의료 데이터 솔루션에서 CMS 청구 데이터 변환(프리뷰) 사용
[이 문서는 시험판 문서이며 변경될 수 있습니다.]
CMS 청구 데이터 변환(프리뷰)을 사용하면 CMS(Centers for Medicare & Medicaid Services) CCLF(Claim and Claim Line Feed) 형식으로 청구 데이터를 수집, 저장 및 분석할 수 있습니다. 기능에 대해 자세히 알아보고 배포 및 구성하는 방법을 이해하려면 다음을 참조하세요.
변환 메커니즘 이해
청구 데이터 변환 파이프라인은 네이티브 또는 압축된 형식의 청구 파일을 레이크하우스로 수집합니다. 엔드투엔드 변환은 다음과 같은 높은 수준의 연속 단계를 따릅니다.
- OneLake에서 청구 파일 변환
- OneLake에서 청구 파일 구성
- 브론즈 레이크하우스로 청구 데이터 추출
- 청구 데이터를 FHIR NDJSON 파일로 변환
- 브론즈 레이크하우스에서 청구 데이터를 FHIR 평면화된 테이블로 변환
- 실버 레이크하우스에서 청구 데이터를 FHIR 관계형 테이블로 변환
청구 데이터 변환 파이프라인 실행
청구 데이터 변환 파이프라인을 실행하기 전에 청구 샘플 데이터 설정의 단계를 완료해야 합니다.
브론즈 레이크하우스의 청구 데이터를 실버 레이크하우스로 변환하려면 healthcare#_msft_clinical_claims_cclf_data_transformation 데이터 파이프라인을 열고 실행을 선택합니다.
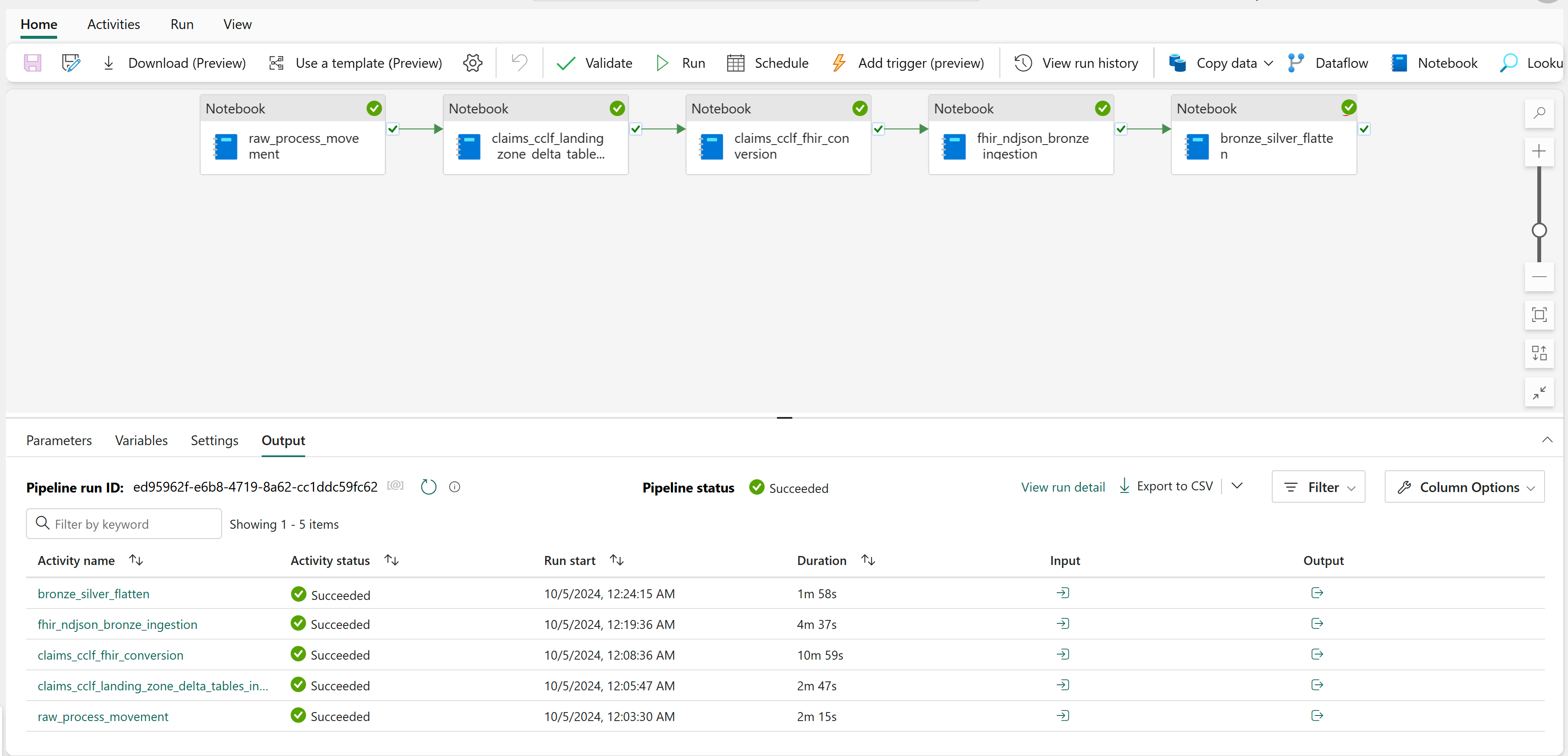
파이프라인이 성공적으로 실행되면 실버 레이크하우스에서 ExplanationOfBenefit 테이블을 열어 변환된 데이터를 확인합니다.



사용 시 고려 사항
CMS 청구 데이터 변환(프리뷰) 기능을 사용하기 전에 이러한 핵심 사항을 검토하십시오.
Spark 버전
Notebook은 기본적으로 Spark 런타임 버전 1.2(Spark 3.4, Delta 2.4)에서 실행되도록 미리 구성되어 있습니다. 환경 수준에서 이 설정을 유지해야 합니다. 자세한 내용은 Fabric 작업 영역에서 Spark 런타임 버전 재설정을 참조하세요.
파일 확장명
업로드한 CCLF 파일은 *.T1000001~*.T1000009의 확장자 형식을 따라야 합니다. 확장자가 잘못된 파일은 브론즈 레이크하우스의 Failed 폴더로 이동합니다.
레코드 길이
CCLF 파일의 레코드 길이 불일치는 하나 이상의 레코드가 필수 고정 길이 형식에서 벗어날 때 발생합니다. 이러한 불일치로 인해 데이터 정렬 오류, 불완전한 데이터 캡처 또는 처리 오류가 발생할 수 있습니다. 예상 길이를 충족하지 않는 레코드가 있는 파일은 브론즈 레이크하우스의 Failed 폴더로 이동합니다.