자습서: 기능 종속성을 사용하여 데이터 정리
이 자습서에서는 데이터 정리에 기능 종속성을 사용합니다. 함수 종속성은 의미 체계 모델(Power BI 데이터 세트)의 한 열이 다른 열의 함수일 때 존재합니다. 예를 들어 우편 번호 열에 city 열의 값이 결정될 수 있습니다. 기능 종속성은 DataFrame 내의 두 개 이상의 열에 있는 값 간의 일대다 관계로 나타납니다. 이 자습서에서는 Synthea 데이터 세트를 사용하여 기능 관계가 데이터 품질 문제를 감지하는 데 어떻게 도움이 되는지 보여줍니다.
이 자습서에서는 다음 방법을 알아봅니다.
- 도메인 지식을 적용하여 의미 체계 모델의 기능 종속성에 대한 가설을 작성합니다.
- 데이터 품질 분석을 자동화하는 데 도움이 되는 의미 체계 링크의 Python 라이브러리(SemPy)의 구성 요소를 숙지하세요. 이러한 구성 요소는 다음과 같습니다.
- FabricDataFrame - 추가적인 의미 정보를 가진 pandas 유사 구조체입니다.
- 기능 종속성에 대한 가설의 평가를 자동화하고 의미 체계 모델에서 관계 위반을 식별하는 유용한 함수입니다.
필수 구성 요소
Microsoft Fabric 구독을받으세요. 또는 무료 Microsoft Fabric 평가판등록하세요.
Microsoft Fabric 에로그인하세요.
홈페이지 왼쪽 아래에 있는 환경 전환기를 사용하여 패브릭으로 전환합니다.

- 왼쪽 탐색 창에서 작업 영역 선택하여 작업 영역을 찾아 선택합니다. 이 작업 영역은 현재 작업 영역이 됩니다.
노트북에서 따라하세요.
data_cleaning_functional_dependencies_tutorial.ipynb Notebook은 이 자습서와 함께 제공됩니다.
이 자습서와 함께 제공되는 노트북을 열려면 데이터 과학 자습서를 위한 시스템 준비 지침에 따라 노트북을 워크스페이스로 가져옵니다.
이 페이지에서 코드를 복사하여 붙여 넣으면 새 Notebook 만들있습니다.
코드를 실행하기 전에 노트북에 lakehouse를 연결해야 합니다.
Notebook 설정
이 섹션에서는 필요한 모듈 및 데이터를 사용하여 Notebook 환경을 설정합니다.
- Spark 3.4 이상의 경우 패브릭을 사용할 때 기본 런타임에서 의미 체계 링크를 사용할 수 있으며 설치할 필요가 없습니다. Spark 3.3 이하를 사용하거나 최신 버전의 의미 체계 링크로 업데이트하려는 경우 다음 명령을 실행할 수 있습니다.
python %pip install -U semantic-link
나중에 필요한 모듈의 필요한 가져오기를 수행합니다.
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_synthea샘플 데이터를 끌어오기. 이 자습서에서는 합성 의료 레코드의 Synthea 데이터 세트를 사용합니다(단순성을 위해 작은 버전).
download_synthea(which='small')
데이터 탐색
FabricDataFrame을(를) providers.csv 파일의 콘텐츠로 초기화합니다.providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()자동 검색된 기능 종속성의 그래프를 그려 SemPy의
find_dependencies함수와 관련된 데이터 품질 문제를 확인합니다.deps = providers.find_dependencies() plot_dependency_metadata(deps)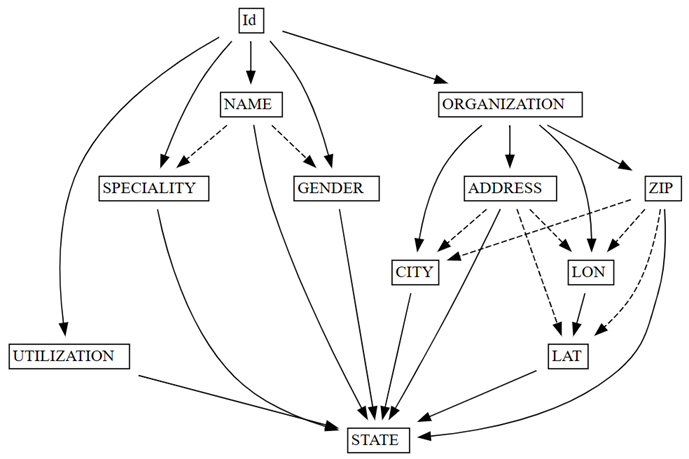
기능 종속성의 그래프는
Id가NAME및ORGANIZATION를 결정한다는 것을 보여 주며, 이는Id이 고유하기 때문에 예상된 결과입니다(단색 화살표로 표시).Id고유한지 확인합니다.providers.Id.is_unique코드는
True반환하여Id고유한지 확인합니다.

기능 종속성 심층 분석
또한 기능 종속성 그래프는 ORGANIZATION 예상대로 ADDRESS 및 ZIP결정한다는 것을 보여 줍니다. 그러나 당신은 ZIP가 CITY도 결정할 것이라고 기대할 수도 있습니다. 하지만 파선 화살표는 이 종속성이 데이터 품질 문제를 가리키는 근사적임을 나타냅니다.
그래프에는 다른 특수성이 있습니다. 예를 들어 NAMEGENDER, Id, SPECIALITY또는 ORGANIZATION결정하지 않습니다. 이러한 각 특성은 조사할 가치가 있을 수 있습니다.
SemPy의
list_dependency_violations함수를 사용하여 위반의 테이블 형식 목록을 확인하여ZIPCITY간의 대략적인 관계를 자세히 살펴봅니다.providers.list_dependency_violations('ZIP', 'CITY')SemPy의
plot_dependency_violations시각화 함수를 사용하여 그래프를 그립니다. 이 그래프는 위반 횟수가 작은 경우 유용합니다.providers.plot_dependency_violations('ZIP', 'CITY')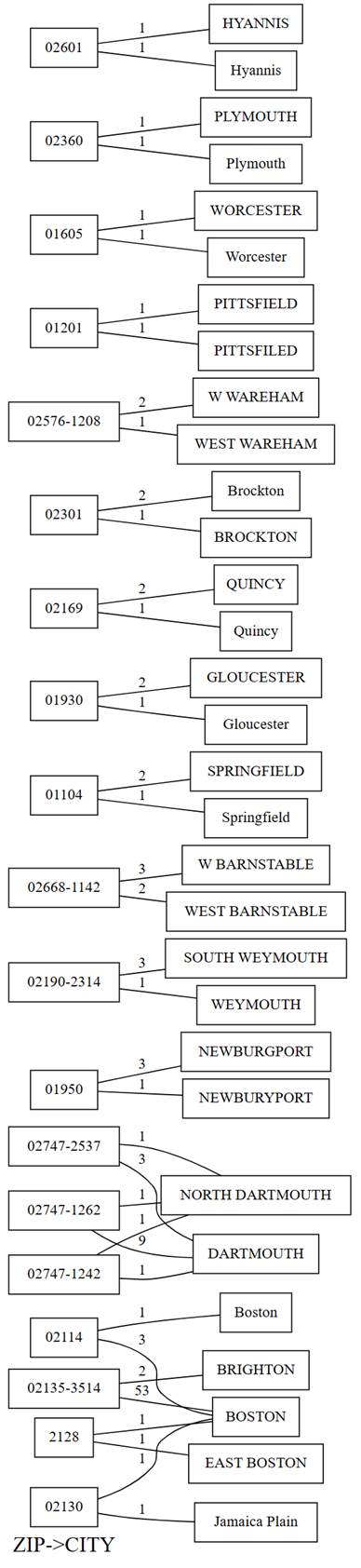
종속성 위반 그림에는 왼쪽의
ZIP값과 오른쪽에CITY값이 표시됩니다. 이 두 값을 포함하는 행이 있는 경우 가장자리는 그림의 왼쪽에 있는 우편 번호를 오른쪽에 있는 도시와 연결합니다. 가장자리는 이러한 행의 수가 표시됩니다. 예를 들어 우편 번호가 02747-1242인 두 개의 행이 있으며, 하나는 도시 "NORTH DARTHMOUTH"이고 다른 행은 이전 그림과 다음 코드와 같이 도시 "DARTHMOUTH"가 있는 행입니다.다음 코드를 실행하여 종속성 위반의 플롯으로 수행한 이전 관찰을 확인합니다.
providers[providers.ZIP == '02747-1242'].CITY.value_counts()플롯에서는 "DARTHMOUTH"로 표시된
CITY를 가진 행들 중 9개 행의ZIP이 02747-1262이며, 한 행의ZIP가 02747-1242이고, 한 행의ZIP가 02747-2537임을 보여줍니다. 다음 코드를 사용하여 이러한 관찰을 확인합니다.providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()"DARTMOUTH"와 연결된 다른 우편 번호가 있지만 이러한 우편 번호는 데이터 품질 문제를 암시하지 않으므로 종속성 위반 그래프에 표시되지 않습니다. 예를 들어 우편 번호 "02747-4302"는 "DARTMOUTH"에 고유하게 연결되며 종속성 위반 그래프에 표시되지 않습니다. 다음 코드를 실행하여 확인합니다.
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
SemPy에서 검색된 데이터 품질 문제 요약
종속성 위반 그래프로 돌아가면 이 의미 체계 모델에 몇 가지 흥미로운 데이터 품질 문제가 있음을 알 수 있습니다.
- 일부 도시 이름은 모두 대문자입니다. 이 문제는 문자열 메서드를 사용하여 쉽게 해결할 수 있습니다.
- 일부 도시 이름에는 "북쪽" 및 "동쪽"과 같은 한정자(또는 접두사)가 있습니다. 예를 들어 우편 번호 "2128"은 "EAST BOSTON"에 한 번 매핑되고 "BOSTON"에 한 번 매핑됩니다. "NORTH DARTHMOUTH"와 "DARTHMOUTH" 사이에도 비슷한 문제가 발생합니다. 이러한 한정자를 삭제하거나 가장 자주 발생하는 우편 번호를 도시에 매핑할 수 있습니다.
- 일부 도시에는 "PITTSFIELD" vs. "PITTSFILED" 및 "NEWBURGPORT vs. "NEWBURYPORT"와 같은 오타가 있습니다. "NEWBURGPORT"의 경우 가장 일반적인 항목을 사용하여 이 오타를 수정할 수 있습니다. "PITTSFIELD"의 경우 각 항목이 하나만 있으면 외부 지식이나 언어 모델 사용 없이 자동 명확하게 구분하기가 훨씬 더 어려워집니다.
- 경우에 따라 "West"와 같은 접두사는 단일 문자 "W"로 축약됩니다. "모든 경우에 'W'가 'West'를 나타낸다면, 이 문제는 간단한 교체로 해결될 수 있습니다."
- 우편 번호 "02130"은 한 번 "보스턴"과 "자메이카 플레인"에 한 번 매핑됩니다. 이 문제는 해결하기 쉽지 않지만 더 많은 데이터가 있는 경우 가장 일반적인 항목에 매핑하는 것이 잠재적인 해결 방법이 될 수 있습니다.
데이터 정리
모든 대문자를 타이틀 사례로 변경하여 대문자화 문제를 해결합니다.
providers['CITY'] = providers.CITY.str.title()위반 검색을 다시 실행하여 일부 모호성이 사라졌는지 확인합니다(위반 횟수는 더 작음).
providers.list_dependency_violations('ZIP', 'CITY')이 시점에서 데이터를 더 수동으로 구체화할 수 있지만, 한 가지 잠재적인 데이터 정리 작업은 SemPy의
drop_dependency_violations함수를 사용하여 데이터 열 간의 기능 제약 조건을 위반하는 행을 삭제하는 것입니다.결정 변수의 각 값에 대해
drop_dependency_violations종속 변수의 가장 일반적인 값을 선택하고 다른 값이 있는 모든 행을 삭제하여 작동합니다. 이 통계적 추론으로 인해 데이터에 대한 올바른 결과가 발생할 것이라고 확신하는 경우에만 이 작업을 적용해야 합니다. 그렇지 않으면 필요에 따라 검색된 위반을 처리하는 고유한 코드를 작성해야 합니다.ZIP및CITY열에서drop_dependency_violations함수를 실행합니다.providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')ZIPCITY간의 종속성 위반을 나열합니다.providers_clean.list_dependency_violations('ZIP', 'CITY')이 코드는 빈 목록을 반환하여 CITY -> ZIP 기능 제약 조건의 위반이 더 이상 없음을 나타냅니다.
관련 콘텐츠
의미 체계 링크/SemPy에 대한 다른 자습서를 확인하세요.
- 자습서: 샘플 의미 체계 모델 기능 종속성 분석
- 자습서: Jupyter Notebook에서 Power BI 측정값 추출 및 계산
- 자습서: 의미 체계 링크 사용하여 의미 체계 모델에서 관계 검색
- 자습서: 의미 체계 링크 사용하여 Synthea 데이터 세트의 관계 검색
- 자습서: SemPy 및 GX(Great Expectations) 사용하여 데이터 유효성 검사