자습서: 의미 체계 링크를 사용하여 의미 체계 모델에서 관계 발견
이 자습서에서는 Jupyter Notebook에서 Power BI와 상호 작용하는 방법과 SemPy 라이브러리를 사용하여 테이블 간의 관계를 감지하는 방법을 보여 줍니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- 의미 체계 링크의 Python 라이브러리(SemPy)를 사용하여 의미 체계 모델(Power BI 데이터 세트)에서 관계를 발견합니다.
- Power BI와의 통합을 지원하고 데이터 품질 분석을 자동화하는 데 도움이 되는 SemPy의 구성 요소를 사용합니다. 이러한 구성 요소는 다음과 같습니다.
- FabricDataFrame - 추가적인 의미 체계 정보를 통해 향상된 Pandas와 유사한 구조입니다.
- Fabric 작업 영역에서 Notebook으로 의미 체계 모델을 당겨오기 위한 함수입니다.
- 함수 종속성에 대한 가설의 평가를 자동화하고 의미 체계 모델에서 관계 위반을 식별하는 함수입니다.
필수 조건
Microsoft Fabric 구독을 구매합니다. 또는 무료 Microsoft Fabric 평가판에 등록합니다.
Microsoft Fabric에 로그인합니다.
홈페이지 왼쪽 아래에 있는 환경 전환기를 사용하여 패브릭으로 전환합니다.

왼쪽 탐색 창에서 작업 영역을 선택하여 내 작업 영역을 찾아 선택합니다. 이 작업 영역은 현재 작업 영역이 됩니다.
fabric-samples GitHub 리포지토리에서Customer Profitability Sample.pbix 및 Customer Profitability Sample (auto).pbix 의미 체계 모델을 다운로드하여 작업 영역에 업로드합니다.
Notebook에서 따라 하기
이 자습서에는 powerbi_relationships_tutorial.ipynb Notebook이 함께 제공됩니다.
이 튜토리얼에 포함된 노트북을 열려면, 데이터 과학 튜토리얼을 위한 시스템 준비의 지침을 따라 노트북을 작업 공간으로 가져오세요.
이 페이지에서 코드를 복사하여 붙여넣으려는 경우 새 Notebook을 만들 수 있습니다.
코드 실행을 시작하기 전에 Notebook에 레이크하우스를 연결해야 합니다.
Notebook 설정
이 섹션에서는 필요한 모듈 및 데이터를 통해 Notebook 환경을 설정합니다.
Notebook 내의
SemPy인라인 설치 기능을 사용하여 PyPI에서%pip를 설치합니다.%pip install semantic-link나중에 필요한 SemPy 모듈을 가져옵니다.
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violations출력 서식 지정에 도움이 되는 구성 옵션을 적용하기 위해 Pandas를 가져옵니다.
import pandas as pd pd.set_option('display.max_colwidth', None)
의미 체계 모델 살펴보기
이 자습서에서는 표준 샘플 의미 체계 모델인 Customer Profitability Sample.pbix를 사용합니다. 의미 체계 모델에 대한 설명은 Power BI에 대한 고객 수익성 샘플을 참조하세요.
SemPy의
list_datasets함수를 사용하여 현재 작업 영역에서 의미 체계 모델을 탐색할 수 있습니다.fabric.list_datasets()
이 Notebook의 나머지 부분에서는 두 가지 버전의 고객 수익성 샘플 의미 체계 모델을 사용합니다.
- 고객 수익성 샘플: 미리 정의된 테이블 관계가 있는 Power BI 샘플에서 제공되는 의미 체계 모델
- 고객 수익성 샘플(자동): 동일한 데이터이지만 관계는 Power BI에서 자동으로 감지하는 데이터로 제한됩니다.
미리 정의된 의미 체계 모델을 사용하여 샘플 의미 체계 모델 추출
SemPy의 함수를 사용하여
list_relationships의미 체계 모델 내에 미리 정의되고 저장된 관계를 로드합니다. 이 함수는 테이블 형식 개체 모델에서 나열됩니다.dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsSemPy의
relationships함수를 사용하여plot_relationship_metadataDataFrame을 그래프로 시각화합니다.plot_relationship_metadata(relationships)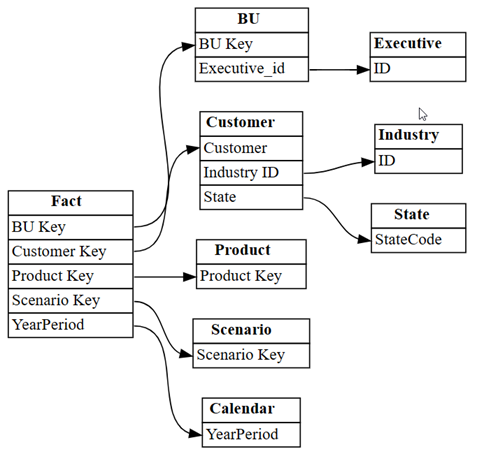

이 그래프는 주제 전문가가 Power BI에서 정의한 방식을 반영하므로 이 의미 체계 모델의 테이블 간 관계에 대한 ‘근거’를 보여 줍니다.
보완 관계 발견
Power BI가 자동으로 감지한 관계로 시작하면 더 작은 집합을 갖게 됩니다.
의미 체계 모델에서 Power BI가 자동으로 검색한 관계를 시각화합니다.
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)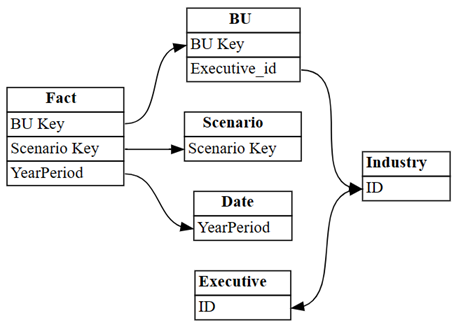
Power BI의 자동 감지에서 많은 관계를 놓쳤습니다. 또한 자동 감지된 관계 중 두 가지가 의미론적으로 올바르지 않습니다.
-
Executive[ID]->Industry[ID] -
BU[Executive_id]->Industry[ID]
-
관계를 테이블로 인쇄합니다.
autodetectedIndustry테이블에 대한 잘못된 관계가 인덱스 3과 4의 행에 표시됩니다. 이 정보를 사용하여 문제를 해결할 수 있습니다.잘못 식별된 관계를 무시합니다.
autodetected.drop(index=[3,4], inplace=True) autodetected이제 정확하지만 불완전한 관계가 있습니다.
plot_relationship_metadata를 사용하여 불완전한 관계를 시각화합니다.plot_relationship_metadata(autodetected)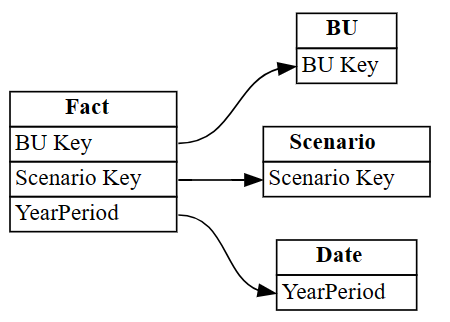
SemPy의
list_tables및read_table함수를 사용하여 의미 체계 모델에서 모든 테이블을 로드합니다.tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()find_relationships를 사용하여 테이블 간의 관계를 찾고 로그 출력을 검토하여 이 함수의 작동 방식에 대한 몇 가지 인사이트를 얻을 수 있습니다.suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )새로 발견된 관계를 시각화합니다.
plot_relationship_metadata(suggested_relationships_all)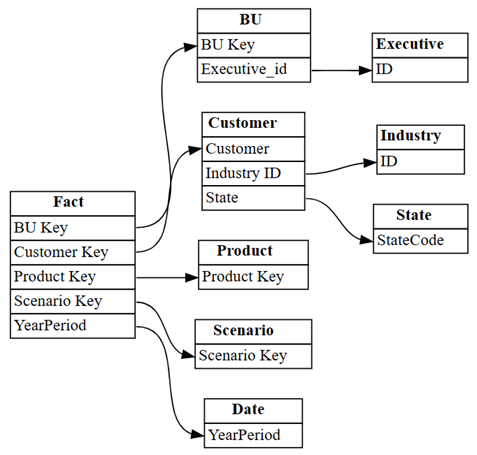
SemPy는 모든 관계를 감지할 수 있었습니다.
exclude매개 변수를 사용하여 검색을 이전에 식별되지 않은 추가 관계로 제한합니다.additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



관계 유효성 검사
먼저 고객 수익성 샘플 의미 체계 모델에서 데이터를 로드합니다.
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()list_relationship_violations함수를 사용하여 기본 및 외래 키 값의 겹침을 확인합니다 .list_relationships함수의 출력을list_relationship_violations의 입력으로 제공합니다.list_relationship_violations(tables, fabric.list_relationships(dataset))관계 위반은 몇 가지 흥미로운 인사이트를 제공합니다. 예를 들어
Fact[Product Key]의 7개 값 중 1개는Product[Product Key]에 존재하지 않으며 누락된 키는50입니다.
탐색적 데이터 분석은 흥미로운 프로세스이며 데이터 정리도 마찬가지입니다. 데이터를 어떻게 보는지, 무엇을 묻고 싶은지 등에 따라 데이터에 숨겨진 것이 항상 있기 마련입니다. 의미 체계 링크는 데이터를 활용해 더 많은 성과를 달성할 수 있는 새로운 도구를 제공합니다.
관련 콘텐츠
의미 체계 링크/SemPy에 대한 다른 자습서를 확인해 볼 수 있습니다.