데이터 마트 이해
이 문서에서는 데이터 마트에 대한 중요한 개념을 묘사하고 설명합니다.
의미 체계 모델 이해(기본값)
데이터 마트는 데이터 마트 테이블, 해당 구조 및 기본 데이터의 내용과 자동으로 생성되고 동기화되는 의미 체계 계층을 제공합니다. 이 계층은 자동으로 생성된 의미 체계 모델로 제공됩니다. 이 자동 생성 및 동기화를 사용하면 계층 구조, 친숙한 이름 및 설명과 같은 항목으로 데이터 도메인을 더 자세히 설명할 수 있습니다. 로캘 또는 비즈니스 요구 사항에 따라 서식을 설정할 수도 있습니다. 데이터 마트를 사용하면 보고에 대한 측정값 및 표준화된 메트릭을 만들 수 있습니다. Power BI(및 기타 클라이언트 도구)는 시각적 개체를 만들고 컨텍스트의 데이터를 기반으로 이러한 계산에 대한 결과를 제공할 수 있습니다.
데이터 마트에서 만들어진 기본 Power BI 의미 체계 모델을 사용하면 별도의 의미 체계 모델에 연결하고, 새로 고침 일정을 설정하고, 여러 데이터 요소를 관리할 필요가 없습니다. 대신 데이터 마트에서 비즈니스 논리를 빌드할 수 있으며 해당 데이터는 Power BI에서 즉시 사용할 수 있으므로 다음을 사용하도록 설정합니다.
- 의미 체계 모델 허브를 통한 데이터 마트 데이터 액세스.
- Excel에서 분석할 수 있는 기능.
- Power BI 서비스에서 보고서를 빠르게 만드는 기능.
- 데이터를 새로 고치거나 동기화하거나 연결 세부 정보를 이해할 필요가 없습니다.
- Power BI Desktop 없이 웹에서 솔루션 빌드.
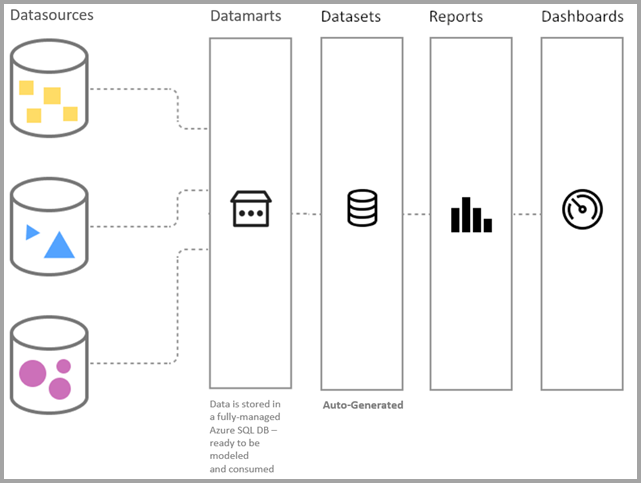
미리 보기 중에는 DirectQuery를 통해서만 기본 의미 체계 모델 연결을 사용할 수 있습니다. 다음 이미지는 보고서 만들기를 통해 데이터 연결부터 시작하여 데이터 마트가 프로세스 연속체에 어떻게 적합한지 보여 줍니다.
기본 의미 체계 모델은 다음과 같은 점에서 기존 Power BI 의미 체계 모델과 다릅니다.
- XMLA 엔드포인트는 읽기 전용 작업을 지원하며 사용자는 의미 체계 모델을 직접 편집할 수 없습니다. XMLA 읽기 전용 권한이 있으면 쿼리 창에서 데이터를 쿼리할 수 있습니다.
- 기본 의미 체계 모델에는 데이터 원본 설정이 없으며 사용자는 자격 증명을 입력할 필요가 없습니다. 대신 쿼리에 자동 SSO(Single Sign-On)를 사용합니다.
- 새로 고침 작업의 경우 의미 체계 모델은 의미 체계 모델 작성자 자격 증명을 사용하여 관리되는 데이터 마트의 SQL 엔드포인트에 연결합니다.
Power BI Desktop을 사용하면 사용자는 복합 모델을 빌드하여 데이터 마트의 의미 체계 모델에 연결하고 다음을 수행할 수 있습니다.
- 분석할 특정 테이블을 선택합니다.
- 데이터 원본을 더 추가합니다.
마지막으로 기본 의미 체계 모델을 직접 사용하지 않으려면 데이터 마트의 SQL 엔드포인트에 연결할 수 있습니다. 자세한 내용은 데이터 마트를 사용하여 보고서 만들기를 참조하세요.
기본 의미 체계 모델의 내용 이해
현재 데이터 마트의 테이블은 기본 의미 체계 모델에 자동으로 추가됩니다. 또한 사용자는 더 많은 유연성을 위해 모델에 포함하려는 데이터 마트에서 테이블 또는 보기를 수동으로 선택할 수 있습니다. 기본 의미 체계 모델에 있는 개체는 모델 보기에서 레이아웃으로 만들어집니다.
개체(테이블 및 뷰)를 포함하는 백그라운드 동기화는 제한된 부실을 적용하여 의미 체계 모델을 업데이트하는 데 다운스트림 의미 체계 모델이 사용되지 않을 때까지 기다립니다. 사용자는 언제든지 의미 체계 모델에서 원하거나 원하지 않는 테이블을 수동으로 선택할 수 있습니다.
증분 새로 고침 및 데이터 마트 이해
데이터 마트 편집기를 사용하여 데이터 흐름 및 의미 체계 모델 증분 새로 고침과 유사한 증분 데이터 새로 고침을 만들고 수정할 수 있습니다. 증분 새로 고침은 새 데이터 및 업데이트된 데이터를 자주 로드하는 데이터 마트 테이블에 대해 자동화된 파티션 생성 및 관리를 제공하여 예약된 새로 고침 작업을 확장합니다.
대부분의 데이터 마트의 경우 증분 새로 고침에는 자주 변경되고 관계형 또는 별표 데이터베이스 스키마의 팩트 테이블과 같이 기하급수적으로 증가할 수 있는 트랜잭션 데이터가 포함된 하나 이상의 테이블이 포함됩니다. 증분 새로 고침 정책을 사용하여 테이블을 분할하고 가장 최근의 가져오기 파티션만 새로 고치면 새로 고쳐야 하는 데이터의 양을 크게 줄일 수 있습니다.
데이터 마트에 대한 증분 새로 고침 및 실시간 데이터는 다음과 같은 이점을 제공합니다.
- 빠르게 변화하는 데이터에 대한 새로 고침 주기 감소
- 새로 고침이 더 빠릅니다.
- 새로 고침이 더 안정적입니다.
- 리소스 사용이 줄어듭니다.
- 큰 데이터 마트를 만들 수 있습니다.
- 구성이 간단함
자동 관리 캐싱 이해
자동 관리 캐싱을 사용하면 기본 의미 체계 모델에 대한 기본 데이터를 자동으로 가져올 수 있으므로 스토리지 모드를 관리하거나 오케스트레이션할 필요가 없습니다. 기본 의미 체계 모델에 대한 가져오기 모드는 빠른 Vertipaq 엔진을 사용하여 데이터 마트의 의미 체계 모델에 대한 성능 가속화를 제공합니다. 자동 관리 캐싱을 사용하여 Power BI는 가져올 모델의 스토리지 모드를 변경하며, Power BI 및 Analysis Services의 메모리 내 엔진을 사용합니다.
자동 관리 캐싱은 다음과 같은 방식으로 작동합니다. 새로 고칠 때마다 기본 의미 체계 모델의 스토리지 모드가 DirectQuery로 변경됩니다. 자동 관리 캐싱은 병렬 가져오기 모델을 비동기적으로 빌드하고 데이터 마트에서 관리하며 데이터 마트의 가용성 또는 성능에 영향을 주지 않습니다. 기본 의미 체계 모델이 완료된 후 들어오는 쿼리는 가져오기 모델을 사용합니다.
가져오기 모델의 자동 생성은 데이터 마트에서 변경 내용이 감지되지 않은 후 약 10분 이내에 수행합니다. 가져오기 의미 체계 모델은 다음과 같은 방식으로 변경됩니다.
- 새로 고침
- 새 데이터 원본
- 스키마 변경:
- 새 데이터 원본
- Power Query Online의 데이터 준비 단계로 업데이트
- 다음과 같은 모든 모델링 업데이트:
- 측정값 그룹
- 계층 구조
- Descriptions
자동 관리 캐싱에 대한 모범 사례
변경 내용에 대해 배포 파이프라인을 사용하여 최상의 성능을 보장하고 사용자가 가져오기 모델을 사용하고 있는지 확인합니다. 배포 파이프라인을 사용하는 것은 이미 데이터 마트를 빌드하는 모범 사례이지만 이렇게 하면 자동 관리 캐싱을 더 자주 활용할 수 있습니다.
자동 관리 캐싱에 대한 고려 사항 및 제한 사항
- Power BI는 현재 캐싱 작업의 기간을 10분으로 한정합니다.
- 특정 열에 대한 고유성/null이 아닌 제약 조건은 가져오기 모델에 적용되며 데이터가 준수하지 않으면 캐시 빌드가 실패합니다.
관련 콘텐츠
이 문서에서는 이해해야 할 중요한 데이터 마트 개념에 대한 개요를 제공했습니다.
다음 문서에서는 데이터마트 및 Power BI에 관한 자세한 정보를 제공합니다.
데이터 흐름 및 데이터 변환에 대한 자세한 내용은 다음 문서를 참조하세요.