Microsoft Fabric에서 사용자 지정 Spark 풀을 만드는 방법
이 문서에서는 분석 워크로드를 위해 Microsoft Fabric에서 사용자 지정 Apache Spark 풀을 만드는 방법을 설명합니다. Apache Spark 풀을 사용하면 사용자가 특정 요구 사항에 따라 맞춤형 컴퓨팅 환경을 만들어 최적의 성능과 리소스 사용률을 보장할 수 있습니다.
자동 크기 조정을 위한 최소 및 최대 노드를 지정합니다. 이러한 값을 기준으로 작업의 컴퓨팅 요구 사항이 변경됨에 따라 시스템은 노드를 동적으로 획득하고 사용 중지하므로 효율적인 크기 조정 및 성능이 향상됩니다. Spark 풀에서 실행기의 동적 할당은 수동 실행기 구성의 필요성도 완화합니다. 대신 시스템은 데이터 볼륨 및 작업 수준 컴퓨팅 요구 사항에 따라 실행기 수를 조정합니다. 이 프로세스를 사용하면 성능 최적화 및 리소스 관리에 대한 걱정 없이 워크로드에 집중할 수 있습니다.
참고 항목
사용자 지정 Spark 풀을 만들려면 작업 영역에 대한 관리자 액세스 권한이 필요합니다. 용량 관리자는용량 관리자 설정의 Spark 컴퓨팅 섹션에서 사용자 지정된 작업 영역 풀 옵션을 사용하도록 설정해야 합니다. 자세한 내용은 Fabric 용량에 대한 Spark 컴퓨팅 설정을 참조하세요.
사용자 지정 Spark 풀을 만듭니다.
작업 영역과 연결된 Spark 풀을 만들거나 관리하려면 다음을 수행합니다.
작업 영역으로 이동하여 작업 영역 설정을 선택합니다.
데이터 엔지니어링/과학 옵션을 선택하여 메뉴를 확장한 다음, Spark 설정선택합니다.
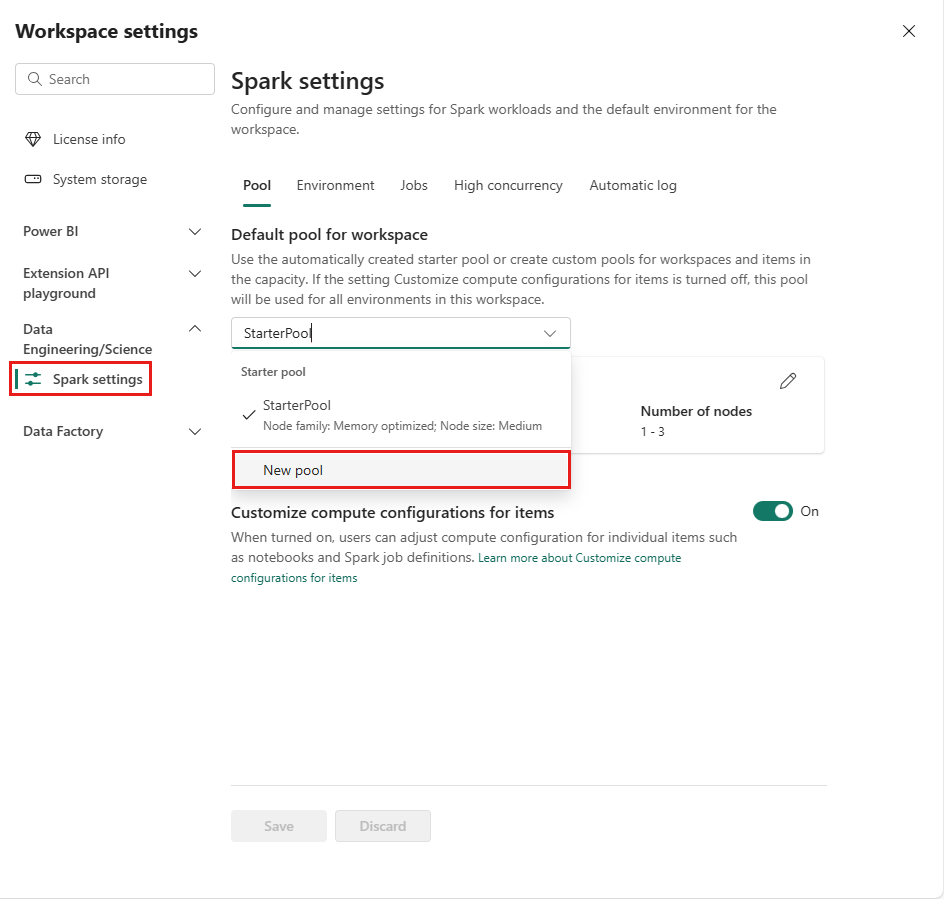
새 풀 옵션을 선택합니다. 풀 만들기 화면에서 Spark 풀의 이름을 지정합니다. 또한 노드 패밀리를 선택하고 워크로드에 대한 컴퓨팅 요구 사항에 따라 사용 가능한 크기(Small, Medium, Large, X-Large 및 XX-Large)에서 노드 크기를 선택합니다.

사용자 지정 풀에 대한 최소 노드 구성을 1로 설정할 수 있습니다. Fabric Spark는 단일 노드가 있는 클러스터에 복원 가능한 가용성을 제공하므로 작업 실패, 실패 시 세션 손실 또는 더 작은 Spark 작업에 대한 컴퓨팅 비용 초과를 염려할 필요가 없습니다.
사용자 지정 Spark 풀에 대해 자동 크기 조정은 사용하거나 사용하지 않도록 설정할 수 있습니다. 자동 크기 조정을 사용하도록 설정하면 풀은 사용자가 지정한 최대 노드 제한까지 새 노드를 동적으로 확보한 다음 작업 실행 후 사용 중지합니다. 이 기능은 작업 요구 사항에 따라 리소스를 조정하여 성능을 개선합니다. Fabric 용량 SKU의 일부로 구매한 용량 단위에 맞는 노드의 크기를 조정할 수 있습니다.

Spark 풀에 동적 실행기 할당을 사용하도록 선택할 수도 있습니다. 그러면 사용자가 지정한 최대 바인딩 내에서 최적 실행기 수가 자동으로 결정됩니다. 이 기능은 데이터 볼륨에 따라 실행기 수를 조정하여 성능 및 리소스 사용률을 개선합니다.

이러한 사용자 지정 풀의 기본 자동 일시 중지 기간은 2분입니다. 자동 일시 중지 기간에 도달하면 세션이 만료되고 클러스터가 할당되지 않습니다. 사용자 지정 Spark 풀이 사용되는 기간 및 노드 수에 따라 요금이 청구됩니다.
관련 콘텐츠
- Apache Spark 공개 문서에서 자세히 알아보세요.
- Microsoft Fabric에서 Spark 작업 영역 관리 설정을 시작합니다.