arbeide med Azure Machine Learning-designer
Azure Machine Learning-utformingen har et visuelt lerret der du kan dra og slippe datasett og moduler. En bunkepipeline som opprettes fra designeren, kan integreres i Customer Insights - Data hvis den er konfigurert i henhold til dette.
Arbeide med SDK-et for Azure Machine Learning
Datateknikere og AI-utviklere bruker SDK-et for Azure Machine Learning til å bygge Machine Learning-arbeidsflyter. Modeller som er lært opp ved hjelp av SDK-et, kan for øyeblikket ikke integreres direkte. En bunkeslutningspipeline som bruker denne modellen, er nødvendig for å integrere med Customer Insights - Data.
Krav til bunkepipeline for å integrere med Customer Insights - Data
Konfigurasjon av datasett
Opprett datasett for å bruke tabelldata fra Customer Insights for bunkeslutningspipelinen. Registrer disse datasettene i arbeidsområdet. For øyeblikket støtter vi bare tabelldatasett i .csv-format. Parameteriser datasettene som tilsvarer tabelldata, som en pipelineparameter.
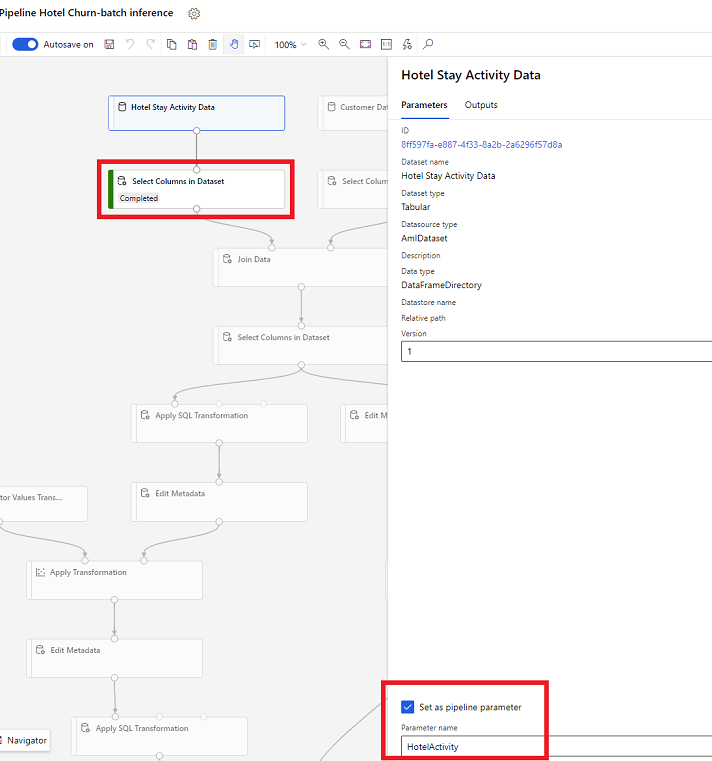
Datasettparametere i designeren
I designeren åpner du Velg kolonner i datasett og velger deretter Angi som pipelineparameter, der du oppgir et navn for parameteren.
Datasettparameter i SDK (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
Bunkebeslutningspipeline
I utformingen bruker du en opplæringspipeline til å opprette eller oppdatere en beslutningspipeline. For øyeblikket støttes bare bunkebeslutningspipeliner.
Publiser pipelinen til et endepunkt ved hjelp av SDK-et. For øyeblikket integreres Customer Insights - Data med standard pipeline i et endepunkt for bunkepipeliner i Machine Learning-arbeidsområdet.
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
Importere pipelinedata
Designeren har Eksporter data-modulen som tillater at utdataene fra en pipeline kan eksporteres til Azure Storage. For øyeblikket må modulen bruke datalagertypen Azure Blob Storage og parametrisere datalageret og den relative banen. Systemet overstyrer begge disse parameterne under kjøring av pipeline med et datalager og en bane som er tilgjengelig for produktet.
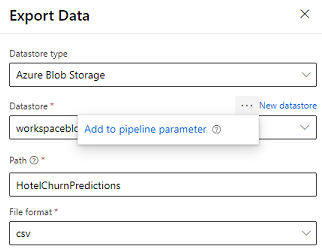
Når du skriver beslutningsutdata ved hjelp av kode, laster du opp utdataene til en bane innenfor et registrert datalager i arbeidsområdet. Hvis banen og datalageret er parametrisert i pipelinen, kan Customer Insights lese og importere beslutningsutdataene. Det er for øyeblikket støtte for enkle tabellutdata i CSV-format. Banen må inneholde navnet på katalogen og filnavnet.
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name